 電子發燒友App
電子發燒友App


網絡上流傳著這么的一句流行語:“萬事不懂問度娘”。自從有了各種搜索引擎,新名詞新技術對大眾而言,已不再神秘。然而,當你搜索“大數據”或者“big data solution”等關鍵字時,搜索出的海量相關知識鋪天蓋地,對初學者而言,仍然很難在短時間內入門。本文目的,是以傻瓜式提問的方式讓初學者輕松的了解“大數據”。
大數據的概念
“大數據”,是不是----數據很大就叫大數據?
實際上簡單的這樣理解也沒有錯,在明確定義時,會比較強調大數據的4個V的特性: Volume,Variety,Value,Velocity。也就是:
一、數據存儲空間占用大(至PB及以上級別);
二、數據類型繁多;
三、價值密度低;
四、處理速度快。
搜索的信息中,你會發現有某些名詞出現的頻率非常高,心里也隨之會產生一些疑問。“PB是多大?”“Map-Reduce是啥?”“Hadoop是啥?”“大數據跟云計算啥關系?跟傳統意義的數據庫啥關系?”等等。
這么多的信息量,我們還是按照大數據的基本定義,四個V來逐一梳理吧。
從第一個V開始,Volume。
數據量很大,到底能達到什么程度呢?先來學習一下數量級的知識吧。
1KB(Kilobyte 千字節) = 2^10 B = 1024 B;
1MB(Megabyte 兆字節) = 2^10 KB = 1024 KB = 2^20 B;
1GB(Gigabyte 吉字節) = 2^10 MB = 1024 MB = 2^30 B;
1TB(Trillionbyte 太字節) = 2^10 GB = 1024 GB = 2^40 B;
1PB(Petabyte 拍字節) = 2^10 TB = 1024 TB = 2^50 B;
1EB(Exabyte 艾字節) = 2^10 PB = 1024 PB = 2^60 B;
1ZB(Zettabyte 澤字節) = 2^10 EB = 1024 EB = 2^70 B;
1YB(YottaByte 堯字節) = 2^10 ZB = 1024 ZB = 2^80 B;
1BB(Brontobyte ) = 2^10 YB = 1024 YB = 2^90 B;
1NB(NonaByte ) = 2^10 BB = 1024 BB = 2^100 B;
1DB(DoggaByte) = 2^10 NB = 1024 NB = 2^110 B;
……
“哇!坑爹啊,整出這么多名詞,跟大數據都有關系嗎?需要我們掌握嗎?”別激動!其實,KB,MB,GB我們在日常電腦操作中已經經常碰到了。甚至TB級的大硬盤,也已經應用于家用電腦中了。我們所說的“大數據”,目前大多產品還處在了立足PB展望EB的級別。后面的那些什么ZB、YB、BB、NB、 DB……等,就暫時先當他們是浮云吧~
第二個V, Variety。
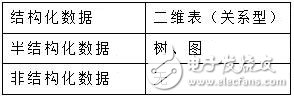
關于這一點,百度百科里是這么說的“網絡日志、視頻、圖片、地理位置信息等等”。從專業一點的角度,我們可以說“大數據”中,可以有結構化數據,但更多的是大量的非結構化和半結構化數據。
結構化和非結構化數據是什么意思?
結構化數據是指,可以存儲在數據庫里,可以用二維表結構來邏輯表達實現的數據。
非結構化數據,是指不方便用數據庫二維邏輯表來表現的數據,包括所有格式的辦公文檔、文本、圖片、XML、HTML、各類報表、圖像和音頻/視頻信息等等。
而半結構化數據,就是介于完全結構化數據(如關系型數據庫、面向對象數據庫中的數據)和完全無結構的數據(如聲音、圖像文件等)之間的數據,HTML文檔就屬于半結構化數據。它一般是自描述的,數據的結構和內容混在一起,沒有明顯的區分。
上述的描述,其實還是有點不明確。用數據模型的列表來看,區別就更清晰一點了:
第三個V,Value。
價值密度低。以視頻為例,連續不間斷監控過程中,可能有用的數據僅僅有一兩秒。
第四個V,Velocity。
處理速度快。如此龐大的數據量,需要在短時間內迅速響應。所使用的技術,當然是有別于傳統的數據挖掘技術的。
釋疑解惑
“梳理完了四個V,咋還是云山霧罩的呢?”
下面來回答幾個初學者可能思考到的問題吧!
針對大數據的四個V,有沒有什么對應的技術來應對呢?
目前,查詢“大數據”,你會發現度娘給出的各種信息中,Hadoop這個詞出現的很頻繁。而且,很多廠商提供的產品,也都會打上一個標簽:“**產品已經并入Hadoop分布式計算平臺,以及將Hadoop引入**產品。”
什么是Hadoop?
Hadoop是由Apache基金會開發的一個分布式系統基礎架構。它是一個能夠對大量數據進行分布式處理的軟件框架。用戶可以在不了解分布式底層細節的情況下,開發分布式程序,充分利用集群的威力高速運算和存儲。
Hadoop包含了如下子項目:
1. Hadoop Common: 在0.20及以前的版本中,包含HDFS、MapReduce和其他項目公共內容,從0.21開始HDFS和MapReduce被分離為獨立的子項目,其余內容為Hadoop Common
2. HDFS: Hadoop 分布式文件系統 (Distributed File System) - HDFS (Hadoop Distributed File System)
3. MapReduce:并行計算框架,0.20前使用 org.apache.hadoop.mapred 舊接口,0.20版本開始引入org.apache.hadoop.mapreduce的新API
4. HBase: 類似Google BigTable的分布式NoSQL列數據庫。
5. Hive:數據倉庫工具,由Facebook貢獻。
6. Zookeeper:分布式鎖設施,提供類似Google Chubby的功能,由Facebook貢獻。
7. Avro:新的數據序列化格式與傳輸工具,將逐步取代Hadoop原有的IPC機制。
8. Pig: 大數據分析平臺,為用戶提供多種接口。
作為初學者,我們先撥開一些浮云,看看這里面到底有些什么。有三個主體部分,是我們需要重點關注的:HDFS、MapReduce、HBase。
實際上,Apache Hadoop的HDFS是Google File System(GFS)的開源實現。MapReduce是Google MapReduce的開源實現。HBase是Google BigTable的開源實現。
Hadoop是一個能夠讓用戶輕松架構和使用的分布式計算平臺。它主要有以下幾個優點:1高可靠性2高擴展性3高效性4高容錯性。用戶可以輕松地在Hadoop上開發和運行處理海量數據的應用程序。而實際上,很多公司提供的大數據產品也是基于Hadoop進行開發的。
數據存儲空間占用大
針對數據存儲空間占用大,我們需要用到的是“分布式存儲”。分布式存儲系統,就是將數據分散存儲在多***立的設備上。傳統的網絡存儲系統采用集中的存儲服務器存放所有數據,存儲服務器成為系統性能的瓶頸,也是可靠性和安全性的焦點,不能滿足大規模存儲應用的需要。分布式網絡存儲系統采用可擴展的系統結構,利用多臺存儲服務器分擔存儲負荷,利用位置服務器定位存儲信息,它不但提高了系統的可靠性、可用性和存取效率,還易于擴展。
前面我們介紹到的Hadoop,其中的HDFS就是現今最流行的分布式存儲平臺之一。
HDFS原理簡要描述
HDFS(Hadoop Distributed File System),是一個分布式文件系統。HDFS有著高容錯性(fault-tolerent)的特點,并且設計用來部署在低廉的(low-cost)硬件上。它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。HDFS放寬了(relax)POSIX的要求(requirements)這樣可以實現流的形式訪問(streaming access)文件系統中的數據。
HDFS是一個主從結構的體系,一個HDFS集群是由一個名字節點,它是一個管理文件的命名空間和調節客戶端訪問文件的主服務器,當然還有的數據節點,一個節點一個,它來管理存儲。HDFS暴露文件命名空間和允許用戶數據存儲成文件。
對外部客戶機而言,HDFS 就像一個傳統的分級文件系統。可以創建、刪除、移動或重命名文件,等等。
內部機制,是將一個文件分割成一個或多個的塊,這些塊存儲在一組數據節點中。名字節點(NameNode)操作文件命名空間的文件或目錄操作,如打開,關閉,重命名,等等。它同時確定塊與數據節點的映射。數據節點(DataNode)來負責來自文件系統客戶的讀寫請求。數據節點同時還要執行塊的創建,刪除,和來自名字節點的塊復制指示。這與傳統的 RAID 架構大不相同。塊的大小(通常為 64MB)和復制的塊數量在創建文件時由客戶機決定。NameNode 可以控制所有文件操作。
HDFS 內部的所有通信都基于標準的 TCP/IP 協議。
數據類型繁多
大數據處理,有如下需求:對數據庫高并發讀寫的需求、對海量數據的高效率存儲和訪問的需求、對數據庫的高可擴展性和高可用性的需求。傳統的關系型數據庫在此類需求面前束手無策。此時,一個新的概念被引入了----NoSQL。












 工商網監
工商網監
評論