詳解深度學習在廣告推薦領域的作用
當2012年Facebook在廣告領域開始應用定制化受眾(Facebook Custom Audiences)功能后,“受眾發現”這個概念真正得到大規模應用,什么叫“受眾發現”?如果你的企業已經積累了一定的客戶,無論這些客戶是否關注你或者是否跟你在Facebook上有互動,都能通過Facebook的廣告系統觸達到。“受眾發現”實現了什么功能?在沒有這個系統之前,廣告投放一般情況都是用標簽去區分用戶,再去給這部分用戶發送廣告,“受眾發現”讓你不用選擇這些標簽,包括用戶基本信息、興趣等。你需要做的只是上傳一批你目前已有的用戶或者你感興趣的一批用戶,剩下的工作就等著Custom Audiences幫你完成了。
Facebook這種通過一群已有的用戶發現并擴展出其他用戶的推薦算法就叫Lookalike,當然Facebook的算法細節筆者并不清楚,各個公司實現Lookalike也各有不同。這里也包括騰訊在微信端的廣告推薦上的應用、Google在YouTube上推薦感興趣視頻等。下面讓我們結合前人的工作,實現自己的Lookalike算法,并嘗試著在新浪微博上應用這一算法。
調研
首先要確定微博領域的數據,關于微博的數據可以這樣分類:
用戶基礎數據:年齡、性別、公司、郵箱、地點、公司等。
關系圖:根據人?人,人?微博的關注、評論、轉發信息建立關系圖。
內容數據:用戶的微博內容,包含文字、圖片、視頻。
有了這些數據后,怎么做數據的整合分析?來看看現在應用最廣的方式——協同過濾、或者叫關聯推薦。協同過濾主要是利用某興趣相投、擁有共同經驗群體的喜好來推薦用戶可能感興趣的信息,協同過濾的發展有以下三個階段:
第一階段,基于用戶喜好做推薦,用戶A和用戶B相似,用戶B購買了物品a、b、c,用戶A只購買了物品a,那就將物品b、c推薦給用戶A。這就是基于用戶的協同過濾,其重點是如何找到相似的用戶。因為只有準確的找到相似的用戶才能給出正確的推薦。而找到相似用戶的方法,一般是根據用戶的基本屬性貼標簽分類,再高級點可以用上用戶的行為數據。
第二階段,某些商品光從用戶的屬性標簽找不到聯系,而根據商品本身的內容聯系倒是能發現很多有趣的推薦目標,它在某些場景中比基于相似用戶的推薦原則更加有效。比如在購書或者電影類網站上,當你看一本書或電影時,推薦引擎會根據內容給你推薦相關的書籍或電影。
第三階段,如果只把內容推薦單獨應用在社交網絡上,準確率會比較低,因為社交網絡的關鍵特性還是社交關系。如何將社交關系與用戶屬性一起融入整個推薦系統就是關鍵。在神經網絡和深度學習算法出現后,提取特征任務就變得可以依靠機器完成,人們只要把相應的數據準備好就可以了,其他數據都可以提取成向量形式,而社交關系作為一種圖結構,如何表示為深度學習可以接受的向量形式,而且這種結構還需要有效還原原結構中位置信息?這就需要一種可靠的向量化社交關系的表示方法。基于這一思路,在2016年的論文中出現了一個算法node2vec,使社交關系也可以很好地適應神經網絡。這意味著深度學習在推薦領域應用的關鍵技術點已被解決。
在實現算法前我們主要參考了如下三篇論文:
Audience Expansion for Online Social Network Advertising 2016
node2vec: Scalable Feature Learning for Networks Aditya Grover 2016
Deep Neural Networks for YouTube Recommendations 2016
第一篇論文是LinkedIn給出的,主要談了針對在線社交網絡廣告平臺,如何根據已有的受眾特征做受眾群擴展。這涉及到如何定位目標受眾和原始受眾的相似屬性。論文給出了兩種方法來擴展受眾:
1. 與營銷活動無關的受眾擴展;
2. 與營銷活動有關的受眾擴展。
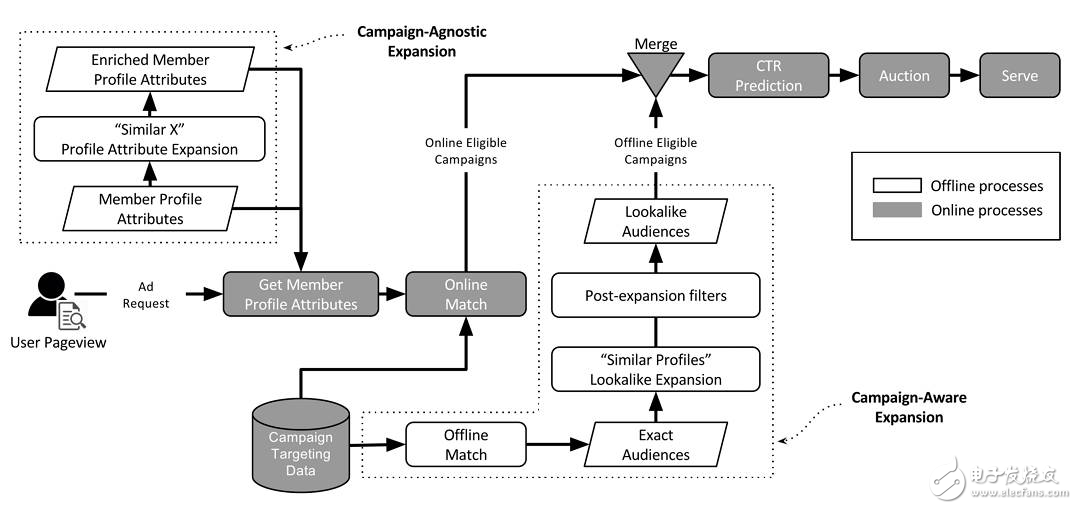
圖1 LinkedIn的Lookalike算法流程圖
在圖1中,LinkedIn給出了如何利用營銷活動數據、目標受眾基礎數據去預測目標用戶行為進而發現新的用戶。今天的推薦系統或廣告系統越來越多地利用了多維度信息。如何將這些信息有效加以利用,這篇論文給出了一條路徑,而且在工程上這篇論文也論證得比較扎實,值得參考。
第二篇論文,主要講的是node2vec,這也是本文用到的主要算法之一。node2vec主要用于處理網絡結構中的多分類和鏈路預測任務,具體來說是對網絡中的節點和邊的特征向量表示方法。
簡單來說就是將原有社交網絡中的圖結構,表達成特征向量矩陣,每一個node(可以是人、物品、內容等)表示成一個特征向量,用向量與向量之間的矩陣運算來得到相互的關系。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%