 電子發(fā)燒友App
電子發(fā)燒友App


我們?yōu)槭裁葱枰邔哟尉C合
高層次綜合(High-level Synthesis)簡(jiǎn)稱 HLS,指的是將高層次語(yǔ)言描述的邏輯結(jié)構(gòu),自動(dòng)轉(zhuǎn)換成低抽象級(jí)語(yǔ)言描述的電路模型的過(guò)程。所謂的高層次語(yǔ)言,包括 C、C++、SystemC 等,通常有著較高的抽象度,并且往往不具有時(shí)鐘或時(shí)序的概念。相比之下,諸如 Verilog、VHDL、SystemVerilog 等低層次語(yǔ)言,通常用來(lái)描述時(shí)鐘周期精確(cycle-accurate)的寄存器傳輸級(jí)電路模型,這也是當(dāng)前 ASIC 或 FPGA 設(shè)計(jì)最為普遍使用的電路建模和描述方法。
然而,HLS 技術(shù)在近十年來(lái)獲得了大量的關(guān)注和飛速的發(fā)展,尤其是在 FPGA 領(lǐng)域。縱觀近年來(lái)各大 FPGA 學(xué)術(shù)會(huì)議,HLS 一直是學(xué)術(shù)界和工業(yè)界研究最集中的領(lǐng)域之一。究其原因,主要有以下幾點(diǎn)。
第一,使用更高的抽象層次對(duì)電路建模,是集成電路設(shè)計(jì)發(fā)展的必然選擇。集成電路伴隨摩爾定律發(fā)展至今,其復(fù)雜性已經(jīng)逐漸超過(guò)人類可以手工管理的范疇。例如,蘋(píng)果 iPhone11 內(nèi)置的 A13 芯片,就有著約 85 億支晶體管。
然而,根據(jù) NEC 2004 年發(fā)布的研究,一個(gè)擁有 100 萬(wàn)邏輯門的芯片設(shè)計(jì)通常需要編寫(xiě) 30 萬(wàn)行 RTL 代碼。因此,完全使用 RTL 級(jí)的邏輯抽象設(shè)計(jì)當(dāng)代芯片是不現(xiàn)實(shí)的,并將對(duì)設(shè)計(jì)、驗(yàn)證、集成等各個(gè)環(huán)節(jié)造成巨大的壓力。
相比之下,使用諸如 C、C++等高層語(yǔ)言對(duì)系統(tǒng)建模,可以將代碼密度壓縮 7 到 10 倍,這極大的緩解了設(shè)計(jì)復(fù)雜度。
第二,高層語(yǔ)言能促進(jìn) IP 重用的效率。傳統(tǒng)的基于 RTL 的 IP 往往需要定義固定的架構(gòu)和接口標(biāo)準(zhǔn),在 IP 重用時(shí)需要花費(fèi)大量時(shí)間進(jìn)行系統(tǒng)互聯(lián)和接口驗(yàn)證。相比之下,高層語(yǔ)言隱藏了這些要求,轉(zhuǎn)而由 HLS 工具負(fù)責(zé)具體實(shí)現(xiàn)。
對(duì)于 FPGA 而言,現(xiàn)代 FPGA 里有著大量成熟的 IP 單元,如嵌入式存儲(chǔ)器、算術(shù)運(yùn)算單元、嵌入式處理器,以及最近逐漸興起的 AI 加速器、片上網(wǎng)絡(luò)系統(tǒng)等等。這些 FPGA IP 有著固定的功能和位置,因此可以被 HLS 工具充分利用,在提升 IP 重用效率的同時(shí),簡(jiǎn)化綜合算法、提高綜合后電路的性能。
第三,HLS 能幫助軟件和算法工程師參與、甚至主導(dǎo)芯片或 FPGA 設(shè)計(jì)。這是由于 HLS 工具能封裝和隱藏硬件的實(shí)現(xiàn)細(xì)節(jié),從而使軟件和工程師能專注于上層算法的實(shí)現(xiàn)。對(duì)于硬件工程師而言,HLS 也能幫助他們進(jìn)行快速的設(shè)計(jì)迭代,并專注于對(duì)性能、面積或功耗敏感的模塊和子系統(tǒng)的優(yōu)化設(shè)計(jì)。
FPGA 高層次綜合的前世今生
伴隨集成電路的復(fù)雜性的飛速增長(zhǎng),芯片設(shè)計(jì)方法學(xué)也在不斷演進(jìn)。早在 FPGA 出現(xiàn)之前,人們就已經(jīng)開(kāi)始嘗試擺脫依靠人工檢視芯片版圖的設(shè)計(jì)方法,轉(zhuǎn)而探索使用高層語(yǔ)言對(duì)電路邏輯進(jìn)行行為級(jí)描述,并通過(guò)自動(dòng)化工具將電路模型轉(zhuǎn)化為實(shí)際的電路設(shè)計(jì)。
在上世紀(jì)八九十年代,面向集成電路設(shè)計(jì)的 HLS 工具就已經(jīng)是學(xué)術(shù)界研究的熱點(diǎn)。這其中比較有代表性的工作,包括卡耐基梅隆大學(xué)的 CMU-DA(design automation)工具,以及加拿大卡爾頓大學(xué)提出的 force-directed 調(diào)度算法等等。
從現(xiàn)在看來(lái),這些工作為當(dāng)前的電路綜合算法打下了基礎(chǔ),并為后來(lái) HLS 研究提供了很多寶貴的經(jīng)驗(yàn)和借鑒。然而,這個(gè)階段的 HLS 工作在成果轉(zhuǎn)化方面十分失敗,并未有效的轉(zhuǎn)化成工業(yè)實(shí)踐。一個(gè)最主要的原因,就在于“在錯(cuò)誤的時(shí)間,遇上了對(duì)的人”。
當(dāng)時(shí)正值摩爾定律蓬勃興起的時(shí)期,集成電路設(shè)計(jì)正在經(jīng)歷史上最大的變革。在后端,自動(dòng)布局布線已經(jīng)逐漸成為主流;在前端,RTL 綜合也在逐漸興起。傳統(tǒng)電路設(shè)計(jì)工程師都紛紛開(kāi)始采用基于 RTL 的電路建模方法,取代傳統(tǒng)的基于原理圖和版圖的設(shè)計(jì),并由此帶來(lái) RTL 綜合工具的飛速發(fā)展。相比之下,這個(gè)階段的 HLS 研究往往使用了特殊的編程語(yǔ)言,如 CMU-DA 采用的名為“ISPS”的語(yǔ)言,因此很難獲得那些正在和 RTL 處于“蜜月期”的工程師們的青睞。
伴隨著一段時(shí)間的沉寂,HLS 在 2000 年之后再次開(kāi)始獲得學(xué)術(shù)界和工業(yè)界的關(guān)注,比較有名的工具包括 Bluespec 和 AutoPilot 等。主導(dǎo)這一變化的主要原因是,HLS 工具開(kāi)始將 C/C++作為主要的目標(biāo)語(yǔ)言,從而被很多不了解 RTL 的系統(tǒng)和算法工程師所逐漸接受。同時(shí),HLS 工具綜合生成的結(jié)果也有了長(zhǎng)足進(jìn)步,在某些應(yīng)用領(lǐng)域甚至可以和人工手寫(xiě) RTL 近似的性能水平。
此外,F(xiàn)PGA 的逐漸興起也對(duì) HLS 的發(fā)展起到了重要的助推作用。和 ASIC 設(shè)計(jì)不同,F(xiàn)PGA 有著固定數(shù)量的片上邏輯資源。因此 HLS 工具不用過(guò)度糾結(jié)于 ASIC 設(shè)計(jì)中面積、性能和功耗的絕對(duì)優(yōu)化,而只需要將設(shè)計(jì)合理的映射到 FPGA 的固定架構(gòu)上即可。這樣,HLS 就成為了在 FPGA 上快速實(shí)現(xiàn)目標(biāo)算法的絕佳方式。
時(shí)至今日,高層次綜合技術(shù)取得了進(jìn)一步的發(fā)展。大型 FPGA 公司都推出了各自的 HLS 工具,如賽靈思的 Vivado HLS 和英特爾的 HLS 編譯器、OpenCL SDK 等。在學(xué)術(shù)界也有諸多成果涌現(xiàn),如多倫多大學(xué)的 LegUp 等等。
接下來(lái),老石將以 AutoPilot 這個(gè) HLS 工具為例,簡(jiǎn)單介紹高層次綜合的主要工作原理。
高層次綜合的主要工作原理
AutoESL 公司的 AutoPilot 工具,可以說(shuō)是 HLS 領(lǐng)域最為成功的學(xué)術(shù)成果轉(zhuǎn)化案例。AutoPilot 源自于 UCLA 叢京生教授主導(dǎo)的 xPilot 項(xiàng)目,從隨后與當(dāng)時(shí)負(fù)責(zé)該課題的博士生張志如(現(xiàn)任康奈爾大學(xué)副教授)一起創(chuàng)辦了 AutoESL 公司,并在 2011 年被賽靈思收購(gòu),成為了之后的 Vivado HLS。
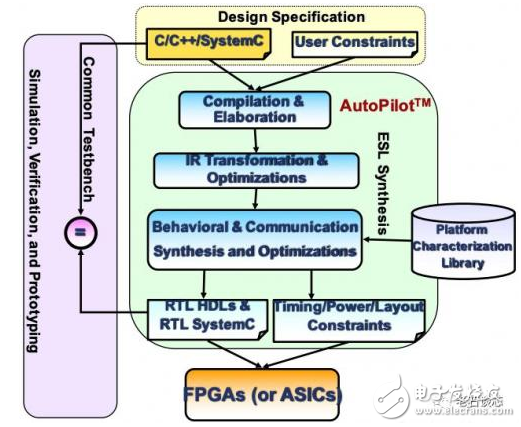
AutoPilot 的工作流程框圖如下圖所示。在前端,它使用了基于 LLVM 的編譯器架構(gòu),能夠處理可綜合的 ANSI C、C++,以及 OSCI SystemC 等語(yǔ)言編寫(xiě)的模型。這個(gè)名為 llvm-gcc 的前端編譯器會(huì)將高層語(yǔ)言模型轉(zhuǎn)換為中間表達(dá)式(IR),并進(jìn)行一系列針對(duì)代碼復(fù)雜度、冗余、并行性等方面的代碼優(yōu)化。然后再根據(jù)具體的硬件平臺(tái),綜合生成 RTL 代碼、驗(yàn)證與仿真環(huán)境,以及必須的時(shí)序和布局約束等。
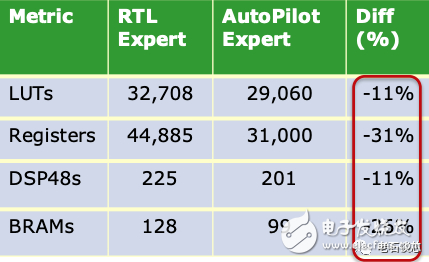
AutoPilot 的成功之處在于,它的 HLS 結(jié)果在某些應(yīng)用領(lǐng)域完勝人工優(yōu)化 RTL 取得的結(jié)果。例如,在一個(gè)無(wú)線 MIMO 系統(tǒng)中使用的 Sphere 解碼器 IP 中,AutoPilot 將 4000 行 C 代碼算法成功綜合到 Virtex5 FPGA 上,運(yùn)行在 225MHz,并取得了比賽靈思 Sphere 解碼器 IP 更少的邏輯資源使用量,見(jiàn)下圖。這個(gè)結(jié)果放在現(xiàn)在也令人十分震撼,它很好的證明了 HLS 有潛力取得比 RTL IP 更為出色的性能。
高層次綜合工具常用的優(yōu)化方法
傳統(tǒng)的處理器編譯器設(shè)計(jì)通常只有一個(gè)主要目標(biāo),那就是盡量提升性能。相比之下,高層次綜合工具需要統(tǒng)籌考慮各種電路設(shè)計(jì)的主要指標(biāo),如性能、功耗、面積等等,同時(shí)也要兼顧工具本身的性能,比如占用的資源和運(yùn)行時(shí)間等。因此,在開(kāi)發(fā) HLS 工具時(shí),要額外考慮和采用更多的優(yōu)化方法,而這些優(yōu)化方法也是當(dāng)今學(xué)術(shù)界和工業(yè)界在 HLS 領(lǐng)域重點(diǎn)研究的方向。總的來(lái)說(shuō),HLS 工具的主流優(yōu)化方法有以下幾種。
01
字長(zhǎng)分析和優(yōu)化
FPGA 的一個(gè)最主要特點(diǎn)就是可以使用任意字長(zhǎng)的數(shù)據(jù)通路和運(yùn)算。因此,F(xiàn)PGA 的 HLS 工具不需要拘泥于某種固定長(zhǎng)度(如常見(jiàn)的 32 位或 64 位)的表達(dá)方式,而可以對(duì)設(shè)計(jì)進(jìn)行全局或局部的字長(zhǎng)優(yōu)化,從而達(dá)到性能提升和面積縮減的雙重效果。
然而,字長(zhǎng)分析和優(yōu)化需要 HLS 的使用者對(duì)待綜合的算法和數(shù)據(jù)集有深入的了解,這也是限制這種優(yōu)化方式廣泛使用的主要因素之一。
02
循環(huán)優(yōu)化
循環(huán)優(yōu)化一直是 HLS 優(yōu)化方法的研究重點(diǎn)和熱點(diǎn),因?yàn)檫@是將原本順序執(zhí)行的高層軟件循環(huán)有效映射到并行執(zhí)行的硬件架構(gòu)的重點(diǎn)環(huán)節(jié)。
循環(huán)優(yōu)化的最終目的,就是盡量將循環(huán)里兩次相鄰的操作以最小的時(shí)延實(shí)現(xiàn),理想情況下,相鄰的循環(huán)操作可以完全并行執(zhí)行。然而,由于硬件資源的限制,以及更多的是因?yàn)檠h(huán)間存在嵌套和依賴關(guān)系,很難將循環(huán)完全展開(kāi)。如何優(yōu)化各種循環(huán),以實(shí)現(xiàn)最優(yōu)的硬件結(jié)構(gòu),就成為了學(xué)術(shù)界和工業(yè)界最為關(guān)心的要點(diǎn)。
一個(gè)流行的循環(huán)優(yōu)化方法,就是所謂的多面體模型,即 Polyhedral Model。多面體模型的應(yīng)用非常廣泛,在 HLS 里主要被用來(lái)將循環(huán)語(yǔ)句以空間多面體表示(見(jiàn)下圖),然后根據(jù)邊界約束和依賴關(guān)系,通過(guò)幾何操作進(jìn)行語(yǔ)句調(diào)度,從而實(shí)現(xiàn)循環(huán)的變換。
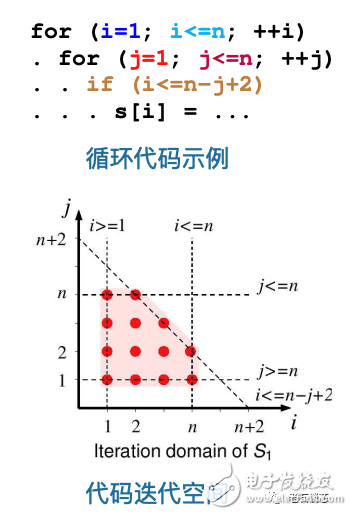
需要指出的是,多面體模型在 FPGA HLS 里已經(jīng)取得了相當(dāng)?shù)某晒Γ芏嘌芯烤C明多面體模型可以幫助實(shí)現(xiàn)性能和面積的優(yōu)化,同時(shí)也能幫助提升 FPGA 片上內(nèi)存的使用效率。
03
對(duì)軟件并行性的支持
C/C++與 RTL 相比,一個(gè)主要的區(qū)別是,前者編寫(xiě)的程序被設(shè)計(jì)用來(lái)在處理器上順序執(zhí)行,而后者可以通過(guò)直接例化多個(gè)運(yùn)算單元,實(shí)現(xiàn)任務(wù)的并行處理。隨著處理器對(duì)并行性的逐步支持,以及如 GPU 等非處理器芯片的興起,C/C++開(kāi)始逐漸引入對(duì)并行性的支持。例如,出現(xiàn)了 pthreads 和 OpenMP 等多線程并行編程方法,以及 OpenCL 等針對(duì) GPU 等異構(gòu)系統(tǒng)進(jìn)行并行編程的 C 語(yǔ)言擴(kuò)展。
因此作為 HLS 工具,勢(shì)必要增加對(duì)這些軟件并行性的支持。例如,LegUp 就整合了度 pthreads 和 OpenMP 的支持,從而可以實(shí)現(xiàn)任務(wù)和數(shù)據(jù)層面的并行性。
另外,Altera 在被英特爾收購(gòu)之前就已經(jīng)推出了 OpenCL SDK,可以將 OpenCL 進(jìn)行高層次綜合,并生成 FPGA 電路邏輯與 CPU 代碼兩部分,從而實(shí)現(xiàn) FPGA 作為硬件加速模塊的快速開(kāi)發(fā)。
高層次綜合的發(fā)展前景
HLS 經(jīng)過(guò)十?dāng)?shù)年的發(fā)展,雖然有諸如 AutoPilot、OpenCL SDK 等 FPGA HLS 商業(yè)化成功的案例出現(xiàn),但距離其完全替代人工 RTL 建模還有很長(zhǎng)的路要走。
比如,對(duì)于 FPGA 而言,內(nèi)存瓶頸一直是制約系統(tǒng)性能的重要因素。除片上的各類 BRAM 之外,還有各類片外存儲(chǔ)單元,如 DDR、QDR,以及近年興起的 HBM 等等。因此,有效利用片上和片外各類存儲(chǔ)單元一直是 HLS 的研究熱點(diǎn)。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論