大數據操作系統(tǒng)轉型分析smack堆棧
從大數據到快速數據
除了能夠以批處理模式分析大型數據集之外,現代數據驅動型組織還需要盡快從所收集的數據中生成洞察,并最終采取行動。在這方面,傳統(tǒng)的Hadoop堆棧(HDFS作為存儲層,MapReduce或Tez作為處理框架,YARN作為集群資源管理器)缺乏嚴重性。為了減輕這種情況,業(yè)界已經提出了諸如Lambda架構(見《程序員》2016年11月“Lambda與Kappa計算架構之我見”一文)等架構。在Lambda架構中,一個“慢”大數據處理框架(如Hadoop堆棧)與一個“快速”的流處理框架(如Apache Storm)組合在一起。由快速框架處理的數據或者與慢速處理框架周期性地重新集成,或者完全丟棄,并且由使用慢速處理框架處理的數據代替。當然,這種Lambda型結構并不是沒有問題,它會導致代碼重復和需要重新處理與集成數據。
SMACK堆棧
所謂的SMACK堆棧是一個在過去一年中變得流行的架構。SMACK堆棧的各部分如下:
Spark作為一個通用、快速、內存中的大數據處理引擎;
Mesos作為集群資源管理器;
Akka作為一個基于Scala的框架,允許我們開發(fā)容錯、分布式、并發(fā)應用程序;
Cassandra作為一個分布式、高可用性存儲層;
Kafka作為分布式消息代理/日志。
首先我們將快速討論組成SMACK堆棧的部件,特別注意Cassandra,因為它與堆棧的其他部分不同,似乎沒有在國內廣泛使用。
Apache Spark
Apache Spark已經成為一種“大數據操作系統(tǒng)”。數據被加載并保存到簇存儲器中,并且可以被重復查詢。這使得Spark對機器學習算法特別有效。Spark為批處理、流式處理(以微批處理方式)、圖形分析和機器學習任務提供統(tǒng)一的接口。它用Scala編寫,并公開了Scala、Java、Python和R的API。此外,Spark能夠對數據執(zhí)行SQL查詢,更利于分析師們學習傳統(tǒng)的BI工具。
Apache Mesos
Apache Mesos是一個開源的集群管理器,由加州大學伯克利分校開發(fā)。它允許跨分布式應用程序的高效資源隔離和共享。在Mesos中,這樣的分布式應用程序被稱為框架。
Akka
Akka是構建在JVM上運行的并發(fā)程序框架。強調一個基于actor的并發(fā)方法:actors被當作原語,它們只通過消息而不涉及共享內存進行通信。響應消息,actors可以創(chuàng)建新的actors或發(fā)送其他消息。actor模型由Erlang編程語言編寫,更易普及。
Apache Cassandra
Cassandra最初是在Facebook開發(fā)的,后來成為一個Apache開源項目。它是一個分布式、面向列的NoSQL數據存儲,類似于Amazon的Dynamo和Google的BigTable。與其他NoSQL數據存儲相反,它不依賴于HDFS作為底層文件系統(tǒng),具有無主控架構,允許它具有幾乎線性的可擴展性,并且易于設置和維護。Cassandra的另一個優(yōu)勢是支持跨數據中心復制(XDCR)。跨數據中心復制實際上有助于使用單獨的工作負載和分析集群。Cassandra的企業(yè)版可從DataStax (http://www.datastax.com)獲得。
根據固定分區(qū)鍵,數據在Cassandra集群的節(jié)點上分割。其架構意味著它沒有單點故障。根據CAP定理,我們可以在每個表的基礎上對一致性和可用性進行微調。
Apache Kafka
在SMACK堆棧內,Kafka負責事件傳輸。Kafka集群在SMACK堆棧中充當消息主干,可以跨集群復制消息,并將其永久保存到磁盤以防止數據丟失。
在詳細了解SMACK堆棧的各部分如何協(xié)同工作之前,我們將快速討論Cassandra的數據模型及其在Cassandra上進行分析所面臨的挑戰(zhàn)。
Cassandra數據模型
與其他NoSQL數據存儲類似,基于Cassandra應用程序的成功數據模型應該遵循“存儲你查詢的內容”模式。也就是說,與關系數據庫相反,在關系數據庫中,我們可以以標準化形式存儲數據。當我們談論Cassandra數據模型時,仍然使用術語table,但是Cassandra表的行為更像排序,分布式映射,然后是關系數據庫中的表。
Cassandra支持用于定義表與插入和查詢數據的SQL語言,稱為Cassandra Query Language(CQL)。
當定義一個Cassandra表時,我們需要提供一個分區(qū)鍵,它確定數據在集群節(jié)點之間的分布方式,以及確定數據如何排序的聚簇列。當使用CQL查詢時,我們只能查詢(使用WHERE子句)并根據聚簇列排序。
讓我們來看看Cassandra文檔中的一個示例,該文檔是音樂共享服務(如Spotify)中的播放列表建模:

在這個例子中,uuid(通用唯一ID,保證在多個機器之間是唯一的)id是分區(qū)鍵,song_order是聚類列,(id,song_order)需要在表的所有行中都是唯一的。此外,id決定了在哪個機器上存儲行,song_order決定了行在物理主機上的存儲順序。也可以在Cassandra中使用復合分區(qū)鍵,將它們放在()中。
CQL查詢如下所示:
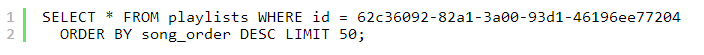
WHERE子句中出現的任何列都要求是主鍵的一部分,或者可以在其上定義索引。此外,分區(qū)鍵只能出現在相等(=)操作中。只有當所選行的集合被作為連續(xù)塊存儲在主機上時,范圍查詢才是可行的。通過聚類SQL的類似列和LIMIT子句,CQL能夠支持排序,但不具備GROUP BY的類似功能。
根據特定列進行查詢,減少了對隨機磁盤訪問的需求,但也強烈限制了Cassandra作為分析數據庫的使用。“存儲你查詢的內容”范例需要根據Cassandra數據庫上執(zhí)行的查詢進行仔細地數據建模,從而限制了支持新查詢的能力。為了對存儲在Cassandra中的數據執(zhí)行分析,應該將數據加載到單獨的處理框架中,我們選擇Apache Spark框架。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%