 電子發(fā)燒友App
電子發(fā)燒友App


人們通常用每秒百萬(wàn)條指令(MIPS)來(lái)衡量微控制器(MCU)的計(jì)算性能,但是沒有任何兩個(gè)MCU/SoC架構(gòu)是完全相同的,加速不同應(yīng)用性能的集成度也不相同。因此,在采用適當(dāng)硬件特性的情況下,固件應(yīng)用可減少對(duì)CPU資源的占用。在移植到不同架構(gòu)的過(guò)程中,如果開發(fā)人員只關(guān)注MIPS,僅以MIPS來(lái)預(yù)測(cè)應(yīng)用所需的計(jì)算性能,那么就會(huì)大錯(cuò)特錯(cuò)了。本文將就典型的計(jì)算問(wèn)題分析MCU/SoC的多種架構(gòu)特性,目的是說(shuō)明MIPS并不能真正反映器件的計(jì)算性能,并探討我們應(yīng)當(dāng)如何應(yīng)對(duì)這一問(wèn)題。此外,鑒于目前比較此類產(chǎn)品系統(tǒng)級(jí)功能的基準(zhǔn)標(biāo)準(zhǔn)較少,本文還將專門重點(diǎn)討論運(yùn)行速率在100MHz以下的MCU/SoC器件。
100MHz以下架構(gòu)的特點(diǎn)
100MHz以下的MCU通常使用8位、16位或32位架構(gòu),數(shù)據(jù)總線寬度為8位、16位或32位。這些產(chǎn)品也可分為其它多種類型,如Harvard/Von Neumen和RISC與CISC等,每種類型都有其引人關(guān)注的不同之處。對(duì)大多數(shù)MCU而言,不同的指令需要執(zhí)行不同的機(jī)器資源。此外,振蕩器頻率通常與機(jī)器工作周期不同,比如,就經(jīng)典的8051而言,振蕩器的12個(gè)周期才相當(dāng)于機(jī)器工作1個(gè)周期。而對(duì)許多PIC器件而言,4個(gè)振蕩器周期就對(duì)應(yīng)于1個(gè)機(jī)器工作周期。
下面我們通過(guò)一個(gè)示例來(lái)更好地了說(shuō)明這一問(wèn)題。假設(shè)某器件的振蕩器頻率為20MHz,其兩個(gè)振蕩器周期對(duì)應(yīng)于1個(gè)機(jī)器工作周期。此外,指令執(zhí)行需要1到6個(gè)機(jī)器工作周期。那么,該器件的MIPS額定值是多少呢?我們將振蕩器頻率除以2,得到可用的機(jī)器工作周期為1千萬(wàn)。不過(guò),如何將機(jī)器工作周期轉(zhuǎn)換為MIPS則取決于我們?nèi)绾慰创@一問(wèn)題。如果您是營(yíng)銷人員,您會(huì)只專注于最佳情況,也就是假定每條指令只要一個(gè)工作周期,這樣這款產(chǎn)品的性能就是10 MIPS。如果您想了解最低的理論性能,那么就會(huì)假定每條指令需要6個(gè)工作周期,這就會(huì)得到1.66(10/6)MIPS。這里我們得到了最高和最低的MIPS。對(duì)典型應(yīng)用而言,實(shí)際的MIPS性能介于二者之間,具體取決于應(yīng)用的指令集組合。我們這里還作了令一個(gè)假定,即認(rèn)為不同的架構(gòu)指令計(jì)算性能類似,但這基本上是不現(xiàn)實(shí)的。
我們這里假定機(jī)器工作周期數(shù)量是決定器件執(zhí)行指令數(shù)量的唯一因素。下面,我們?cè)O(shè)想一下閃存對(duì)處理性能的影響。一般而言,閃存提供數(shù)據(jù)的速率不超過(guò)20MHz。因此,如果CPU運(yùn)行速率超過(guò)20MHz,而用閃存執(zhí)行指令,那么閃存數(shù)據(jù)速率就成為了最大的瓶頸。在此情況下,我們可讓閃存總線帶寬高于數(shù)據(jù)總線帶寬,并創(chuàng)建指令緩沖器以跟上指令速率,從而解決上述問(wèn)題。要做到這一點(diǎn),CPU就要在執(zhí)行當(dāng)前指令時(shí)調(diào)用下一條指令。這種做法對(duì)線性代碼而言沒問(wèn)題。但不幸的是,實(shí)際系統(tǒng)代碼很少是線性的。每次代碼出現(xiàn)分支,指令緩沖器都必須重構(gòu)。另一種改進(jìn)性能的辦法是添加緩存容量。簡(jiǎn)而言之,如果一個(gè)MCU/SoC管理閃存的效率較高,而另一個(gè)效率較低,則即便機(jī)器工作循環(huán)和指令集相同,性能數(shù)據(jù)也將大不相同。
我們已經(jīng)比較熟悉類似上述的各種因素,開發(fā)人員通常會(huì)在比較不同器件的性能時(shí)考慮到這些相關(guān)因素。下面我們來(lái)談?wù)勀承┎惶黠@的因素。
DMA對(duì)MIPS的影響
某MCU/SoC器件支持DMA(直接存儲(chǔ)器存取)功能,其能將CPU從存儲(chǔ)器存取工作中解放出來(lái),從而提高性能。我們?cè)趺丛u(píng)估DMA對(duì)MIPS的影響呢?先來(lái)看看主模式下串行通信協(xié)議SPI的典型使用情況。SPI是一個(gè)很好的例子,因?yàn)樗ǔJ荕CU/SoC上最高吞吐量的板內(nèi)通信外設(shè),而且配合存儲(chǔ)器、以太網(wǎng)、無(wú)線收發(fā)器芯片等一同使用。
假定:
SPI速率:8Mbps
數(shù)據(jù)包大小:128字節(jié)
數(shù)據(jù)吞吐率要求:每個(gè)數(shù)據(jù)包160uS
如SPI速率為8Mbps,那么傳輸1個(gè)字節(jié)需要1uS。因此,傳輸128個(gè)字節(jié)需要128uS。我們的預(yù)算為每個(gè)數(shù)據(jù)包160uS,這就剩下32uS(160-128)用于SPI管理。這32uS的預(yù)算要平均分配給128個(gè)字節(jié),因?yàn)橄到y(tǒng)每一個(gè)uS都要載入一個(gè)新數(shù)據(jù)字節(jié)。32uS除以128即可得到SPI管理每數(shù)據(jù)字節(jié)傳輸有250nS的時(shí)間。
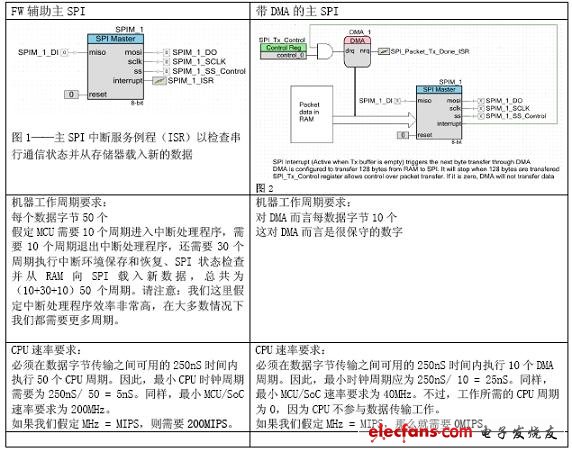
就上例而言,DMA將MCU/SoC速率需求降低了160MHz,而將CPU處理能力需求降低了200MHz。如果我們假定一次周期相當(dāng)于MIPS,那么本應(yīng)用的DMA就相當(dāng)于一個(gè)200MIPS處理器。
DMA實(shí)現(xiàn)的高效MIPS在很大程度上取決于吞吐量需求。我們?cè)倥e一個(gè)本應(yīng)用的極端例子。假定每個(gè)數(shù)據(jù)包沒有時(shí)間限制,那么DMA每字節(jié)節(jié)約的CPU周期數(shù)達(dá)50個(gè),那么就128個(gè)字節(jié)而言,周期數(shù)節(jié)約可達(dá)6400個(gè)。如果MCU需要在16MHz的情況下支持8MHz SPI,且128個(gè)字節(jié)的數(shù)據(jù)包每秒只傳輸一次,那么不支持DMA的MCU/SoC運(yùn)行速率就需達(dá)到每秒16,006,400條指令,性能水平和支持DMA的MCU每秒160萬(wàn)條指令相當(dāng)。因此,就這一特殊的使用案例而言,DMA的影響可以忽略不計(jì)。
協(xié)處理器對(duì)MIPS的影響
MCU/SoC帶協(xié)處理器的情況并不少見。協(xié)處理器能并行處理某些高計(jì)算強(qiáng)度任務(wù),將CPU解放出來(lái)并提高處理器的MIPS效率。
我們不妨設(shè)想一下這樣一款應(yīng)用,其輸入音頻數(shù)據(jù)進(jìn)入后由ADC采樣,采樣頻率為44.1Ksps。假設(shè)我們希望抑制50或60HZ的直線頻率。為此,我們需要使用數(shù)字帶阻過(guò)濾器。
采樣速率:44.1Ksps,采樣間隔22.7uS
FIR過(guò)濾器抽頭數(shù):128
為了簡(jiǎn)化說(shuō)明,我們不考慮過(guò)濾器的輸出級(jí)。
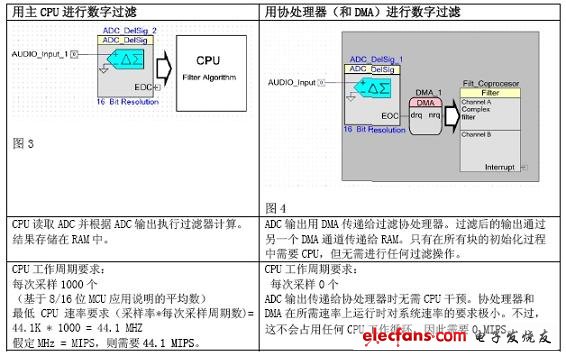
就上例而言,協(xié)處理器將CPU速率要求降低了44.1 MIPS。請(qǐng)注意,該示例采用了簡(jiǎn)單的FIR過(guò)濾器。如果需要更復(fù)雜的過(guò)濾器,那么MIPS要求可能會(huì)高得多(數(shù)百M(fèi)IPS)。
可編程數(shù)字器件對(duì)MIPS的影響
一些MCU/SoC器件的可編程數(shù)字邏輯為CPLD或FPGA邏輯形式,這使開發(fā)人員能用硬件實(shí)施CPU功能,而CPU功能傳統(tǒng)上是用軟件實(shí)施的。下面我們來(lái)看看可編程數(shù)字邏輯對(duì)MIPS有什么影響。
我們假設(shè)三相無(wú)電刷DC(BLDC)電動(dòng)機(jī)的轉(zhuǎn)速為30,000rpm。電動(dòng)機(jī)的轉(zhuǎn)動(dòng)要求脈沖時(shí)序。出于簡(jiǎn)化目的,我們還假定用霍爾感應(yīng)器來(lái)探測(cè)電動(dòng)機(jī)轉(zhuǎn)子的位置。三個(gè)這樣的霍爾感應(yīng)器用來(lái)實(shí)現(xiàn)上述目的。每轉(zhuǎn)60度,霍爾感應(yīng)器輸出之一就會(huì)發(fā)生變化。如果電動(dòng)機(jī)有兩個(gè)轉(zhuǎn)子極組,那么兩個(gè)電氣循環(huán)將對(duì)應(yīng)于一次機(jī)械轉(zhuǎn)動(dòng)。這就是說(shuō),就一次完整轉(zhuǎn)動(dòng)而言,霍爾感應(yīng)器輸出會(huì)改變12次。霍爾感應(yīng)器輸出導(dǎo)致6個(gè)PWM輸出變化。各帶配套輸出的三個(gè)PWM用于創(chuàng)建6個(gè)PWM輸出。下圖顯示了霍爾感應(yīng)器輸入同PWM輸出之間的關(guān)系。PWM值為正說(shuō)明PWM高壓側(cè)工作,值為負(fù)則說(shuō)明PWM低壓側(cè)工作。
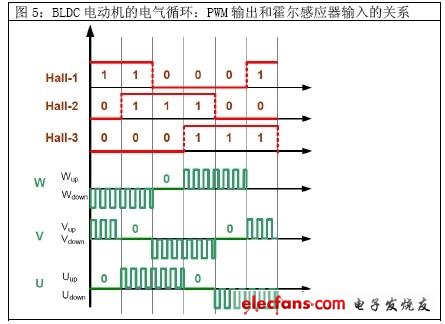
下面我們來(lái)分析通常如何實(shí)施BLDC轉(zhuǎn)換,以及如果器件具備可編程邏輯(CPLD或FPGA)功能,又將如何簡(jiǎn)化BLDC轉(zhuǎn)換。
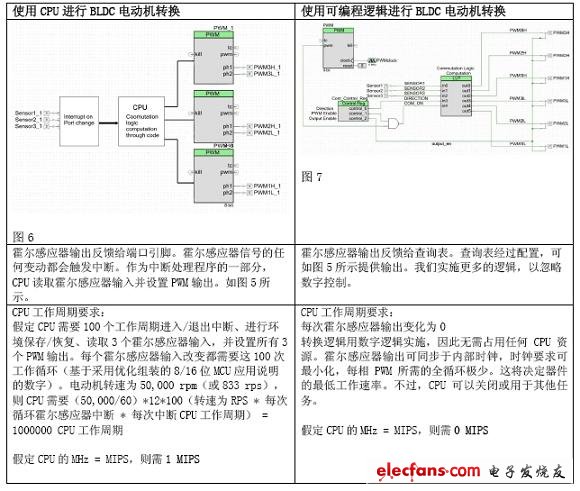
就上例而言,可編程數(shù)字技術(shù)將CPU速率要求降低了1MIPS。如果電動(dòng)機(jī)轉(zhuǎn)速較低,那么該技術(shù)對(duì)MIPS的影響也較低,反之亦然。上例采用了優(yōu)化組裝和簡(jiǎn)單的開環(huán)控制。實(shí)際應(yīng)用會(huì)更加復(fù)雜,且通常使用C代碼,以簡(jiǎn)化維護(hù)和再利用。如果使用一般性C代碼,則MIPS要求會(huì)增加到3 MIPS。幾乎所有電動(dòng)機(jī)控制應(yīng)用都需要類似于PID控制的多控制回路,這提高了計(jì)算要求。不過(guò),如果通過(guò)硬件來(lái)完成相同工作,那么就能確保CPU占用為零。因此,整個(gè)電動(dòng)機(jī)控制應(yīng)用的MIPS需求介于5到10 MIPS之間,而采用硬件方法,需求則為零。
基于可編程邏輯的實(shí)施方案具有較高的再利用性,且不存在任何集成問(wèn)題。實(shí)施一個(gè)電動(dòng)機(jī)控制所需的可編程數(shù)字邏輯要求非常低,因此我們能在硬件中實(shí)施多個(gè)電動(dòng)機(jī)控制和轉(zhuǎn)換邏輯。如果用CPU完成相同的工作,由于我們無(wú)法同時(shí)處理兩個(gè)中斷,那么MIPS需求就會(huì)增長(zhǎng)好幾倍。此外,為了保證合理的中斷響應(yīng)時(shí)間,CPU運(yùn)行速率必須比最低速率要求快得多。因此,我們能用可編程邏輯輕松地實(shí)施完整的BLDC電動(dòng)機(jī)控制系統(tǒng),比如4個(gè)這樣的系統(tǒng)。不過(guò),如果用MCU固件來(lái)實(shí)現(xiàn)相同的任務(wù),則需要約100 MIPS的性能。
正如本文所述,MIPS并不能代表MCU/SoC器件解決系統(tǒng)級(jí)問(wèn)題的真正能力。如果器件具備上述所有功能,那么什么樣的器件MIPS性能才適用呢?200 MIPS、500 MIPS還是1,000 MIPS?在所有情況下,MIPS不過(guò)是一個(gè)意義非常有限的數(shù)字而已。
那么,開發(fā)人員如何確定最適合應(yīng)用需要的器件呢?不幸的是,這個(gè)問(wèn)題并不太容易回答:
·確定應(yīng)用中存在關(guān)鍵計(jì)時(shí)或CPU性能要求的區(qū)域。
·確定MCU/SoC廠商是否提供應(yīng)用說(shuō)明或類似于您所需應(yīng)用的示例項(xiàng)目。如果已經(jīng)提供,則能為您針對(duì)既定MCU/SoC來(lái)優(yōu)化應(yīng)用的程度提供指導(dǎo)。如果沒有提供,則應(yīng)想辦法找到使用給定架構(gòu)實(shí)施應(yīng)用的潛在辦法,并了解您可使用哪些硬件特性。
·根據(jù)上述示例所示粗略估算MIPS性能要求。計(jì)算不必特別精確。您應(yīng)盡力確定潛在的巨大差距。在上述所有示例中,性能差異都已足夠大,精確計(jì)算已非必要。
·如果性能差距較小,比如在10%到20%之間,而工作任務(wù)是應(yīng)用的主要組成部分,則唯一的選擇是用廠商的開發(fā)工具包創(chuàng)建特定的實(shí)施方案,檢測(cè)實(shí)際性能差距。
·如果您計(jì)劃購(gòu)買大量器件,則有關(guān)要求可作為RFQ(詢價(jià)單)的一部分。這讓廠商能根據(jù)您的特定應(yīng)用提供器件性能相關(guān)信息。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論