GPU要超越CPU擠身一線主角還得靠AI - 全文
GPU應用因AI開始有了截然不同的新轉變,不只讓一些支援高度平行運算應用的高階GPU相繼問世,現在連整套GPU深度學習專用服務器也搶灘登陸,要助企業加快AI應用。
AI人工智慧、虛擬/擴增實境(VR/AR)與自動駕駛技術,在過去一年引起很高的市場關注,而一舉躍升成為當前最火紅的熱門話題,特別是以深度學習(Deep Learning)為首的AI應用,過去幾個月來,因為Google的AI電腦AlphaGo接連大敗歐洲和南韓國圍棋棋王,更在全世界吹起一股AI風潮,使得現在不只有大型科技或網路公司要大力投資AI,就連各國政府也都要砸重金扶植AI產業。
目前一些大型科技或網路業者,例如Google、Facebook、亞馬遜AWS、IBM、微軟與百度等,都陸續已在云端服務中融入AI服務,做為電腦視覺、語音辨識和機器人等服務用途,甚至,也開始有越來越多規模較小的新創或網路公司,如Api.ai、Drive. ai、Clarifai與MetaMind等,打算將AI開始應用在各行各業的領域上。
GPU開始在AI應用逐漸嶄露頭角
然而,決定這些AI服務能不能獲得更好發揮的關鍵,不只得靠機器學習的幫忙,甚至得借助深度學習的類神經演算法,才能加深AI未來的應用。這也使得近年來,GPU開始在一些AI應用當中逐漸嶄露頭角。這是因為不論是AI、VR/AR,還是自動駕駛技術的應用,雖然各有不同用途,但他們普遍都有一個共同的特色,都是需要大量平行運算(Parallel Computing)的能力,才能當作深度學習訓練模型使用,或者是將圖形繪制更貼近真實呈現。
所謂的平行運算泛指的是將大量且密集的運算問題,切割成一個個小的運算公式,而在同時間內并行完成計算的一種運算類型。而GPU則是最能夠將平行運算發揮到極致的一大關鍵,這是因為GPU在晶片架構上,原本就被設計成適合以分散式運算的方式,來加速完成大量且單調式的計算工作,例如圖形渲染等。所以,過去像是高細膩電玩畫面所需的大量圖形運算,就成為了GPU最先被廣為運用的領域,現在,VR/AR則是進一步打算將原本就擅于繪圖運算的GPU發揮得更淋漓盡致,來呈現出高臨場感的3D虛擬實境體驗。
當然在游戲繪圖運算外,后來GPU也被拿來運用在需要大量同質計算的科學研究中使用。甚至近年來,GPU也開始因為深度學習的關系,而在一些AI應用當中擔任重要角色。
深度學習其實是機器學習類神經網路的其中一個分支,深度學習本身是由很多小的數學元件組合成一個復雜模型,就像是腦神經網路一般,可以建構出多層次的神經網路模型,來分別處理不同層次的運算工作,這些神經網路本身并不做判斷,只重覆相同計算工作,使得GPU在深度學習方面可以獲得很好的發揮,而隨著網路、云端和硬體技術成熟所帶來巨量的資料,也造就了現在所需完成訓練的深度學習模型,比起以前更需要大量高階GPU的平行運算能力,才足以應付得了。
GPU平行運算性價比贏過CPU
因為AI、VR/AR與自駕車應用需求提高后,也促使GPU重要性與日俱增,甚至為了因應深度學習與AI應用趨勢,新世代GPU反而希望盡可能在晶片中裝入了更多電晶體和核心數,來提高大量同性質的資料計算能力。若是以Nvidia新的Tesla P100系列的GPU加速器產品來舉例說明的話,在這個GPU加速器內總共裝有3,584個CUDA核心數(單精度條件下),其內含的電晶體數更一舉超過了150億顆,數量幾乎是前一代Tesla M40 GPU的翻倍,在雙精度條件下的浮點運算能力,更高達有5.3 TFLOPs。
當然GPU之外,CPU本身也具有計算處理的能力,不過在處理平行運算時,***大學資工系副教授洪士灝認為,GPU的CP值(性價比)比CPU還要高。這是因為GPU原本就擅長處理大量高同質性的資料計算工作,而CPU則擅于通用型任務的資料處理,所以對于一些需要大量單調式運算工作的應用,就很適合使用GPU來執行,例如利用深度學習神經網路訓練模型來實現AI應用,或者是用繪圖運算呈現VR/AR所需的高細膩畫面,都很適合用GPU的方式來進行計算。
另外從Nvidia官方所公布的一份CUDA C Programming Guide設計指南中也揭露了在2013年前的過去10年間,GPU與CPU兩者在單精度與雙精度浮點運算(Floating-Point Operations Per Second,FLOPS)發展的比較差異。整體來看,GPU與CPU發展越到后期,兩者在浮點運算處理能力的差距,有逐漸被拉大的趨勢,這是因為越到后面才推出的新款GPU,更加強調浮點運算的重要性,而盡可能要提高GPU浮點運算的處理能力。所以,現在許多超級電腦內都有使用GPU,來大幅提高浮點運算的實力。
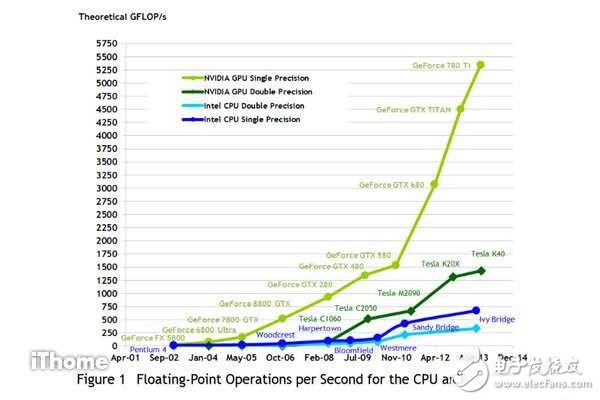
從Nvidia官方所公布的一份CUDA C Programming Guide設計指南中也部分揭露了在2013年前的過去10年間,GPU與CPU兩者在單精度與雙精度浮點運算發展的比較差異。
整體來看,GPU與CPU發展越到后期,兩者在浮點運算處理能力的差距,有逐漸被拉大的趨勢,這是因為越到后面才推出的新款GPU,更加強了浮點運算的能力。
今年GTC大會聚焦AI、VR/AR與無人汽車應用
今年在美國圣荷西舉行的GTC技術大會(GPU Technology Conference),也因為AI、VR/AR、無人汽車的關系而格外備受矚目。今年總共吸引了全球超過5千人參加,更有將近上百位的全球媒體、分析師到場,還有多達2百家廠商參展,規模是歷年來最大。而做為主辦方的Nvidia今年氛圍也很不一樣,Nvidia不僅在現場同時發布多款與深度學習和AI有關GPU新品,還針對了原本就擅長的VR/AR與自動駕駛應用領域推出了新的開發工具和產品,希望就此能讓VR/AR與自動駕駛可以更進一步應用。
也正因為AI、VR/AR與自駕車讓GPU的應用更廣了,因而造就了GPU在這次GTC大會扮演的重要性和應用性明顯提高不少,特別是AI與深度學習的應用方面,今年更成為會場上最炙手可熱的技術話題,在為期4天超過240場大小場的GPU主題講座中,有半數以上都圍繞著AI與深度學習而打轉,這還不包括了來自2位人工智慧界的重量級AI大師,分別是IBM人工智慧研究和技術策略的IBM Watson 技術長Rob High與豐田汽車研究機構執行長Gill Pratt,今年都親自到場分享他們所觀察到的最夯AI技術和應用新進展。
Nvidia執行長黃仁勛在今年主題演說中也強調GPU未來角色的重要性,將替深度學習與AI開啟一種前所未有的全新運算模式(Computing Model),將促使深度學習成為未來企業甚至每個人,都不能加以忽視的大事(Big Deal ),甚至將開啟另一種AI即平臺的新服務模式(AI-as-a-Platform)。而為了搶攻AI與深度學習市場,Nvidia今年甚至還罕見地,首度發表世上第一臺整套式深度學習專用的超級電腦DGX-1。
Nvidia執行長黃仁勛在今年主題演說中數度強調GPU未來角色的重要性,將替深度學習與AI開啟一種前所未有的全新運算模式(Computing Model),將促使深度學習成為未來所有企業甚至每個人,都不能加以輕忽的大事(Big Deal ),甚至帶來一種AI即平臺的新服務模式(AI-as-a-Platform)。而為了搶攻AI與深度學習市場,Nvidia今年甚至還罕見地,首度發表世上第一臺整套式深度學習專用的超級電腦DGX-1。
AI專用服務器將助企業加快深度學習應用
Nvidia在這臺深度學習專用的超級電腦DGX-1內,使用了服務器專用的GPU加速器Tesla P100為基礎而打造完成,Tesla P100采用了新一代Pascal架構設計,比前一代Maxwell架構的GPU加速器,在用來訓練神經網路的效能方面,Nvidia宣稱,Tesla P100足足有提升12倍之多。
Nvidia在這組超級電腦內總共裝入8張Tesla P100加速卡,使得DGX-1在半精度(FP16)的浮點運算次數每秒高達有170TFLOPS,如此高度的運算能力,Nvidia甚至宣稱,只要有了DGX-1,就等同于擁用了250臺x86服務器而搭建的運算叢集規模,將有助于企業在深度學習方面獲得更好的應用效果。
而靠著DGX-1的高度運算能力,也因而縮短了過去用來做為深度學習訓練所需花費的冗長時間,若以單組2路Xeon E5服務器和DGX-1進行比較的話,根據Nvidia測試的結果,在做為AlexNet機器學習的模型訓練方面,DGX-1完成訓練所花費的時間要遠比Xeon E5服務器還快許多,Xeon級服務器得要花150小時才能做完的訓練,DGX-1只須2小時就能完成。若以訓練機器辨識照片來舉例的話,所代表的是,每天被喂給DGX-1機器做訓練的照片,數量高達有13億張。
除了GPU以外,這臺DGX-1還有配置了一個2路Xeon E5 CPU處理器,系統記憶體部分最大則可支援512GB DDR4的記憶體容量,并也配備有7TB大小的SSD硬碟,至于電力供給部份則是使用一臺3U高度3,200瓦的電源供應設備,還支援了NVLink 混合式立方網格 (NVLink Hybrid Cube Mesh)技術,可提供更高速GPU互連的能力,網路部分則提供了雙10GbE連接埠和一個100Gb的Quad InfiniBand高速網路介面,而使得每臺DGX-1機器的總傳輸頻寬,每秒最高可達768GB。
不僅如此,Nvidia在這臺DGX-1中加入許多新的深度學習軟體功能,像是新增加的Nvidia深度學習GPU訓練系統(Deep Learning GPU Training System,DIGITS),可用來協助企業設計一個完整且互動的神經網路,還支援了 CUDA深度神經網路圖庫(CUDA Deep Neural Network library,cuDNN )的v5新版本,可用來做為設計神經網路時可供GPU加速的函式圖庫。DGX-1系統內也提供了一些深度學習優化的框架,例如Caffe、Theano與Torch等,另還搭配一套云端管理存取的工具和一個容器應用儲存庫(Repository )。
Nvidia這臺深度學習專用的超級電腦DGX-1,主要是使用了服務器專用GPU加速器Tesla P100來打造完成的AI專用服務器,因而在這臺機器內總共裝入8張Tesla P100加速顯卡,使得DGX-1在半精度(FP16)的浮點運算次數每秒可高達170TFLOPS,如此高度的運算能力,Nvidia甚至宣稱,這幾乎等同于用250臺x86服務器而搭建的運算叢集規模,將助企業獲得更好的深度學習作用。
GPU將擠身成為AI服務器界的一線主角
而從Nvidia這次所發布DGX-1的銷售策略來看,除了要積極搶攻深度學習與AI市場外,也不難看出Nvidia想要透過推出整套式AI專用的GPU服務器,好讓自己也開始變身成為一家能提供特殊GPU解決方案的服務器供應商。
而這樣的作法所帶來的其中一個改變,便是也開始讓GPU應用位置有了截然不同以往的轉變。相較于過去GPU只在游戲或研究領域受到重視,但在服務器應用當中,GPU始終淪為配角,CPU才是主角,CPU處理器規格決定了一臺服務器工作效能的高低,但現在,在一些特殊深度學習或AI專用的服務器當中,GPU受重視的程度有時反而還高過了CPU,GPU反倒竄升成為一線主角。
以前,CPU是服務器效能高低的關鍵,但現在,在這些深度學習或AI等特定用途的服務器當中,GPU則是變成了關鍵,GPU擁有的核心數量多寡,決定了能不能將深度學習與AI更進一步延伸應用,CPU反而變成了配角,兩者位置恰恰好顛倒了過來,不過這種情況,目前只有在一些特殊運算用途的AI設備中才看得到,但也確實反應了GPU應用位置,正在逐漸改變當中。
當然,除了AI與深度學習需要用到GPU外,另一個需要用到GPU的VR/AR應用也成為今年GTC大會的另一大熱門焦點。除了現場有Nvidia技術人員展示結合GPU技術的各類VR應用外,展區內也設有VR Village體驗區,參加者可以現場試用Oculus與HTC Vive這兩款已正式出售的VR頭戴式裝置,現場體驗VR帶來的沉浸式視覺效果。
而從這些VR展示體驗當中,也說明了VR技術已開始跨入大眾化的實用階段,而且不只運用在游戲娛樂領域,其他專業領域也開始能與VR結合,像是Nvidia在這次大會中就推出了一個Iray VR新應用,能將原本設計好的3D場景或物件模型,經過Iray渲染技術,在虛擬實境中呈現貼近真實情境的影像渲染效果,讓VR不只是當作游戲使用而已,未來就連設計后的3D制圖也能用VR渲染技術呈現。當然在持續提高VR影像畫面細膩度和更快速的即時反應的同時, VR技術的下一步也需要搭配更高階的GPU,才能達到更深度沉浸式的高臨場感體驗。
除此之外,在無人汽車應用方面也有新進展。Nvidia將參與協助打造首輛賽車用的無人汽車的計畫,將采用Nvidia自動駕駛平臺Drive PX2做為汽車電腦系統核心,未來這輛無人賽車完成以后,重量預估將達1噸重,并且將會參加即將在2016至2017年賽季,由Formula E電動方程式首度舉辦的Roborace無人駕駛賽事。這場無人賽車比賽,預估將會有10支隊伍,共20輛的無人汽車參賽,共同在同個賽車場上較勁。每輛無人賽車硬體配備都完全相同,所以最后決勝關鍵將決定于哪只隊伍可以運用機器學習,甚至借助深度學習的類神經演算法,盡可能提高駕駛判斷的預測能力,才能做到在以毫秒為競速單位的賽車場上稱王。
Nvidia這次還首度用VR來呈現火星地理環境,讓穿戴者可以沉浸在有如真實火星圍繞的視覺感受當中,這些環境資料都是從搜集科學專用衛星的精確影像資料,以及火星任務取得數年的探測數據,所建構出貼近火星地形和氣候的虛擬實境。Nvidia執行長黃仁勛現場還與蘋果共同創辦人Steve Wozniak遠端視訊連線,并邀請他現場示范如何用VR來玩火星探險游戲,沒想到Steve Wozniak卻顧不得旁人,自己就在現場玩開了 ,惹得現場笑聲一片,連人稱科技頑童的他也難以抵擋VR的魅力,也正說明了VR技術已開始走入實用階段。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
相關閱讀:
- [電子說] Blackwell GB100能否在超級計算機和AI市場保持領先優勢? 2023-10-24
- [電子說] 如何使用Rust創建一個基于ChatGPT的RAG助手 2023-10-24
- [電子說] 訊飛星火大模型V3.0正式發布,全面對標ChatGPT 2023-10-24
- [電子說] 如何創建FPGA控制的機器人手臂 2023-10-24
- [電子說] 亞馬遜云科技生成式AI最新案例分析,助力企業業務創新迭代 2023-10-24
- [電子說] 怎樣延長半導體元器件的壽命呢? 2023-10-24
- [電子說] 新思科技攜手臺積公司加速N2工藝下的SoC創新 2023-10-24
- [電子說] 服務器硬盤通用基礎知識 2023-10-24
( 發表人:包永剛 )