 電子發燒友App
電子發燒友App


隨著 SoC 芯片性能的提高,各模塊間的數據交換成為提高微處理器系統運行速度的瓶頸。DMA 控制器能夠有效替代微處理器的加載/存儲指令,顯著提高系統的并行能力。傳統的 DMA 的結構專用性強而可擴展性不足[1~3]。在高速并行系統中,單時鐘域的設計已不能有效控制功耗的增長。面對 SoC 不斷擴大的規模,還必須設計一種動態配置 DMA 通道的結構以提高邏輯資源的利用率。本文介紹了在 0.18um 工藝下,面向完整的 AMBA 總線結構的高性能 32 位 DMA 控制器的 ASIC 實現,提出了使用雙時鐘域配合具有同步復位的門控時鐘(Gated Clock)實現功耗控制的方法。握手信號路由陣列的設計使得有限數量的通道可以匹配更多的總線外設。
VLSI是超大規模集成電路(Very Large Scale Integration)的簡稱,指幾毫米見方的硅片上集成上萬至百萬晶體管、線寬在1微米以下的集成電路。由于晶體管與連線一次完成,故制作幾個至上百萬晶體管的工時和費用是等同的。大量生產時,硬件費用幾乎可不計,而取決于設計費用。
超大規模集成電路是70年代后期研制成功的,主要用于制造存儲器和微處理機。64k位隨機存取存儲器是第一代超大規模集成電路,大約包含15萬個元件,線寬為3微米。目前超大規模集成電路的集成度已達到600萬個晶體管,線寬達到0.3微米。用超大規模集成電路制造的電子設備,體積小、重量輕、功耗低、可靠性高。利用超大規模集成電路技術可以將一個電子分系統乃至整個電子系統“集成”在一塊芯片上,完成信息采集、處理、存儲等多種功能。例如,可以將整個386微處理機電路集成在一塊芯片上,集成度達250萬個晶體管。超大規模集成電路研制成功,是微電子技術的一次飛躍,大大推動了電子技術的進步,從而帶動了軍事技術和民用技術的發展。超大規模集成電路已成為衡量一個國家科學技術和工業發展水平的重要標志。也是世界主要工業國家,特別是美國和日本競爭最激烈的一個領域。超大規模集成電路將繼續得到發展。
DMA 結構的比較
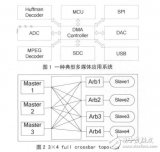
AMBA是 ARM 公司提出的用于微處理器片上通信的先進的總線結構。一種典型的 AMBA 總線由 AHB 和 APB 總線分段構成。總線上的設備可以分為能夠主動讀寫的主設備(Master)與只能接收來自 Master 請求的從設備(Slave)。
近來針對 DMA 控制器的研究引出了新的 SoC 架構,如使用分布式 Flyby DMA 結構[1];為數據吞吐量大的模塊預設專用通道[2,3]等。這些結構的共同點在于數據在搬移過程中不需要經過緩存就可以達到指定地址。然而缺乏緩存結構的 DMA 有一定的局限性。從應用的角度來講,在音視頻編解碼程序中普遍存在同端口內存數據塊搬移的操作,而非緩存結構的 DMA 無法在同端口上實現單周期的先讀后寫操作。此外,在 APB 總線上只能存在一個 Master 設備,所以既無法為每個外設配置獨立 Master 以獲取數據,也不可能在低速總線上完成單周期傳輸。從功耗的角度看,當系統中存在較多 Master 模塊時,總線仲裁器的負擔就被加重,而仲裁器正是AMBA 總線功耗的主要來源。使用緩存結構的系統級 DMA 盡管存在數據傳輸的延時,但能適用于 AMBA 不同速度的分段總線,可擴展性遠高于非緩存結構 DMA。
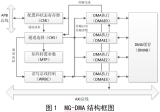
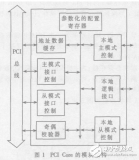
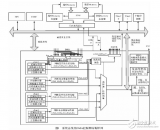
如圖 1 所示,本文提出的 DMA 控制器在整個系統中可分為 3 個部分。DMA Master 端解析來自當前通道的命令包并發出 AHB 總線請求,完成緩存區與 AHB 總線的數據交換。 DMA 的引擎(DMA Engine)包含各個通道的邏輯資源與雙口緩存結構(Dual Port FIFO)及相應的控制邏輯。DMA 控制器的 APB Master 發出 APB 的總線請求,這些信號與來自 AHB 的轉換信號一起在兩段總線的橋接(Bridge)部分進行仲裁選擇,實現 APB 總線與 DMA 緩存區的數據交換。
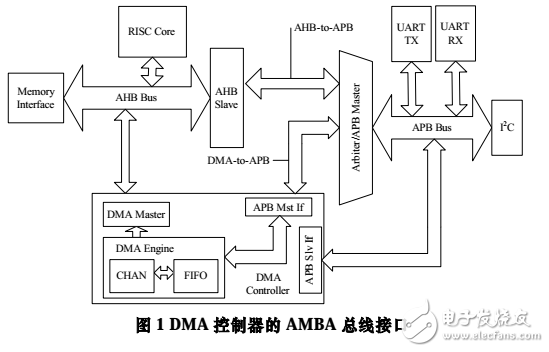
DMA 控制器的 VLSI 實現
DMA 的時鐘域
在不具備 DMA 的 AMBA 總線中,APB 唯一的 Master
在 AHB 總線的驅動下進行數據傳輸。兩段總線以串行的方式工作。從表 1 中可知,由于在 AMBA 結構中微處理器不提供對 APB 的 Burst 操作,完成對 APB 的 4 個 Word 的傳輸,至少需要 20 個 AHB 的時鐘周期。而當存在 DMA 控制器時, APB 總線能緩存需要和 AHB 交換的數據,并且可以獨立地驅動數據傳輸。不僅使傳輸周期減少了 50%,而且實現了 APB與AHB 的并行運行。
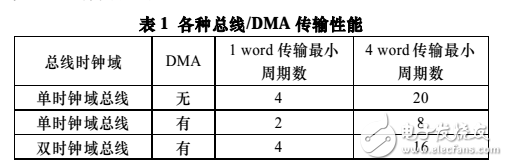
由于并行的實現,APB 總線上某些時間段中數據傳輸更加頻繁。DMA 的 APB 信號進入總線以前必須經過仲裁,當使用類似于高速總線上的 Burst 模式時,APB 可以多個連續兩周期的傳輸來運行,這增加了互連線的翻轉頻率。尤其在 DMA 多個通道相互交替占有 APB 時,這種翻轉間隔便被縮小。因此,依據功耗 P = CV 2 f ,AHB 總線的二分頻時鐘被用來驅動 APB 總線。在這種配置下,相對于使用指令集進行的傳輸依然持有速度上的優勢。
DMA 的內部結構
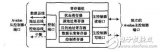
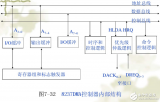
DMA 控制器的核心部分圍繞通道狀態機和雙口緩存數據的 FIFO 結構來設計。如圖 2 所示,功能模塊包括非整字地址對齊邏輯(Read/Write Aligner)、64×32bit 雙口 FIFO、FIFO 控制邏輯、DMA 引擎、DMA 握手信號路由器(HandshakeRouter)和功耗管理電路。其中 DMA 引擎又包括 DMA 通道狀態機邏輯和通道仲裁器(Chan Arb)。
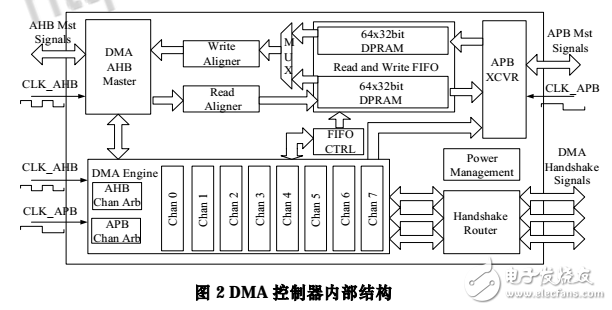
雙時鐘域設計的難點在于時鐘域的劃分以及不同時鐘的相位要求。從圖 2 中可以看到,DMA 的數據通路部分由 2 個總線接口及 2 塊 64×32bit 的雙口 SRAM 組成,其中 DMA Master 接口與數據對齊邏輯由 CLK_AHB 來驅動,而 APB 端由 CLK_APB 來驅動。DMA 的通道根據數據流方向共分為兩種:一種控制 AHB 上模塊的數據交換;另一種控制 AHB 與 APB 上模塊的數據交換。
為了減小面積,利用 APB 時鐘是 AHB 時鐘二分頻的特點,將兩種不同類型的通道復用同一個存儲端口。這樣,兩種通道的狀態機邏輯中使用各自的時鐘產生 SRAM 讀寫地址與控制信號。為了支持多通道獨立讀寫操作以提高并行度,每個 AHB 與 APB 交換數據的通道必須使用讀寫獨立的SRAM。這樣,使用 2 塊雙口 SRAM 實現了不同時鐘域緩存共享。每個通道擁有 2 塊 8×32bit 的不同流向的緩存容量,以匹配 DMA 的 AHB Master 端最高支持 4 個 Word 的 Burst操作。
DMA 通道的狀態機與仲裁
DMA 的通道是指能夠控制數據從起點傳輸到終點的邏輯資源以及相應的緩存空間。圖 3 展示了兩種類型通道在傳輸數據過程中的狀態機變化。其中虛線對應 AHB 到 AHB 的通道,實線對應 AHB 與 APB 間數據交換的通道。
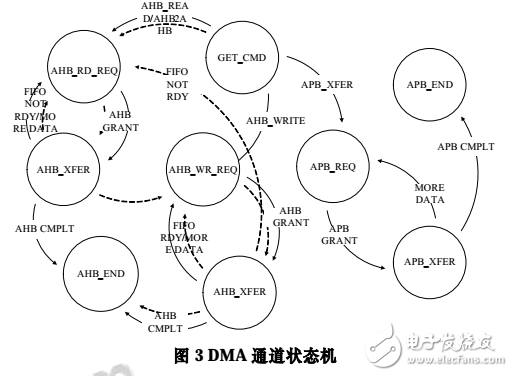
AHB 與 APB 的數據交換以接收來自 AHB 的命令符作為傳輸的開始。AHB 和 APB 能夠根據當前的緩存充溢情況獨立地發出總線請求。于是相應的邏輯各自進入 AHB_RD(WR)_REQ 和 APB_REQ 狀態,并根據目的地址與當前剩余的傳輸字節數來調整單次傳輸的字節。DMA 的 AHBMaster 和 APB Master 在狀態機的控制下,獨立地對 Read FIFO 或 Write FIFO 的一個端口進行操作。
類似地, AHB 數據通道在接收命令符以后,進入AHB_RD_REQ 狀態,在 FIFO 不足半滿的情況下,APB Mst從起始地址讀出數據放入緩存;在 FIFO 超過半滿的Signals情況下,AHB_WR_REQ 狀態從緩存中取出數據送至的地址。
由于在同一時刻只能有一個通道占有 AHB 或APB 總線,DMA 多通道的總線請求必須經過仲裁器的仲裁。根據文獻[6]的分析,Round Robin 策略在相應多設備的請求中能最有效地利用已知帶寬。為了讓AHB 的傳輸減少延時,在不同類型通道間使用固定優先級。在同類型通道間,使用 Round Robin 策略使各設備有相同幾率被服務。
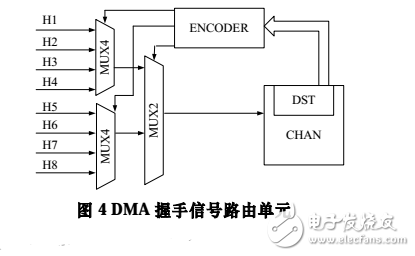
DMA 握手信號路由陣列
當 AMBA 總線上的外設數量增加時,數據源設備與目標設備之間的對應關系也隨著數量線性增加。必須設計一種可以動態配置每個通道占有設備的方法,以減少通道的數量。
本文提出了一種基于握手信號路由陣列動態配置通道的方法。 DMA 的握手信號控制著通道起始和終止狀態。 DMA_REQ 信號是目標設備對 DMA 控制器的輸入,標識可以開始傳輸數據。當傳輸完成后,目標設備發出 DMA_ CMD_END 信號以通知 DMA 結束傳輸過程。由于目標設備處理總線數據的速度可能低于總線的傳輸速度,因此通常在總線接收端使用小規模的緩存。而握手信號即用來控制緩存數據不會在進入處理流程之前被來自總線的新數據覆蓋。
圖 4 展示了連接 8 個總線外設的 DMA 控制器的握手信號路由陣列的單元。2 個二級選擇器陣列分別用作 2 個握手信號的路由。H1~H8 是來自目標設備的握手信號。每個通道使用 2 個 4 選 1 和 1 個 2 選 1 的選擇器級聯成一個單元來從 8 個握手信號中選出當前占有通道設備的信號。在命令字獲取階段得到的目標設備地址映射為一個 8bit 的信號(如00000001,00000010),輸入 8/3 編碼器來產生陣列的選擇信號。當系統具有 16 個總線外設時,陣列單元為 4 個 MUX4、 2 個 MUX2 和最后一個 MUX2 的三級級聯,以此類推。
2.4 功耗管理和同步復位的實現
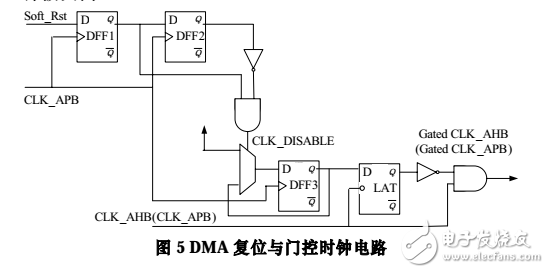
在 0.18μm 的工藝下,由于時鐘樹的反轉引起的電容充放電對功耗的貢獻達到了整體功耗的 30%~40%。一種有效的遏制此類功耗的方法是采用門控時鐘。使用低電平有效的鎖存器和與門串連的方法得到門控時鐘,可以避免時鐘毛刺的產生。
由于時鐘無效以后 DMA 模塊進入狀態鎖存,在下一次時鐘有效時,系統將以上一次時鐘關閉時鎖存的狀態進入運行。為了避免一個不確定的狀態在關閉時鐘時被鎖存,同步復位的電路將在時鐘關閉之前先復位所有觸發器電路。如圖 5 所示,一個兩級移位寄存器電路的輸出用來產生門控時鐘的使能信號 CLK_DISABLE。當 Soft_Rst 信號為低時,門控時鐘的使能信號為 0,DFF3 輸入為 0,時鐘正常輸入。當需要關閉時鐘時,Soft_Rst 先通過 APB 總線被寫高,在第 1 個 APB 時鐘周期后,模塊同步復位成功且 Soft_Rst 已經移位至 DFF1 的輸出,隨后組合邏輯把使能信號拉高,DFF3 的輸入信號為 1。在第 2 個 APB 時鐘上升沿,DFF3 輸出為高,在隨后到來的相應時鐘域的低電平時段,LAT 通路,于是時鐘被關閉。
仿真結果與性能
經過 Design Compiler 邏輯綜合,DMA 控制器在 SMIC 0.18um 的工藝下,能夠達到 AHB 時鐘域 180MHz,APB 時鐘域 90MHz 的工作頻率。
ALP3310 是基于 AMBA 總線開發并采用了該 DMA 控制器的 32 位 RISC 處理器,含有 UART、I2C 等 16 個總線外設。DMA 控制器具有 2 個 AHB 數據通道,6 個 AHB 與 APB的數據通道。
不同的內部結構和系統仲裁的實現都會影響 DMA 的總線占有率。仿真表明,忽略 AHB 總線競爭以及 DMA 內部通道競爭的影響,DMA 的 AHB 端口平均每 10 個 AHB 周期可以完成 4 個 Word 的傳輸,達到約 280MB/s 的傳輸速度。
在 AHB 和 APB 上對比 DMA 與軟件傳輸數據的速度。在 AHB 上,分別用微處理器和 DMA 將 SRAM 中的 128 個字節的數據搬移到 SRAM 的另一段地址中。如表 2 所示,DMA 的 AHB 傳輸對比軟件傳輸具有 80.0%的速度優勢。
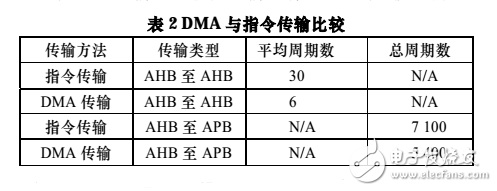
對于 APB 的傳輸,通過微處理器直接寫 APB 外設花費了 7 100 個 AHB 周期。而寫入 SRAM 僅花費了 5 400 個 AHB周期,并且微處理器隨即被釋放,剩余的工作由 DMA 完成,從而減少了 26.7%的傳輸時間。
本文提出了面向 AMBA 總線的 32 位高性能 DMA 控制器的設計方法,引入了雙時鐘域、同步復位門控時鐘和握手信號路由陣列的設計,并根據仿真結果進行了性能分析。實驗結果表明,采用了該 DMA 控制器的 32 位 RISC 處理器 ALP3310 的總線傳輸速度得到大幅提高。












 工商網監
工商網監
評論