 電子發燒友App
電子發燒友App


***這篇博客的所有內容都是約翰·馬爾姆寫的,博士。 約翰D.是數值分析和算法開發的專家。 他在Imagimob公司擔任機器學習開發人員***
我們生活在一個數據世界里。 幾乎每個人都在談論數據和我們可以從中提取的潛在價值。 大量的原始數據對我們來說是復雜和難以解釋的,在過去的幾年里,機器學習技術使我們有可能更好地理解這些數據,并利用來造福我們。 到目前為止,大部分價值都是由在線企業實現的,但現在價值也開始擴散到由傳感器生成數據的物理世界。 然而,對于許多人來說,從傳感器數據到嵌入式AI模型的路徑似乎幾乎是不可克服的。
Writing embedded software is notoriously time-consuming, and is known to take at least 10-20 times longer than desktop software 被發展的狀態開發區 [1]. It does not have to be that way. Here, we will walk you through a real AI project—from to embedded application—using our efficient, time-saving method.
機器學習的邊緣
今天,處理和解釋傳感器數據的絕大多數軟件都是基于傳統的方法:變換、濾波、統計分析等。 這些方法是由一個人設計的,他參考他們的個人領域知識,在數據中尋找某種“指紋。 通常,這種指紋是數據中事件的復雜組合,需要機器學習才能成功地解決問題。
To be able to process sensor data in real-time, the machine learning model needs to run locally on the chip, close to the sensor itself—usually called “the edge.” Here, we explain how a machine learning application can be created, from the initial data collection phase to the final embedded application. As an example, we look at a project we at Imagimob carried out together with the radar manufacturer Acconeer.
嵌入式AI項目:手勢識別
(左)Acconeer生產世界上最小、最節能的產品雷達系統。
在2019年,Imagimob與Acconeer合作,創建了一個帶有手勢識別的嵌入式應用程序。 兩家公司都專注于為小型電池供電設備提供解決方案,對能源效率、處理能力和BOM成本提出了極端要求。 我們的目標硬件包含一個基于ArmCortex-M0-M4架構的MCU,它提供了市場上最節能的平臺。 對于我們Imagimob來說,邊緣計算幾乎已經成為最小ArmCortexM系列MCU上的高級計算的同義詞。 重要的是,能夠運行我們的應用程序在下端的ArmCortexM系列MCU,因為它向世界表明,我們正在瞄準地球上最小的設備。 這就是我們希望從市場角度出發的地方。
Acconeer生產世界上最小、最節能的雷達系統。 數據包含大量信息,對于手勢控制等高級用例,需要復雜的解釋。 在數據輸出流的頂部運行機器學習軟件對這些案例有很大的好處。 因此,Imagimob-Aconeer協作在創建全新的和創造性的嵌入式應用程序方面是一個很好的匹配。
我們與Acconeer的項目的目標是創建一個嵌入式應用程序,該應用程序可以使用雷達數據實時分類五種不同的手勢(包括用于喚醒應用程序的一個手勢)。 由于雷達體積小,可以放置在一對耳機中,手勢將作為虛擬按鈕來引導功能,通常被編程成物理按鈕。 該項目的最終產品被確定為一個運行在ArmCortex-M4架構上的C庫,該庫于2020年1月在拉斯維加斯的CES上被展示為一個健壯的現場演示。 對于演示,我們使用耳朵耳機。 然而,我們的長期產品目標是在耳內耳機中使用這項技術。 我們認為,手勢檢測特別會改變耳內耳機的可用性,因為它們的面積有限,這使得物理按鈕的放置變得困難。
從數據收集到嵌入式C庫
在其核心,(監督)機器學習是關于找到一個函數(F),根據y=f(X)將一些輸入數據(X)映射到一些輸出數據(Y)。 該函數或“模型”是通過處理許多不同的輸入/輸出對(x,y)和“學習”它們之間的關系來找到的。 如果y是一個連續的值,那么這個問題被稱為回歸問題。 但如果y取離散值,則被認為是一個分類問題。 因此,機器學習項目的第一步是收集這些數據對。 模型構建是第二步。 嵌入式項目的最后一步是在目標平臺上部署模型。 下面,我們以手勢識別項目為指導示例,通過這些步驟。
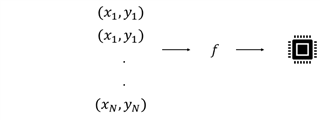
機器學習項目的第一步是收集數據對。 模型構建是第二步,a嵌入式項目的最后一步是在目標平臺上部署模型。
1.數據收集
(左)我們為初始階段建造了一個粗糙的試驗臺data collectionwhich 由雷達傳感器組成 安裝在上面development 板和放置在一個 一對耳機。
從表面上看,數據收集似乎不是一項艱巨的任務。 但這一步通常被低估了,根據我們的經驗,這是大部分時間都花在這里的。 首先要考慮的是如何從傳感器中物理地獲取數據。 許多傳感器帶有一個開發板,可以從中提取數據,通常是通過某種電纜連接到PC機。 對于手勢識別項目,我們搭建了一個粗糙的試驗臺,用于初始數據采集,由安裝在開發板上的雷達傳感器組成,放置在一對耳機上,如下圖所示。 在這種情況下,我們使用了AcconeerXM112雷達傳感器和XB112突破板。
?
接下來要考慮的是如何有效地標記數據。 換句話說,你需要弄清楚如何為每個“x”標記適當的“y”。這可能看起來很瑣碎,但當涉及到最小化這一步所需的人工工作量時,這是至關重要的。 考慮到大量的數據,如果您不能正確地理解這一點,它將成為一項非常耗時的任務。 對于傳感器時間序列數據,通常不可能僅僅通過查看數據來標記數據,否則,例如圖像數據可能是可能的。
幫助標記過程的一種方法是將視頻記錄附加到數據中。 ImagimobCapture是一個Android應用程序,它將同步視頻記錄附加到每個傳感器數據流中。 標簽可以直接在應用程序中完成,也可以在桌面應用程序ImagimobStudio中完成。 在我們的雷達手勢識別項目中,數據流看起來如下:
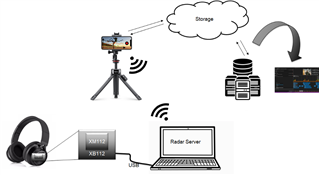
雷達手勢識別項目中的數據流。
在這里,數據從傳感器,帶有USB串口,發送到PC。 在PC上,服務器運行并將數據發送到手機上的ImagimobCapture,而手勢則被視頻記錄。 標記的數據,連同其視頻記錄,然后發送回PC,或云存儲,如果數據是遠程收集。 從存儲中,數據可以下載到ImagimobStudio,當它是建模階段的時候。
我們定義了以下一組手勢(“覆蓋傳感器”僅用于喚醒應用程序),并記錄了大約七個不同的人的數據。

從七個不同的人記錄了上述一組手勢的數據。
數據收集過程的一個例子如下圖所示。 手勢識別模型僅限于特定的手勢,但可以很容易地用其他手勢進行再訓練。
手勢數據采集過程的一個例子。
2. 建模
一旦數據到位并貼上標簽,就該建立機器學習模型了。 通常,人們開始建立模型只是為了很快意識到他們需要調整一些標簽。 你是做什么的? 手動進入并編輯文本文件和更新數據是很麻煩的,這是我們都希望盡可能避免的。 相反,圖形工具是可取的。 Imagimob Studio將數據與視頻記錄一起加載,并允許用戶以圖形方式拖動和修剪標簽。 一個例子,以一個記錄的手勢,顯示在下面的圖像。 視頻與綠色數據一起可見。 在底部,藍色的標簽顯示出來,我們可以看到它們緊緊地放在手勢周圍(非零數據)。
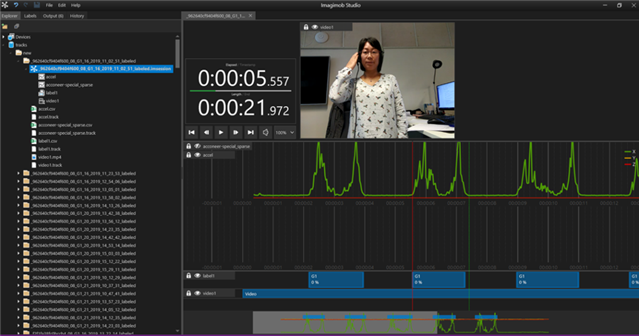
Imagimob Studio將數據與視頻記錄一起加載,并允許用戶以圖形方式拖動和修剪標簽。 這是一個有記錄的手勢的例子。
如果數據已經在ImagimobCapture中預先標記,那么通過文件并確保數據是正確的,并且標簽已經到位,這是一個相對較小的任務。 沒有正確標記的數據,很難找到一個好的模型。 找到一個高精度的好模型通常需要多次迭代和實驗。 首先要決定使用什么機器學習技術,例如隨機森林、支持向量機或人工神經網絡等。 在過去的幾年里,深度學習由于具有原始數據的令人印象深刻的學習能力而受到歡迎。 深度學習的主要吸引力之一是它排除了手動查找功能的需要,這是更傳統的機器學習方法所需要的。 它具有提高精度和消除大量手工工作的潛力。 然而,仍有許多所謂的超參數有待選擇,例如網絡的體系結構、所謂的學習率和許多其他參數。
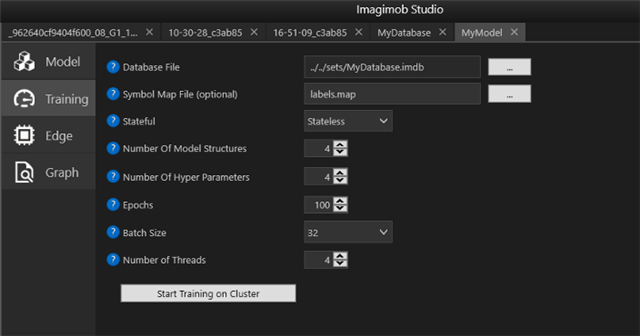
在ImagimobStudio中,用戶經歷了構建深度神經網絡的過程。 用戶定義要試用多少種不同類型的超參數,然后程序自動搜索所有組合并保存最佳模型。
在ImagimobStudio中,用戶被引導通過構建深度神經網絡的過程。 用戶定義要試用多少種不同類型的超參數,然后程序自動搜索所有組合并保存最佳模型。
一旦您對模型的健壯性感到滿意,就該是過程中的最后一步了:將模型導出到C代碼并為嵌入式硬件構建庫。
3. 部署
當從PC環境中的高級語言軟件開發到微控制器(MCU)上的低級編程時,復雜性急劇增加。 發育時間增加的因子為10-20并不少見[1]。 例如,障礙可能包括更難的內存和處理限制,更長的調試周期,以及更難找到的更糟糕的錯誤類型。
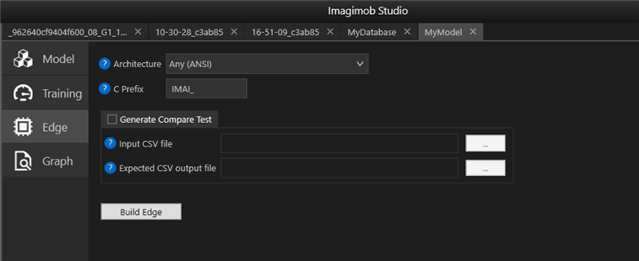
在ImagimobStudio中,以.h5文件形式訓練的模型很容易轉換為特定硬件類型的C代碼,如“Edge”選項卡所示。
在ImagimobStudio中,以.h5文件形式(用于從Tensorflow、Keras和其他深度學習框架導出模型權重和體系結構的通用格式)的經過訓練的模型可以很容易地轉換為特定硬件類型的C代碼,如上一幅圖像中的“Edge”選項卡所示。
然后編譯C代碼并將其閃爍到硬件上。 我們通常構建一個庫,可以集成到C應用程序中。 右邊,可以看到現場演示的嵌入式版本。它有一個電池驅動的Acconeer物聯網模塊XM122與藍牙連接。 人工智能應用程序運行在XM122模塊上,其中包括來自北歐半導體的NRF52840SoC,該模塊基于ArmCortexM4MCU。
現場演示的嵌入式版本。
在這里,你可以看看最后的演示:
Imagimob手勢檢測庫規范
圖像手勢檢測庫的核心是針對時間序列數據的人工神經網絡。 它是專門設計的,腦海中有一個小的記憶足跡。 庫用C編寫并在靜態庫中編譯,然后與主AcconeerC應用程序一起編譯。
· The Gesture detection library uses radar data from the Acconeer XM122 IoT Module as input
· The memory footprint of the gesture library is approximately 80 kB RAM
· The library runs on a 32-bit 64 MHz Arm Cortex M4 MCU with 1 MB Flash and 256 kB RAM
· The library processes roughly 30 kB of data per second
· The execution time of the AI model is roughly 70 ms which means that it predicts a gesture at approximately 14.3 Hz
下一步:手勢控制的內置耳機
在2020年6月,由Imagimob、Acconeer和Flexworks組成的一個財團從瑞典Vinnova獲得了價值45萬$的贈款,以采取下一步建設gesturhe控制的耳內耳機。 Acconeer將覆蓋傳感部分,Flexworks將負責硬件和力學,我們在Imagimob將開發手勢檢測應用程序。 在這個項目中,我們不僅將建立第一個手勢控制的耳內耳機,而且我們還將致力于一個硬件加速系統的機器學習代碼在單片機上。 我們將繼續使用ArmCortexM系列,并受益于Arm提供的先進解決方案。
約翰·馬爾姆博士。 D.是數值分析和算法開發的專家。 他在Imagimob擔任機器學習開發人員。
證明書(幫助或意見的)征求
[1]McConnell,史蒂夫,軟件估計,神秘的黑色藝術,微軟出版社,2006年







 工商網監
工商網監
評論