 電子發燒友App
電子發燒友App


Residual Pattern Learning: 在不影響模型閉集表現的情況下分割異常物體
Out-of-Distribution (OoD) Segmentation 是在原有的閉集分割器的基礎上, 讓模型進一步擁有識別異常物體的能力。現在的SOTA的方法都是基于重新fine-tuning/retraining整個閉集Segmentation網絡, 這樣會導致對原本inlier object的性能下降。同時, 大多數OoD的辦法很難對多個不同的環境進行很好的擬合, 導致識別異常物體的性能在不同的場景會落差很大。
在這里和大家分享一波我們ICCV 2023中稿的工作 "Residual Pattern Learning for Pixel-wise Out-of-Distribution Detection in Semantic Segmentation". 在本次工作中, 我們針對當前OoD Segmentation中的兩個問題進行了優化, 并且用consistent checkpoint 在所有數據集上取得了非常好的性能。? ? ? ??

背景:
語義分割模型用于將像素級別的sample分類到 In Distribution (ID) 類別中。然而,當在開放世界中部署時,這些模型的可靠性不僅取決于其對ID像素的分類能力,還取決于其對Out-of-Distribution (OoD) 像素的檢測能力。比如在autonomous driving的任務中, 路上出現一些障礙物 (OoD object, 比如說`路障`) 的時候, 傳統的閉集semantic segmentation并不能很好的檢測出這些物體。因為原本的segmentation 模型在訓練的時候并沒有定義這些種類, 導致這類物體會被判定成head categories (e.g., road), 會對駕駛造成潛在的危險。
OoD Segmentation方向概述:?
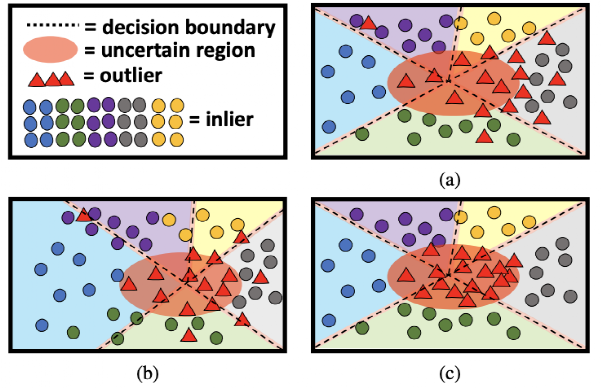
1). 鎖網絡: 最straight forward的方法就是直接通過softmax 或者 energy的結果來把segmentation輸出的mask里面潛在的low confidence pixel判斷成OoD。這種方法的好處是不會影響ID的segmentation性能, 并且不需要訓練網絡, 但是在遇到復雜的inlier或者outlier的時候, 性能會下降的很明顯, 如上圖 (a) 所示。
2). 重新訓練: 最近的辦法主要是通過Outlier Exposure (OE) 將一個不相干的OoD數據集加入到ID數據集, 然后fine-tune已經訓練好的close-set segmentation模型。在這個fine-tuning過程中, 利用新加入的OoD object來強行增加原本segmentation模型對異常的敏感度, 使得其OoD分割的性能得到了非常大的提升。但是這類方法的重新訓練會導致原本ID類別的分割的性能受到不可逆的干擾, 如圖 (b) 所示。
由這兩點為motivation, 我們想要在保留原本inlier的分類性能的情況下, 得到一個穩定有效的OoD 分割器。
方法:?
1). Residual Pattern Block (RPL):
與以往直接fine-tuning/retraining 分割網絡不同, 我們在在原本的網絡上外接了一個輕便的RPL block (frpl),然后原本的segmentation模型會全程鎖住。基本思路是, frpl block對ID的pixel不做任何影響, 但是對潛在的OoD pixel做一個擾動, 讓對應的confidence大幅下降, 進而通過最終map里的energy來判別是不是異常。
在訓練過程中, 我們先用原本的網絡生成 y_tilde (ID pseudo label):
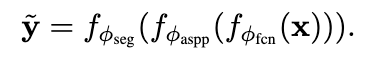
然后用RPL擾動后的原本網絡的結果:
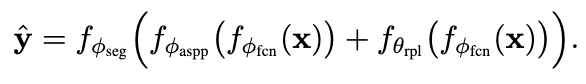
對ID的pixel, 我們用cross-entropy來做penalty, 保證原本對OE的OoD object, 我們用下面的Energy cost function來約束他的能量

在訓練的過程中, RPL不會導致原本segmentation模型的性能受到影響, 并且能高效的分割出潛在的OoD pixel。
2). Context-Robust Contrastive Learning (CoroCL):
目前所有OoD Segmentation在不同場景下的表現都不穩定, 比如大多數分割器在城市場景下能夠很好的檢測到物體, 但是在以下鄉村的環境 (context) 下就會直接失效。
為了應對這個問題, 增強網絡對多個context的魯棒性, 我們引用了supervised contrastive learning。我們在RPL的基礎上多加了一層projection layer, 并且隨機提取四種樣本, 分別是
1). ID 場景里的 inlier pixel, 2). ID 場景里的OoD pixel,? ?? ? ? ? ? 和
和
3). OoD 場景里的inlier pixiel 4). OoD 場景里的OoD Pixel ?? ? ? ? ?
我們通過InfoNCE來將不同場景的Inlier pixel聚合到一起, 并且推遠OoD pixel? ? ? ?
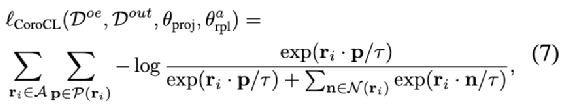
實驗:
1). Test Results (wandb visualisation: https://wandb.ai/yy/RPL?workspace=user-pyedog1976)? ? ?
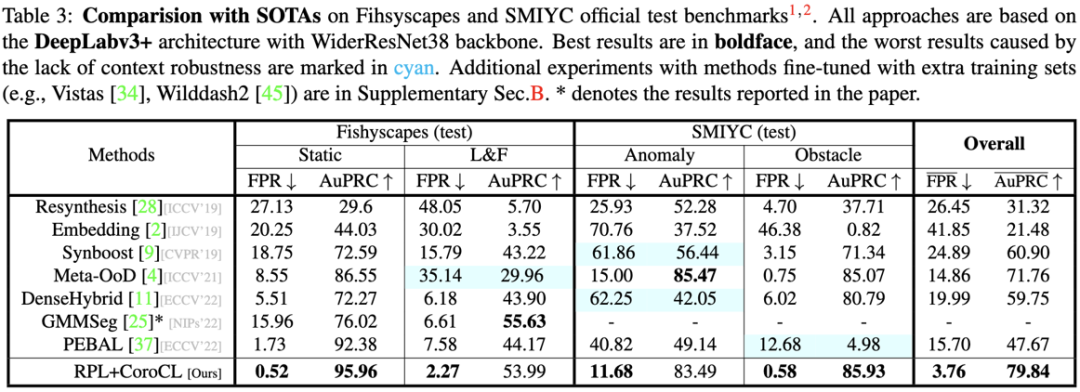
我們的結果在多個benchmark上獲得了最穩定的結果, 超過了之前的SOTA超過10個點的FPR和20個點的AuPRC。
2). Ablation Study
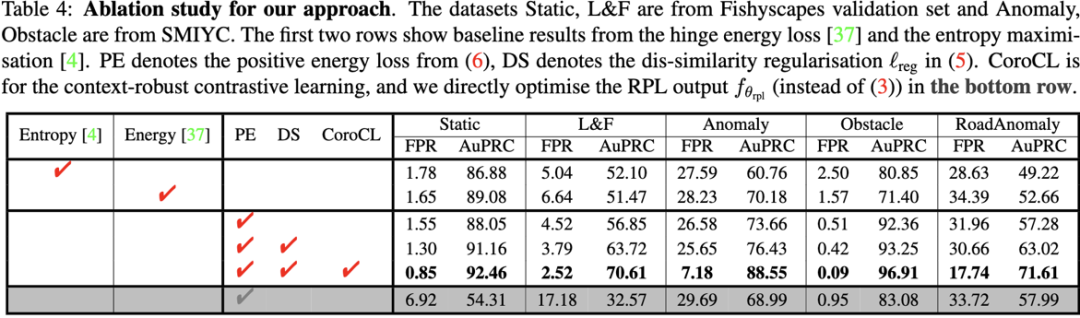
在消融實驗里, 我們可以先比較了用entropy和energy用來當loss的結果, 然后比較了使用RPL和直接使用一個binary OoD 檢測器 (最后一行), RPL與Energy帶來了穩定的提升。然而RPL在不同的context也有之前OoD segmentation的通病: 在FS-StaticL&F這種city環境下效果很好, 但是在其他的benchmark比如Anomaly&RoadAnomaly表現卻很差 (25.65 & 17.74), CoroCL很好的緩解了這個問題。
2.1). Ablation of RPL
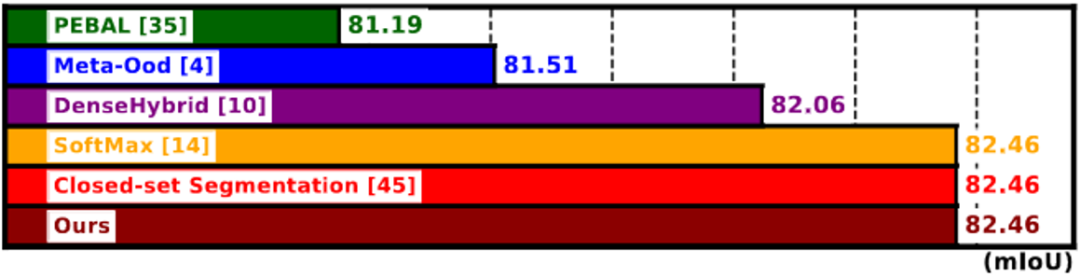
在上圖, 我們比較了原本close-set 分割模型的 mIoU [39] 和 其他re-training based OoD ([3], [9] and [31]) 在close-set的表現。我們的方法和freeze model 的方法 [13] 在ID數據集沒有改變, 但是我們的方法有更好的識別OoD pixel的性能 (如section 1.) 所示)。
?
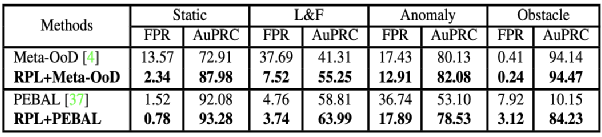
同時如上表, 我們RPL block可以對其他的OoD的方法在所有benchmark帶來進一步的提升。
2.2). Ablation of CoroCL
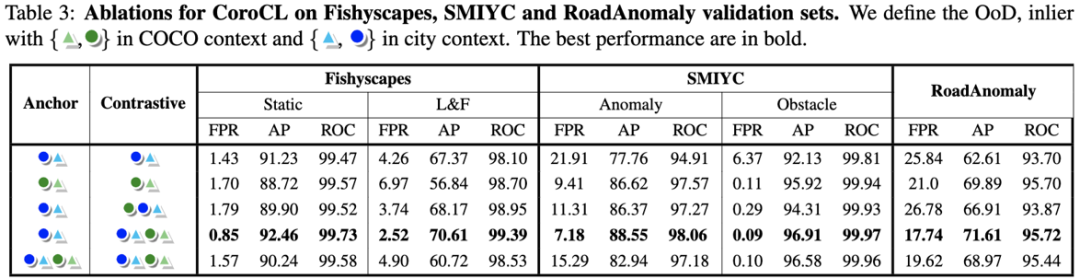
我們在對anchor set 和 contrastive set的選擇上, 測試了不同的組合。在最后我們發現當使用Anchor set為Inlier與OE, Contrastive set為全部種類時效果最好。在這種組合下, InfoNCE只會將 ?? ? ? ? ? 互相拉近, 推遠 ? ? ? ? ?
互相拉近, 推遠 ? ? ? ? ? , 但不會把兩種OoD ? ? ? ? ?拉近。
, 但不會把兩種OoD ? ? ? ? ?拉近。
3). The Learned RPL Feature
我們用self-attention
torch.einsum(’abc,bca->bc’,r, r.permute(1,2,0))
來可視化RPL的輸出學到的OoD pattern (r)。在上圖可以看到, RPL對潛在的OoD object會輸出擾動, 而ID的pixel會擬合0輸出。
3). Final Visualisation?
* 顏色越偏紅 代表異常可能性越高
編輯:黃飛
?











 工商網監
工商網監
評論