 K1 AI CPU基于llama.cpp與Ollama的大模型部署實踐
K1 AI CPU基于llama.cpp與Ollama的大模型部署實踐
為了應對大模型(LLM)、AIGC等智能化浪潮的挑戰,進迭時空通過AI指令擴展,在RISC-V CPU中注入了原生AI算力。這種具有原生AI能力的CPU,我們稱之為AI CPU。K1作為進迭時空第一顆AI CPU芯片,已于今年4月份發布。
下面我們以K1為例,結合llama.cpp來展示AI CPU在大模型領域的優勢。
llama.cpp是一個開源的高性能CPU/GPU大語言模型推理框架,適用于消費級設備及邊緣設備。開發者可以通過工具將各類開源大語言模型轉換并量化成gguf格式的文件,然后通過llama.cpp實現本地推理。
得益于RISC-V社區的貢獻,已有llama.cpp在K1上高效運行的案例,但大語言模型的CPU資源使用過高,使其很難負載其他的上層應用。為此進迭時空在llama.cpp社區版本的基礎上,基于IME矩陣加速拓展指令,對大模型相關算子進行了優化,在僅使用4核CPU的情況下,達到目前社區最好版本8核性能的2-3倍,充分釋放了CPU Loading,給開發者更多空間實現AI應用。
Ollama是一個開源的大型語言模型服務工具,它幫助用戶快速在本地運行大模型。通過簡單的安裝指令,用戶可以執行一條命令就在本地運行開源大型語言模型,如Llama、Qwen、Gemma等。
部署實踐
工具與模型準備
#在K1上拉取ollama與llama.cpp預編譯包apt updateapt install spacemit-ollama-toolkit
#k開啟ollama服務ollama serve
#下載模型wget -P /home/llm/ https://archive.spacemit.com/spacemit-ai/ModelZoo/gguf/qwen2.5-0.5b-q4_0_16_8.gguf
#導入模型,例為qwen2.5-0.5b#modelfile地址:https://archive.spacemit.com/spacemit-ai/ollama/modelfile/qwen2.5-0.5b.modelfileollama create qwen2 -f qwen2.5-0.5b.modelfile
#運行模型ollama run qwen2
Ollama效果展示
性能與資源展示
我們選取了端側具有代表性的0.5B-4B尺寸的大語言模型,展示K1的AI擴展指令的加速效果。
參考性能分別為llama.cpp的master分支(下稱官方版本),以及RISC-V社區的優化版本(下稱RISC-V社區版本,GitHub地址為:
https://github.com/xctan/llama.cpp/tree/rvv_q4_0_8x8)
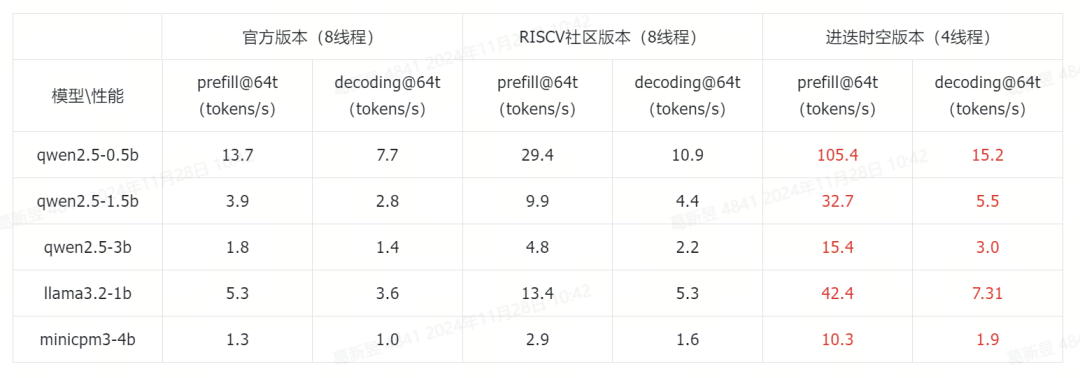
所有模型均采用4bit量化。其中RISC-V社區版本以及官方版本模型為最優實現的加速效果,模型量化時將token-embedding-type設置為q8_0。
llama.cpp的進迭時空版本CPU占用情況:


llama.cpp的RISC-V社區版本CPU占用情況:


參考文檔
https://github.com/ggerganov/llama.cpp
https://github.com/ollama/ollama
https://github.com/QwenLM/Qwen2.5
Qwen2 Technical Report
https://ollama.com
結語
進迭時空在K1平臺上大模型部署方面取得了初步進展,其卓越的性能與高度的開放性令人矚目。這為開發者們提供了一個極為友好的環境,使他們能夠輕松依托社區資源,進一步拓展和創新,開發出更多豐富的應用。
我們滿懷期待地憧憬著K1平臺上未來可能出現的更多大語言模型應用的創新設想。在此過程中,我們將持續保持關注并不斷推進相關工作。此外,本文所提及的預發布軟件包,將在年底以源代碼的形式開源,以供廣大開發者共同學習與探索。
-
芯片
+關注
關注
459文章
51984瀏覽量
434159 -
cpu
+關注
關注
68文章
11015瀏覽量
215373 -
大模型
+關注
關注
2文章
2959瀏覽量
3704
發布評論請先 登錄
【幸狐Omni3576邊緣計算套件試用體驗】CPU部署DeekSeek-R1模型(1B和7B)
如何在Ollama中使用OpenVINO后端
將Deepseek移植到i.MX 8MP|93 EVK的步驟
在MAC mini4上安裝Ollama、Chatbox及模型交互指南
K230D部署模型失敗的原因?
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
進迭時空 K1 系列 8 核 64 位 RISC - V AI CPU 芯片介紹
Kimi發布視覺思考模型k1,展現卓越基礎科學能力
用Ollama輕松搞定Llama 3.2 Vision模型本地部署

Llama 3 與開源AI模型的關系
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
[技術] 【飛凌嵌入式OK3576-C開發板體驗】llama2.c部署
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型






 工商網監
工商網監
評論