 電子發(fā)燒友App
電子發(fā)燒友App


【服務(wù)器數(shù)據(jù)恢復(fù)故障描述】
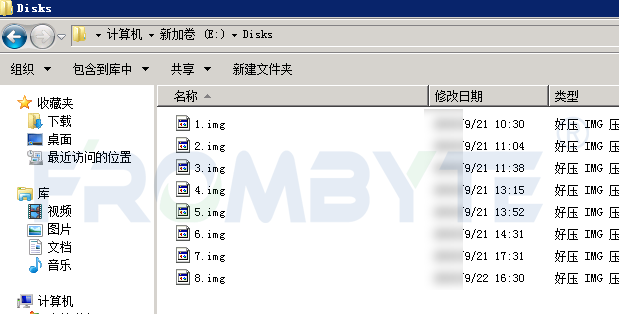
用戶的EMC CX4-480存儲(chǔ)服務(wù)器由于硬盤出現(xiàn)故障離線癱瘓。服務(wù)器中共有10塊硬盤,其中7塊硬盤組成RAID 5磁盤陣列。另外3塊硬盤為服務(wù)器在使用過程中的掉線磁盤,用戶在處理掉線磁盤時(shí)只添加新的硬盤做rebuild,并沒有將掉線的硬盤拔掉,現(xiàn)已有過3塊掉線磁盤,所以服務(wù)器中有3塊多余硬盤。
服務(wù)器管理員推斷服務(wù)器癱瘓的原因是陣列中硬盤出現(xiàn)硬件故障導(dǎo)致服務(wù)器癱瘓,于是將所有硬盤交給硬件數(shù)據(jù)恢復(fù)工程師對(duì)硬件進(jìn)行物理檢測。硬件數(shù)據(jù)恢復(fù)工程師對(duì)服務(wù)器中所有硬盤逐一進(jìn)行物理檢測后并沒有發(fā)現(xiàn)硬盤存在物理故障,只好由服務(wù)器數(shù)據(jù)恢復(fù)工程師對(duì)所有硬盤做全盤鏡像后對(duì)服務(wù)器riad進(jìn)行分析。
【服務(wù)器數(shù)據(jù)恢復(fù)】
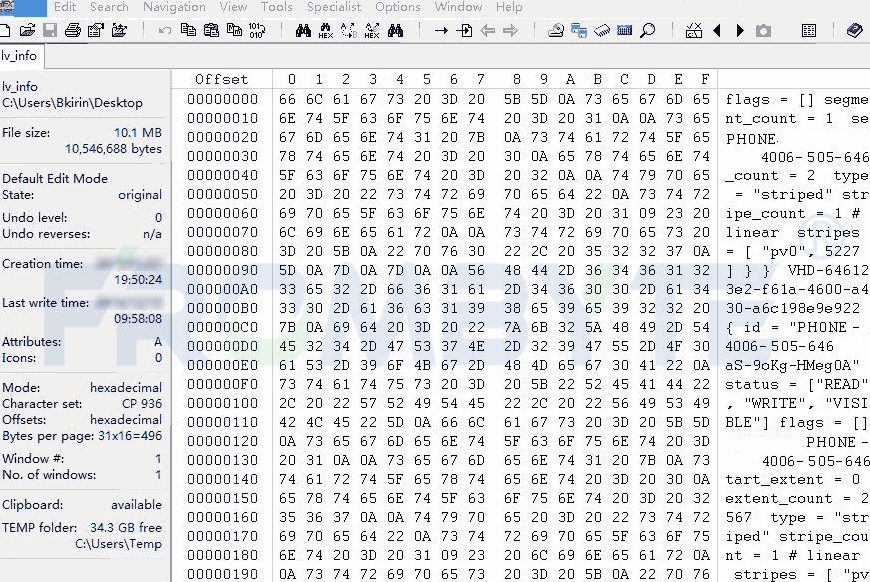
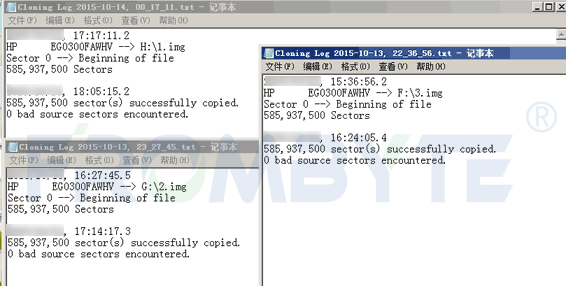
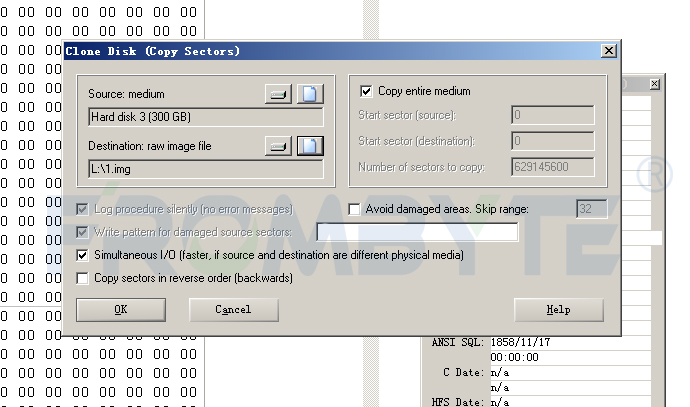
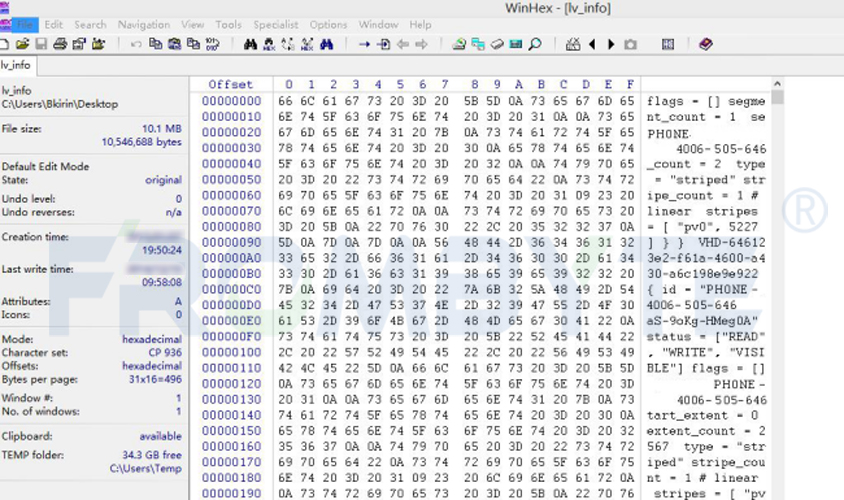
按照數(shù)據(jù)恢復(fù)流程對(duì)所有磁盤進(jìn)行鏡像備份后,服務(wù)器數(shù)據(jù)恢復(fù)工程師開始對(duì)服務(wù)器raid結(jié)構(gòu)進(jìn)行分析;服務(wù)器數(shù)據(jù)恢復(fù)工程師分析后發(fā)現(xiàn)該服務(wù)器中的硬盤每512字節(jié)多加了一個(gè)8字節(jié)的校驗(yàn),也就是變成了每扇區(qū)520字節(jié)了。如此一來繼續(xù)進(jìn)行raid結(jié)構(gòu)分析將十分困難,為了提高工作效率,服務(wù)器數(shù)據(jù)恢復(fù)工程師自己編寫了一個(gè)小程序?qū)?字節(jié)的校驗(yàn)去掉來方便后期的工作。
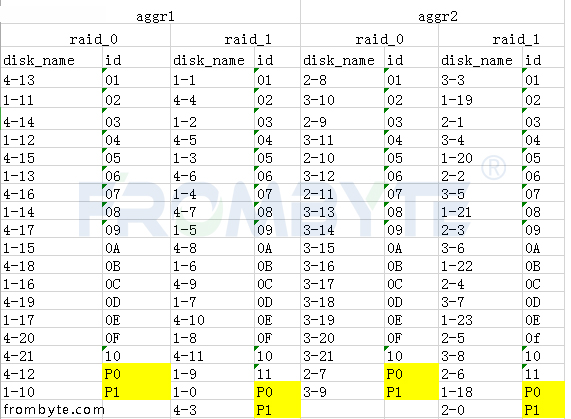
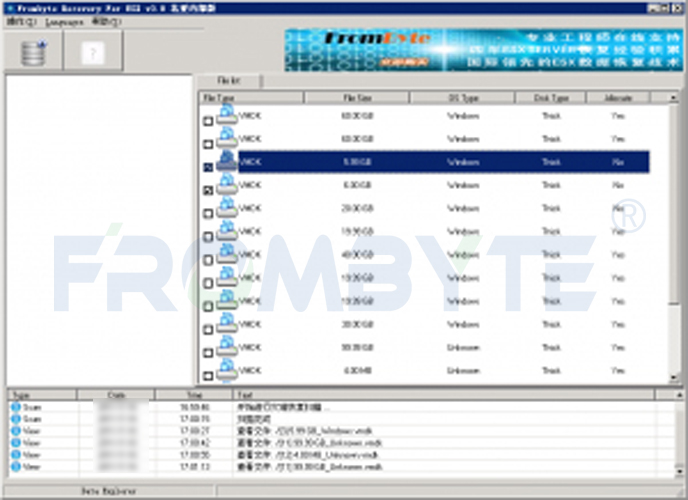
所有磁盤都轉(zhuǎn)換完成后,工程師繼續(xù)分析RAID的結(jié)構(gòu)。由于多了3塊以前的舊盤,需要通過比較每塊磁盤,即其中會(huì)有兩塊磁盤前面的一部分相同,而這兩塊當(dāng)中會(huì)有一個(gè)是舊的,舊的數(shù)據(jù)量沒有新盤多,就可以排除舊的磁盤。這樣的磁盤會(huì)有3對(duì),也就可以排除所有舊的磁盤了。
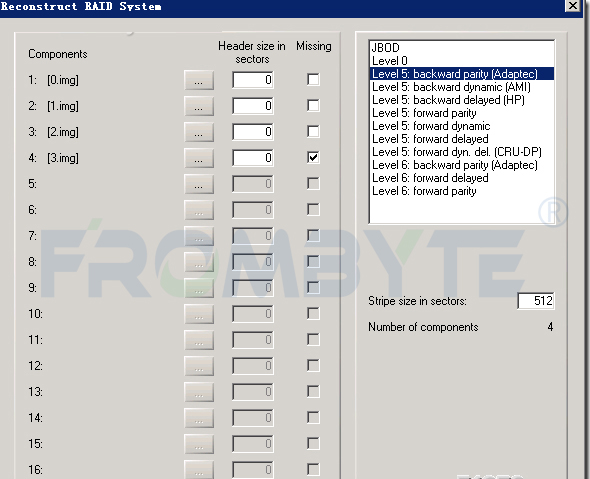
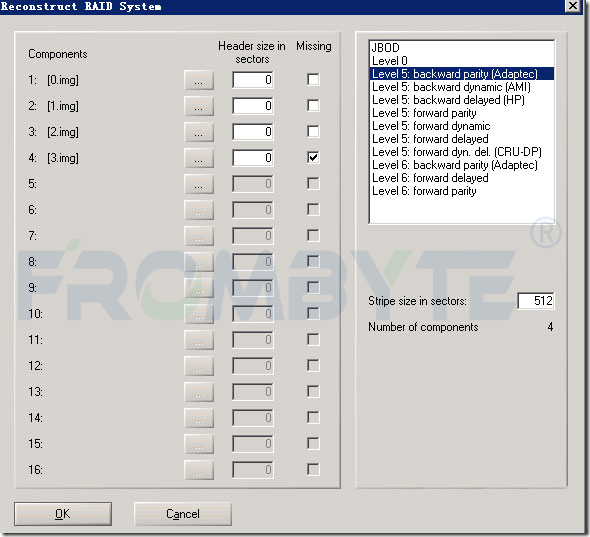
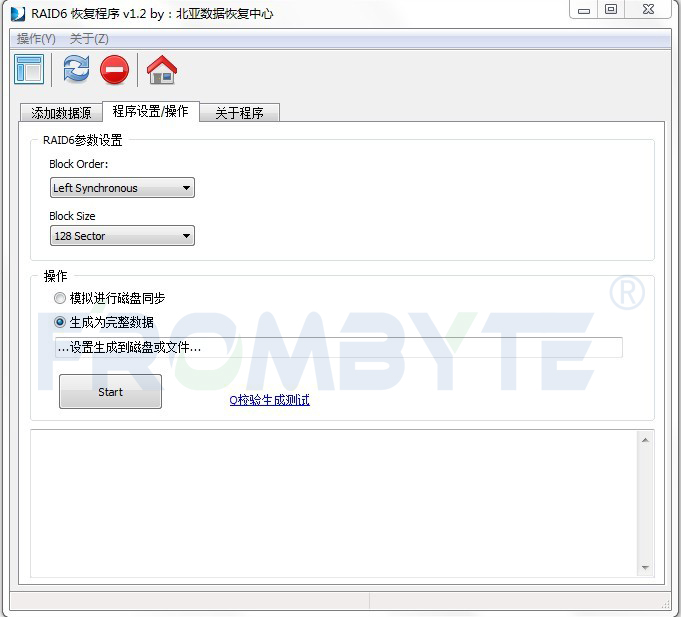
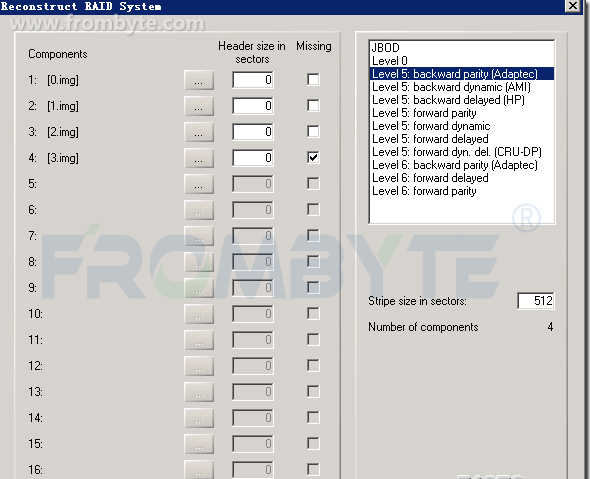
接下來看RAID結(jié)構(gòu),由于客戶用的NTFS文件系統(tǒng),用MFT很容易就可以找到RAID的結(jié)構(gòu)了。知道RAID結(jié)構(gòu)后發(fā)現(xiàn)這不是一個(gè)普通的RAID 5,而是一個(gè)雙循環(huán)。無法借助數(shù)據(jù)恢復(fù)工具重組RAID,只好轉(zhuǎn)為其他方式重組raid陣列!重組RAID后發(fā)現(xiàn)數(shù)據(jù)不是最新的。服務(wù)器數(shù)據(jù)恢復(fù)工程師猜測可能是RAID 5先掉線一塊硬盤時(shí)管理員沒有及時(shí)發(fā)現(xiàn),沒有及時(shí)添加新的硬盤做rebuild。導(dǎo)致運(yùn)行一段時(shí)間后又有一塊硬盤掉線了,才造成整個(gè)RAID不可用。所以還需要找出一塊舊的磁盤,才能生成最新的數(shù)據(jù)。繼續(xù)進(jìn)行找盤的工作!服務(wù)器數(shù)據(jù)恢復(fù)工程師采用窮舉加校驗(yàn)的方法進(jìn)行分析,即假設(shè)某個(gè)磁盤是掉線的,踢掉磁盤后重組RAID,但不是生成全部的數(shù)據(jù),而是只生成前面5G的數(shù)據(jù),我們只需要查看這個(gè)索引表的位圖的信息是否正確就可以判斷此RAID是否正確。如果正確那么生成此RAID的數(shù)據(jù)即可完成RAID的重組
【服務(wù)器數(shù)據(jù)恢復(fù)成功】
? ? ? ?整個(gè)恢復(fù)過程,包括做鏡像,扇區(qū)轉(zhuǎn)換和最后的拷貝數(shù)據(jù),一共耗時(shí)3天。數(shù)據(jù)恢復(fù)率達(dá)百分之九十九以上。雖然整個(gè)過程比較漫長,但是最終的結(jié)果用戶很高興,因?yàn)檫@給他們帶來了不必要的損失。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論