 電子發(fā)燒友App
電子發(fā)燒友App


1
引言
先給大家先算個賬:假設我要 GPT4 Turbo 幫我總結一篇 5000 字的文章,生成的總結是 500 個漢字,總共需要多少錢?這是一道數(shù)學題。
已知條件是:
一個漢字約等于 2 個 token
OpenAI GPT 4 Turbo 的價格是:輸入$0.01/K token,輸出$0.03/K token
解答:
總結 5000 字的文章總金額 = 0.01 輸入 token 數(shù)/1000 + 0.03 輸入 token 數(shù)/1000 = $0.13,也就是 9 毛錢。
如果按照我每天 10 篇文章的閱讀量,每年要 9365 = 3285 元,這個數(shù)字對我來說還是太貴了(也許某些媒體機構可能會使用)。
看來要大規(guī)模應用 LLM,降低算力成本也是首要任務,這個話題非常廣泛,比如:
做模型的人可以思考怎么在模型側降低預訓練成本
以上兩者讓科學家們?nèi)ジ悖敲醋?AI 應用的是不是沒有辦法呢,也不全是,所以就構成了這篇文章的副標題:
作為 AI 應用開發(fā)者,目前以及未來有什么方法降低算力成本?
目前這方面的探討不多,大家多多指正。按照之前一篇講大模型 AI 應用架構中提到的四層結構,我認為AI 應用開發(fā)人員的降本方式集中在模型的選擇和應用層的使用上。
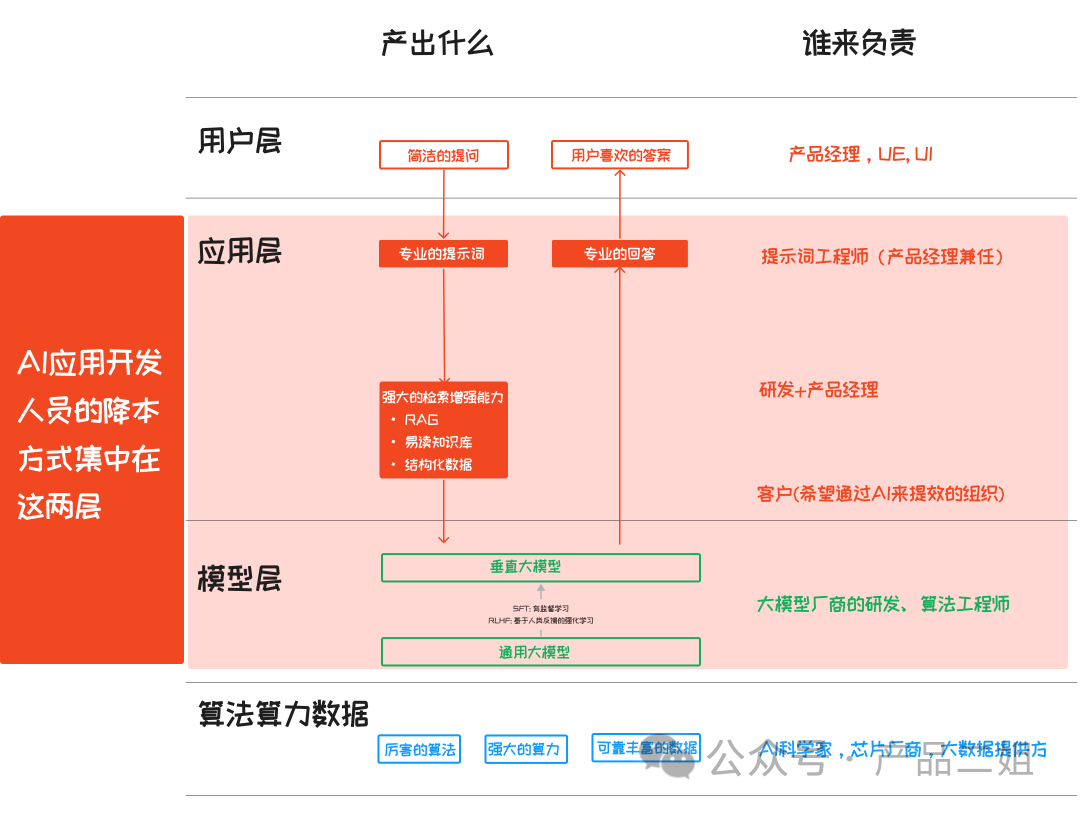
這一篇我們來講模型層的成本計算,應用層的下一篇來講。
2
AI 應用降本之“大模型選擇”
先說結論:
1.大概率來說,模型的定價和模型參數(shù)量、訓練數(shù)據(jù)的 token 量成正比。所以模型參數(shù)量越小,訓練數(shù)據(jù)的 token 量越小,成本越低。
2.參數(shù)量小,并不意味著模型能力也會低。評估小模型是否適用于你的場景,一看機構評測,二看垂直度,三親手實驗。
3.訓練數(shù)據(jù)的 token 量越小,也并不意味著模型能力低。訓練數(shù)據(jù)的質(zhì)量比數(shù)量更重要,使用時要考察數(shù)據(jù)質(zhì)量和數(shù)據(jù)垂直度。
4.可以嘗試采用“聯(lián)邦小模型”的方式,在應用側做好分發(fā),從而達到”花小模型的錢,享大模型的福”。
我們一個個來看。
3
模型消耗的重要因素:算力成本計算公式
注:這一部分的計算量有點大,不過都是加減乘除,大家輕松看待。
首先對于模型廠商來說:模型算力成本 = 預訓練成本 + 推理成本 。
3.1
預訓練成本
即訓練一個模型所需成本,按照過去 openAI 的節(jié)奏是每半年訓練一次。預訓練成本計算如下:
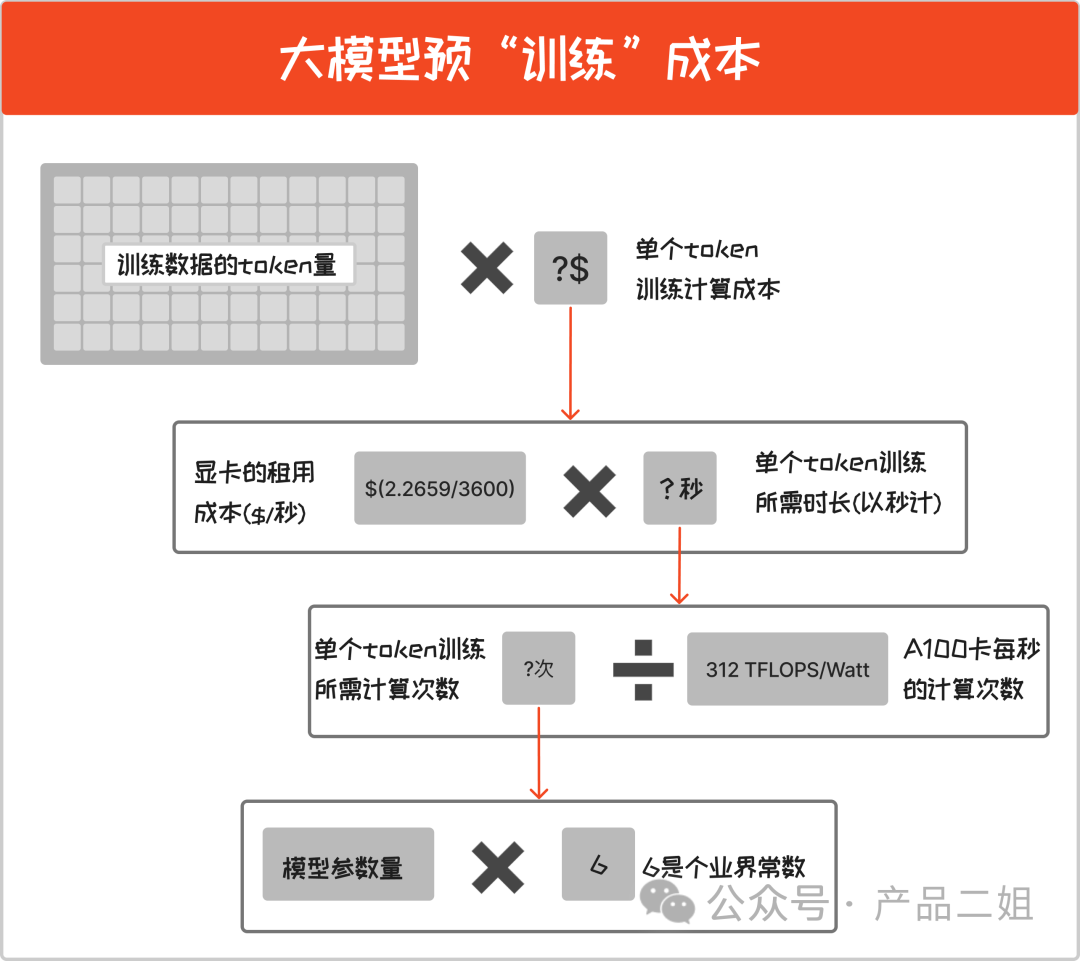
預訓練成本 = ( 模型參數(shù)量 6 /A100 卡每秒的計算次數(shù)) 顯卡的租用成本 訓練數(shù)據(jù)的 token 量
在這里有兩個兩個常量:
A100 卡每秒的計算次數(shù) = 312 TFLOPS/Watt (官方公布,每秒可以進行 312T 次浮點數(shù)計算)
顯卡租用成本:暫時以微軟 Azure 云上公布的 Nvdia A100 的三年期租用價格$2.2659/小時計算,本文按秒來計算,就是每秒租用價格為$(2.2659/3600) (參考 https://azure.microsoft.com/en-us/pricing/details/virtual-machines/linux/#pricing)
常量之外,還有兩個變量,他們與預訓練成本成正比:
模型參數(shù)量
訓練數(shù)據(jù)的 token 量
拿 openAI 的模型舉個例子大家感受一下(考慮到這里的顯卡成本是按照租用成本來計算的,openAI 作為顯卡消耗大戶,咱們可以直接打個五折):
GPT3 的參數(shù)量是 175B,訓練數(shù)據(jù)的 token 量 500B,約 105 萬美元*5 折,約 372.75 萬元。
GPT4 的參數(shù)量是 1800B,訓練數(shù)據(jù)的 token 量 13T, 費用是 GPT3 的 280 倍,約 1.45 億美元,人民幣 10 億元。
GPT4 Turbo 的參數(shù)量是 8*222B ,訓練數(shù)據(jù)的 token 量 13T,費用與 GPT4 差不多。
注:GPT4 和 GPT4 Turbo 的參數(shù)量和訓練數(shù)據(jù) token 量均為坊間普遍傳聞,并未得到 openAI 證實。
預訓練成本算出來之后,我們看看算力成本的另外一項:推理成本。
3.2
推理成本
即每次用戶問答時消耗的算力成本,是按用量來消耗的,我們就按照 open AI 的定價單位:每千個 token 來算。
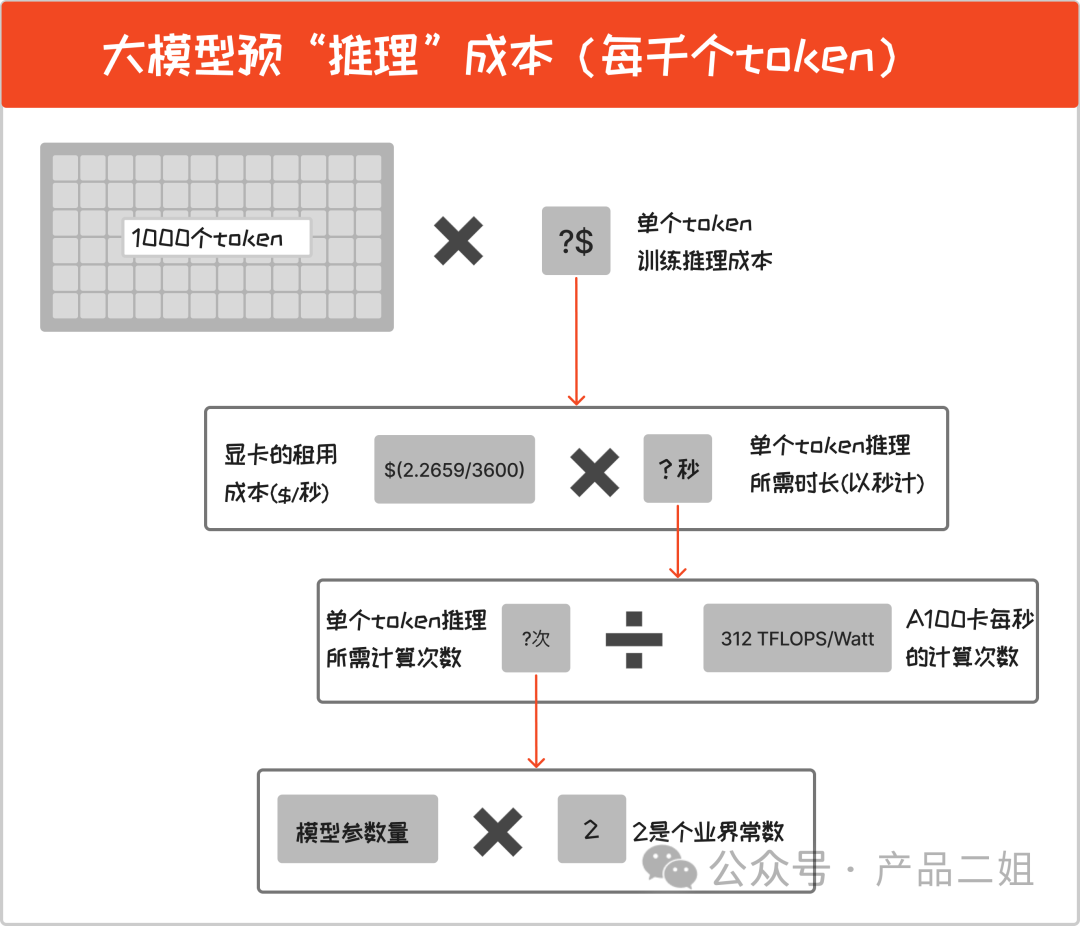
每千個 token 推理成本 = 1000( 模型參數(shù)量2 /A100 卡每秒的計算次數(shù))顯卡的租用成本
推理成本僅與模型參數(shù)量成正比,拿 OpenAI 最新的 GPT4 Turbo 模型舉例:
GPT4 Turbo 的參數(shù)量是 8222B,按照上述公式計算,每千個 token 推理成本 = $0.0071656。
到這里大家可能會好奇:openAI 到底要有多少使用量、多少用戶才能收回成本?這個問題我放在文末。我們先來總結一下這一部分的核心:
模型的算力成本與模型參數(shù)量和所使用訓練數(shù)據(jù)使用的 token 量成正比,大概率來說(因為定價不一定總是以成本為標準):
模型參數(shù)量越少,成本越低
訓練數(shù)據(jù)的 token 數(shù)量越少,成本越低
但是模型參數(shù)量變小了,訓練數(shù)據(jù)的 token 數(shù)量越少,是不是意味著效果也會變差?當然不是,比如 9 月份發(fā)布的 Mistral 7B,只有 70 億參數(shù),就能匹敵 Llama 1 34B(擁有 340 億參數(shù))。當然,目前來說,GPT4 Turbo 是公認的一騎絕塵,但在 GPT4 之下:
沒有最大的模型,只有最合適的模型。
因為從產(chǎn)品角度,我們有時并不需要模型有那么多的參數(shù)量,也不需要模型訓練那么多數(shù)據(jù),這時候我們就需要評估:
參數(shù)量小的模型能不能滿足我們的使用場景?
預訓練數(shù)據(jù)量低的模型能不能滿足我們的使用場景?
引出接下來的話題。
4
如何評估小模型能不能滿足我們的使用場景
首先個人認為當前情況下這個評測僅在你無法使用 GPT4 的時候有意義。同等能力下,優(yōu)先使用參數(shù)小的模型。評測大體可以做以下幾步操作:
先看評測機構的結果,各自都有不同的方法。早些時候我在知乎上有一篇《大模型技術哪家強,找對機構看排行》,里面提到一些機構,當然現(xiàn)在也誕生了很多新的評測機構,大家可以參考。
結合你自己的使用場景,比如注重推理,還是注重表達來選擇。
最后親手去根據(jù)自己的場景做實驗,說白了,就是同樣的提示詞,你需要測哪個模型的效果最符合你的訴求,這一塊也有方法,我們留在以后討論。
值得借鑒的是,周末在聽知乎張俊林老師的訪談中提到:“ 在學術研究上,目前小模型的語言表達能力和知識獲取的能力上已經(jīng)可以和大模型匹敵,在推理能力上會弱,但目前也有途徑來解決,我們有望在今年解決。”
Mixrel 7B 就是一個很好的例子。再看看另外一個話題:預訓練數(shù)據(jù)量對模型的影響。
5
預訓練數(shù)據(jù)量低會對模型有哪些影響
目前看起來,訓練數(shù)據(jù)的質(zhì)量比數(shù)量更重要。對于大模型廠商來說,如何從繁多的數(shù)據(jù)中拿到高質(zhì)量的訓練數(shù)據(jù)是他們降低成本的重要工作。
另外一方面,以垂直領域數(shù)據(jù)作為訓練數(shù)據(jù),也會誕生出很多垂直領域的模型。這些模型從預訓練(而不是 SFT 微調(diào))數(shù)據(jù)上就開始垂直化。比如 Bloomberg 訓練出來的金融大語言模型(LLM for Finance,參數(shù)量為 500 億),使用了包含 3630 億 token 的金融領域數(shù)據(jù)集以及 3450 億 token 的通用數(shù)據(jù)集。
對于 AI 應用開發(fā)者來說,可以從垂直度和數(shù)據(jù)量大小兩方面考慮。
除此之外,張俊林老師也腦暴了另外一種省錢的方式:”聯(lián)邦小模型“(不用去百度,這是我起的名字),不妨也放在這里也來討論一下。
6
未來會有聯(lián)邦小模型嗎?
我所指的”聯(lián)邦小模型“是在應用層,未來如果有不同能力的模型,比如有的模型擅長表達,有的擅長推理,那么在應用層可以按照場景將問題分發(fā)給不同的模型,從而達到”花小模型的錢,享大模型的福”的效果。
以上就是我理解中的在模型層可以做的降低成本的方法,但目前在這方面的實踐行業(yè)內(nèi)都比較少,畢竟沒有那么多卡和經(jīng)歷去評測所有的模型,也歡迎大家一起討論。
最后解答一下大家可能好奇的問題:OpenAI 現(xiàn)在能收回算力成本嗎?
7
附加題:OpenAI 能收回算力成本嗎
7.1
openAI 的算力成本
我們以 openAI 每半年進行一次訓練為假設條件,看看 OpenAI 每個月的算力成本。
openAI 每月的算力成本= 預訓練成本/6 個月 + 每月 token 消耗量(千)*每千個 token 推理成本
也就是:
openAI 每月的算力成本= 1.45 億/6 + 每月 token 消耗量(千)0.007
7.2
方法一:假設 openAI 只有 Token 用量收費項目,每月賣出多少 Token 能收回成本
目前 openAI GPT4 Turbo 的官方報價如下圖:
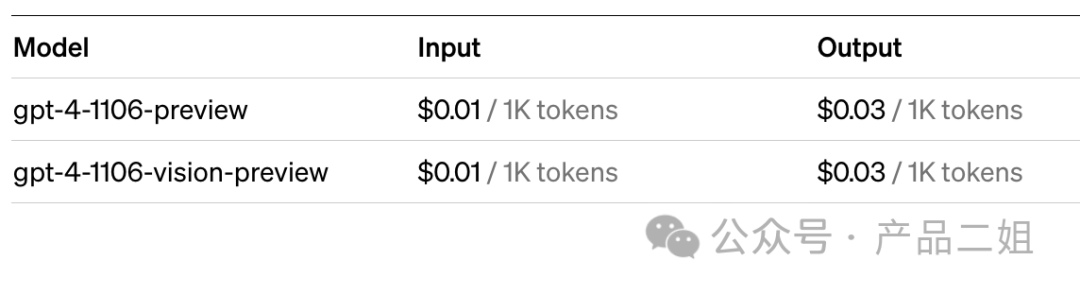
拍腦袋假設用戶的 Input 和 Output 比例為 1:1,那么平均價格就是$0.02/千 Token,推理成本(0.00716567)僅占其中的 36%,要想收回“訓練”成本 1.45 億美元,就靠價格中的另外 64%了。
按照目前的定價,我們可以得出:
openAI 每月的收入 = (每月 token 消耗量(萬億)2)千萬
結合 “openAI 每月的算力成本 = 2.4 千萬 + (每月 token 消耗量(萬億)0.7)千萬”,放在坐標系里:OpenAI 按量使用每月賣出 1.85 萬億 token 方可回本。
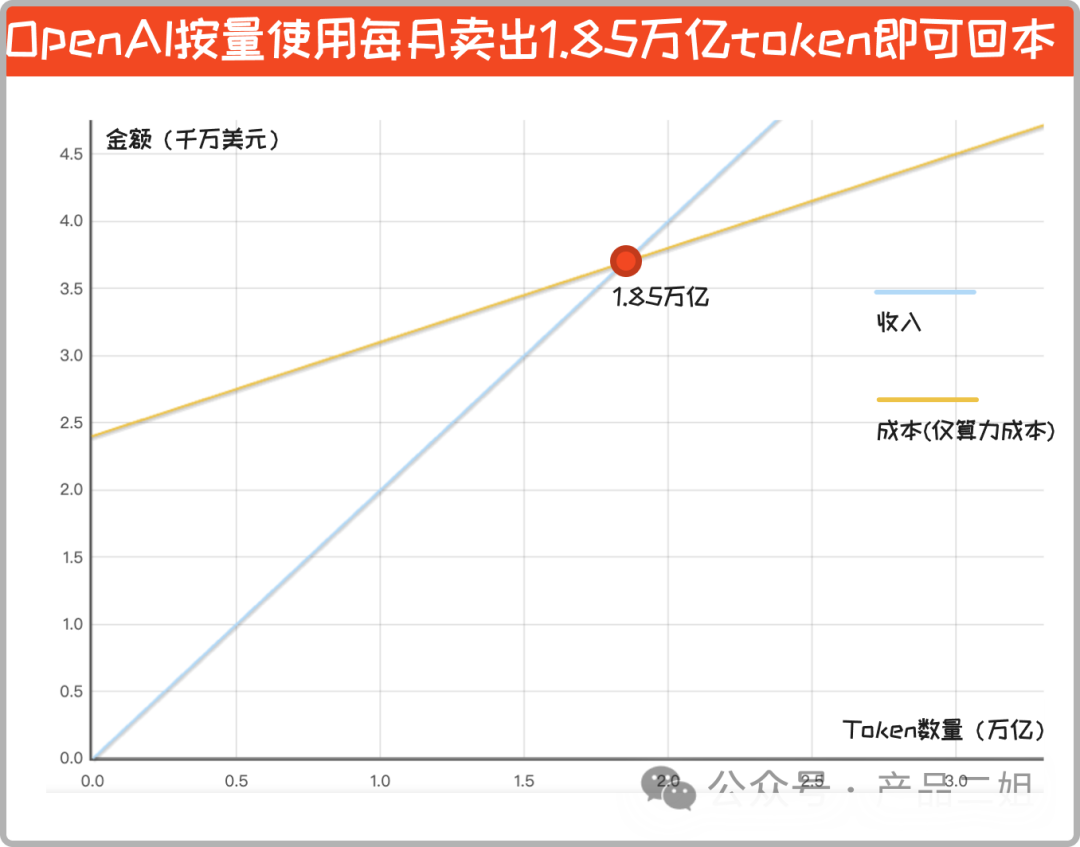
假設有一千萬個用戶,每個用戶每天要消耗:6154 個 Token,相當于問答產(chǎn)生 6154/1.3 = 4733 個單詞,這個要求應該不算高。
7.3
方法二:假設 openAI 只有 chatPLUS 會員訂閱收費,賣出多少用戶能收回成本。
OpenAI 的收入 = 用戶數(shù)$ 20 = (2用戶數(shù)(千萬))億美元
如果每個用戶都物盡其用,按照 openAI 官方回復:ChatPlus 會員每三個小時最多問 40 個問題,我參照我自己的使用情況:
平均每個英文問題約消耗 500 個單詞(約等于 500 個 token)。
醒著的 9 個小時最多問 120 個問題,
那么每月總共使用 30120 500 = 180(萬)個 token。
OpenAI 每月算力成本 = 1.45 億/6 + 每月 token 消耗量(千) 0.007
=(0.24 + 用戶數(shù)(千萬)平均每人每月 token 消耗量(萬) 0.007)億美元
放在坐標系里是這樣的:
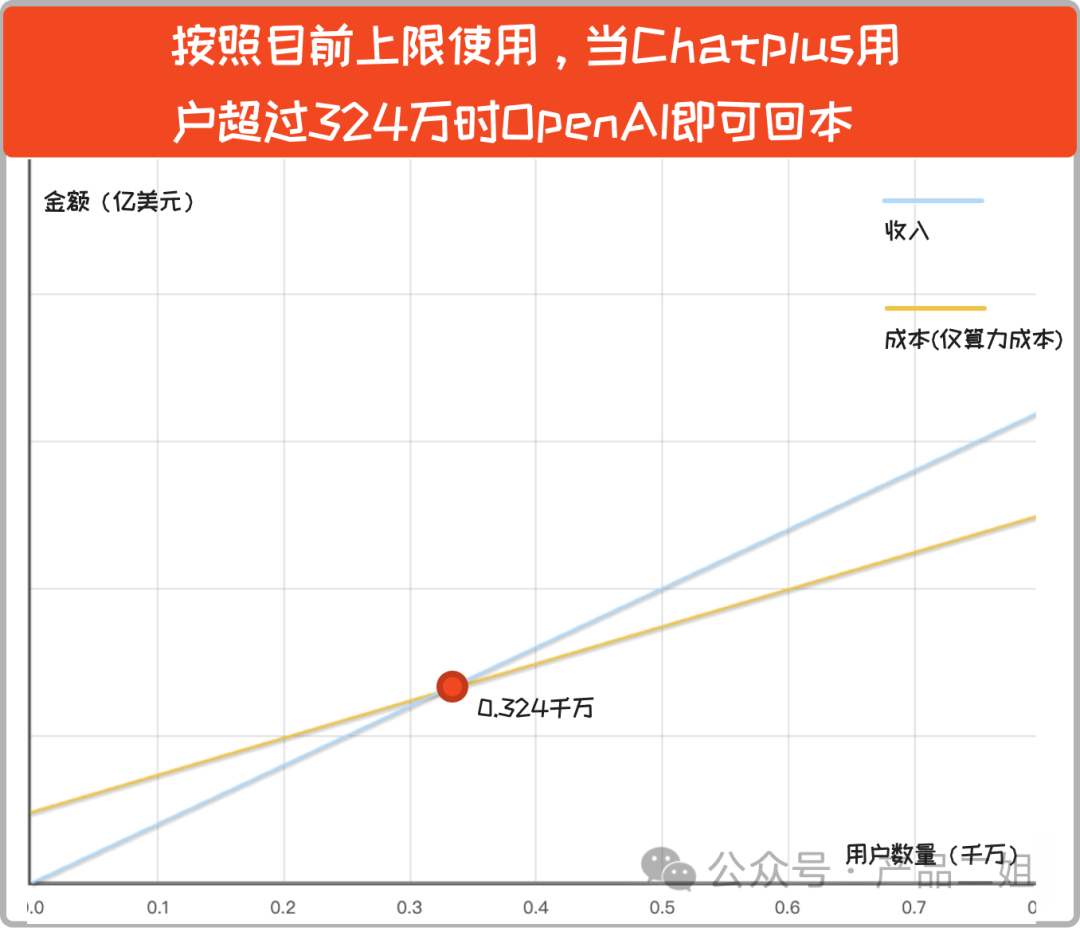
即使每個 Plus 用戶都物盡其用,只要用戶數(shù)量超 324 萬后,OpenAI 就開始盈利。
實際上,坊間流傳 Plus 會員平均每天的 token 數(shù)量可能在 6700 左右(我個人覺得評估偏低),如果是這樣的話,用戶數(shù)只要超過 129 萬,就可以實現(xiàn)盈利。
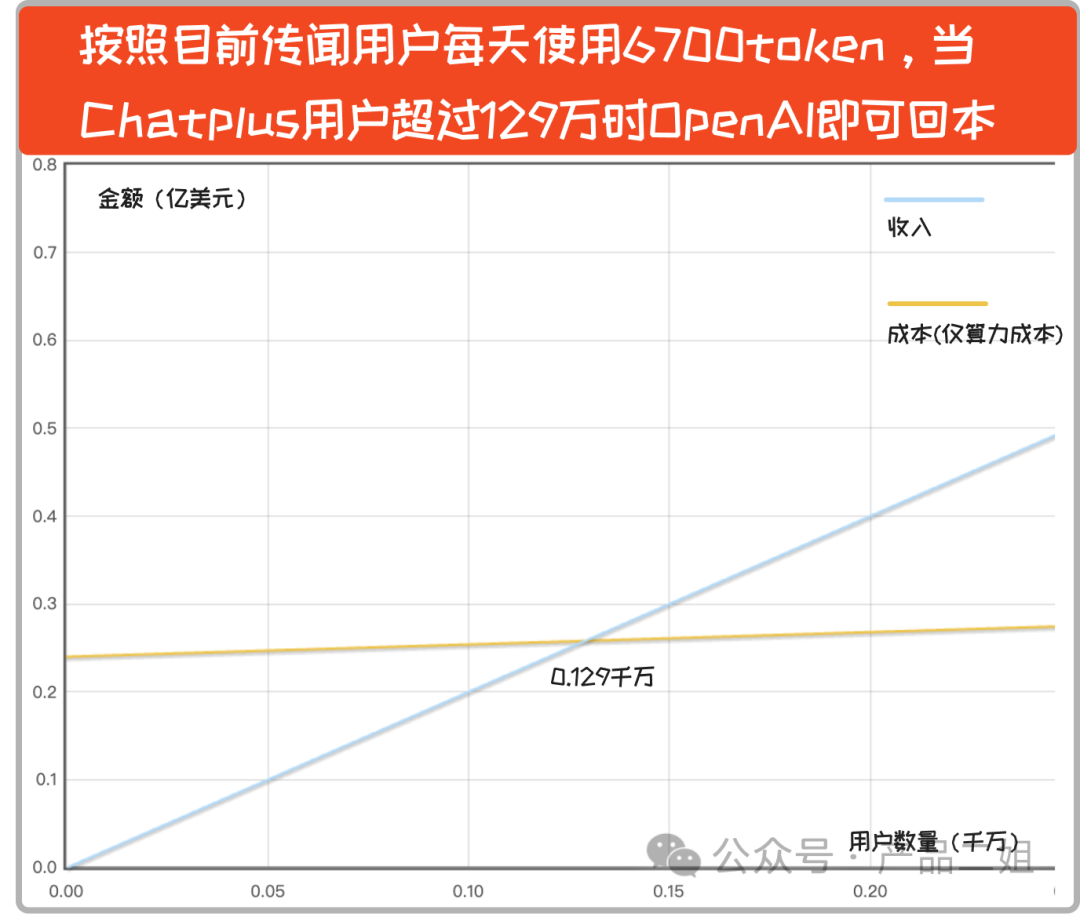
再次重申,以上成本不包含人力成本(目測怎么也有幾個億美元吧)
這一通計算下來,感覺 OpenAI 的定價目前也還算合理,也反映出來模型成本估算的方式也算正確。
如果未來 OpenAI 成為 Google 級的超十億大應用,加上算力成本下降(芯片、數(shù)據(jù)、模型優(yōu)化等方式),還有很大的降價空間,比如說降低到目前的千分之一。我們期待這一天的到來。
審核編輯:黃飛
?





















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論