首款POWER8應(yīng)用誕生將加速POWER架構(gòu)滲透市場。結(jié)合二十多個軟硬體廠商的OpenPOWER組織,共同發(fā)表第一個建構(gòu)于IBM最新POWER8處理器架構(gòu)的白牌伺服器。該伺服器整合泰安電腦、IBM
2014-04-29 09:16:09 969
969 `各位看官,說了半天的快充,大家一定也想知道,快充到底有多快,為什么會快,會不會不安全等等。下面一一道來。最近江湖上傳言有特別快的快充,那個快充,幾分鐘甚至幾秒鐘就能充滿手機,這些江湖傳言是并不是
2015-12-25 15:29:14
快恢復(fù)二級管具有特性好,反向恢復(fù)時間短的特點,由于它特點的不同,所以快恢復(fù)二級管在電路應(yīng)用中有不可取代的作用。快恢復(fù)二級管主要應(yīng)用于開關(guān)電源,PWM脈寬調(diào)至器、變頻器等電路中。快恢復(fù)二級管可以從
2022-05-31 16:14:37
高,吸引了許多懂法不懂法,懂技術(shù)不懂技術(shù)的小伙伴圍觀,組成了一場全民狂歡大戲,根源在于:被審的是那些年,我們一起用過的快播啊!看了這么多,小編就只有一句話!樂事,你欠快播的廣告費什么時候可以還?(喜歡小編的壇友,可以打賞點小編,有更多好的內(nèi)容推送哦)`
2016-01-11 15:02:42
在過去的幾年間,F(xiàn)PGA技術(shù)備受矚目,而快閃FPGA的出現(xiàn)無疑引發(fā)FPGA領(lǐng)域的一場革命,推動了FPGA的進一步飛躍。由于PPGA的特性主要由其使用的可編程技術(shù)來決定,相對于SRAM FPGA,快閃FPGA具有更好的非易失性,這使其成為FPGA設(shè)計的更好的選擇。
2019-08-05 07:59:59
我一直在使用ARM處理器,現(xiàn)在速度為幾百兆的芯片感覺就很少了,認(rèn)為速度就很快了,今天看到了DSP的處理速度能達到4800MIPS,這個換算成頻率是4800MHZ嗎?也就是4.8G,真的嗎?為什么這么快呢?
2014-08-13 09:27:52
你好,我想通過SPI接口與USB接口的微控制器與PC。MiHROCHIPMCP2210具有這種能力。但是我找不到關(guān)于司機的任何信息。它有HID驅(qū)動程序嗎?我想全速使用它。HID驅(qū)動程序支持這么快的速度嗎?我想用我自己的軟件用Qt/C++編寫,我怎么用呢?有任何DLL文件嗎?謝謝。
2020-03-19 11:12:07
; 0) { console.log("已經(jīng)是第一張") prompt.showToast({message:"已經(jīng)是第一張"})}else{ this.idx
2022-05-18 10:21:00
;實時監(jiān)測數(shù)據(jù)可通過RJ45接口傳給以太網(wǎng),使監(jiān)控中心及時得到UPS的相關(guān)參數(shù);同時UPS監(jiān)控軟件根據(jù)測試參數(shù)判斷UPS運行狀況,電壓是否越限或過低等。 單片機選用美國冬澤電商(AMERICA
2008-08-18 09:06:43
計算機已在各行各業(yè)得到廣泛應(yīng)用。作為直接關(guān)系到計算機軟硬件能否安全運行的一個重要因素——電源質(zhì)量的可靠性應(yīng)當(dāng)成為中小企業(yè)首要考慮的問題。伴隨著計算機的誕生而出現(xiàn)的美國冬澤電商(AMERICA
2008-08-16 08:32:01
美國冬澤電商(AMERICA POWER ELECTRONIC )線性穩(wěn)壓器的用處很大,可以使用在很多場合。現(xiàn)在,我們以美國APE芯片為例來介紹美國冬澤電商(AMERICA
2008-08-18 09:19:40
,世界著名的電子制造商均在檳城設(shè)立了生產(chǎn)基地,2008年的這次展會吸引了眾多專業(yè)觀眾參觀,美國冬澤電商也出席了此次電子盛會。 &
2008-08-12 13:40:11
allegro 怎么這么難操作,那位大神有快捷方法的
2018-01-29 08:35:53
freerots任務(wù)怎么建才快
2023-10-13 07:43:11
點擊學(xué)習(xí)>>《龍哥手把手教你學(xué)LabVIEW視覺設(shè)計》視頻教程最近招聘labview工程師。遇到問題是簡歷這么這么少,但是學(xué)習(xí)的人還挺多的。是不是大家只是把labview當(dāng)做本身的一個技能啊。還身懷絕技其它的。labview我只想找一個專精的怎么這么難。
2016-10-25 09:46:40
PWM整流器及其控制2012版 》作者 :張興 張崇魏書籍介紹:PWM整流器以其優(yōu)良的性能和潛在的優(yōu)勢正在廣泛的應(yīng)用,已成為電力電子技術(shù)研究的熱點。本書以電壓型PWM整流器為主,兼顧電流型PWM
2019-03-22 22:36:38
`今天小編看到一個工程師寫的打油詩,拿出來給大家分享,有興趣的小伙伴也可以跟帖回哦!春眠不覺曉,張工特?zé)兰矣欣虾托。澓谟制鹪鐗毫θ杖赵觯婵钤略律俾殘鋈鐟?zhàn)場,處處心機婊加班熬通宵,老板還發(fā)狂世界
2015-12-21 15:06:24
``相關(guān)課程推薦:《8周LabVIEW視覺項目編程實戰(zhàn)特訓(xùn)營》此論文比較好比較全面 感謝張學(xué)東同學(xué)的無私奉獻,希望大家向他多多學(xué)習(xí)非常完整的程序:非常完整的論文正文:不可多得的學(xué)習(xí)資料。,其實labview做論文不是很難哦,關(guān)鍵在于要去做,敢想 不怕困難,再次感謝張學(xué)冬同學(xué)[hide][/hide]``
2011-11-07 11:12:28
未完待續(xù)!!在講三軸加速度計的時候,提到外部中斷。接下來就看看中斷為什么這么配置。
2021-08-13 08:14:59
如題為什么ARM這么流行呢?
2013-03-28 14:28:15
下面兩張圖片,是利用網(wǎng)上的BETA計算得到的,有個疑問:為什么在測純電阻的時候,選擇5933和5934的區(qū)別這么大?
2018-11-30 10:54:33
一,什么是快充及快充目前的主要協(xié)議版本有那些?快充是高通引導(dǎo)的一種充電方式標(biāo)準(zhǔn), 其主要是通過改變電壓和電流的方式來提高充電功率,從而在保持相對低的溫度情況下縮短了充電的時間。利用快充技術(shù)可以在30
2021-09-15 08:28:45
問題是:為什么我的電池耗盡這么快?我做錯了什么嗎?我能做些什么更好?我的 deepsleep、WiFi 連接和 Mqtt 代碼取自我的 temp./light/hum。傳感器項目,在深度睡眠模式下消耗
2023-02-24 08:41:03
還有這么詳細(xì)而淺顯易懂的硬件教學(xué)視頻,我興奮了很久,覺得自己的領(lǐng)路人出現(xiàn)了。接下來,我就跟著張工的視頻,一集一集的學(xué)習(xí),從一個什么都不懂得菜鳥,跟著張工學(xué)完了模電,再到現(xiàn)在的開關(guān)電源。在跟張工的學(xué)習(xí)
2015-01-31 22:55:41
單片機是查表快 還是位移快,比如說:要判斷某一位,1. 移位計算 while((GPIO1->DATA & (1
2015-03-23 09:44:15
我必須制作一個桌面應(yīng)用程序,用CyPress PLE軟件收集來自BLE傳感器的數(shù)據(jù)。目前我正在使用CyScript,但是我想用我自己的應(yīng)用程序自動化和定制這個過程。哪里有可能找到柏柏爾冬樂和CySMART之間使用的協(xié)議文件?
2019-09-30 09:01:54
各位大俠我下載了中北大學(xué)張學(xué)冬同學(xué)的多路信號采集系統(tǒng)的程序 但是他的主程序框圖是有密碼的誰知道密碼嗎? 真的很想借鑒下 因為現(xiàn)在正在畢設(shè)攻堅呢謝謝了
2012-05-28 10:38:25
充電器實現(xiàn)快充的原理是什么?實現(xiàn)手機快充有哪幾種方式呢?
2021-11-03 07:06:40
對存在的一張RGB圖像將其變換成一張灰度圖的方法,最好能給出簡單程序。謝謝
2019-04-03 15:10:32
導(dǎo)電電極是快充電池的關(guān)鍵嗎?
2017-08-11 13:48:32
`就一張圖片`
2012-12-28 22:37:11
第一張是峰值保持原理圖,第二張是輸出,請問為什么輸出會有這么大的抖動(綠色線左邊部分),有哪位能夠詳細(xì)解釋一下嗎?
2017-12-18 23:26:24
市場上有無線快充移動電源嗎?之前我在各大網(wǎng)站尋找都沒有找到我想到的既然市場這片是空白的為什么我們不做一個呢由億品奇 EPQI自主研發(fā)生產(chǎn)的EH200F無線快充移動電源現(xiàn)已上市亮點如下1、采用雙充電
2017-08-04 19:50:55
為什么其他板塊都火,這里這么冷清?太軟了
2008-06-13 17:48:47
想問下目前rtthread支持2張或者2張以上的SD卡掛載嗎?
2022-09-20 14:26:53
手機快充是如何實現(xiàn)的?
2021-09-26 07:17:28
快充的原理是什么?有哪些提升快充功率的方法?
2021-09-26 08:29:47
機器視覺-張廣軍
2020-03-31 12:34:41
每天的效率怎么這么低呢
2016-05-11 16:11:33
、服務(wù)調(diào)用失敗的自動回滾,性能比XA協(xié)議事務(wù)快10倍。GTS有哪些功能,相比傳統(tǒng)事務(wù)的優(yōu)勢在哪呢?我們通過一張圖讀懂GTS。5月30日15:00,阿里中間件技術(shù)專家寈峰將在線解讀GTS【直播報名直通車】原文鏈接
2018-06-04 19:02:59
毫米波究竟是什么,為什么這么重要?
2020-12-03 07:53:53
宿舍限壓想做一個簡單的變壓插排沒找的原理圖哪位大神給張
2015-11-16 20:24:56
怎么用for循環(huán),控制一張張播放圖片?
2012-03-06 19:55:17
那位大神能給我詳細(xì)的分析下手機快充的原理嗎?最好附圖
2016-11-28 15:12:41
熱得快實際上是一根高阻值的電阻嗎?當(dāng)有電流通過時,就把電流轉(zhuǎn)化為熱能散發(fā)了嗎?這是什么原理啊?
2019-12-19 09:33:51
幾篇張正友標(biāo)定方法的英文原文,不少朋友看過張正友標(biāo)定方法,這里提供他的英文原文。喜歡看英文文獻的,以及愿意更深入理解matlab中相機標(biāo)定工具箱的朋友可以參考。
2018-05-04 14:43:25
其他的論壇沒有這么多人,沒有這么快的更新.... 你們覺得呢?
2013-04-17 10:52:27
凜冬已至,隨著氣溫逐漸降低到零下,電動汽車在冬季的行駛能耗不斷上升,直接導(dǎo)致掉電極快。此前中汽研發(fā)布的一組數(shù)據(jù)顯示,當(dāng)室外溫度為-7℃、車內(nèi)22℃時,純電動汽車的平均續(xù)航里程將下降39%之多,而如果是不具備電池溫控系統(tǒng)的微型電動車,電量則會下降60%之多。
2021-01-22 06:51:43
本帖最后由 一只耳朵怪 于 2018-6-22 10:38 編輯
DM8168HDVPSS如何實現(xiàn)一張一張圖片抓拍
2018-06-22 04:36:47
請問testbench是這么搭建的嗎?實際放在adc前端是用電阻1:1拉回去做反饋嗎?
2021-06-22 08:09:59
特斯拉的快充系統(tǒng)的主要特點是什么?特斯拉的快充系統(tǒng)是由哪些部分組成的?怎樣去設(shè)計特斯拉的快充系統(tǒng)充電接口電路?
2021-07-11 07:44:24
這個論壇為什么這么冷清呀
2012-09-20 22:26:51
1.系統(tǒng)功能 高壓輸電線路的導(dǎo)線接頭是線路安全運行的薄弱環(huán)節(jié),特別是耐張桿塔上用并溝線夾或用螺栓連接的跳線接頭,因為這兩種接頭都是通過螺栓將導(dǎo)線連接在一起的,這種連接方式若安裝時螺栓壓
2021-11-12 09:14:32
MDSC-8000S 金屬雙張檢測控制器 單探頭版產(chǎn)品概述針對汽車制造與汽配生產(chǎn)行業(yè)大片料,須單側(cè)傳感器安裝特點,實現(xiàn)單邊探頭檢測雙張上料問題應(yīng)應(yīng)用場景車汽車及配件行業(yè),導(dǎo)磁金屬大片料接觸性雙張檢測
2022-09-08 11:39:19
中金分析師何偉、郭海燕、于奔制作出了長篇報告《三星為什么這么牛》,詳細(xì)地剖析了三星集團的歷史、戰(zhàn)略與優(yōu)勢。
2012-08-13 09:40:355387 OpenPOWER?基金會中國峰會,攜手全球伙伴企業(yè)一起加速基于IBM POWER技術(shù)的協(xié)同創(chuàng)新。作為OpenPOWER基金會的一員,賽靈思面向基于CAPI的高性能電源系統(tǒng)解決方案不斷推出FPGA加速技術(shù),用以加速
2015-06-08 10:42:43974 作者:Michael Gschwind,IBM Systems機器學(xué)習(xí)和深度學(xué)習(xí)首席工程師 我很榮幸地宣布推出面向OpenPOWER深度學(xué)習(xí)框架的重大更新,作為軟件“distros”(發(fā)布版本
2017-11-10 14:49:02280 IBM于美國時間2015年11月16日,發(fā)布了該公司主辦的“OpenPOWER基金會”過去取得的成果和今后的戰(zhàn)略。還宣布與FPGA廠商賽靈思建立了為期4年的戰(zhàn)略合作關(guān)系,將加快機器學(xué)習(xí)、網(wǎng)絡(luò)虛擬
2017-02-08 20:42:11173 今天,OpenPOWER基金會在京召開主題為“開放力量 ? 引領(lǐng)新一代計算技術(shù)”的第二代分布式計算技術(shù)峰會。來自IBM公司、賽靈思公司、深圳市恒揚科技股份有限公司、聯(lián)科集團(中國) 有限公司、無錫
2017-02-08 20:51:11235 、清華大學(xué)等機構(gòu)的領(lǐng)導(dǎo)、專家,以及ISV、FPGA技術(shù)人員和行業(yè)用戶200余人共同出席了峰會。 峰會期間,OpenPOWER基金會宣布成立第二代分布式計算聯(lián)盟,以推動新一代計算技術(shù)和應(yīng)用的發(fā)展。同時,構(gòu)建于SuperVessel云平臺上的CAPI FPGA應(yīng)用加速商城(CAPI FPGA APP Store)也正
2017-02-08 20:54:11324 IBM CAPI)板卡。支持強力渦輪風(fēng)扇進行主動散熱,對機箱電源、結(jié)構(gòu)和散熱無特殊要求。Semptian NSA-120主要用于大數(shù)據(jù)、云計算等互聯(lián)網(wǎng)業(yè)務(wù)的計算加速,可廣泛應(yīng)用于大數(shù)據(jù)分析、圖像識別和處理、視頻編解碼、壓縮解壓縮、語音識別和處理、神經(jīng)網(wǎng)絡(luò)、機器學(xué)習(xí)、網(wǎng)絡(luò)安全等領(lǐng)域的計算加速。
2019-10-06 17:33:003162 近日,OpenPOWER基金會宣布正式推出全新硬件加速ISV支持計劃,為本地ISV(獨立軟件開發(fā)商)免費提供基于RedPOWER服務(wù)器以及賽靈思FPGA的云端開發(fā)及測試環(huán)境,幫助ISV提升大數(shù)據(jù)、云計算等新興技術(shù)研發(fā)能力,促進第二代分布式計算的發(fā)展。
2019-10-06 18:05:00446 IBM組建OpenPOWER產(chǎn)業(yè)聯(lián)盟18個月,首款國產(chǎn)POWER芯片和三款服務(wù)器面世,中國企業(yè)獲得技術(shù)了嗎?高鐵國產(chǎn)化路線是否復(fù)制成功? 第一款國產(chǎn)POWER芯片、三款服務(wù)器,這是中國北京、江蘇兩地
2017-02-09 04:06:05163 安卓8.0初體驗,竟然這么流暢還有這么多黑科技功能
2017-04-13 09:00:313556 在之前的OpenPOWER歐洲峰會上,我們推出了全新的框架,旨在便于開發(fā)者開始采用CAPI加速其應(yīng)用開發(fā)。CAPI存儲、網(wǎng)絡(luò)和分析編程框架,或者簡稱為CAPI SNAP,通過OpenPOWER成員
2017-11-16 13:16:061683 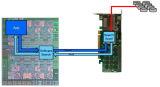
什么是異構(gòu)計算?可能在很多人看來感覺高深莫測,我們可以先用一個比喻來簡單的解釋一下。比如在做簡單的整數(shù)算數(shù)時,知道算法口訣的人,心算即可,但遇到比較復(fù)雜的算數(shù)問題時,就得需要一個計算器了,但在這個運算過程中,一些簡單的計算可以提前由心算完成再輸入計算器,比如計算“(5+2)÷26”,可能我們直接就輸入“7÷26”了。
2017-11-17 11:49:464626 今日在北京開啟的OpenPOWER峰會主要聚焦點在人工智能技術(shù)上,OpenPOWER在中國蓬勃發(fā)展,是否會為國內(nèi)的廠商帶來機遇。
2017-12-14 09:24:19951 近日OpenPOWER 吸引了大多數(shù)人的眼球,在 OpenPOWER 中國高峰論壇上 總經(jīng)理 Ken King 宣布了新成員的加入,并發(fā)布了Power9 服務(wù)器。據(jù)悉,Power9 服務(wù)器的出現(xiàn)就是為挑戰(zhàn)英特爾 X86 架構(gòu)而產(chǎn)生的。
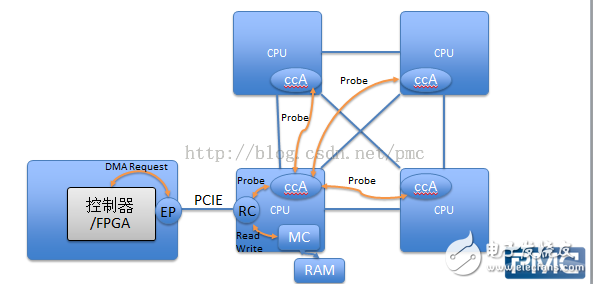
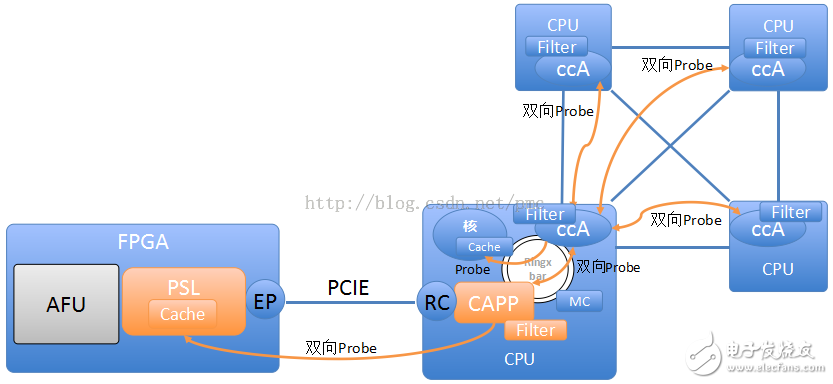
2017-12-18 10:24:391340 我們說一說IBM搞的CAPI,CAPI是OpenPower體系里的一個技術(shù),其目的是讓FPGA更好更方便的融入現(xiàn)有的系統(tǒng)。那么現(xiàn)有的FPGA是怎么被使用的呢?不如先說說什么是FPGA,要弄清楚什么是FPGA,就得先說說什么是CPU。可笑,CPU大家都知道,冬瓜哥這逼格咋降低了?笑而不語。
2018-07-12 11:35:009331 2018 OpenPOWER峰會在美國拉斯維加斯舉行。浪潮在大會上展示了其基于OpenPOWER9的新品服務(wù)器FP5280G2,這是該款產(chǎn)品首次在北美亮相,并已經(jīng)完成了對云計算、大數(shù)據(jù)以及AI領(lǐng)域
2018-03-25 11:27:001449 NVMe是一種新興的固態(tài)硬盤接口協(xié)議,如今越來越普遍地被企業(yè)級、數(shù)據(jù)中心和HPC市場采用。NVMe構(gòu)建了一個廣泛的生態(tài)系統(tǒng),OpenPOWER已加入其中,支持該協(xié)議。
2018-06-26 15:20:0013724 
生態(tài)障礙。CAPI(一致性加速器處理器接口)把兩家公司的開發(fā)人員聯(lián)系起來,包括中國FPGA開發(fā)人員5萬人,Java,C++的開發(fā)人員4、5百萬。
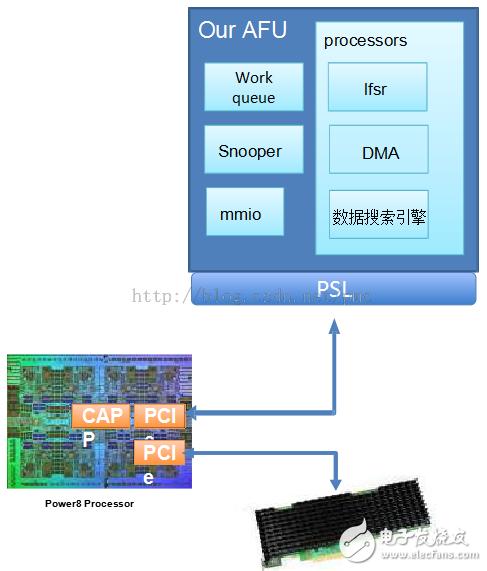
2018-10-11 16:51:391950 在本演示中,來自IBM的Bruce Wile討論了新推出的CAPI SNAP框架,該框架支持FPGA加速。
“SNAP”框架是“存儲,網(wǎng)絡(luò)和分析編程”的縮寫,可以在數(shù)據(jù)流動時加速對數(shù)據(jù)的分析
2018-11-29 06:09:002963 一篇漫畫看懂:一顆芯片,咋就這么難造?
2018-12-01 08:41:289003 Alpha Data 為 ADM-PCIE-8K5 PCIe 加速器板提供的板支持包 (BSP) 包括:高性能PCIe/DMA、OpenPOWER Architecture CAPI(參見:采用
2019-07-30 17:31:442215 )測試設(shè)備驗證。OpenPOWER的一致性加速器處理器接口 (CAPI) 實現(xiàn)了擴展至60Gbps吞吐量和2TB存儲的解決方案。
2019-07-31 11:40:141512 總聽有人說現(xiàn)在的CPU太貴了,那為什么CPU會這么貴?不知道你們有沒有思考過呢?
2020-01-12 11:08:558880 電子發(fā)燒友網(wǎng)為你提供TE(ti)CAT-CAPI-6T相關(guān)產(chǎn)品參數(shù)、數(shù)據(jù)手冊,更有CAT-CAPI-6T的引腳圖、接線圖、封裝手冊、中文資料、英文資料,CAT-CAPI-6T真值表,CAT-CAPI-6T管腳等資料,希望可以幫助到廣大的電子工程師們。
2021-07-08 21:00:04
科技巨頭紛紛元宇宙 元宇宙為什么這么火 最近元宇宙很火,許多科技巨頭都入局了元宇宙,那么元宇宙為什么這么火呢? 彭博社估計,在三年之后,全球“元宇宙”市場規(guī)模能夠達到8000億美元,所以元宇宙真是
2021-11-03 16:09:203646 《linux就該這么學(xué)》劉遄電子版
2022-01-21 09:18:09 0
0 多圓盤軸封磨損這么嚴(yán)重,還能修復(fù)么?
2022-02-10 13:42:153 電機軸維修原來這么很簡單
2022-02-28 16:17:1315 方案概述鋰電池在進行疊片的一般順序是:正極片+隔離膜+負(fù)極片+隔離膜+正極片......,如果某一極片出現(xiàn)重疊片料或者零張片料,則會嚴(yán)重影響電池的安全性。為了解決這一問題,可以在料堆與疊片機之間安裝
2022-09-08 15:28:24
 電子發(fā)燒友App
電子發(fā)燒友App










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論