 電子發(fā)燒友App
電子發(fā)燒友App


眾所周知,ADC主要用于對(duì)模擬信號(hào)進(jìn)行數(shù)字采集,以進(jìn)行數(shù)據(jù)處理。我們周?chē)男盘?hào)一般都是不斷變化的模擬量,如光、溫度、速度、壓力、聲音等。然而,我們大多數(shù)人都使用數(shù)字設(shè)備。如果我們想方便地使用和處理信息,就需要將模擬量轉(zhuǎn)換為數(shù)字量,并傳送到微控制器或微處理器。那么ADC轉(zhuǎn)換是如何實(shí)現(xiàn)的呢?這是一個(gè)什么樣的過(guò)程?閱讀下面的筆記,你一定會(huì)對(duì)模數(shù)轉(zhuǎn)換器有更全面、更系統(tǒng)的了解。
在電子信息系統(tǒng)的學(xué)習(xí)中,我們或許早就被告知現(xiàn)實(shí)世界是模擬的,而數(shù)字化的模擬世界則越來(lái)越展現(xiàn)更多的風(fēng)采。但是所謂的數(shù)字和模擬只是相對(duì)的而已,你可以把模擬量當(dāng)做無(wú)窮數(shù)字量的組合,也可以把數(shù)字量當(dāng)做具有不同間隔特征的模擬量。這模數(shù)之間的差別也就是采樣和量化的差別而已!
那么Analog如何才能走到Digital呢?
一、ADC幾個(gè)步驟
1、采樣和保持
如果把模擬信號(hào)比作無(wú)限采樣點(diǎn)的數(shù)字信號(hào),那么我們就需要采取其中一些有限點(diǎn)才能進(jìn)行真正的數(shù)字化傳輸。采多少點(diǎn)?怎么采?
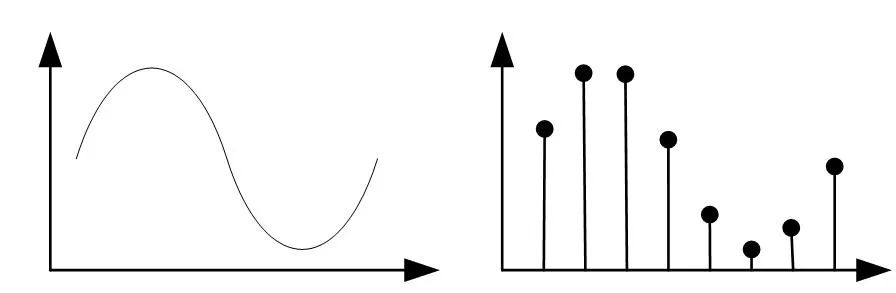
奈奎斯特(Nyquist)采樣定理:
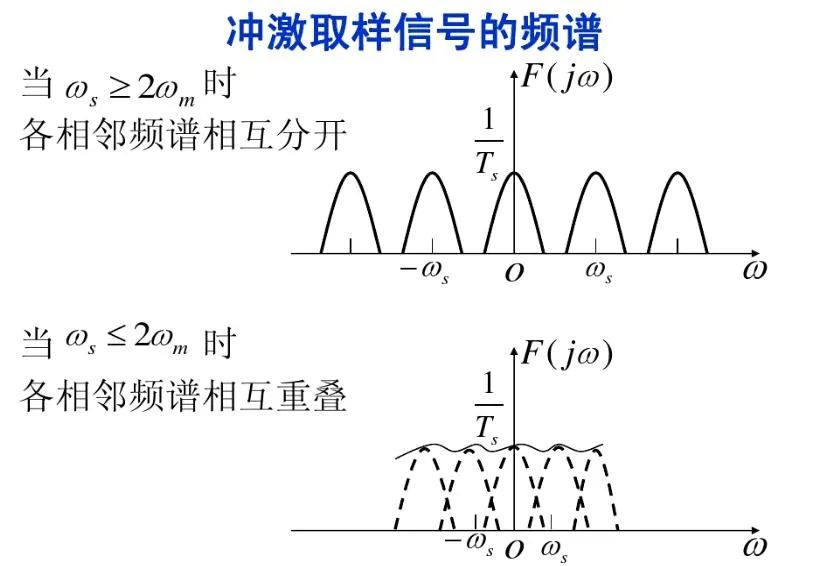
簡(jiǎn)單來(lái)說(shuō)就是采樣頻率必須大于信號(hào)頻率的2倍,fs≥2fn。這樣才能重新恢復(fù)信號(hào)。如果不,會(huì)因?yàn)轭l譜混疊而無(wú)法復(fù)原,具體原因自行查找公式推導(dǎo)及分析。如下圖頻譜
保持的意思簡(jiǎn)單理解就是讓采樣后的數(shù)值保存到下一步轉(zhuǎn)換。
2、量化和編碼
所謂的量化是把采樣后的N多個(gè)點(diǎn)數(shù)值按照一定標(biāo)準(zhǔn)和步驟轉(zhuǎn)化為數(shù)字式的0和1,這個(gè)過(guò)程根據(jù)方式的不同可以分為很多種ADC類(lèi)型,因此具有不同的性能特性,見(jiàn)下文。
二、ADC的幾種架構(gòu)
1、積分型ADC
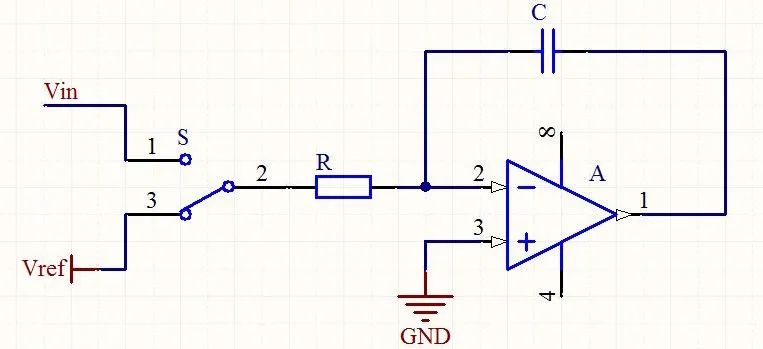
顧名思義,積分ADC的基本原理就是利用運(yùn)放對(duì)輸入信號(hào)和參考信號(hào)進(jìn)行積分輸出,這里參考信號(hào)一般與輸入信號(hào)極性相反,這樣輸出電壓就會(huì)有上升時(shí)間和下降時(shí)間,根據(jù)計(jì)數(shù)器來(lái)統(tǒng)計(jì)時(shí)間,最后按照函數(shù)關(guān)系得到采樣信號(hào)的值。
特征簡(jiǎn)介:
A:積分時(shí)間決定轉(zhuǎn)換精度,因此犧牲轉(zhuǎn)換速度可以提升精度,在早期的一些儀表轉(zhuǎn)換精度要求不高的場(chǎng)合應(yīng)用,后來(lái)的ADC很少采用這種架構(gòu)了。
B:抗噪聲能力強(qiáng)。對(duì)于零點(diǎn)正負(fù)的白噪聲,積分時(shí)可以消除。
2、逐次比較型SAR
顧名思義是利用比較的方式來(lái)轉(zhuǎn)換輸出數(shù)字量,這個(gè)用來(lái)比較的值由DAC產(chǎn)生,如下圖:初始化DAC的輸出由寄存器設(shè)置為1/2Vref,然后由比較器判斷大小來(lái)決定輸出1或0,進(jìn)而進(jìn)行下一步再次設(shè)置寄存器輸出DAC,如此循環(huán)到最后一次LSB。依次輸出的0和1即為轉(zhuǎn)換后的數(shù)字量。算法核心就是二分法搜索,類(lèi)似于猜數(shù)字值的游戲。
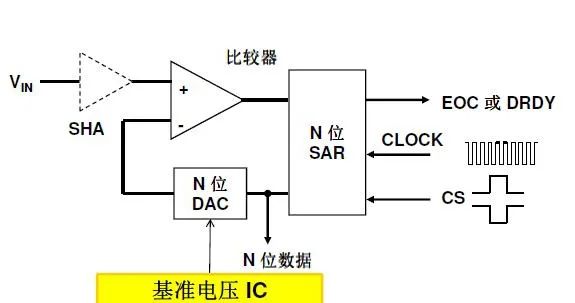
特征簡(jiǎn)介:
A:100K到1M的中等速度,12到16位的中等精度,綜合性能較好,因此是目前應(yīng)用最多的ADC架構(gòu)之一。
B:精度主要決定于DAC的轉(zhuǎn)換精度,因此DAC需要校準(zhǔn),比較器也需要滿足高速和能夠匹配系統(tǒng)的較高精度。
C:功耗可調(diào),由轉(zhuǎn)換速度決定,因此也限制了高速應(yīng)用。
D:總之SAR型ADC的內(nèi)部各組成模塊需要組合設(shè)計(jì)性能匹配最優(yōu)。
3、Pipeline流水線型ADC
基本原理如圖,利用多個(gè)比較器進(jìn)行并行處理,很明顯,高速!
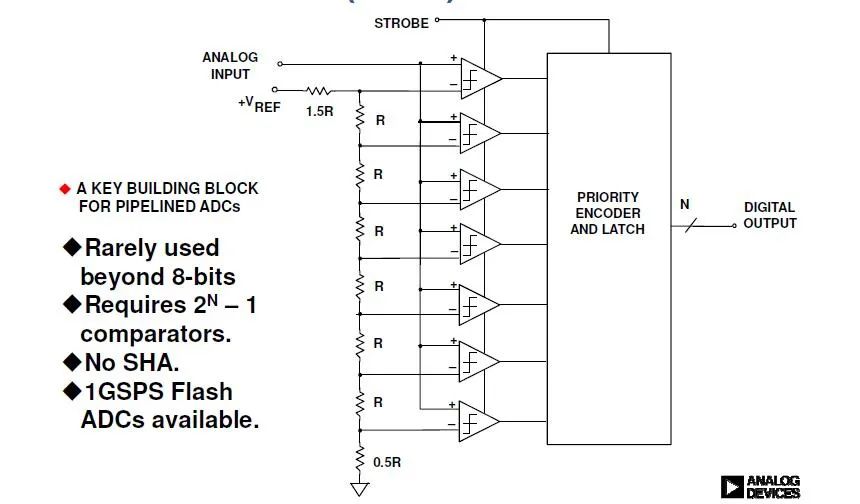
特征簡(jiǎn)介:
A:很明顯夠快,比較器并行處理。
B:功耗大,面積大,自然是因?yàn)楸容^器多。
C:分辨率不夠,也是因?yàn)楣拇螅鄶?shù)小于16位。
D:轉(zhuǎn)換周期需要不斷校準(zhǔn)以保證一定精度。
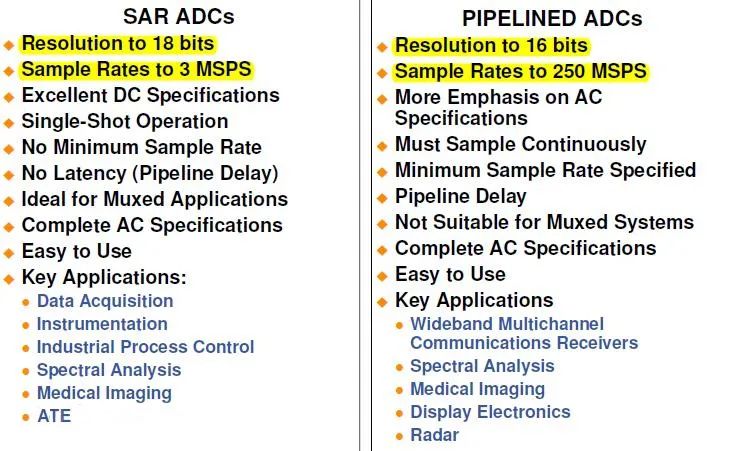
兩種ADC架構(gòu)的比較:
4、Σ-Δ型ADC
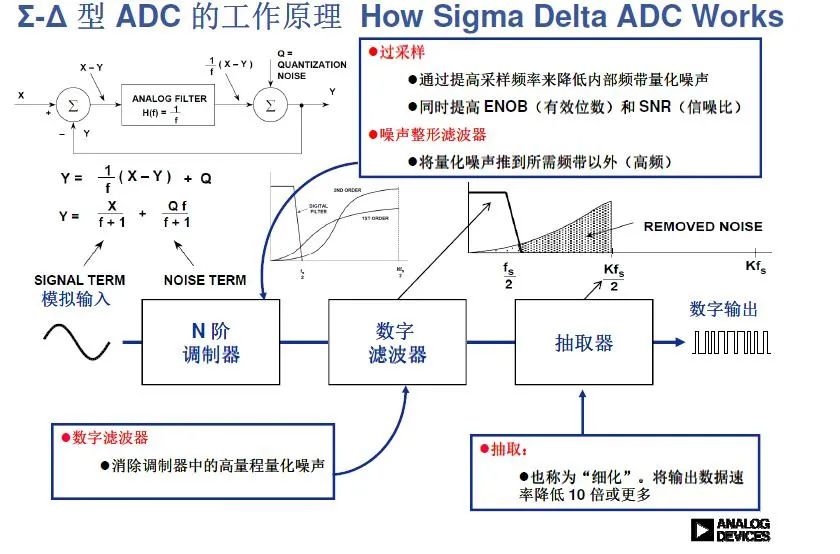
Sigma-Delta 型ADC也是目前應(yīng)用相當(dāng)多的一種ADC架構(gòu),尤其是在高位數(shù)分辨率的ADC設(shè)計(jì)上,這種調(diào)制型的ADC轉(zhuǎn)換設(shè)計(jì)盡可能采用數(shù)字電路來(lái)處理并結(jié)合算法實(shí)現(xiàn)更好的性能。核心技術(shù)點(diǎn):過(guò)采樣和噪聲整形。
Sigma-Delta調(diào)制過(guò)采樣:
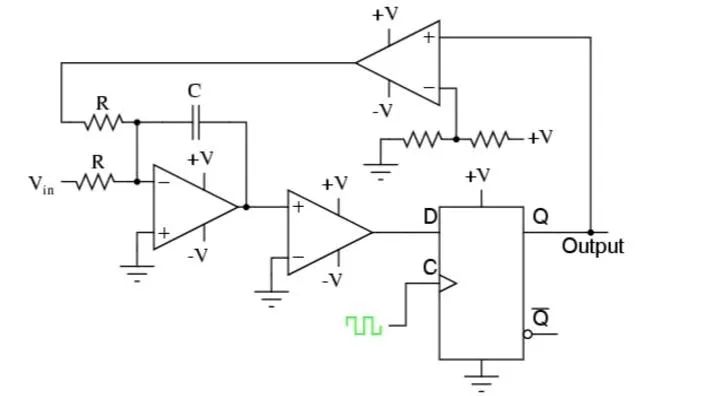
如圖,sigma-delta的意思是差分求和,我們來(lái)顧名思義一下這個(gè)過(guò)程:
假設(shè)第一個(gè)積分運(yùn)放輸出1,則到后面Q輸出也為1,第二個(gè)運(yùn)放輸出則為+V。
+V反饋到第一個(gè)運(yùn)放輸入,驅(qū)動(dòng)積分器向反方向輸出,待采集信號(hào)Vi也會(huì)驅(qū)動(dòng)積分器輸出,綜合而言如果積分器輸出為0,第二個(gè)比較器反饋回來(lái)的就是-V,以驅(qū)動(dòng)積分器向輸出。這個(gè)環(huán)路最后的目的是實(shí)現(xiàn)運(yùn)放的基本特性:反相端應(yīng)該為0!
這樣整個(gè)輸出的1的個(gè)數(shù)比例對(duì)應(yīng)的電壓值其實(shí)就是待測(cè)信號(hào)的電壓值!能否理解?就是通過(guò)對(duì)誤差的不斷累積求和得到對(duì)應(yīng)值!Q會(huì)輸出一串01值即完成。
過(guò)采樣:
上述過(guò)程中的觸發(fā)器時(shí)鐘非常快,遠(yuǎn)大于奈奎斯特采樣要求,這樣可以將量化噪聲推到更高頻段內(nèi)。量化噪聲:數(shù)字量化的最小單位存在的誤差被稱(chēng)為量化噪聲,即1LSB和2LSB之間的誤差值。
噪聲整形:
前一步得到的高速01數(shù)字流可以通過(guò)數(shù)字方式進(jìn)行處理得到最后的輸出結(jié)果。因?yàn)樵谶^(guò)采樣過(guò)程中是以速度換取精度的方式來(lái)操作的,高速但是噪聲大,在噪聲整形過(guò)程中通過(guò)數(shù)字濾波器和抽取電路把噪聲消除并降低最終的信號(hào)輸出速率,實(shí)現(xiàn)高精度的數(shù)據(jù)轉(zhuǎn)換結(jié)果!
如下圖總結(jié):
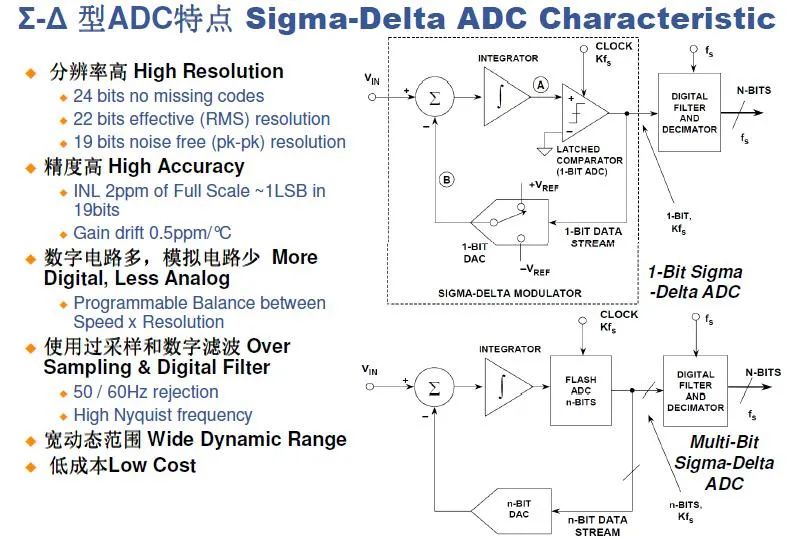
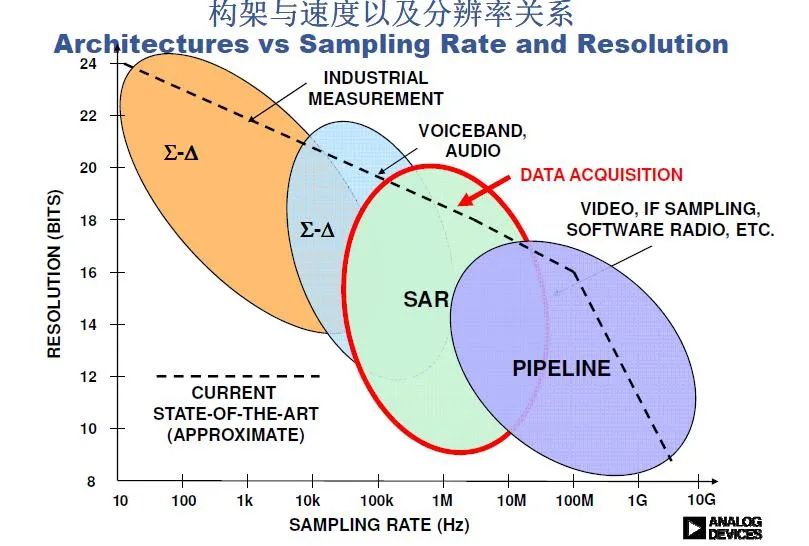
幾種ADC架構(gòu)的簡(jiǎn)單比較:
大家在學(xué)習(xí)ADC的過(guò)程中一定有很多問(wèn)題,我這邊也總結(jié)了一些學(xué)習(xí)中遇到的問(wèn)題,現(xiàn)在分享給大家,希望能從中學(xué)習(xí)到一些有用的知識(shí)。
Q1
設(shè)計(jì)一個(gè)電路是怎么樣的一個(gè)過(guò)程啊?如何從架構(gòu)開(kāi)始一步一步到滿足性能要求的電路來(lái)? 特別是各管子的參數(shù)是靠手算出來(lái)的還是工具仿真出來(lái)的?
先初步手算的 然后仿真精細(xì)化。比如BGR,先確定電流、功耗、輸出電壓等基本指標(biāo),然后選擇電路結(jié)構(gòu),再進(jìn)行手算。有了初步參數(shù),就可以仿了,然后再調(diào)。設(shè)計(jì)的尺寸還要看工藝和版圖的可行性
Q2
同步sar邏輯和異步的區(qū)別是什么呢?哪個(gè)更好一些?
同步SAR更多是應(yīng)用于低速,一般采樣率不會(huì)超過(guò)5MHz,而且高速時(shí)鐘需要外灌溉;異步SAR可以做到很高速,對(duì)于40nm這種工藝,單通道可以到100MHz左右,如果是Finfet工藝,可以更高。由于異步SAR ADC在面積和功耗上遠(yuǎn)遠(yuǎn)優(yōu)于pipelined ADC,在精度要求不是太高的應(yīng)用領(lǐng)域(不超過(guò)10Bit),異步SAR可以代替pipeline了。
Q3
計(jì)算SNR的時(shí)候,諧波功率也算到噪聲功率嗎?計(jì)算ENOB用的是SNR還是SNDR?
是信號(hào)和其他所有比,當(dāng)然這個(gè)也要看定義,有的地方把snr和sndr區(qū)分開(kāi),sndr是信號(hào)比諧波+噪聲,snr就是信號(hào)比噪聲了。事實(shí)上大家大部分情況下說(shuō)的snr就是sndr,不特別強(qiáng)調(diào)的話,習(xí)慣性默認(rèn)snr就是sndr。就是說(shuō)通常說(shuō)snr是加上了諧波失真的sndr,而不是僅用enob公式算出來(lái)的snr。
Q4
對(duì)怎么做一些屏蔽,隔離,匹配,floorplan等等能不能給說(shuō)一說(shuō),因?yàn)楫吘刮覀円艿念l率還不低呢。
說(shuō)白了就是DAC的布局布線,這可以是一個(gè)專(zhuān)門(mén)的Topic。我們通常所說(shuō)的中心對(duì)稱(chēng)圖形其實(shí)大部分只能消除一階的系統(tǒng)失配,但是一不小心就可能放大高階失配。涉及到我們SAR ADC里面的CDAC,要分情況來(lái)討論,如果是低速的高精度SAR ADC,由于速度低,我們的CDAC可以采用很多方式來(lái)消除系統(tǒng)失配。但是對(duì)于高速SAR ADC,一個(gè)電容拆分的越散,雖然系統(tǒng)匹配越好,但是布線越復(fù)雜,寄生效應(yīng)越明顯,對(duì)速度的影響越大。我在做100MHz采樣率這種數(shù)量級(jí)的SAR ADC的時(shí)候,我們的總電容其實(shí)都不大的,LSB電容不足1fF,整個(gè)SAR ADC的面積也很小,具體到CDAC,也就100*100左右。我們會(huì)更多地從速度的角度觸發(fā),MSB電容做一些拆分散開(kāi),其他電容以layout優(yōu)先,layout舒服了,電路性能才能上去。這里有幾張關(guān)于DAC Layout的圖給大家看看,大概需要考慮到哪個(gè)程度。
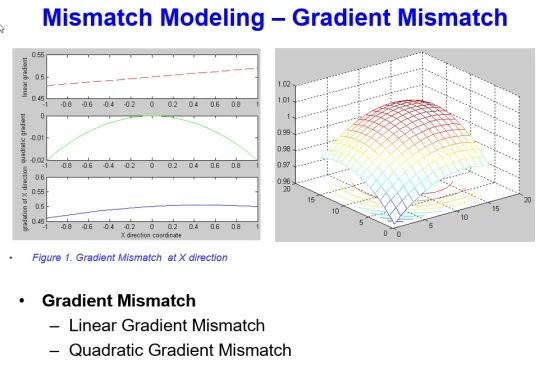
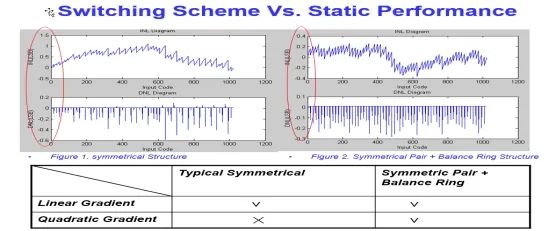
一階線性匹配和高階非線性失配都要考慮,最終layout布局要能消除或者減弱所有mismatch。
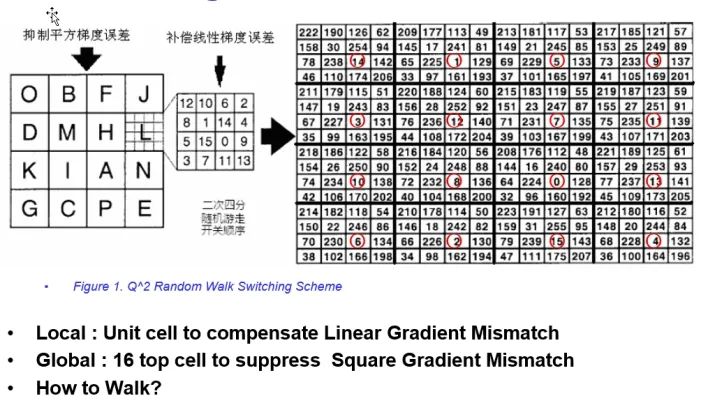
類(lèi)似的有Q^2隨機(jī)游走式布局。
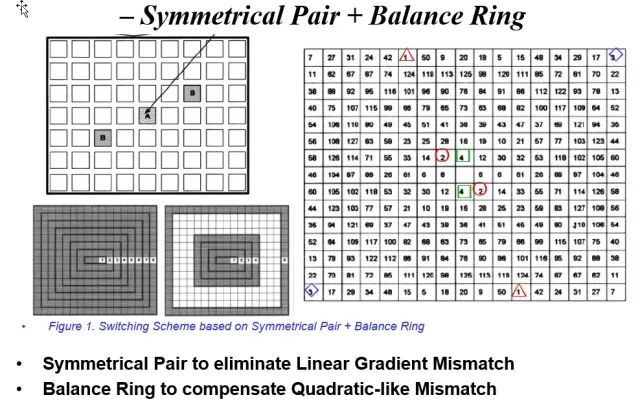
平衡環(huán)的方式,目的就是要將DAC的器件單元完全打散,消除一階和高階系統(tǒng)mismatch,最終的目的都是為了在惡劣的環(huán)境下實(shí)現(xiàn)較低的INL。
Q5
仿單級(jí)放大器是應(yīng)該去跑仿真仿瞬態(tài)仿真合適還是交流仿幅頻特性曲線合適?
不矛盾,這兩都需要跑,或者是需要跑哪些仿真得看實(shí)際需求。AC或者STB是得到幅頻特性,諸如低頻增益、GBW、穩(wěn)定相關(guān)的PM和GM等這些參數(shù)。但是AC畢竟只是基于某個(gè)特定工作點(diǎn)的電路性能,實(shí)際中OP的輸出輸入都是有一定范圍的,工作點(diǎn)偏了OP性能肯定也會(huì)發(fā)生改變,跑Tran,對(duì)Tran波形做DFT就能夠知道信號(hào)的質(zhì)量,DFT是對(duì)OP輸出信號(hào)的線性度進(jìn)行定量計(jì)算,反映了不同工作點(diǎn)情況下的OP性能參數(shù)變化(增益的變化、GBW的變化等)。
Q6
我在想是不是我不做太高速的,可以不用太在意這個(gè)頻域的東西?因?yàn)槲覀兪菕煸?a target="_blank">MCU上的一個(gè)模塊,萬(wàn)一不行,我就讓他們軟件多給點(diǎn)時(shí)間去采結(jié)果。
大家先看DFT譜線圖的物理意義很重要,從不懂到似懂非懂再到明白,總要有個(gè)過(guò)程,該經(jīng)歷的痛苦要經(jīng)歷的。事實(shí)上工作好多年不會(huì)用DFT分析信號(hào)線性度的大有人在,這種情況下就比較被動(dòng)了,每次要請(qǐng)人幫忙搭建仿真Bench,關(guān)鍵是仿完心里還底氣不足。你們學(xué)完能有個(gè)似懂非懂的狀態(tài)就差不多了,答疑的時(shí)候我再幫大家梳理一遍,從似懂非懂到明白也就是一線之隔,一瞬間的事兒。
Q7
其實(shí)我對(duì)歸一化,dB的意思也沒(méi)理解透。
譜線的Y軸是dB就是說(shuō)這根譜線的功率吧,這個(gè)能理解。
這里的功率,是指某信號(hào)在某點(diǎn)的電流電壓積么?
高考,各地的滿分不一樣,假設(shè)湖北滿分750,上海滿分600。現(xiàn)在分別有2個(gè)學(xué)生A和B,A是湖北考生,B是上海考生,A考了600分,B考了500分,我們?cè)趺磥?lái)判斷他們誰(shuí)的成績(jī)更好呢?單單比較分值的絕對(duì)值沒(méi)有意義,我們把總分歸一化到100分上來(lái),A=600/750100=80分,B=500/600100=83.3分,簡(jiǎn)單來(lái)說(shuō)B成績(jī)更好。這就是歸一化,以統(tǒng)一的標(biāo)準(zhǔn)來(lái)衡量。
Q8
我感覺(jué)明明簡(jiǎn)單的一個(gè)誤差指標(biāo),但是卻要搞出這么多分散的指標(biāo)來(lái)表達(dá)這個(gè)誤差,太暈了,ADC判斷誤差,這個(gè)看起來(lái)覺(jué)得應(yīng)該好理解,就是搞出各種誤差指標(biāo),這下就難理解了
對(duì)信號(hào)歸一化的意思是,所有頻譜對(duì)應(yīng)的功率值都除以信號(hào)功率值,由于縱坐標(biāo)已經(jīng)變成了log軸,所以直接減法就行。
20log10(A/B)=20log10(A) - 20*log10(B)
在DFT頻譜里面,信號(hào)功率是最大值,對(duì)應(yīng)著考試的滿分,對(duì)信號(hào)歸一化就是對(duì)滿分歸一化。
Q9
s=20log10(2s/N/FS); 對(duì)數(shù)里面2*s/N/FS什么意思?
好問(wèn)題,你發(fā)現(xiàn)了程序里的一個(gè)小bug。
Q9.1
直接log10(s),不對(duì)嗎?
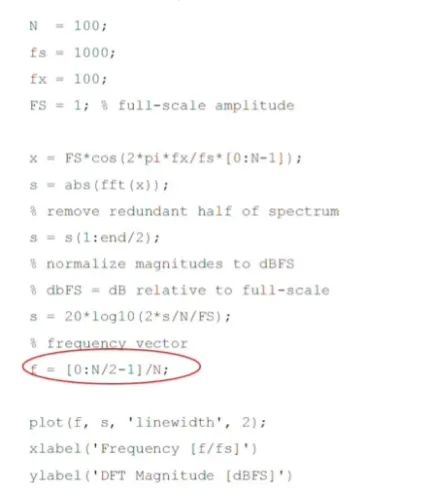
2s/N/fs=s(2/N/fs),其中2/N/fs是一個(gè)常數(shù)。我們關(guān)注FFT的結(jié)果只關(guān)注信號(hào)和諧波以及噪聲之間的相對(duì)差值,所以所有的s元素都乘以一個(gè)常數(shù)是不影響結(jié)果的。
但是這里的歸一化確實(shí)不對(duì),s是fft結(jié)果,如何對(duì)s進(jìn)行歸一化呢?最簡(jiǎn)單粗暴的方法是 log之后 s=s-max(s)。
如果按照DFT的理論公式,歸一化的方法應(yīng)該是2s/N,為什么要2呢?我們?cè)诖酥爸蝗×薔/2個(gè)點(diǎn),丟了一半,這里的2是補(bǔ)那一半回來(lái)。為什么/N呢?因?yàn)闀r(shí)域采了N個(gè)點(diǎn),對(duì)應(yīng)頻域也是N個(gè)點(diǎn),/N的意思是求平均。
所以這里的代碼里多了一項(xiàng)/fs,正確的應(yīng)該是s=20log10(2s/N)
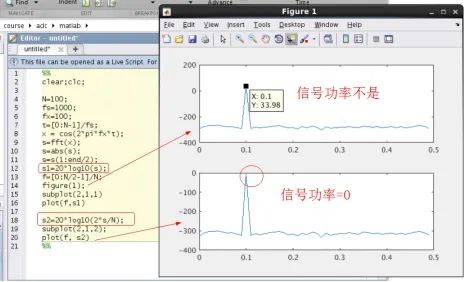
從這個(gè)圖你們應(yīng)該能看的更清楚,第一章圖的FFT結(jié)果沒(méi)有對(duì)信號(hào)進(jìn)行歸一化,信號(hào)的值不為0,第二張圖僅僅是對(duì)信號(hào)進(jìn)行了歸一化,信號(hào)顯示為0,噪底整體下移。
如果看不懂就略過(guò),畢竟是乘以一個(gè)常數(shù)。我建議你們以后歸一化就直接 s = s-max(s),簡(jiǎn)單粗暴好理解。









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論