Sharding-JDBC簡介及適用場景
大小:0.5 MB 人氣: 2017-10-12 需要積分:1
標(biāo)簽:sharding(7810)
【編者按】數(shù)據(jù)庫分庫分表從互聯(lián)網(wǎng)時代開啟至今,一直是熱門話題。在NoSQL橫行的今天,關(guān)系型數(shù)據(jù)庫憑借其穩(wěn)定、查詢靈活、兼容等特性,仍被大多數(shù)公司作為首選數(shù)據(jù)庫。因此,合理采用分庫分表技術(shù)應(yīng)對海量數(shù)據(jù)和高并發(fā)對數(shù)據(jù)庫的沖擊,是各大互聯(lián)網(wǎng)公司不可避免的問題。雖然很多公司都致力于開發(fā)自己的分庫分表中間件,但截止目前,仍無完美的開源解決方案覆蓋此領(lǐng)域。
分庫分表適用場景
分庫分表用于應(yīng)對當(dāng)前互聯(lián)網(wǎng)常見的兩個場景——大數(shù)據(jù)量和高并發(fā)。通常分為垂直拆分和水平拆分兩種。
垂直拆分是根據(jù)業(yè)務(wù)將一個庫(表)拆分為多個庫(表)。如:將經(jīng)常和不常訪問的字段拆分至不同的庫或表中。由于與業(yè)務(wù)關(guān)系密切,目前的分庫分表產(chǎn)品均使用水平拆分方式。
水平拆分則是根據(jù)分片算法將一個庫(表)拆分為多個庫(表)。如:按照ID的最后一位以3取余,尾數(shù)是1的放入第1個庫(表),尾數(shù)是2的放入第2個庫(表)等。
關(guān)系型數(shù)據(jù)庫在大于一定數(shù)據(jù)量的情況下檢索性能會急劇下降。在面對互聯(lián)網(wǎng)海量數(shù)據(jù)情況時,所有數(shù)據(jù)都存于一張表,顯然會輕易超過數(shù)據(jù)庫表可承受的數(shù)據(jù)量閥值。這個單表可承受的數(shù)據(jù)量閥值,需根據(jù)數(shù)據(jù)庫和并發(fā)量的差異,通過實際測試獲得。
單純的分表雖然可以解決數(shù)據(jù)量過大導(dǎo)致檢索變慢的問題,但無法解決過多并發(fā)請求訪問同一個庫,導(dǎo)致數(shù)據(jù)庫響應(yīng)變慢的問題。所以通常水平拆分都至少要采用分庫的方式,用于一并解決大數(shù)據(jù)量和高并發(fā)的問題。這也是部分開源的分片數(shù)據(jù)庫中間件只支持分庫的原因。
但分表也有不可替代的適用場景。最常見的分表需求是事務(wù)問題。同在一個庫則不需考慮分布式事務(wù),善于使用同庫不同表可有效避免分布式事務(wù)帶來的麻煩。目前強一致性的分布式事務(wù)由于性能問題,導(dǎo)致使用起來并不一定比不分庫分表快。目前采用最終一致性的柔性事務(wù)居多。分表的另一個存在的理由是,過多的數(shù)據(jù)庫實例不利于運維管理。綜上所述,最佳實踐是合理地配合使用分庫+分表。
Sharding-JDBC簡介
Sharding-JDBC是當(dāng)當(dāng)應(yīng)用框架ddframe中,從關(guān)系型數(shù)據(jù)庫模塊dd-rdb中分離出來的數(shù)據(jù)庫水平分片框架,實現(xiàn)透明化數(shù)據(jù)庫分庫分表訪問。Sharding-JDBC是繼dubbox和elastic-job之后,ddframe系列開源的第3個項目。
Sharding-JDBC直接封裝JDBC API,可以理解為增強版的JDBC驅(qū)動,舊代碼遷移成本幾乎為零:
可適用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。可基于任何第三方的數(shù)據(jù)庫連接池,如DBCP、C3P0、 BoneCP、Druid等。理論上可支持任意實現(xiàn)JDBC規(guī)范的數(shù)據(jù)庫。雖然目前僅支持MySQL,但已有支持Oracle、SQLServer等數(shù)據(jù)庫的計劃。
Sharding-JDBC定位為輕量Java框架,使用客戶端直連數(shù)據(jù)庫,以jar包形式提供服務(wù),無proxy代理層,無需額外部署,無其他依賴,DBA也無需改變原有的運維方式。
Sharding-JDBC分片策略靈活,可支持等號、between、in等多維度分片,也可支持多分片鍵。
SQL解析功能完善,支持聚合、分組、排序、limit、or等查詢,并支持Binding Table以及笛卡爾積表查詢。
與常見開源產(chǎn)品對比
為了對其他開源項目表示尊重,我們無意評論目前仍在更新中的項目。這里僅列出目前停止更新,但仍然在數(shù)據(jù)庫分片領(lǐng)域非常有影響力的幾個項目,請參見表1。
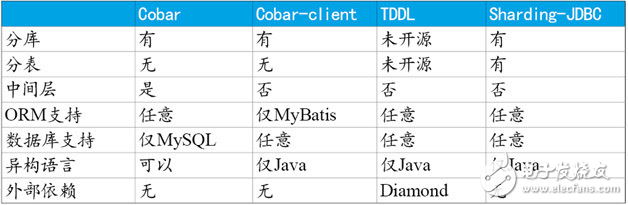
表1 數(shù)據(jù)庫分片工具對比
通過以上表格可以看出,Cobar屬于中間層方案,在應(yīng)用程序和MySQL之間搭建一層Proxy。中間層介于應(yīng)用程序與數(shù)據(jù)庫間,需要做一次轉(zhuǎn)發(fā),而基于JDBC協(xié)議并無額外轉(zhuǎn)發(fā),直接由應(yīng)用程序連接數(shù)據(jù)庫,性能上有些許優(yōu)勢。這里并非說明中間層一定不如客戶端直連,除了性能,需要考慮的因素還有很多,中間層更便于實現(xiàn)監(jiān)控、數(shù)據(jù)遷移、連接管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均屬于客戶端直連方案。此方案的優(yōu)勢在于輕便、兼容性、性能以及對DBA影響小。其中Cobar-Client的實現(xiàn)方式基于ORM(Mybatis)框架,其兼容性與擴(kuò)展性不如基于JDBC協(xié)議的后兩者。
實現(xiàn)原理
前文已介紹了Sharding-JDBC是實現(xiàn)了JDBC協(xié)議的jar文件。基于JDBC協(xié)議的實現(xiàn)與基于MySQL等數(shù)據(jù)庫協(xié)議實現(xiàn)的中間層略有差別。
無論使用哪種架構(gòu),核心邏輯均極為相似,除了協(xié)議實現(xiàn)層不同(JDBC或數(shù)據(jù)庫協(xié)議),都會分為分片規(guī)則配置、SQL解析、SQL改寫、SQL路由、SQL執(zhí)行以及結(jié)果歸并等模塊。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%