 電子發燒友App
電子發燒友App


根據給定的稀疏上身追蹤信號(頭和雙手)來實現全身追蹤,亦即頭顯追蹤的頭部運動,以及控制器追蹤的雙手運動
目前大多數基于VR一體機的Avatar系統都沒有下半身,一個重要的原因是,盡管設備能夠通過內向外追蹤實現頭部和雙手的動捕,而這又使得估計手臂和胸部的位置相對容易,但系統難以判斷你的腿、腳或臀部位置,所以今天的Avatar一直都是缺失下半截。
所以,行業一直在探索各種解決方案。例如,Meta早前的一份研究就提出了基于AI的純頭顯全身Avatar動捕方案,無需任何光學標記。
在另一篇論文中,Meta的研究人員又提出了另一種為Avatar長出雙腿的方法AGRoL。據介紹,這是一種全新的條件擴散模型,專門用于根據給定的稀疏上身追蹤信號(頭和雙手)來實現全身追蹤,亦即頭顯追蹤的頭部運動,以及控制器追蹤的雙手運動。所述模型使用了一個簡單的MLP架構和一種新的運動數據調節方案,從而能夠準確流暢預測全身運動,尤其是具有挑戰性的下半身運動。
人類是AR/VR應用的主要參與者。所以,能夠追蹤全身運動是所述應用的一大需求。常見的方法只能準確地追蹤上身,而全身追蹤可以解鎖引人入勝的體驗,增加用戶的臨場感。但在典型的AR/VR設置中,缺乏對完整人體的強烈追蹤信號,只有頭和手通過嵌入頭顯和控制器中的慣性測量單元傳感器進行追蹤。對于理想情況,我們希望使用大多數頭顯提供的標準三輸入(頭和雙手)來實現高保真全身追蹤。
考慮到頭和手的位置和方向信息,預測全身姿勢,尤其是下半身,其本質是一個欠約束的問題。為了解決這一挑戰,一系列的方法依賴于生成性模型。在這個領域,擴散模型在圖像和視頻生成中顯示出令人印象深刻的結果,特別是對于條件生成。這促使Meta使用擴散模型來生成基于稀疏追蹤信號的全身姿態。
當然,在這項任務中使用擴散模型并非易事。具有擴散模型的條件生成方法廣泛用于跨模態條件生成。遺憾的是,考慮到數據表示的差異,例如人體關節特征與圖像,所述方法不能直接應用于運動合成任務。
在名為《Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model》的論文中,Meta提出了一種全新的擴散架構Avatars Grow Legs(AGRoL),并專門針對條件運動合成任務而設計。
這項研究使用了基于MLP的架構,團隊發現精心設計的MLP網絡已經可以實現與最先進方法相當的性能。然而,MLP網絡的預測運動可能包含抖動偽影。
為了解決這個問題,并從稀疏的追蹤信號中生成平滑的真實全身運動,研究人員設計了一個由MLP架構賦能的輕量級擴散模型。
擴散模型需要在訓練和推理期間將時間步長嵌入注入網絡,而他們發現這個MLP架構對輸入中的位置嵌入不敏感。所以,團隊進一步提出了一種新的策略,以在擴散過程中有效地注入時間步長嵌入。利用所提出的策略,模型可以顯著減輕抖動問題,并進一步提高性能及其對追蹤信號丟失的魯棒性。正如在大型運動捕捉數據集AMASS的實驗證明,AGRoL在全身運動預測能力方面優于現有技術的全身運動。
Meta的目標是預測給定稀疏追蹤信號的全身運動,即頭顯和雙手控制器的方向和平移。給定N個觀察到的關節特征序列:
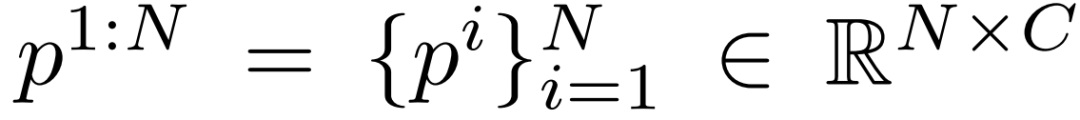
團隊希望預測N個幀的全身姿態:
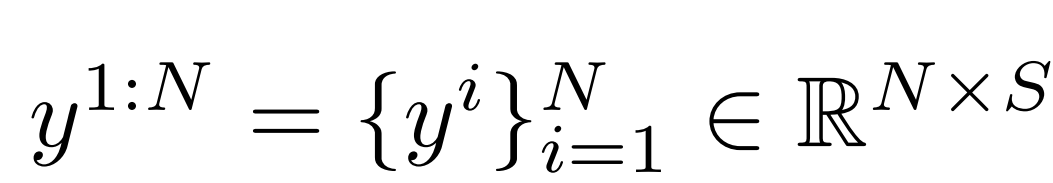
其中C和S表示輸入/輸出關節特征的維度。
研究人員采用SMPL模型來表示人體姿勢,并且僅使用SMPL模型的前22個關節,而忽略手上的關節。因此,y 1:N表示骨盆的全局方向和每個關節的相對旋轉。
基于MLP的網絡
網絡僅由4種在深度學習時代廣泛使用的組件組成:全連接層(LN)、SiLU激活層、1D卷積層(內核大小為1)和層歸一化。注意,1D卷積層同時可以視為在不同維度操作的全連接層。所述網絡架構的細節如下圖所示。
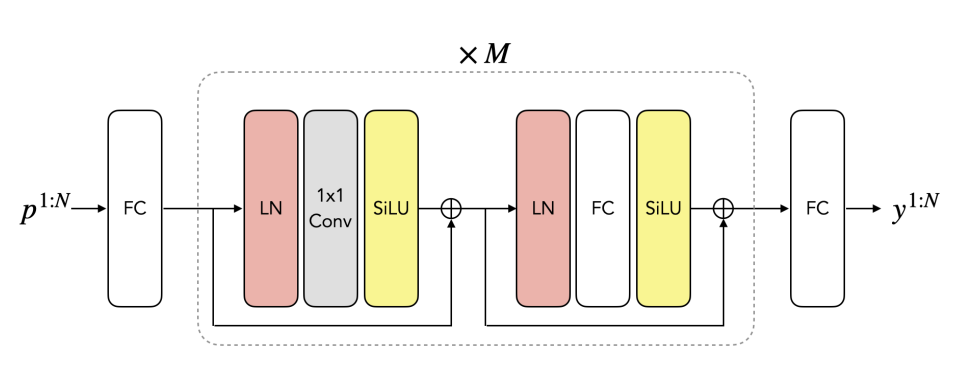
MLP網絡的每個block包含一個卷積層和一個全連接層,分別負責時間和空間信息合并。研究人員使用skip-connection作為層的預規范化。首先,使用線性層將輸入數據p 1:N投影到更高維度的latent space。網絡的最后一層從latent space投射到全身的輸出空間,其比例為y 1:N。
擴散模型
擴散模型是一種生成性模型,它學習反轉由馬爾可夫鏈添加的隨機高斯噪點,以便從噪點中恢復期望的數據樣本。
在擴散模型中,時間步長t的嵌入通常作為額外的輸入饋送到網絡。添加時間步長嵌入的常見方法是將其與輸入連接,類似于transformer-based method中使用的位置嵌入。然而,由于Meta的網絡使用MLP,研究人員發現模型對時間步長嵌入的值不太敏感,這阻礙了去噪過程的學習,并導致具有嚴重抖動問題的運動預測。
為了解決這個問題,研究人員提出了一種新的策略,在MLP網絡的每個block之前重復注入時間步長嵌入。管道的細節下圖所示。
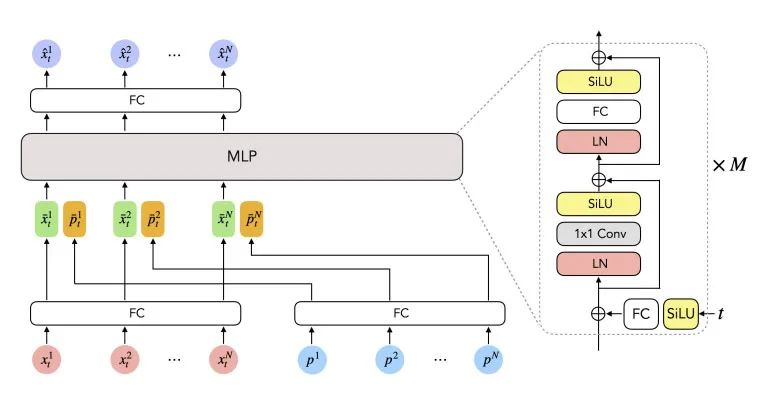
時間步嵌入投影為通過全連接層和SiLU激活層匹配輸入特征維度,然后,預測每個block的時間步嵌入的比例和移位因子,直接將獲得的特征添加到輸入中間激活。團隊指出,所提出的策略可以在很大程度上減輕抖動問題,并實現平滑運動的合成。
研究人員在AMASS數據集訓練和評估模型,采用SMPL人體模型作為人體姿態表示,并訓練模型來預測根關節的全局方向和其他關節的相對旋轉。

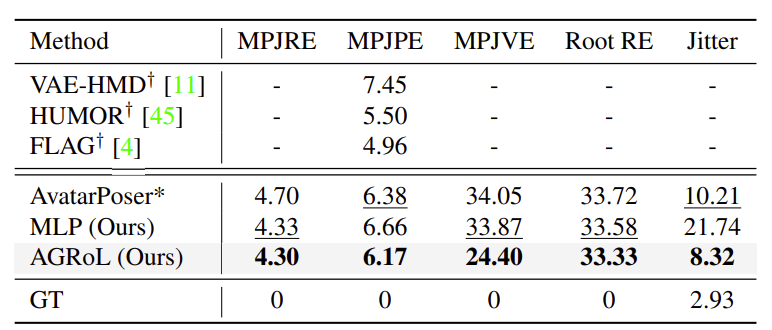
如表1和表2所示,Meta的MLP網絡完全可以超越大多數以前的方法,并與最先進的方法取得可比的結果,這表明了所述網絡的有效性。在擴散過程的幫助下,AGRoL模型進一步提高了MLP網絡的性能,并超越了所有以前的方法。
另外,所提出的AGRoL模型顯著減少了抖動誤差,這意味著與其他模型相比,生成性運動更加平滑。

上圖是AGRoL(下方)和AvatarPoser(上方)對AMASS數據集測試序列的定性比較。圖中可視化了預測的骨骼和人體網格。綠色的骨架表示使用Meta方法預測的運動。紅色的骨架則表示使用AvatarPoser預測的運動。藍色的骨骼表示ground truth運動。如圖所示,與AvatarPoser的預測運動相比,Meta的預測運動更準確。
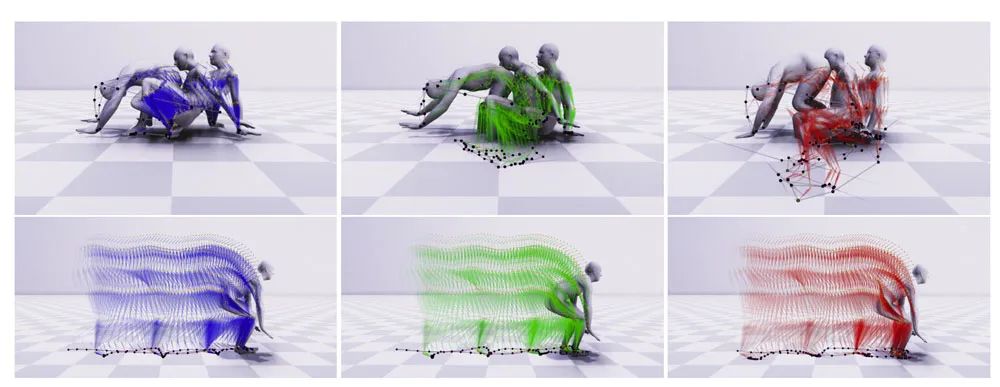
上圖可視化了預測運動的軌跡。左邊的圖像顯示了帶有藍色骨架的ground truth運動。中間圖像顯示了帶有綠色骨架的AGRoL預測運動。右邊圖像顯示了AvatarPoser預測運動(紅色骨骼)。
圖中的淺紫色矢量表示每個關節的速度矢量。通過可視化運動軌跡,可以從圖中更好地查看抖動問題和雙腳滑動問題。平滑運動傾向于具有規則的姿勢軌跡,每個關節的速度向量穩定地變化。姿勢軌跡的密度將隨著行走速度而變化,當人減速時,軌跡將變得更密集。
相關論文:
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
總的來說,AGRoL是一種專門為基于稀疏IMU追蹤信號的全身運動合成而設計的條件擴散模型。AGRoL是一種簡單而高效的MLP擴散模型。為了實現漸進去噪并產生平滑的運動序列,研究人員提出了一種分block注入方案,在神經網絡的每個中間block之前添加擴散時間步長嵌入。通過這種時間步嵌入策略,AGRoL在全身運動合成任務中實現了最先進的性能,而不會出現其他運動預測方法中常用的任何額外損失。
研究表明,基于輕量級擴散的模型AGRoL可以生成真實的平滑運動,同時實現實時推理速度,使其適合在線應用。與現有方法相比,它對追蹤信號丟失更為魯棒。
編輯:黃飛
?






















 工商網監
工商網監
評論