 電子發(fā)燒友App
電子發(fā)燒友App


會上,Top500組織發(fā)布了半年度全球最快超級計算機排行榜,AMD 驅(qū)動的 Frontier 超級計算機以 1.194 Exaflop/s (EFlop/s) 的性能穩(wěn)居榜首,擊敗了一半的超級計算機。而來自阿貢國家實驗室基于英特爾的 Aurora 超級計算機提交的規(guī)模為 585.34 Petaflop/s (PFlop/s)。
阿貢提交的方案僅采用了?Aurora?系統(tǒng)的一半,在 Top500 中排名第二,取代日本的?Fugaku,成為世界上第二快的超級計算機。英特爾還推出了 20 款基于 Sapphire Rapids CPU 的新型超級計算機進入榜單,但 AMD 的 EPYC(霄龍)繼續(xù)占據(jù) Top500 的位置,目前為榜單上的 140 個系統(tǒng)提供支持,同比增長 39%。
英特爾和阿貢國家實驗室目前仍在努力讓 Arora 在 2024 年全面上線。Aurora 提交代表了 10,624 個英特爾 CPU 和 31,874 個英特爾 GPU 協(xié)同工作,以總共 24.69 兆瓦 (MW) 的功率提供 585.34 PFlop/s。相比之下,AMD 的 Frontier 以 1.194 EFlop/s 的性能奪冠,這是 Aurora 性能的兩倍多,但消耗的能源卻相對較少,為 22.70 MW(是的,完整的 Frontier 超級計算機的功耗還不到 Aurora 系統(tǒng)的一半)。Aurora 在本次提交中并未進入 Green500(最節(jié)能的超級計算機名單),但 Frontier 繼續(xù)在該名單上排名第八。
然而,Aurora 在完全上線后預(yù)計最終將達到 2 EFlop/s 的性能。完成后,Auroroa 將擁有 21,248 個 Xeon Max CPU 和 63,744 個 Max 系列“Ponte Vecchio”GPU,分布在 166 個機架和 10,624 個計算刀片上,使其成為世界上已知最大的 GPU 單一部署。該系統(tǒng)利用 HPE Cray EX(Intel Exascale 計算刀片)并使用 HPE 的 Slingshot-11 網(wǎng)絡(luò)互連。
AMD 正在勞倫斯利弗莫爾國家實驗室部署 El Capitan ,預(yù)計其速度比 Aurora 更快,性能可達 2 EFlop/s+。因此,英特爾不斷推遲的Aurora 可能永遠不會在 Top500 榜單上占據(jù)第一的位置——下一輪 Top500 提交的競賽肯定會在 2024 年 6 月開始。
2018 年。當(dāng)時,系統(tǒng)設(shè)計為使用 Knights Hill 處理器,后來被取消。此后的幾年里,該系統(tǒng)經(jīng)歷了多次重新設(shè)計和重新安排, 新的 Aurora 于 2019 年宣布, 將于 2021 年提供 1 exaflop 的性能。2021 年末的另一次重新安排聲稱該系統(tǒng)在完成后將提供 2 exaflop 的性能,這是現(xiàn)在定于明年進行,英特爾、阿貢和慧與將繼續(xù)致力于系統(tǒng)驗證、驗證以及在新系統(tǒng)中擴展工作負載。您可以在此處查看Argonne 今天分享的其他 Aurora 基準(zhǔn)測試。
與此同時,部署在Azure云中的微軟新Eagle超級計算機目前已占據(jù)排行榜第三位,將日本富岳推至排行榜第四位。Eagle是第一個突破前十的云系統(tǒng)。芬蘭卡亞尼的 LUMI 系統(tǒng)以 379.70 PFlop/s 的性能躋身前五。
英特爾運行 1 萬億參數(shù)模型的超算
在 Supercomputing 2023 上,英特爾提供了有關(guān)其最新 HPC 和 AI 計劃的大量更新,包括有關(guān)第五代 Emerald Rapids 和未來 Granite Rapids Xeon CPU、Guadi 加速器、針對Nvidia H100 GPU 的新Max 系列 GPU 基準(zhǔn)測試的新信息,以及公司在Aurora 超級計算機上運行的“genAI”1 萬億參數(shù)人工智能模型的工作。
完成后,人們普遍預(yù)計 Aurora 將以 2 Exaflop/s (EFlop/s) 的性能奪得世界上最快的超級計算機的桂冠。然而,英特爾尚未透露有關(guān) Aurora 正式提交 Top500 名單的基準(zhǔn)測試的詳細信息,該公司表示將把該公告留給能源部和阿貢國家實驗室。如果按照慣例,Top500 組織將在今天晚些時候發(fā)布這些備受期待的結(jié)果。與此同時,英特爾的更新包含了大量值得仔細研究的新花絮。

滿負荷運行時,英特爾 Aurora 超級計算機將配備 21,248 個配備 HBM2E 的 Sapphire Rapids Xeon Max CPU 和 60,000 個 Xeon Max GPU,使其成為世界上已知的最大 GPU 部署。如前所述,英特爾尚未發(fā)布 Top500 提交的基準(zhǔn)測試,但該公司確實分享了一些工作負載的性能以及系統(tǒng)運行的部分補充。
英特爾和阿貢國家實驗室在 genAI 項目中測試了 Aurora,這是一個萬億參數(shù) GPT-3 LLM 基礎(chǔ)人工智能模型。由于數(shù)據(jù)中心 GPU Max“Ponte Vecchio”GPU 上存在大量內(nèi)存,Aurora 可以運行僅包含 64 個節(jié)點的大型模型。Argonne 已在總共 256 個節(jié)點上并行運行該模型的四個實例。調(diào)整工作負載后,該工作負載最終將擴展到 10,000 個節(jié)點。
英特爾還強調(diào)了藥物篩選人工智能推理應(yīng)用程序 ESP-ML 中從 128 個節(jié)點到 256 個節(jié)點的強勁擴展,但 Argonne 針對競爭對手 GPU 的基準(zhǔn)測試更有趣:英特爾聲稱,在使用 PyTorch/FP32 進行 CosmicTagger 訓(xùn)練時,單個 Max 1550 GPU 比 AMD MI250 加速器提速 56%,比 Nvidia 上一代 A100 GPU 具有 2.3 倍的優(yōu)勢。結(jié)果還表明強大的擴展性,六 GPU Sunspot 測試節(jié)點表現(xiàn)出 83% 的性能擴展。結(jié)果,Sunspot 節(jié)點的性能是使用未知 GPU 的四 GPU AMD 測試系統(tǒng)的兩倍多,是使用更老的 Polaris 的四 GPU 節(jié)點性能的五倍。
阿貢國家實驗室還在模擬小鼠大腦的大腦連接組工作負載 (Connectomics ML) 中測試了 512 個 Aurora 節(jié)點與 475 個節(jié)點的 Polaris 的對比,突顯了其比 Polaris 的 2 倍優(yōu)勢。
英特爾的數(shù)據(jù)中心路線圖仍在按計劃進行,第五代 Emerald Rapids 芯片定于 12 月 14 日推出。英特爾公布了旗艦級 64 核 Xeon 8592+ 與其前身 56 核第四代 Xeon 8480+ 的基準(zhǔn)測試結(jié)果。與往常一樣,使用供應(yīng)商提供的基準(zhǔn)測試(您可以在本文的最后一個專輯中找到測試說明)。
正如您對更高內(nèi)核數(shù)量的期望,8592+ 在 AI 語音識別和 LAMMPS 基準(zhǔn)測試中實現(xiàn)了 1.4 倍的增益,同時在 FFMPEG 媒體轉(zhuǎn)碼工作負載中實現(xiàn)了 1.2 倍的增益。
英特爾還提供了其未來 Granite Rapids Xeon 的性能預(yù)測,該處理器將在“Intel 3”節(jié)點上生產(chǎn)。這些芯片將添加更多內(nèi)核、更高頻率、FP16 硬件加速,并支持 12 個內(nèi)存通道,包括可極大提高內(nèi)存吞吐量的新型MCR 內(nèi)存 DIMM 。總而言之,英特爾聲稱 AI 工作負載提高了 2-3 倍,內(nèi)存吞吐量提高了 2.8 倍,DeepMD+LAMMPS AI 推理工作負載提高了 2.9 倍。
英特爾配備 HBM2E 的 Xeon Max CPU 現(xiàn)已發(fā)貨。英特爾將其配備 64GB 封裝?HBM?內(nèi)存的 56 核 Intel Max 9480 與 AMD 96 核 EPYC 9654 進行了正面交鋒。英特爾為這一系列基準(zhǔn)測試選擇的工作負載由以下目標(biāo)用例組成:內(nèi)存受限的應(yīng)用自然會讓 Xeon 芯片受益。總體而言,英特爾聲稱在模擬、能源、材料科學(xué)、制造和金融服務(wù)工作負載等一系列工作負載中,比 EPYC 競爭者平均有 1.2 倍的優(yōu)勢。
英特爾分享了有關(guān)即將推出的 Gaudi 3 的一些細節(jié),這將標(biāo)志著該公司將其 Gaudi 和 GPU 系列合并為一個單一產(chǎn)品——Falcon Shores之前的最后一款 Guadi 加速器。5nm Gaudi 3 在 BF16 工作負載方面的性能是 Gaudi 2 的四倍,網(wǎng)絡(luò)性能是 Gaudi 2 的兩倍(Gaudi 2 具有 24 個內(nèi)置 100 GbE RoCE 網(wǎng)卡),HBM 容量是 Gaudi 2 的 1.5 倍(Gaudi 2 具有 96 GB 的 HBM2E)。正如我們在圖中看到的那樣,Gaudi 3 轉(zhuǎn)向了具有兩個計算集群的基于圖塊的設(shè)計,而不是英特爾為 Gaudi 2 使用的單芯片解決方案。英特爾一直在緩慢提供有關(guān)其未來 Falcon Shores GPU 的詳細信息。
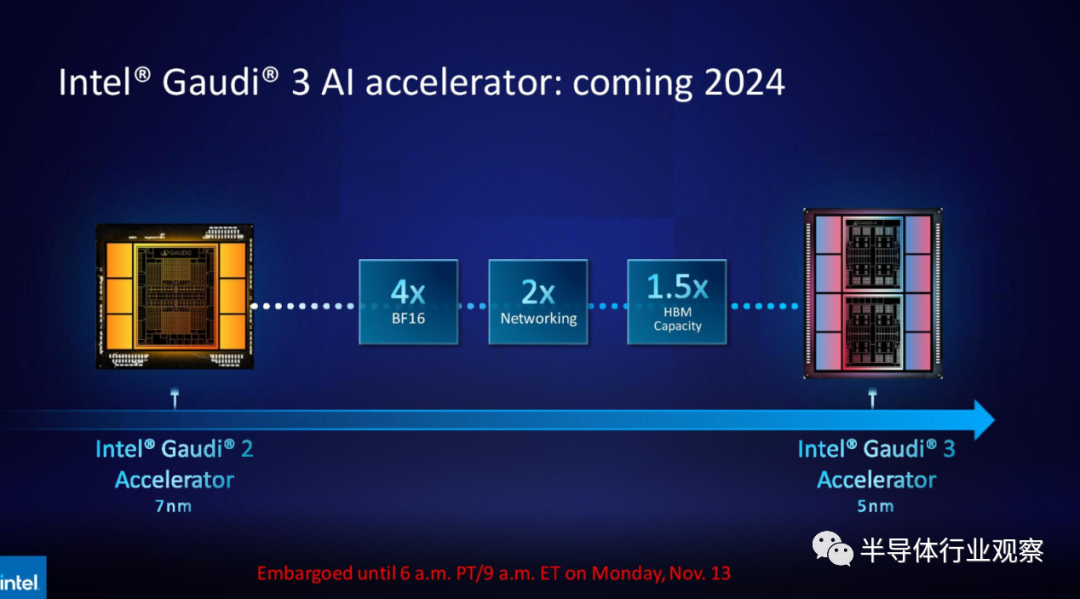
但英特爾重申,盡管合并了 Habana Gaudi IP 和 Xe GPU IP 的各個方面,但基于圖塊的 Falcon Shores 將通過 OneAPI 編程接口將外觀和功能視為單個 GPU。Falcon Shores 將采用 HBM3 內(nèi)存和以太網(wǎng)交換,并支持?CXL?編程模型。此外,針對 Gaudi 加速器和 Xeon Max GPU 進行調(diào)整的應(yīng)用程序?qū)⑴c Falcon Shores 向前兼容,從而為客戶提供兩個截然不同的 GPU 和 Gaudi 系列之間的代碼連續(xù)性。
此外,英特爾的數(shù)據(jù)中心 GPU Max 系列現(xiàn)已向客戶發(fā)貨,Supermicro 提供具有 8 個 OAM 規(guī)格 GPU 的系統(tǒng),而戴爾和聯(lián)想則提供 4 個 OAM GPU 服務(wù)器。GPU Max 系列 1100 PCIe 卡也可從多個供應(yīng)商處廣泛獲得。
英特爾的基準(zhǔn)測試將 OAM 外形尺寸的 Max 1550(600W GPU)與 Nvidia 的 PCIe 外形尺寸 H100(350W 競爭對手)進行比較。因此,這些基準(zhǔn)測試并不是比較性能的良好試金石。英特爾表示,基準(zhǔn)差異的原因是難以獲得 OAM 外形 H100 GPU。
現(xiàn)在我們正在等待阿貢國家實驗室提交的 Aurora 超級計算機 Top500 提交,看看英特爾能否取代 AMD 驅(qū)動的 Frontier,成為世界上最快的超級計算機。預(yù)計該更新將于今天晚些時候進行。
編輯:黃飛
?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論