 電子發燒友App
電子發燒友App


摘 要:本文選擇了一種新穎的圖像縮放算法進行FPGA硬件實現。該算法基于奇偶分解的思想,具有復雜度低、硬件需求小和縮放效果良好等突出優點。首先利用MATLAB對該算法進行了功能驗證,然后用縮放耗時、PSNR、邊緣模糊等級和脈沖噪聲等指標評估基于該算法圖像處理效果。與傳統時域算法作對比,對比結果表明該算法在處理效果和運算速度上的優異性。基于Zedboard開發板,運用Vivado HLS高級綜合工具將算法的C程序綜合成硬件IP,并搭建了包含ARM處理器和VGA等模塊的軟硬協同驗證系統。實驗驗證了圖像縮放算法硬件設計的正確性和實用性。
?
1. 引言
數字圖像處理因其廣泛應用于社會生活的各個領域,而成為了研究的熱點。圖像縮放是數字圖像處理中的一項基本而又關鍵的操作,多數圖像與視頻幀都是以壓縮的格式進行存儲和傳送,以降低存儲資源的占用,提高數據傳輸的效率。針對不同的應用,用戶通常需要不同分辨率的圖像。例如,在圖像數據傳輸過程中為節省帶寬,則通常需要發送低分辨率的圖像,而當接收到圖像后,進行顯示時又很希望看到高分辨率的圖像。盡管存在各種數據壓縮軟件,但數據的壓縮仍是有限的,而且數據的壓縮很可能已經對圖片造成了一定的損壞,并不能確保圖片關鍵信息的保留。圖像縮放算法有很多,總體可分為基于時域和頻域兩大類算法,在時域圖像縮放方法中,主要有最近鄰域算法、雙線性插值算法和雙三次線性插值等。雖然它們在改善圖像縮放處理后的失真度上逐漸增強,但其不斷下降的運算速度也成為了不容忽視的問題(特別在視頻幀放大中,圖片的切換頻率限制了縮放算法的可執行時間)。
這些算法中,有的通過PC機上的MATLAB、C等高級語言實現,有的基于ARM等嵌入式處理器實現,而有的則是基于FPGA這類芯片進行硬件的實現。由于PC機和ARM屬于多任務的操作系統,通過軟件編程實現縮放算法是其常用的圖像縮放處理手段。系統代碼解析和串行執行,以及多任務的切換等因素會嚴重降低圖像縮放效率和實時數據顯示,頻繁的圖像縮放會給系統的正常運行造成相當大的負擔。因此,本文重點研究第三種圖像縮放實現方法,充分利用FPGA的并行運算、高集成度、可編程和低成本特性,編程實現縮放算法的硬件結構和IP生成,為進一步實現專用圖像縮放處理芯片的開發和應用提供幫助,以釋放處理器,提高圖像縮放質量和效率。
在綜合考慮圖片處理效果、運算速度和硬件資源需求后,本文選擇了由Hoon Yoo和Byong-Deok Choi共同提出的算法[1] ——基于奇偶分解的分段加權插值的圖像縮放算法(簡稱WLI算法)進行硬件實現。
WLI算法借助于奇偶分解的理論,基于16個相關點實現了圖像中新點值的確立。本課題基于Xilinx的全可編程器件Zedboard,利用vivado hls高級綜合工具編寫可綜合的c程序,實現了WLI縮放算法的硬件IP設計,利用開發板實際縮放操作驗證了硬件縮放的高效率和低時間耗用特征,并通過圖像縮放的VGA對比顯示實驗對設計進行了驗證。同時,設計實現的IP也可以為圖像處理的SoC復用,降低SoC的開發難度。
2. 圖像插值算法及MATLAB仿真
2.1. 傳統插值算法
本文分別選取了最簡單的、基于四個相關點的最近鄰插值算法;有二階線性運算參與的雙線性插值算法;以及最復雜多浮點運算的雙三次插值運算作為對比算法,通過多種圖像質量和效率評價方法,來評估WLI算法的優劣性(具體算法實現參考 [2] 相關內容)。
2.2. WLI算法
WLI算法應用奇偶分解的思想,將一維縮放中相關的四個點進行奇偶分解(奇部和偶部的相關點值分解后的關系示例見圖1)。從定義上分析,奇部向量在頻域圖像數據處理中是一個高通濾波結構,相比于偶部向量,它具有更強的噪聲。而噪聲和高頻信號對該部分的影響往往會掩蓋該部分對正確縮放的像素點取值的貢獻,所以為盡量避免奇部向量中攜帶的噪聲等參量對縮放質量造成損害,對它進行簡單的線性化操作,得出公式(1)的處理方案。
因為偶部向量對稱的特性,其對縮放點的最終取值具有很大的影響度。直接的線性擬合雖然具有運算簡單的特點,但正如圖2所示,這會使得圖片點值的變化太快,影響視覺效果。為使該部分的取值具有緩慢變化的特征,基于平滑曲線的原型方程是一個很好的選擇,但曲線的復雜運算帶來的資源耗用往往使算法縮放得不償失。因此,引文對此部分的曲線公式進行分析討論,巧妙的引入w參數完成了運算方法的降次和近似,如圖2所示,最終得出同樣是一次方程的擬合曲線圖像插值計算公式(2)。
最終由圖3表示出了WLI算法基本單元的信號流處理流程,通過串行移位得到四個相關點,利用加/減操作和移位操作分別得到奇部向量和偶部向量。在s參量的調節下,取w = 0.5時,僅通過兩個乘法器便可實現最核心的操作,最后加和奇部和偶部,便得出最終的縮放結果。該結構僅包括6次加法和6次移位操作,并伴有3次延時和兩個乘法操作,總體硬件資源耗用較少,延時也較低,具備硬件化條件。
2.3. 算法的MATLAB仿真及評估
運用MATLAB語言,編寫程序實現縮放算法。將常用的幾種算法 [3] 進行了縮放耗時 [4] 、PSNR (Peak Signal to Noise Ratio)比較以及邊沿模糊度、脈沖噪聲兩種無參考圖像評測,并對結果進行了比較分析。
PSNR [5] 也叫峰值信噪比,它是最普遍、最廣泛使用的評鑒畫質的客觀測量方法,意指到達噪音比率的頂點信號,是衡量經過處理后的影像品質的客觀方法,用MATLAB實現的計算公式如(3)所示。
其中,MSE是原圖像與處理圖像之間均方誤差。
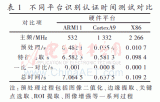
邊緣模糊度 [6] 是指階躍邊緣點占總邊緣點的個數的比例值,其值越小說明圖片邊緣更清晰,圖像質量越好。一般邊緣點的檢測是利用robel算子得到的,而在圖像中根據相關函數也可以判斷并統計出階躍邊緣點,由此便可計算出各個圖像的比例值,使用不同算法對多個圖片放大兩倍后計算出的邊緣模糊度結果如表1。
類似的,脈沖噪聲 [6] 是指圖像中噪聲像素點占總像素點的個數比例,圖像噪聲點是指根據局部圖片判斷出的本不該出現的點值,即該區域有一定的取值范圍,當超過該范圍后即認為該點是噪聲點。本文采用最小二乘法的預測模型進行容限計算,同時判斷和統計總的噪聲點個數,進而計算出不同圖片的脈沖噪聲值結果變化如圖4所示。
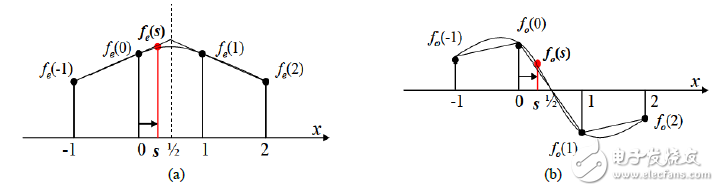
圖1. 奇偶分解相關點示意圖
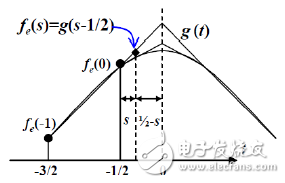
圖2. WLI算法偶部線性擬合示意圖
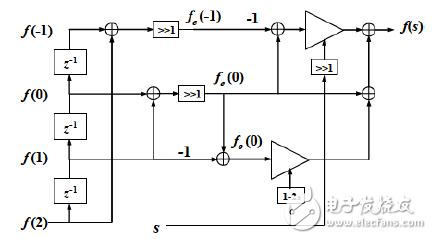
圖3. WLI算法基本結構數據流處理結構
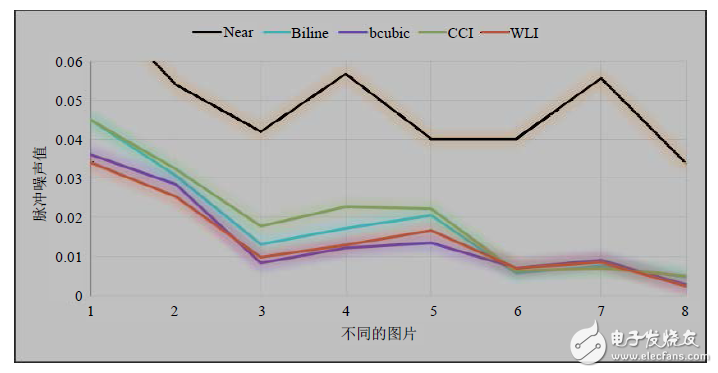
圖4. 多種算法放大2倍的圖片脈沖噪聲對比
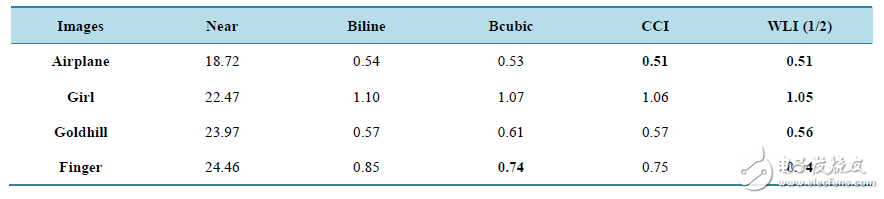
表1. 多種算法放大2倍的圖片邊緣模糊度
根據MATLAB的相關仿真數據,得出WLI算法不僅具有高PSNR值,低耗時等特征,從表1和圖4中的對比結果亦見,其邊緣模糊度和脈沖噪聲也相對較低,充分體現了該算法的優異性。
3. 硬件系統平臺的搭建
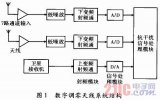
針對Xilinx可編程器件開發板Zedboard [7] ,進行算法的硬件實現和IP生成,同時對軟硬協同驗證系統平臺的設計和功能進行軟件和硬件劃分。如圖5所示,上位機中計算機(PC)負責把新的圖片數據傳送到開發板,或者從開發板接收縮放后的圖片數據,并打印各種處理信息和狀態值。顯示器顯示不同算法的縮放圖片直觀效果。而下位機(Zedboard)則主要完成控制信息編碼輸入,軟件或硬件圖像縮放算法實現,以及內部模塊間的圖片數據傳輸等功能。其中,輸入檢測和控制信息生成、執行,以及對比軟件縮放算法的實現等部分是分配給ARM處理器通過軟件完成的。
3.1. ZEDBOARD的控制輸入IP
該IP設計主要完成對5個按鍵以及2個開關狀態的檢測及編碼,使產生8位編碼數據,用以傳送給XPS構建的子系統的8位GPIO,以axi_lite相關協議映射編碼數據,從而將編碼輸入傳送到了PS (Processing System: ARM處理器)部分,用以軟件編程檢測和處理。
該設計的實現原理如圖6所示,通過計數模塊Count實現按鍵狀態的去抖檢測,兩個按鍵用于縮放算法選擇,并用三個Led的二進制實時顯示,另兩個按鍵用于選擇縮放倍數,一個按鍵用于錄入狀態與完成錄入狀態間的切換;兩個開關則分別控制放大/縮小、顯示使能。
3.2. WLI算法IP
3.2.1. Axi4接口
Axi4 [8] 是由Xilinx和ARM合作提出的便于全可編程器件內部ARM和FPGA之間數據的高速通信的總線標準。Zedboard內部使用Axi4,可細分為Axi_lite、Axi4、Axi_stream三大類,包含地址、數據和反饋通道。能實現ARM和FPGA內部的高速并行數據通信,并支持DMA (direct memory access)通信。
3.2.2. 符合Axi4接口的WLI算法IP
Vivado HLS是Xilinx針對其全可編程器件而推出的高級綜合組件,該軟件可以實現對C語言編寫的程序的直接硬件化,并能很好的綜合出符合Axi標準的IP [9] - [12] 。本文的設計采用這種設計方法,借助OpenCV的MAT的相關內容、要求,編寫可綜合算法程序,圖7是WLI算法的實現流程。
映射策略確定新圖中的一行在原圖的行位置,通過每次縮放一行新圖數據的基本策略,用四個數組(Bram存儲)緩存與映射行相關的四行原圖點值,從而實現算法的二維縮放。WLI子模塊實現對一維4個相關點的算法縮放,通過先行后列的策略實現個相關點的圖像縮放目的。
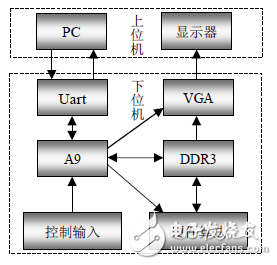
圖5. 縮放算法硬件系統架構
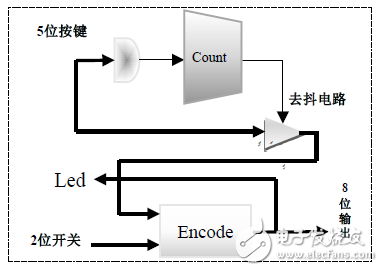
圖6. 控制輸入IP結構框圖
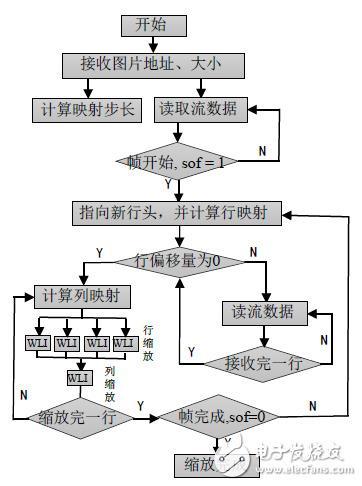
圖7. WLI算法流程
3.3. 硬件系統搭建
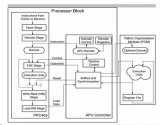
HLS綜合出算法的硬件IP后,通過Planahead環境完成整個硬件系統的搭建。圖8為系統結構示意圖,該系統包括PS子系統、內存間以HP通道(DDR內存和FPGA間的高寬帶、高速數據通道)直接進行數據通信的VDMA、GPIO等IP,以及自主設計的WLI算法IP和VGA顯示IP [13] 。
4. 軟硬協同驗證實驗
4.1. 軟件原理
在硬件系統搭建完成以后,借助于Xilinx的SDK集成環境進行軟件設計。圖9是整個軟件設計運行的流程圖,主要分為初始化、原始圖片選擇接收存儲、GPIO初始化、縮放倍數檢測統計、按鍵狀態檢測判斷和相應算法處理及對比顯示等。
軟件設計中,通過接收PC的選擇信號,選擇使用預定義的圖片,或接收從PC傳來的新圖片。然后進入循環檢測和縮放處理過程,便于演示。同時,通過顯示使能控制端,可以再次更新PC的顯示數據。而縮放顯示模式不僅決定縮放的算法選擇(軟件或硬件),還決定顯示模式(單一還是對比顯示)。
當檢測到GPIO為倍數錄入狀態時,應當進入倍數的檢測和相應操作模式,由此可實現0.1精度的任意倍數圖像縮放效果,并能夠對基于不同縮放算法得到的圖片進行對比顯示。
4.2. 軟硬件協同驗證
通過SDK將編譯好的bootloader程序、FPGA配置bit文件和裸機程序封裝成boot.bin文件,以SD卡實現Zedboard的脫機演示系統。其驗證實驗的系統如圖10所示,右圖是雙三次插值算法軟件縮放結果,而左圖則是WLI算法硬件縮放圖。
各縮放算法在ARM裸機上縮放圖片所耗用時間 [14] 的對比結果如圖11所示。其中最近鄰(Near)、雙線性(Biline)、雙三次(Bcubic)和CCI等為軟件縮放算法,WLI算法為硬件實現算法。
盡管軟件縮放算法在約667 MHz的Cortex A9處理器上運行,而通過FPGA硬件化的WLI算法的運行時鐘僅為100 MHz,但圖11的結果表明,其縮放耗時仍同最近鄰算法相當(Near幾乎被WLI覆蓋了),可見在相同時鐘條件下,其計算效率將會大幅提高,體現硬件實現的并行特征。
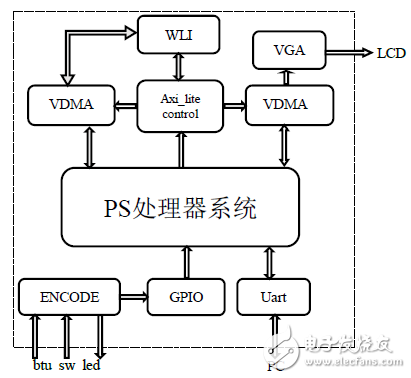
圖8. 硬件系統結構
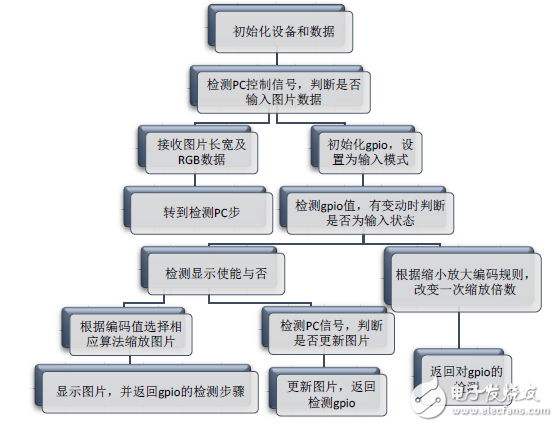
圖9. 軟件處理流程圖
圖10. 圖像縮放對比顯示演示系統
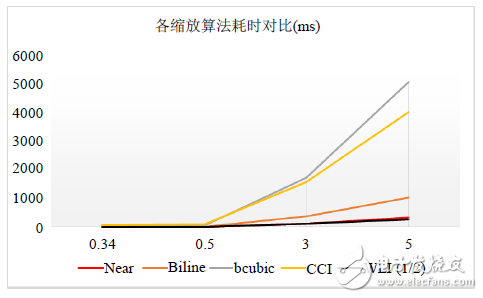
圖11. 各縮放算法不同倍數耗時對比
5. 結論
本文主要研究了時域圖像縮放算法中比較常用的幾種縮放算法,并基于一種稱為WLI的圖像縮放算法,在Xilinx的全可編程器件開發板Zedboard上實現了算法的硬件化,并構建了軟硬協同驗證系統,實現了脫機演示。
本文設計的IP實現了硬件圖像縮放,并與基于軟件實現的圖像縮放具有相同效果,而計算效率提高了至少一個數量級,充分體現了硬件實現圖像縮放的優異性和可行性。
參考文獻 (References)
1. Choi, B.-D. and Yoo, H. (2009) Design of piecewise weighted linear interpolation based on even-odd decomposition and its application to image resizing. IEEE Transactions on Consumer Electronics, 55, 2280-2286.
2. 劉婧 (2009) 圖像縮放算法的研究與FPGA設計. 碩士論文, 上海大學, 上海.
3. 李秀英, 袁紅 (2012) 幾種圖像縮放算法的研究. 現代電子技術, 35, 48-51.
4. Wang, J. (2011) MATLAB三種程序耗時算法.
5. 心海 (2013) PSNR定義與計算.
6. Li, X. (2002) Blind image quality assessment. IEEE ICIP, 1, 449-452.
7. Xilinx (2014) Zynq-7000 all programmable SoC. Xilinx數據手冊.
8. Xilinx (2011) Xilinx, AXI reference guide UG761 (v13.1) March 7. Xilinx數據手冊.
9. 馬建國, 孟憲元 (2011) FPGA現代數字系統設計. 清華大學出版社, 北京.
10. 仆居 (2013) AXI-Stream接口開發詳細流程.
11. 何賓 (2011) 基于AX14的可編程SOC系統設計. 清華大學出版社, 北京.
12. 何賓 (2011) Xilinx all programmable Zynq-7000 SOC設計指南. 清華大學出版社, 北京.
13. 開源硬件社區 (2009) VGA驅動及實現.
14. Cuter (2013) 如何在SDK中計算某段程序的執行時間.












 工商網監
工商網監
評論