 FPGA與GPU計算存儲加速對比
FPGA與GPU計算存儲加速對比
硬件制造商正在將加速方法應用于計算存儲,這是專門設計用于包含內嵌計算元素的存儲。這種方法已經被證明可以為分析和 AI 應用提供優異的性能。使用或者不使用機器學習輔助的分析以及驗證,都可以借助計算存儲器件進行加速。這些器件提供了一個關鍵的優勢,使得成本高昂的計算被卸載到存儲器件上,而不必在服務器 CPU 上完成。與標準的存儲/CPU 方法相比,通過計算存儲獲得的優勢包括:
1. 借助應用專用編程定制可編程硬件,獲得更高性能
2. 將計算任務從服務器卸載到存儲器件,釋放 CPU 資源
3. 數據與計算共址,降低數據傳輸需求
這種新穎的方法前景光明。不過,您應根據具體用例評估這種方法,考量性能、成本、功耗和易用性。性價比和單位功耗性能在選擇加速硬件評估時,占據主要比率。在本文中,我們將研討單位功耗性能。
計算存儲功耗比較
在這個場景中,我們將比較以 CSV 數據讀取用例為主的三種工具:英偉達 GPUDirect 存儲 和RAPIDS存儲,以及基于賽靈思技術的三星 SmartSSD 存儲。CSV 讀取在計算密集型流水線中起著重要的作用(參見圖 1)。
在下文中,我們將性能定義成 CSV 的處理速率,或處理“帶寬”。我們先快速回顧一下三種系統的運行方式。
英偉達 GPUDirect 存儲
端到端滿足分析和 AI 需求
將 GPU 用作計算單元,緊貼基于 NVMe 的存儲器件布局 (GPUDirect)
使用 CUDA 進行編程 (RAPIDS)
英偉達用其 CSV 數據讀取技術衡量相對于標準 SSD 的性能提升。結果如圖 1 所示。使用 1 到 8 個加速器時,對應的吞吐量是 4 到 23GB/s。
三星 SmartSSD 驅動器
將賽靈思 FPGA 用作計算單元
與存儲邏輯內嵌駐留在同一個內部 PCIe 互聯上
通過編程在存儲平臺上開展運算
賽靈思數據分析解決方案合作伙伴 Bigstream 與三星合作,為 Apache Spark 設計加速器,包括用于 CSV 和 Parquet 處理的 IP。SmartSSD 的測試使用單機模式的 CSV 解析引擎,以便開展比較。結果如圖 2 所示,使用 1 到 12 個加速器時,對應的吞吐量是 4 到 23GB/s,同時也給出英偉達的結果(使用 1 到 8 個加速器)。請注意,本討論中的所有結果都按 x 軸上的加速器數量進行參數化。
這些結果令人振奮,但在選擇您的解決方案時,請務必將功耗情況納入考慮。
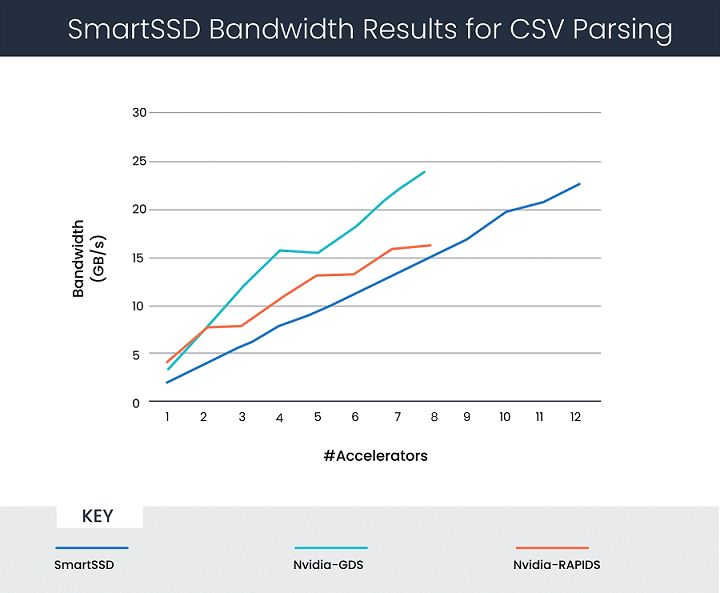
圖 2:SmartSSD 驅動器的 CSV 解析性能結果
單位功耗性能比較
圖 3 顯示了將功耗考慮在內后的分析結果。它們代表單位功耗達到的性能水平,根據上述討論中引用的相關材料,給出了以下假設:
Tesla V100 GPU:最大功耗 200 瓦
SmartSSD 驅動器 FPGA:最大功耗 30 瓦
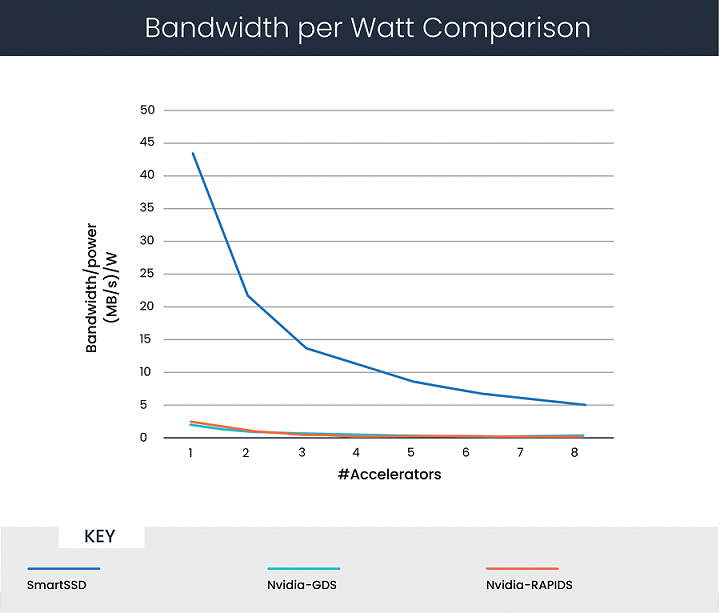
圖 3:CSV 解析的每瓦功耗帶寬比較
在這個場景下,計算表明,在全部使用 8 個加速器的情況下,SmartSSD 的單位功耗性能比 GPUDirect Storage 高 25 倍。
最終思考
計算存儲的優勢在于能增強數據分析和 AI 應用的性能。然而,要讓這種方法具備可實際部署的能力和實用性,就必須在評估時將功耗納入考慮。
針對用于 CSV 數據解析的兩種不同的計算存儲方法,我們已經提出按功耗參數化的吞吐量性能曲線。結果顯示,在使用相似數量的加速器進行比較時,SmartSSD 驅動器的單位功耗性能優于 GPUDirect存儲方法。
審核編輯:郭婷
-
FPGA
+關注
關注
1643文章
21981瀏覽量
614540 -
驅動器
+關注
關注
54文章
8640瀏覽量
149176 -
gpu
+關注
關注
28文章
4915瀏覽量
130720
發布評論請先 登錄
GPU加速計算平臺的優勢
云 GPU 加速計算:突破傳統算力瓶頸的利刃
ASIC和GPU的原理和優勢
GPU加速云服務器怎么用的
《CST Studio Suite 2024 GPU加速計算指南》
NPU與GPU的性能對比
PyTorch GPU 加速訓練模型方法
FPGA和ASIC在大模型推理加速中的應用

FPGA加速深度學習模型的案例
Achronix Speedster7t FPGA與GPU解決方案的比較
FPGA與MCU的應用場景
信號計算主板設計方案:735-基于3U VPX的AGX Xavier GPU計算主板
科普:GPU和FPGA,有何異同






 工商網監
工商網監
評論