 電子發燒友App
電子發燒友App


前言
文章提出的概率退化模型 (PDM) 可以更好地將退化作用與圖像內容解耦。與之前的退化模型相比,PDM 可以生成具有更大退化多樣性的 HR-LR 訓練樣本,這可以生成更多種類的退化作用,并有助于提高 SR 模型在測試圖像上的性能。
9 學習圖像盲超分的退化分布 PDM
論文名稱:Learning the Degradation Distribution for Blind Image Super-Resolution (CVPR 2022)
9.1 盲超分任務介紹
作為基本的 low-level 視覺問題,單圖像超分辨率 (SISR) 越來越受到人們的關注。SISR 的目標是從其低分辨率觀測中重建高分辨率圖像。目前已經提出了基于深度學習的方法的多種網絡架構和超分網絡的訓練策略來改善 SISR 的性能。顧名思義,SISR 任務需要兩張圖片,一張高分辨率的 HR 圖和一張低分辨率的 LR 圖。超分模型的目的是根據后者生成前者,而退化模型的目的是根據前者生成后者。經典超分任務 SISR 認為:低分辨率的 LR 圖是由高分辨率的 HR 圖經過某種退化作用得到的,這種退化核預設為一個雙三次下采樣的模糊核 (downsampling blur kernel)。 也就是說,這個下采樣的模糊核是預先定義好的。但是,在實際應用中,這種退化作用十分復雜,不但表達式未知,而且難以簡單建模。雙三次下采樣的訓練樣本和真實圖像之間存在一個域差。以雙三次下采樣為模糊核訓練得到的網絡在實際應用時,這種域差距將導致比較糟糕的性能。這種退化核未知的超分任務我們稱之為盲超分任務 (Blind Super Resolution)。
令 和 分別代表 HR 和 LR 圖片, 退化模型為:

式中, 代表輸入圖像, 代表卷積操作, 模型主要由 3 部分組成:模糊核 , 下采樣操作 和附加噪聲 。前人工作中最廣泛采用的模糊核是各向同性高斯模糊核 (Isotropic Gaussian Blur Kernel)。 一般為加性白高斯噪聲 (Additive White Gaussian Noise, AWGN)。Blind SISR 任務就是從 LR 圖片恢復 HR 圖片的過程。
9.2 為什么要學習圖像盲超分的退化分布
在盲超分辨率超詳細解讀 (一):模糊核迭代校正方法 IKC 中,我們介紹了一種模糊核迭代校正的盲超分方法 IKC。IKC 發現只有當我們預設的模糊核與圖片真實的模糊核相差不大的時候,超分的結果才顯得自然,沒有偽影和模糊。因此,IKC 提出了一種退化核的迭代校正方法。它的每次迭代都可以分成2步:
第1步:從 LR 圖片中估計模糊核 。
第2步:根據估計得到的模糊核 復原 SR 圖片。
這樣做的缺點是:第1步帶來的微小偏差或者錯誤將會對第2步的結果帶來較大的影響。所以,IKC 為了準確地估計模糊核 ,設計一個校正函數 ,它測量估計的模糊核 和真值之間的差異。先訓練好超分模型,之后迭代訓練預測器和校正器若干次,得到模糊核的一個較為準確的估計。最后借助這個模糊核完成超分的任務。
在盲超分辨率超詳細解讀 (二):盲超分的端到端交替優化方法 DAN (本文作者團隊) 中,作者設計了兩個模塊,分別是 Restorer 和 Estimator。Restorer 可以根據 Estimator 估計得到的模糊核 復原 SR 圖,而復原得到的 SR 圖又進一步輸入 Estimator 以更好地取估計模糊核 。一旦模糊核 被初始化,這兩個模塊可以很好地相互協作,形成一個閉環,反復迭代優化。通過這種方式,Estimator 可以利用來自 LR 和 SR 圖像的信息,這使得模糊核 的估計更加容易,解決了 IKC 的問題。
但是,IKC 和 DAN 兩個方法都預設退化完全取決于圖像的內容,所以都是通過一個判別模型 (IKC 的 Predictor 或者 DAN 的 Estimator) 借助圖片內容來估計模糊核 (退化作用)。但是真實世界圖片的退化作用隨機且與圖片的內容無關。這些判別模型無法建模不確定的退化作用,以及與圖片的內容無關的退化作用,限制了超分模型的性能。
所以,一種更好的解決方案是:我們不通過模型來得到退化作用,而是通過概率模型來建模退化作用。因此,本文作者提出了概率退化模型 (Probabilistic Degradation Model,PDM),可以學習盲圖像超分辨率的退化分布。
具體而言,作者把退化模型建模成:
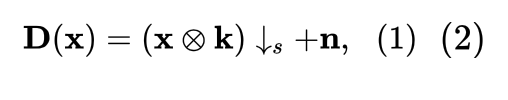
式中, 代表輸入圖像, 代表卷積操作, 模型主要由 3 部分組成:模糊核 , 下采樣操作 和附加噪聲 。
那么這里 的分布就可以看做是模糊核 和附加噪聲 的聯合分布, 這可以通過學習從先驗隨機變量 到 和 的映射來建模。
這樣一來,PDM 就可以建模退化作用中的隨機變量,并把退化作用與圖片的內容進行解耦。學習好了 PDM 之后,PDM 可能更容易涵蓋所有測試圖像的各種退化,并防止 SR 模型過度擬合特定圖像。PDM 可以作為一個數據生成器,并可以很容易地與現有的 SR 模型集成,以幫助它們提高應用程序的性能。
9.3 模糊分布建模
上式2中的退化過程包含線性的2步:

式中, 是不含噪聲的模糊,下采樣之后的結果。
直觀上,這兩個步驟是相互獨立的,因為模糊核主要取決于相機鏡頭 (camera lens) 的屬性,而噪聲主要與傳感器 (sensors) 的屬性相關。因此,退化分布可以建模為:
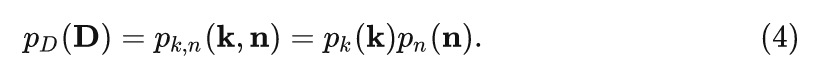
這樣, 和 的分布可以被獨立地建模以表示 的分布。
為了建模模糊核 的分布, 作者定義多變量高斯分布 (Multi-dimensional Normal Distribution) , 并通過生成模型學習從 到模糊核 的映射。
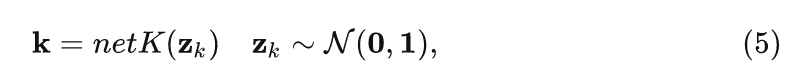
其中, net 是以卷積網絡為代表的生成模型。
不是一般性,作者首先考慮變化的模糊核:
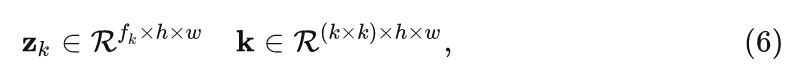
式中, 是正態分布的維度, 是模糊核的尺寸, 是特征的空間維度, 在 的最后一層添加了 Softmax, 以確保模糊核 的每一行之和為1。通常, net 中卷積核的大小被設置為 3 , 這表明所學習的模糊核是空間相關的。否則, 如果所有卷積權重的空間大小都設為 , 那 么每個像素的模糊核都是獨立的。
在大多數情況下, 模糊核 可以由空間不變核來近似, 也就是 的空間變化模糊核的特殊情況。我們有:
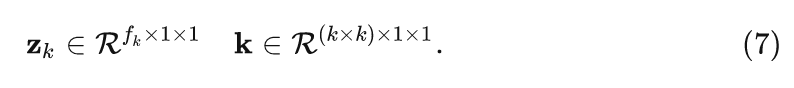
這種近似對于大多數數據集已經足夠好了。
9.4 噪聲分布建模
下面建模噪聲 的分布, 之前的大多數工作把噪聲建模成為一個加性白高斯噪聲 (Additive White Gaussian Noise, AWGN), 與圖像的內容 無關。在這種情況下, 噪聲 的分布也可以用一個普通的生成模塊來表示:
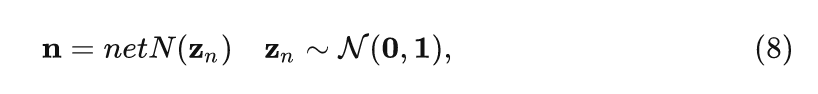
其中, net 是以卷積網絡為代表的生成模型。
不是一般性,作者首先考慮變化的噪聲:
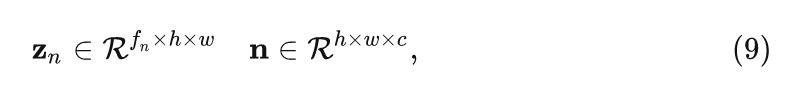
式中, 是正態分布的維度, 是特征的通道數, 是特征的空間維度。
在 CMOS 圖像傳感器中,以 OV5640 為例,其感光陣列如下圖1所示:
可以看到,感光陣列由紅、綠、藍三種感光點組成,B只識別藍色光,R只識別紅色光,Gb只識別綠色光,假如將這種每個感光像素點轉換成數字信號后直接輸出,就得到了 RAW 格式的圖像數據。
而 RGB 是 RAW 格式數據經過一系列處理后得到的圖像格式,當然,使用 CMOS 圖像傳感器話,傳感器內部集成了處理電路,只需要配置寄存器就可以選擇輸出 RAW 格式還是 RGB 格式數據。
人眼能感知的色彩其實是紅色、綠色、藍色三種原色的各種組合,紅綠藍三種顏色的按照不同比例組合最終會呈現出不同的顏色。這種以三原色組合的圖像格式是 RGB 格式,是目前應用最廣的圖像格式。RGB 有很多種格式,常用的有 RGB565,一共用 16bit 就可以表示三種分量;還有 RGB888,這一種格式需要 24bit 的數據來表示,正因為需要的 bit 數多,所以 RGB888 能表示的顏色比 RGB565 要多很多。如果對顏色精細度要求不是很高可以使用 RGB565,在很多計算過程中需要使用 RGB888。
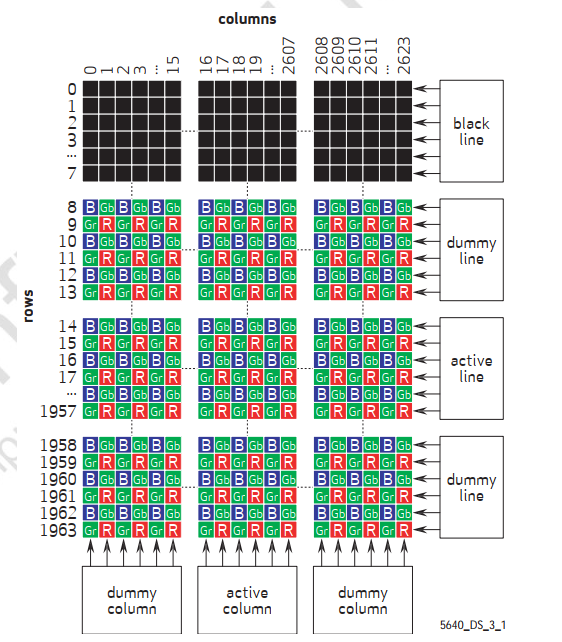
圖1:CMOS 圖像傳感器 OV5640 的感光陣列
所以說 RAW space 中的噪聲其實可以建模成拍攝噪聲 (shot noise) 和讀取噪聲 (read noise) 的混合。所以可以通過一個異質高斯分布來估計得到:
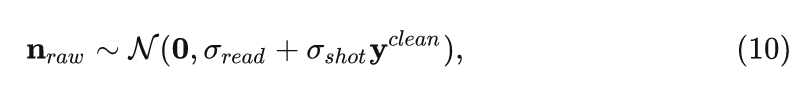
式中, 和 由相機的模擬和數字功放的增益決定。
拍攝噪聲 (shot noise) 一般是泊松分布,它與接受的光信號的強度有關,發生在光子信號讀取之后激發電信號的過程中。讀取噪聲 (read noise) 一般是高斯分布,它與接受的光信號的強度無關,一般發生在電信號從模擬信號到數字信號的 AD 轉換器的過程中,由數字功放的增益決定。
因為 RGB space 的噪聲 來自 RAW space 中的噪聲 , 并且與圖像內容有關, 所以噪聲 應該通過條件生成得到:
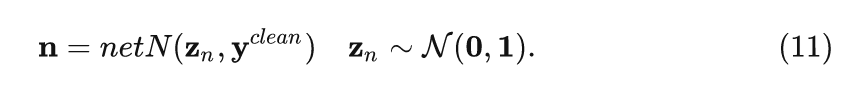
通常, net 中卷積核的大小被設置為 , 這表明所學習的噪聲是空間相關的。否則, 如果所有卷積權重的空間大小都設為 , 那么每個像素的噪聲則都是獨立的。
9.5 概率退化模型
上面兩節介紹的模糊模塊和噪聲模塊可以構造概率退化模型,用來生成訓練所需的 HR-LR 圖像對。
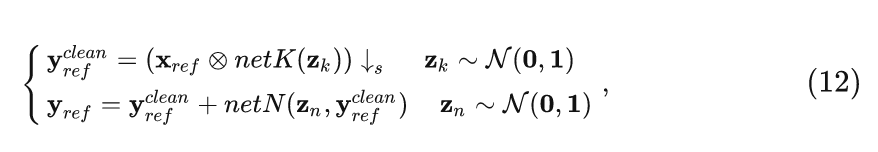
式中, 是參考的 HR 圖, 是用于訓練 SR 模型的一個訓練數據對。
PDM 通過對抗訓練優化, 希望合成的退化圖 與真實世界的圖像 更加接近。
作者一并假設噪聲 具有0均值, 所以在目標函數中再添加這一項:

所以,退化模型總的目標函數是:

PDM 的優勢是:
建模多種退化作用: PDM 可以建模多種退化作用,它允許 HR 圖片退化成為多種 LR 圖片。因此,對于相同數量的 HR 圖像,PDM可以生成更多樣的 LR 圖像,并為 SR 模型提供更多的訓練樣本,這可以更好地覆蓋測試圖像的退化。因此,PDM 可以彌合訓練和測試數據集之間的差距。
關于退化的先驗知識可以容易地結合到 PDM 中: 例如,如果我們觀察到在單個圖像中模糊幾乎是均勻的,那么我們可以調整 和 的形狀,以便只學習空間不變的模糊核。這種先驗知識有助于減少 PDM 的學習空間,并且可以鼓勵使其更容易被訓練。
9.6 利用概率退化模型構建盲超分框架
PDM 的框架如下圖2所示,它可以和 SR 模型一起訓練, 這樣,PDM 就可以與任何 SR 模型集成,形成 Blind SR 的統一框架,稱為 PDM-SR (或者 PDM-SRGAN,如果在 SR 模型的訓練中也采用了對抗性損失和 perceptual loss)。
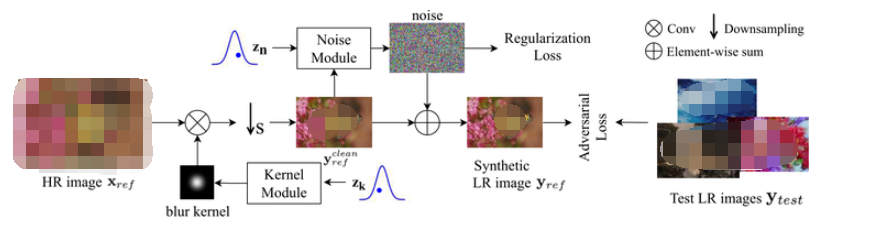
圖2:PDM 框架:退化模型 (對應下圖的 Degredation Model)
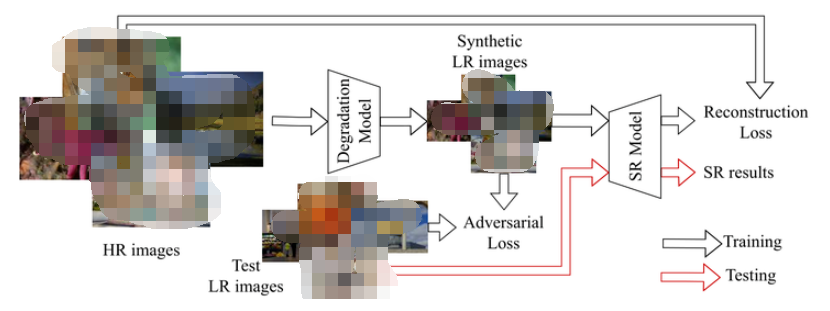
圖2:PDM 框架:訓練流程
9.7 PDM 訓練過程
實驗數據集: NTIRE2017 track2,NTIRE2018 track2 和 track4,NTIRE2020 track1 和 track2。
前三個數據集分別提供了用于訓練的 800,800 和 3200對 HR-LR 圖像和用于驗證的 100 對 HR-LR 圖像。因此,對于每個數據集,作者只使用前半部分 HR 圖像,后半部分 LR 圖像進行訓練。對于 NTIRE2020 的 track1 和 track2,由于他們提供的訓練樣本已經不成對,所以我們直接使用所有圖像進行訓練。
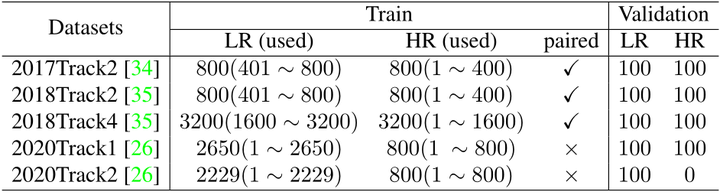
圖3:PDM 實驗數據集
對所有的數據集, 的 hidden dimension 設置為 。模糊核的維度設置為 , 為了簡單起見, 作者假設數據集中的模糊核是空間不變的。 的維度設置為 , 卷積核大小是 的。對抗訓練使用 PatchGAN discriminator, 為了公平比較, 所有比較的方法共享相同的 SR 模型:EDSR 和 RRDB。
訓練時將 HR 圖片 crop 成128×128大小,將 LR 圖片 crop 成32×32大小,batch size 設置為32,所有模型訓練 2 × 105 steps。優化器為 Adam,學習率 2e-4,每隔 5000 steps,減小一半。
由于參考的 SR 模型包括 PSNR-oriented (即 SR 模型由 L1/L2 損失監督) 和 perceptual-oriented (即 SR 模型由 perceptual loss 監督)的方法,作者還提供了我們的方法的兩個版本,即 PDM-SR 和 PDM-SRGAN。如下圖4所示, 就 LPIPS 而言,PDM-SRGAN 的性能遠遠優于其他方法。就 PSNR 和 SSIM 而言,PDM-SR 也取得了最佳的整體性能。特別是在 SSIM 上,PDM-SR 遠遠優于其他所有方法。
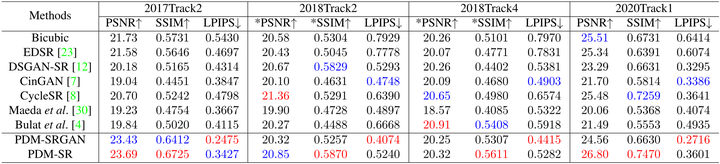
圖4:PDM-SR 和 PDM-SRGAN 的實驗結果
下圖5是 2017 Track2 的 0827x4 圖片和 2018 Track2 的 0860x4m 圖片的視覺比較結果。2017 Track2 的 0827x4 是一張非常模糊的圖片,它的 SR 結果將可能具有不期望的偽像。可以看到,通過其他方法超分辨率的結果仍然模糊,而 PDM-SR 成功地消除了模糊。2018 Track2 的 0860x4m 受到復雜噪聲的影響。如圖所示,PDM-SR 的結果比其他方法更清晰,表明 PDM 也能更好地模擬隨機噪聲。

圖5:2017 Track2 的 0827x4 圖片和 2018 Track2 的 0860x4m 圖片的視覺比較結果
作者進一步與 Real-ESRGAN 和 BSRGAN 等預訓練模型進行了比較,這些方法都是 perceptual-oriented 的,因此作者這里使用 PDM-SRGAN 進行比較。超分模型和其他基線方法一樣,都是 RRDB。如下圖6所示,PDM-SRGAN 在 2020 Track1 實現了最高的 SSIM 和 LPIPS,在 2020 Track2 實現了最好的 NIQE。下圖7是 2020 Track2 的圖片 0010 和 0097 的視覺比較結果。可以看出,Real-ESRGAN 和 BSRGAN 等的方法產生的 SR 結果更可能過于平滑,而這些細節在 PDM-SRGAN 中得到更好的保留。
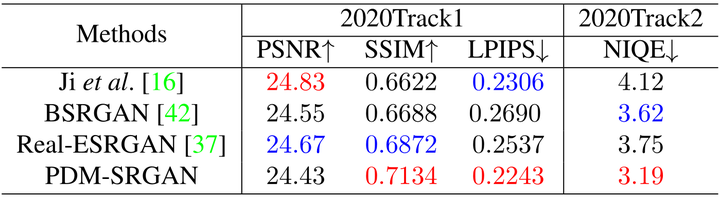
圖6:PDM-SRGAN 與預訓練模型比較

圖7:2020 Track2 的圖片 0010 和 0097 的視覺比較結果
下圖8所示 2017 Track2 數據集合成的 LR 圖和模糊核,可以看出它與高斯核有很大不同。學習到的模糊核是分散而非緊湊的。圖9是 2018 Track4 數據集合成的 LR 圖和模糊核,它呈現出對稱的形態,且噪聲是彩色的,與圖片內容有關。

圖8:2017 Track2 數據集合成的 LR 圖和模糊核

圖9:2018 Track4 數據集合成的 LR 圖和模糊核
總結
本文作者將退化函數作為隨機變量進行研究,并將其分布建模為模糊核 和隨機噪聲 的聯合分布。所提出的概率退化模型 (PDM) 可以更好地將退化作用與圖像內容解耦。與之前的退化模型相比,PDM 可以生成具有更大退化多樣性的 HR-LR 訓練樣本,這可以生成更多種類的退化作用,并有助于提高 SR 模型在測試圖像上的性能。此外,PDM 提供了一個靈活的退化作用,可以根據不同的實際情況進行調整。將來,作者可能會在 PDM 中添加一個額外的可學習的 JPEG 壓縮模塊,以進一步使其能夠模擬 JPEG 壓縮的退化作用。
編輯:黃飛
?









 工商網監
工商網監
評論