 電子發(fā)燒友App
電子發(fā)燒友App


介紹
近年來,向基于NAND閃存的存儲遷移和非易失性存儲器快車?(NVMe?)的引入,為技術(shù)公司以不同的方式“做存儲”增加了許多機會1。實時數(shù)字業(yè)務(wù)的快速增長和多樣化要求這種創(chuàng)新,以便實現(xiàn)新的產(chǎn)品和服務(wù)。因此,新的存儲產(chǎn)品順應(yīng)了更高的帶寬、更低的延遲以及減少占地面積和總擁有成本的趨勢--這對于依賴大型基礎(chǔ)設(shè)施的公司來說是至關(guān)重要的改進。最近的市場報告2預(yù)測,NVMe市場將以約15%的年均增長率增長,到2020年達到570億美元。NVMe市場繼續(xù)發(fā)展,并在三個領(lǐng)域?qū)で筮M一步的技術(shù)創(chuàng)新。
1. 存儲虛擬化以提高靈活性和安全性
2. 靠近存儲數(shù)據(jù)的局部數(shù)據(jù)處理
3. 優(yōu)化基礎(chǔ)設(shè)施的分類存儲3
2018年3月,BittWare發(fā)布了250系列FPGA產(chǎn)品,該產(chǎn)品提供了創(chuàng)新的解決方案,以滿足存儲市場的需求。250系列產(chǎn)品采用Xilinx? UltraScale+? FPGA和MPSoC,在單芯片中提供ASIC級功能,符合存儲行業(yè)的技術(shù)需求6。通過將NVMe與可重構(gòu)邏輯FPGA和MPSoC相結(jié)合,BittWare提供了一類新的存儲產(chǎn)品,在快速發(fā)展的市場中具有關(guān)鍵的差異化優(yōu)勢;Xilinx器件的靈活性和可重構(gòu)性保證了基于20的解決方案可以保持最新的功能,因為NVMe標(biāo)準(zhǔn)隨著時間的推移會融入新的功能5。
本應(yīng)用說明介紹了BittWare支持FPGA和MPSoC的250系列加速器產(chǎn)品如何用于讓客戶為下一代物聯(lián)網(wǎng)和云基礎(chǔ)設(shè)施構(gòu)建高性能、可擴展的NVMe基礎(chǔ)架構(gòu)。
NVMe路線圖
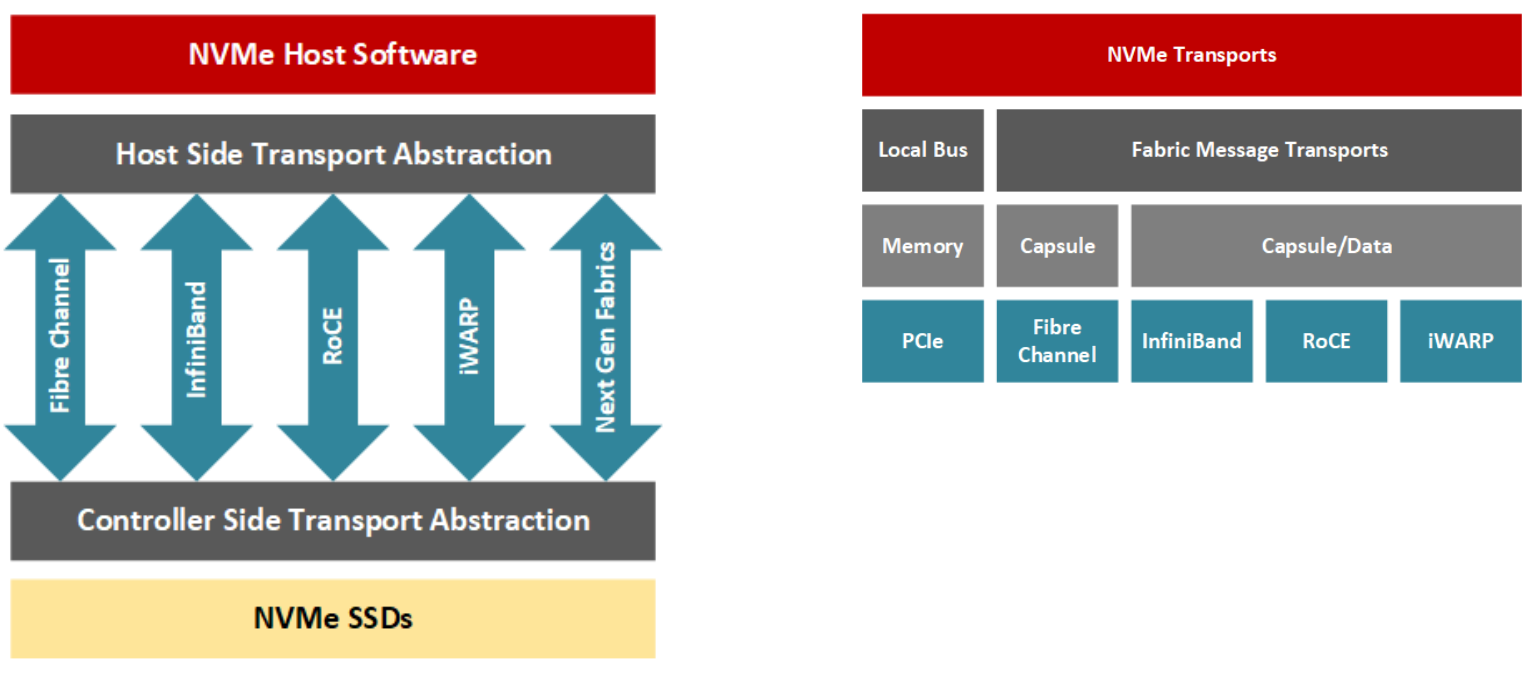
自2011年NVMe誕生以來,NVMe聯(lián)盟一直非常活躍。事實上,NVMe協(xié)議目前正從三個角度發(fā)展,分別定義在不同的規(guī)范中。除了基本的NVMe規(guī)范外,NVMe管理接口(NVMe-MI)詳細介紹了如何管理通信和設(shè)備(設(shè)備發(fā)現(xiàn)、監(jiān)控等),而NVMe over Fabric(NVMe-oF)則推動了如何通過網(wǎng)絡(luò)與非易失性存儲進行通信,以呈現(xiàn)協(xié)議的傳輸不可知性9。
隨著時間的推移,隨著越來越多來自不同行業(yè)的用戶開始采用NVMe,新用戶對新功能的需求進行了定性,并對規(guī)范提出了新的想法。NVMe協(xié)議的應(yīng)用還在不斷增加,它正在產(chǎn)生創(chuàng)新。硬件和軟件公司正在通過引入新的外形因素、創(chuàng)造新的產(chǎn)品和設(shè)備等方式來尋找新的方式進入內(nèi)存。NVMe生態(tài)系統(tǒng)的重點是為用戶提供擴展到數(shù)據(jù)中心或超大規(guī)模基礎(chǔ)設(shè)施的手段,協(xié)議規(guī)范將繼續(xù)朝著這個方向發(fā)展9。
2019年將發(fā)布NVMe基礎(chǔ)規(guī)范的1.4修訂版,這將帶來數(shù)據(jù)延遲、非易失性數(shù)據(jù)的高性能訪問和多個主機之間數(shù)據(jù)共享的便利性方面的改進。NVMe用戶,特別是云提供商期待的功能之一是IO確定性,這將提高IO10并行執(zhí)行期間的服務(wù)質(zhì)量。通過將后臺維護任務(wù)的影響限制在最小范圍內(nèi),并控制嘈雜鄰居的影響,IO確定性功能將為用戶在訪問非易失性數(shù)據(jù)時提供一致的延遲。另一種方法是之前討論的開放通道架構(gòu)11。通過第二種方法,主機接管了部分管理功能,只有數(shù)據(jù)前往存儲硬件。在這種配置中,硬盤與主機的物理接口僅限于高速數(shù)據(jù)通道,沒有邊帶通道。這個例子顯示了NVMe規(guī)范中任何變化的影響和相關(guān)性,并強調(diào)了對靈活的NVMe硬件基礎(chǔ)設(shè)施的要求。
隨著基礎(chǔ)、MI和over Fabric規(guī)范的新修訂版在未來幾個月內(nèi)出臺,NVMe用戶將受益于一個靈活的基礎(chǔ),它可以適應(yīng)新的NVMe要求。250系列FPGA和MPSoC產(chǎn)品不僅提供了這種靈活性,而且還解決了當(dāng)今客戶的挑戰(zhàn),為客戶帶來了直接的競爭優(yōu)勢。
為什么是FPGA?
Bittware的FPGA和MPSoC產(chǎn)品采用了最新的Xilinx UltraScale+技術(shù),并滿足了數(shù)據(jù)中心對NVMe日益關(guān)注的需求。三十多年來,F(xiàn)PGA已經(jīng)為多個行業(yè)提供了可編程硬件解決方案,并被廣泛用于解決汽車、廣播、醫(yī)療和軍事市場等領(lǐng)域的計算和嵌入式系統(tǒng)問題。同時,近年來,F(xiàn)PGA廠商在集成系統(tǒng)設(shè)計中對這一成熟技術(shù)進行了最新、最優(yōu)秀的改進。
Xilinx UltraScale+ FPGA和MPSoC產(chǎn)品采用16nm工藝,通過提供高速結(jié)構(gòu)、嵌入式RAM、時鐘和DSP處理來提高系統(tǒng)性能。此外,Xilinx器件還引入了更快的收發(fā)器技術(shù)(高達32.75Gb/s),以實現(xiàn)更高的吞吐量連接到網(wǎng)絡(luò)或PCIe結(jié)構(gòu)。憑借其高數(shù)量的串行收發(fā)器通道,UltraScale+產(chǎn)品可以同時連接到多個PCIe接口,并為主機CPU提供數(shù)據(jù)卸載接口。在某些情況下,通過用FPGA或MPSoC替換PLX開關(guān),CPU可以卸載部分處理工作,騰出時間進行其他操作。FPGA和MPSoC的可編程邏輯還可以在系統(tǒng)中提供確定性和低延遲的接口,在某些用例中可以獲得明顯的競爭優(yōu)勢。
最近的FPGA系列現(xiàn)在也在器件結(jié)構(gòu)中加入了嵌入式低功耗微處理器。UltraScale+ MPSoC通過將它們結(jié)合到單一封裝中,滿足了需要軟件以及可編程邏輯的應(yīng)用需求。例如,Xilinx Zynq UltraScale+ ZU19EG具有兩個處理單元,一個是四核ARM Cortex-A53,一個是實時雙核ARM Cortex-R5,此外還有一個圖形處理單元ARM Mali?-400 MP2,滿足有混合計算需求的應(yīng)用。ZU19EG MPSoC器件是一款非常通用的芯片,特別適合NVMe over Fabric或Open Channel的實現(xiàn),其中可編程邏輯為存儲數(shù)據(jù)提供了低延遲的確定性路徑,而ARM內(nèi)核則可執(zhí)行復(fù)雜的數(shù)據(jù)包控制操作,或在無CPU的嵌入式系統(tǒng)中取代主機CPU。
在過去的幾年里,BittWare一直走在存儲行業(yè)的前列,并通過開發(fā)基于NVMe技術(shù)的產(chǎn)品為其創(chuàng)新發(fā)展做出了貢獻。BittWare認(rèn)識到,F(xiàn)PGA可以減少I/O瓶頸,并為NVMe固態(tài)硬盤提供一條直接的高速確定性路徑。早在2015年,BittWare就與Xilinx和IBM合作開發(fā)了創(chuàng)新的NoSQL數(shù)據(jù)庫解決方案12。250系列FPGA&MPSoC板建立在這一初始產(chǎn)品的成功基礎(chǔ)上,并為服務(wù)器存儲背板增加了更深更快的板載內(nèi)存、網(wǎng)絡(luò)連接、片上系統(tǒng)和布線選項等功能。
250 FPGA & MPSoC產(chǎn)品系列
250 FPGA和MPSoC產(chǎn)品線包括三種FPGA適配器,即250S+、250-U2和250-SoC,可連接到各種行業(yè)標(biāo)準(zhǔn)的外形尺寸,如PCIe插槽、OCuLink/Nano-Pitch、SlimSAS、MiniSAS HD、U.2存儲背板等。250系列產(chǎn)品可直接安裝到現(xiàn)有基礎(chǔ)設(shè)施的PCIe結(jié)構(gòu)中,以實現(xiàn)對NVMe存儲設(shè)備的低延遲直接訪問。
?
250S+直連式加速器
該系列的第一個加速器是250S+。這款FPGA加速器采用Xilinx UltraScale+ Kintex 15P FPGA和4個板載四通道1TB M.2 NVMe驅(qū)動器(共4TB非易失性閃存),采用符合PCIe標(biāo)準(zhǔn)的8通道半高半長外形。另外,對于只想在系統(tǒng)中引入FPGA計算并且已經(jīng)有存儲設(shè)備的客戶,M.2板載連接器可以使用Molex低損耗高速布線技術(shù),連接到OCuLink/Nano-Pitch或MiniSAS HD NVMe背板。KU15P FPGA擁有1,143K系統(tǒng)邏輯單元、1,968個DSP Slices和70.6 Mb的嵌入式存儲器,是UltraScale+ Kintex FPGA系列中最大的器件,并為實現(xiàn)增值功能提供了大量的可配置資源。板載DDR4內(nèi)存庫允許對更深層次的數(shù)據(jù)向量進行額外的緩沖。
?
250S+有兩種配置。
最多四個M.2 NMVe固態(tài)硬盤通過卡上耦合到Xilinx FPGA。
OCuLink 分離式布線使 250S+ 成為大規(guī)模擴展存儲陣列的一部分。
這款緊湊的高密度存儲節(jié)點為主機需要高速讀取或?qū)懭霐?shù)據(jù)到NVMe驅(qū)動器的應(yīng)用提供了一個一體化的解決方案。板載FPGA設(shè)備可以有效地協(xié)調(diào)和處理數(shù)據(jù)流,將驅(qū)動器呈現(xiàn)為一個或多個命名空間或?qū)崿F(xiàn)RAID功能。250S+可用作直接連接加速器(DAA)來虛擬化存儲,允許NVMe SSD與多個虛擬機共享,在主機CPU和NVMe SSD之間提供一層隔離和安全。FPGA的可編程邏輯還提供了在線打包、壓縮或加密數(shù)據(jù)的選項,對驅(qū)動器訪問帶寬和延遲的影響很小;例如,Xilinx的擦除編碼IP引入了可忽略不計的90ns延遲--與基于CPU的實現(xiàn)相比,在原始性能方面遠勝一籌。250S+還解決了檢查點重啟或突發(fā)緩沖緩存的用例;為虛擬化和獨立的AI和IoT環(huán)境提供了一個簡單的緩存解決方案。
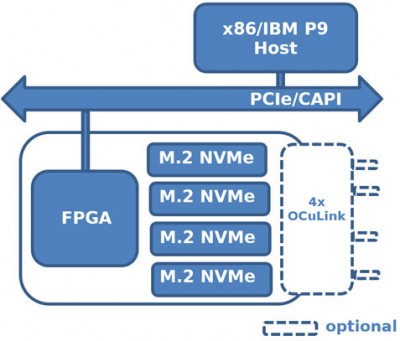
直接附著式加速器(DAA)
虛擬化NVMe存儲,并在多個虛擬機之間共享。
隔離NVMe存儲,以提高主機CPU和NVMe SSD之間的安全性。
250S+ & 250-SoC
250S-U2代理在線加速器
250系列的第二個成員是250-U2。這款加速器板采用Xilinx UltraScale+ Kintex 15P FPGA(與250S+相同)和一列DDR4內(nèi)存,采用2.5“U.2驅(qū)動形式。與250S+不同的是,250-U2沒有任何直接連接到FPGA的板載SSD。這款加速器的新穎設(shè)計使其能夠在沒有專用PCIe插槽的系統(tǒng)中適應(yīng)現(xiàn)有的U.2存儲背板,在現(xiàn)有的標(biāo)準(zhǔn)U.2 NVMe存儲旁邊提供額外的計算能力。這款250-U2產(chǎn)品承擔(dān)了代理在線加速器(PIA)的角色。
?
250-U2可以執(zhí)行在線壓縮、加密和散列,也可以執(zhí)行更復(fù)雜的功能,如擦除編碼、重復(fù)數(shù)據(jù)刪除、字符串/圖像搜索或數(shù)據(jù)庫排序/加入/過濾。根據(jù)應(yīng)用的計算需求,背板群體將顯示出不同比例的250-U2板卡用于NVMe驅(qū)動器。250-U2與存儲一起位于U.2背板中,與其他標(biāo)準(zhǔn)的U.2 NVMe驅(qū)動器一樣,具有利用NVMe-MI規(guī)范的維護選項。由于250-U2處理節(jié)點和存儲直接連接到主機服務(wù)器的PCIe結(jié)構(gòu),DMA數(shù)據(jù)流量可以完全繞過CPU和全局內(nèi)存,利用SPDK等技術(shù)優(yōu)化端到端數(shù)據(jù)傳輸。使用RDMA或點對點DMA解決方案,數(shù)據(jù)直接在NVMe端點之間流動,完全繞過CPU。這些直接進入FPGA和MPSoC可編程邏輯的接口大大降低了訪問延遲(Lusinsky,201721)。另外,這種硬件平臺的另一個用例是作為卸載計算引擎,將很好地適應(yīng)FPGAaaS可擴展基礎(chǔ)設(shè)施。
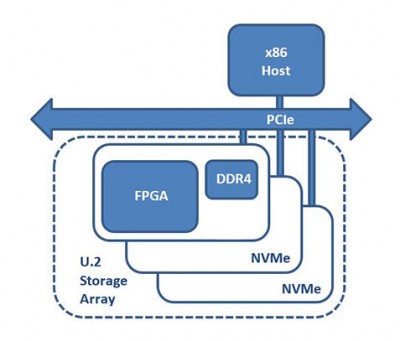
代理在線加速器(PIA)
在本地NVMe存儲數(shù)據(jù)上執(zhí)行低延遲、高帶寬的處理。
多種主機形式 8通道PCIe適配器或2.5”U.2“適配器
250S+ & 250-U2
用于NVMe-over-Fabric的250-SoC。
該系列的第三款加速器250-SoC采用了Xilinx UltraScale+ Zynq 19EG MPSoC,可以通過兩個QSFP28端口(支持100GbE的25Gbps線路速率)連接到網(wǎng)絡(luò)結(jié)構(gòu),也可以通過一個16線PCIe 3.0主機接口和四個8線OCuLink連接器連接到PCIe結(jié)構(gòu)。ZU19EG是該系列中最大的器件,擁有1,143K系統(tǒng)邏輯單元、1,968個DSP Slices和70.6 Mb的嵌入式存儲器。器件封裝中的嵌入式ARM處理和圖形單元為具有混合處理要求的產(chǎn)品創(chuàng)造了理想的平臺。
?
250-SoC的硬件通用性允許從網(wǎng)絡(luò)直接訪問存儲,并支持NVMe-over-Fabric。NVMe-oF是下一代NVMe協(xié)議,可通過網(wǎng)絡(luò)結(jié)構(gòu)分解存儲,并遠程管理存儲;NVMe-oF還提供了比SAS更多的靈活性,可按需設(shè)置網(wǎng)絡(luò)陣列。分散存儲或EJBOF(Ethernet Just-a-Bunch-Of-Flash)硬件可降低數(shù)據(jù)中心的存儲成本、占地面積和功耗。
Xilinx Zynq MPSoC芯片為嵌入式系統(tǒng)提供了額外的靈活性。MPSoC板可以獨立于主機CPU運行操作系統(tǒng)及其完整的軟件棧。憑借其支持多達兩個100GbE端口的高帶寬網(wǎng)絡(luò)功能和板載MPSoC,250-SoC無需為NVMe-oF應(yīng)用同時使用外部網(wǎng)絡(luò)接口卡(NIC)和外部處理器13。基于FPGA的NVMe-oF基礎(chǔ)架構(gòu)的實現(xiàn)非常簡單,而且性能良好,因為數(shù)據(jù)只需通過硬件路徑,從而提供了一個低和可預(yù)測的延遲解決方案。
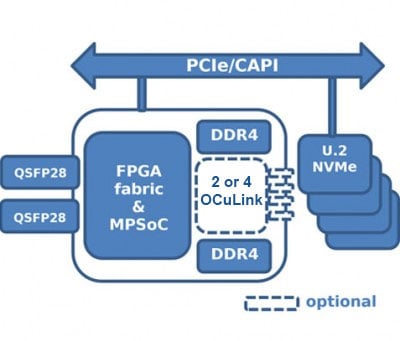
NVMe-over-Fabric (NVMEoF)
在數(shù)據(jù)中心網(wǎng)絡(luò)結(jié)構(gòu)上實現(xiàn)NVMe幀的低延遲和高吞吐量。
250-SoC
250-SoC為存儲行業(yè)提供了一系列靈活的解決方案。250S+和250-SoC針對直接連接加速器的應(yīng)用案例,滿足虛擬化和提高安全性的需求。250-U2和250S+作為代理在線加速器,可以輕松插入到現(xiàn)有的基礎(chǔ)設(shè)施中,為NVMe存儲提供低延遲和高帶寬的本地數(shù)據(jù)計算。最后,250-SoC支持NVMe-over-Fabric,作為一種僅有硬件的創(chuàng)新方法,在支持最新一代NVMe協(xié)議的同時,對存儲進行分解。隨著NVMe市場的不斷發(fā)展,F(xiàn)PGA和MPSoC解決方案將解決NVMe產(chǎn)品的應(yīng)用難題。
NVMe應(yīng)用
NVMe技術(shù)給存儲帶來了顛覆性的創(chuàng)新,并對數(shù)據(jù)中心基礎(chǔ)設(shè)施產(chǎn)生了深遠的影響。協(xié)議的特性使NVMe成為設(shè)計涉及存儲的新產(chǎn)品或應(yīng)用時的首選。
數(shù)據(jù)庫加速等企業(yè)應(yīng)用需要低延遲以及高帶寬的4K或8K數(shù)據(jù)寫入傳輸速率,這兩個要求完全符合NVMe協(xié)議的優(yōu)勢。這些特性使NVMe成為實現(xiàn)重做日志的領(lǐng)頭羊,例如,在數(shù)據(jù)庫發(fā)生故障時,會存儲許多事務(wù)記錄并用于未來重放的用例。對于這種用例,250S+將高達4TB的NVMe存儲直接帶到FPGA可重構(gòu)結(jié)構(gòu)的邊緣,在那里,交易記錄被高速收集到SSD上,準(zhǔn)備重播14。
NVMe還減輕了虛擬化基礎(chǔ)架構(gòu)的挑戰(zhàn),并簡化了虛擬機(Virtual Machines)、無狀態(tài)虛擬機和SRIOV的實施,其中IO是最常見的瓶頸。在無狀態(tài)虛擬機用例中,IT經(jīng)理需要鎖定企業(yè)用戶不修改的操作系統(tǒng)鏡像。用戶只修改自己的數(shù)據(jù),操作系統(tǒng)鏡像在NVMe存儲中保持不變,用戶之間的隱私和安全至關(guān)重要。對于這樣的IT基礎(chǔ)架構(gòu),NVMe存儲是多用戶共享的。250S+是實現(xiàn)這一應(yīng)用的一體化平臺。每個1TB的物理硬盤都被FPGA IP分割,因此每個用戶都能隔離并安全地訪問其操作系統(tǒng)鏡像和數(shù)據(jù)。管理程序管理對硬盤的直接訪問,而不需要仿真驅(qū)動,這為這種IO綁定的應(yīng)用提供了更好的性能。
”大數(shù)據(jù)“市場也為將存儲和處理結(jié)合起來的智能NVMe產(chǎn)品帶來了機會,因為它正在從批處理方法轉(zhuǎn)向?qū)崟r處理方法。地圖縮減問題正朝著實時分析而不是批處理的方向發(fā)展,因此,它們需要一種新的存儲層,這種存儲層的速度要比GFS后端快得多。現(xiàn)在在IT基礎(chǔ)設(shè)施中看到的存儲分層將很少訪問和低速的冷存儲,分離到非常快的SSD、NVMe或NVM存儲器中。在這種用例中,所有的數(shù)據(jù)都會被記錄在GDFS中,但隨后會被移動到具有更快內(nèi)存的計算節(jié)點上。實現(xiàn)NVMe-over-Fabric的250-SoC滿足了這兩個要求,因為它可以訪問高速存儲和高性能計算能力。
深度學(xué)習(xí)行業(yè)與分析界有類似的需求。深度學(xué)習(xí)的新一代加速器,即GPGPU、TPU和FPGA;這些設(shè)備需要大的內(nèi)存帶寬來匹配芯片的計算能力。訓(xùn)練操作會消耗大量的這種高通量數(shù)據(jù),通常是多TB的數(shù)據(jù)15。最近的研究工作表明,F(xiàn)PGA結(jié)構(gòu)可以加速某些網(wǎng)絡(luò)類型的訓(xùn)練操作。因此,將存儲和計算引擎結(jié)合到一個硬件平臺上可以減少延遲,隨著訓(xùn)練數(shù)據(jù)集的增加,允許更多的再訓(xùn)練周期16。
在HPC領(lǐng)域,250S+的本地存儲和250-SoC的遠程版本有一些應(yīng)用,如檢查點/重啟、突發(fā)緩沖區(qū)、分布式文件系統(tǒng)或從調(diào)度器緩存作業(yè)數(shù)據(jù)。通過在FPGA結(jié)構(gòu)上靠近存儲的地方運行算法,F(xiàn)PGA應(yīng)用的占用率仍然很低,同時充分利用存儲,并將CPU騰出來用于其他處理作業(yè)。而不是簡單地存儲數(shù)據(jù)或使用主機CPU對內(nèi)存數(shù)據(jù)庫進行壓縮或加密,其中千兆字節(jié)的數(shù)據(jù)保存在易失性存儲器中,但需要定期備份到閃存中。基于FPGA的系統(tǒng)可以處理這些數(shù)據(jù)的快照,以便永久存儲到基于NVMe的大型存儲陣列中。對于這種類型的操作,MPSoC特別適合對用戶數(shù)據(jù)進行更復(fù)雜的操作。
最后,在物聯(lián)網(wǎng)領(lǐng)域,需要在物聯(lián)網(wǎng)網(wǎng)關(guān)上進行數(shù)據(jù)過濾和預(yù)處理,在物聯(lián)網(wǎng)網(wǎng)關(guān)上進行數(shù)據(jù)的聚合以及接收到數(shù)據(jù)后的加密,F(xiàn)PGA通過加密或壓縮等位運算實時處理數(shù)據(jù)流,并使用250S+將數(shù)據(jù)在板上存儲走,或使用有線250S+或250-SoC將數(shù)據(jù)以輸入帶寬傳遞到存儲背板。從區(qū)塊鏈計算來看,F(xiàn)PGA也是首選平臺。區(qū)塊鏈技術(shù)為物聯(lián)網(wǎng)網(wǎng)關(guān)帶來了差異化,提供一種自適應(yīng)和安全的方法來維護物聯(lián)網(wǎng)設(shè)備的用戶隱私偏好17。
BittWare的能力
二十多年來,BittWare幫助行業(yè)專家在其基礎(chǔ)架構(gòu)中引入FPGA來設(shè)計、開發(fā)和優(yōu)化工作負載。在此期間,BittWare的計算和網(wǎng)絡(luò)解決方案為各個行業(yè)的客戶提供了競爭優(yōu)勢,包括HPC、金融、基因組學(xué)和嵌入式計算。BittWare結(jié)合了硬件、軟件和系統(tǒng)設(shè)計的專業(yè)知識,指導(dǎo)客戶在其產(chǎn)品中最大限度地發(fā)揮FPGA技術(shù)的優(yōu)勢。
?
在250加速器系列中,BittWare選擇了多種Xilinx UltraScale+器件和PCIe外形,為存儲基礎(chǔ)設(shè)施架構(gòu)師提供完整的解決方案。這些加速器將Xilinx器件的可編程邏輯直接連接到基礎(chǔ)架構(gòu)網(wǎng)絡(luò)中,并通過上一代100GbE和PCIe 3.0高速接口連接PCIe結(jié)構(gòu)。此外,利用BittWare母公司Molex的能力,250系列提供了連接現(xiàn)有硬件的高靈活性。Molex是超高速低損耗電纜和互連解決方案的行業(yè)領(lǐng)導(dǎo)者。
結(jié)論
NVMe已經(jīng)并仍在快速地改變著存儲行業(yè)。這種全新的高吞吐量存儲技術(shù)為IT基礎(chǔ)設(shè)施提供了靈活的存儲解決方案。與上一代存儲相比,NVMe不僅提供了卓越的數(shù)據(jù)寫入和讀取帶寬,還充分利用了現(xiàn)有數(shù)據(jù)中心的PCIe和網(wǎng)絡(luò)結(jié)構(gòu)。隨著NVMe的普及,業(yè)界創(chuàng)新者紛紛推出支持NVMe的新產(chǎn)品。所有的基礎(chǔ)數(shù)據(jù)中心設(shè)備都在更新,以支持NVMe;NVMe存儲背板已經(jīng)成為新的標(biāo)準(zhǔn)。
基于FPGA的NVMe產(chǎn)品,讓計算與存儲在硬件層面融合,達到更高的應(yīng)用性能。通過FPGA,可重構(gòu)邏輯的處理通過高吞吐量和低延遲的管道直接連接到存儲上。由于這些特點,數(shù)據(jù)可以流經(jīng)FPGA并進行實時處理。此外,通過使用FPGA處理,CPU核可以自由地執(zhí)行其他只能在處理器上運行的任務(wù)。使用MPSoC,系統(tǒng)可以獲得更多的功能,并將高速數(shù)據(jù)處理和設(shè)備上的控制結(jié)合起來,有可能自主運行。
BittWare基于FPGA和MPSoC的存儲產(chǎn)品旨在滿足實際應(yīng)用的需求,并解決IT基礎(chǔ)架構(gòu)管理人員的挑戰(zhàn)。BittWare通過250產(chǎn)品系列提供了一條生產(chǎn)路徑。
審核編輯:郭婷















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論