 英偉達1小時成功訓練BERT,83億參數打造史上最大語言模型
英偉達1小時成功訓練BERT,83億參數打造史上最大語言模型
英偉達一舉創造了2個壯舉!訓練出了世界上最大的語言模型——MegatronLM,包含83億參數,比BERT大24倍,比GPT-2大5.6倍;還打破了實時對話AI的記錄,僅耗時53分鐘即可訓練出行業標準BERT模型、2毫秒就能對答案做出推斷!
世界上最大的語言模型來了,順便還破了個記錄!
英偉達宣布,目前已經訓練出了世界上最大的語言模型——MegatronLM。
這個模型有多大?83億個參數!比谷歌的 BERT 大24倍,比 OpenAI 的 GPT-2 大5.6倍!
不僅如此,英偉達還宣布打破了實時對話 AI 的記錄——耗時53分鐘就可以訓練出行業標準的BERT模型、2毫秒左右就能對答案做出推斷。
為了實現這一壯舉,英偉達利用模型的并行性,將一個神經網絡分割成多個部分,創建了因數據太大無法容納在單個GPU的訓練模型。
最重要的是,代碼已開源!

GitHub項目地址:
https://github.com/NVIDIA/Megatron-LM
MegatronLM,堪稱NLP 界的“威震天”!
有錢任性:訓練史上最大語言模型需要多少GPU?
更大的語言模型對于諸如文章完成、問題回答和對話系統等NLP任務非常有用。最近,訓練最大的神經語言模型已經成為提高NLP應用水平的最佳方法。
最近的兩篇論文,BERT和GPT-2,展示了大規模語言建模的好處。這兩篇論文都利用了計算機和可用文本語料庫的進步,在自然語言理解、建模和生成方面顯著超越了當前的最優水平。
訓練這些模型需要數以百計exaflops級的計算力和巧妙的內存管理,以換取減少內存占用的重新計算。然而,對于超過10億參數的超大型的模型,單個GPU上的內存不足以匹配模型以及訓練所需的參數,需要利用模型并行性來將參數分割到多個GPU上。有幾種建模并行性的方法,但是它們很難使用,因為它們依賴于自定義編譯器,或者擴展性很差,或者需要對優化器進行更改。
在這項工作中,我們通過對現有PyTorch transformer實現進行少量有針對性的修改,實現了一種簡單而有效的模型并行方法。我們的代碼是用原生Python編寫的,利用混合精度訓練,并利用NCCL庫在GPU之間進行通信。 我們通過在512個GPU上訓練一個transformer語言模型證明了這種方法的有效性,該模型具有8路模型并行性和64路數據并行性,83億參數,使其成為有史以來規模最大的基于transformer的語言模型,其大小為BERT的24倍,GPT-2的5.6倍。我們已經在GitHub存儲庫中發布了實現此方法的代碼。
我們的實驗是在英偉達的DGX SuperPOD上進行的。在沒有模型并行性的情況下,我們可以在單個V100 32GB GPU上訓練一個12億參數的基線模型,并在整個訓練過程中保持39 TeraFLOPS,這是DGX2-H服務器上單個GPU理論峰值的30%。
我們將模型參數擴展到83億,使用512個GPU,通過8路模型并行化,在整個應用程序中我們實現了高達15.1 PetaFLOPS的持續性能,與單GPU相比,擴展效率達到76%。圖1顯示了擴展的結果。
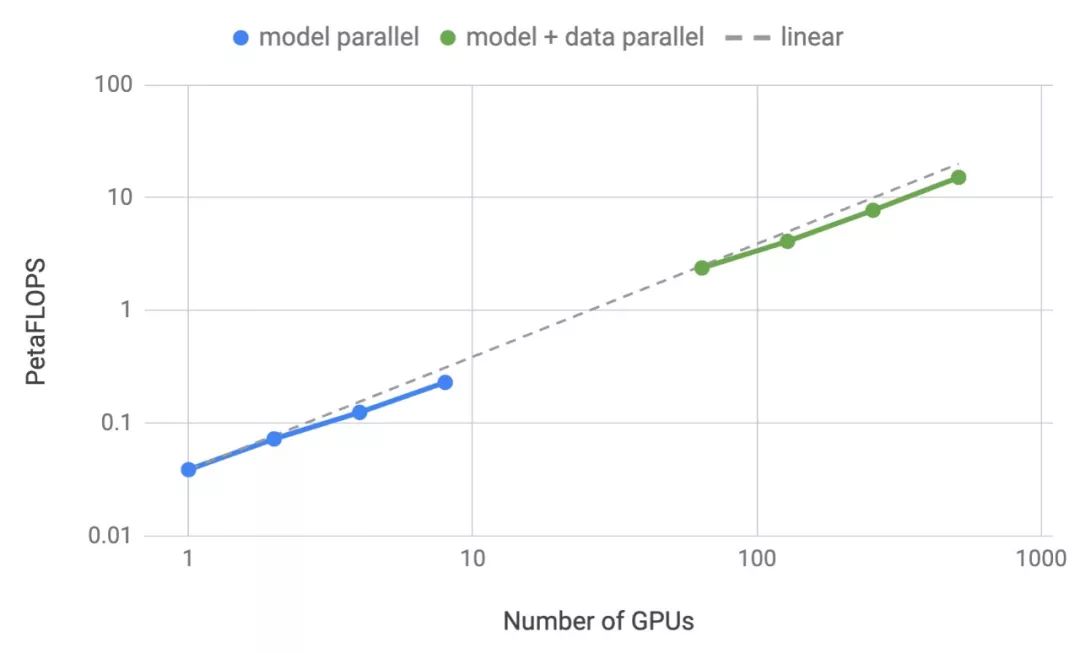
圖1:模型并行(藍色):多達8路模型并行弱擴展,每個GPU大約有10億個參數(例如2個GPU有20億參數,4個GPU有40億參數)。模型+數據并行(綠色):類似于模型并行的64路數據并行的配置。
多GPU并行性
訓練模型的典型范例是利用 weak scaling 方法和分布式數據并行性,根據GPU的數量來擴展訓練批大小。這種方法允許模型在更大的數據集上進行訓練,但有一個約束,即所有參數必須適合一個GPU。
模型并行訓練可以通過跨多個GPU劃分模型來克服這一限制。近年來出現了幾個通用模型并行框架,如GPipe和Mesh-TensorFlow。gPipe在不同的處理器上劃分層組,而Mesh-TensorFlow使用層內模型并行性。我們的方法在概念上類似于Mesh-TensorFlow,我們關注層內并行性并融合GEMM以減少同步。然而,我們只對現有PyTorch transformer實現進行了一些有針對性的修改,以便使用模型并行性來訓練大型transformers。我們的方法很簡單,不需要任何新的編譯器或代碼重新連接來實現模型并行性,并且可以通過插入一些簡單的primitives(圖2中的f和g 算子)完全實現。
我們利用 transformer網絡的結構,通過添加一些同步primitives來創建一個簡單的模型并行實現。
transformer層由一個self attention block和一個2層的多層感知器(MLP)組成。我們分別在這兩個模塊中引入模型并行性。
如圖2a所示,這是MLP的結構,由兩個GEMM組成,中間有一個GeLU非線性,后面有一個dropout層。我們以列并行方式劃分第一個GEMM。這使得GeLU 非線性可以獨立地應用于每個分塊GEMM的輸出。模塊中的第二個GEMM沿著行并行化,直接獲取GeLU層的輸出,不需要任何通信。然后,在將輸出傳遞到dropout層之前,跨GPU減少第二個GEMM的輸出。這種方法將MLP block中的GEMM跨GPU分割了,只需要在正向傳遞(g算子)中執行一個all-reduce操作,在反向傳遞(f算子)中執行一個all-reduce操作。

圖2:(a): MLP, (b):transformer的self attention block。
如圖2(b)所示,在self attention block上,我們利用multihead attention操作中的固有并行性,以列并行方式劃分與鍵(K),查詢(Q)和值(V)相關聯的 GEMM。
這使得我們可以在GPU之間分割每個attention head參數和工作負載,并且不需要任何即時通信來完成self attention。
這種方法對于MLP和self-attention層都融合了兩個GEMM的組,消除了中間的同步點,并獲得了更好的scaling性能。這使我們能夠在一個簡單的transformer層中執行所有GEMM,只使用前向路徑的2個all reduce和后向路徑的2個all reduce,如圖3所示。

圖3:GPT-2 transformer層的模型并行性。
這種方法實現起來很簡單,因為它只需要在向前和向后傳遞中添加一些額外的all-reduce操作。它不需要編譯器,并且與gPipe等方法提倡的那種pipeline模型并行性是正交的。
性能
為了測試我們的實現的計算性能,我們考慮了表1中四組參數的GPT-2模型。

表1:用于scaling 研究的參數。
所有的實驗都是在NVIDIA的DGX SuperPOD上進行的,我們使用了多達32臺DGX- 2h服務器(總共512個Tesla V100 SXM3 32GB GPU)。該系統針對多節點深度學習應用程序進行了優化,服務器內部GPU之間的帶寬為300 GB/s,服務器之間的互連帶寬為100 GB/s。
圖4顯示了模型和模型+數據并行性的擴展值。我們在這兩種設置中都觀察到了出色的擴展數字。例如,8路(8 GPU)模型并行的83億參數模型實現了77%的線性擴展。模型+數據并行性要求在反向傳播步驟之后進一步通信梯度,因此擴展數略有下降。然而,即使是運行在512個GPU上的最大配置(83億參數),相對于強大的基準單GPU配置(12億個參數),我們仍然可以實現74%的擴展性。
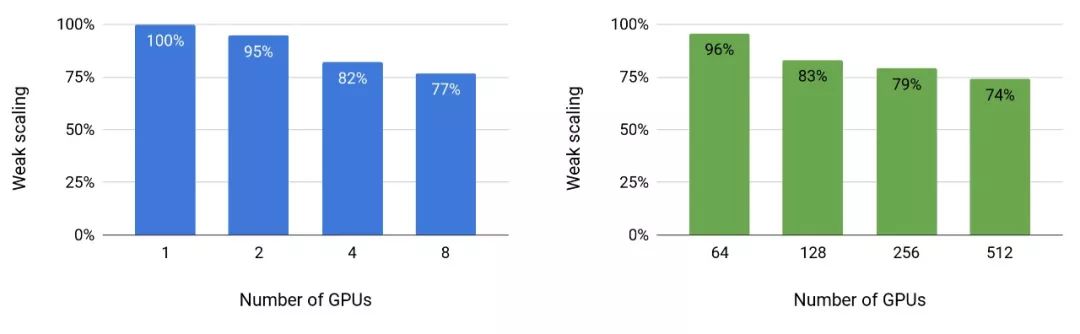
圖4:模型(左)和模型+數據(右)隨著GPU的數量并行地進行weak scaling。
最后,我們研究了attention heads對模型并行擴展的影響。為此,我們考慮了83億參數、具有8路模型并行性的參數配置,并將attention heads的數目從16個改為32個。結果如表2所示。隨著attention heads數量的增加,self attention層中的一些GEMM變小,同時softmax中的元素數量增加。這導致了輕微的scaling decrease。未來的研究在設計大型transformer模型時應該警惕這種超參數,平衡模型性能和模型效率。
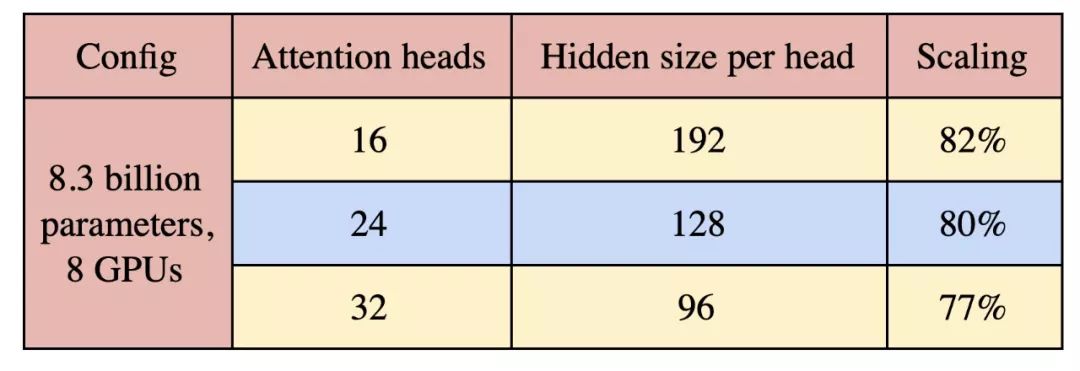
表2:attention heads 數量對scaling的影響。
GPT-2訓練
為了訓練GPT-2模型,我們創建了一個從_Reddit_下載的37 GB _WebText_ dataset,它類似于原始GPT-2論文中描述的webtext數據集。數據集最終有810萬個url。我們將WebText數據集隨機分割為95:5的比例,分別得到訓練集和驗證集。我們考慮了4種參數規模的模型:3.45億、7.75億、25億和83億。

圖5:訓練子集的驗證困惑度。在對37GB數據集過擬合之后,8.3B模型提前停止了。
圖5顯示了驗證的困惑度(perplexity)。我們發現。最大的83億參數的語言模型在~6epoch之后開始overfit,一種1 epoch被定義為15200次迭代。我們認為這可以通過使用更大規模的數據集來緩解,類似于XLNet和RoBERTa等最近論文中使用的數據集。
GPT-2評估
為了分析大型語言模型的訓練性能,我們在wikitext-103數據集上計算了perplexity,在Lambada數據集上計算了closize風格的預測精度。
正如預期的一樣,wikitext perplexity隨著模型尺寸的增大而減小,lambada準確率隨著模型尺寸的增大而增加(表3)。

表3:wikitext perplexity(越低越好)和Lambada完形精度(越高越好)的評估結果。
結論
在這項工作中,我們在現有的深度學習硬件、軟件和模型的基礎上,構建了世界上最大的基于transformer的語言模型。
在此過程中,我們成功地突破了傳統的單GPU訓練的限制,實現了一種簡單而高效的模型并行方法,只需對現有PyTorch transformer實現進行少量有針對性的修改。
我們在512臺NVIDIA V100 GPU上高效地訓練了83億參數的語言模型(分別比BERT和GPT-2大24倍和5.6倍),具有8路模型并行性,并在整個應用程序中實現了高達15.1千萬億次浮點運算(PetaFLOPS)。
我們發現,與較小的transformer模型相比,更大的transformer模型可以在相同的時間內進行訓練,并且可以顯著提高性能。
然而,正如我們在工作中所展示的,NLP仍然需要合適的數據集、問題和技術來正確地訓練這些大型語言模型,否則會出現過擬合。
我們將我們的工作開源,以便社區就可以復制并擴展它們。
英偉達官方GitHub項目已開源!
英偉達在官方GitHub上對MegatronLM開源了代碼,也提供了相應的教程。
項目地址:https://github.com/NVIDIA/Megatron-LM
安裝
官方只支持 Python 3.6。請安裝支持GPU的最新版本PyTorch。
此外,代碼庫的一部分利用tensorflow-cpu(可選)執行TFRecords的數據加載以進行BERT訓練。
建議要么使用./docker/中提供的Dockerfile,要么創建一個虛擬環境(以避免破壞現有的tf安裝)并安裝requirements.txt。
1python-mpipinstallvirtualenv 2virtualenvbert_env 3sourcebert_env/bin/activate 4pipinstall-rrequirements.txt
用法
提供了5個預訓練BERT的腳本和3個預訓練GPT2的腳本。使用 --save 和 --load 保存并加載模型檢查點(checkpoint)。
此外,還提供 GPT2 腳本,用于在wiki文本和LAMBADA上生成GPT2的交互式文本生成和零樣本(zero shot)評估。
BERT預訓練
1bashscripts/pretrain_bert.sh
此腳本運行單個gpu BERT預訓練,主要用于調試目的。優化參數設置為64路分布式訓練。
要使用此腳本,請 --train-data以loose json格式放置,每行一個json。json字典的文本字段應該對應于 --text-key。
1pythonpretrain_bert.py 2--num-layers24 3--hidden-size1024 4--num-attention-heads16 5--batch-size4 6--seq-length512 7--max-preds-per-seq80 8--max-position-embeddings512 9--train-iters1000000 10--savecheckpoints/bert_345m 11--loadcheckpoints/bert_345m 12--resume-dataloader 13--train-datawikipedia 14--lazy-loader 15--tokenizer-typeBertWordPieceTokenizer 16--tokenizer-model-typebert-large-uncased 17--presplit-sentences 18--cache-dircache 19--split949,50,1 20--distributed-backendnccl 21--lr0.0001 22--lr-decay-stylelinear 23--lr-decay-iters990000 24--weight-decay1e-2 25--clip-grad1.0 26--warmup.01 27--fp16 28--fp32-embedding
GPT2 預訓練
1bashscripts/pretrain_gpt2.sh
此腳本運行單gpu gpt2預訓練,主要用于調試目的。優化參數設置為64路分布式訓練。
它與前一個腳本格式大致相同,但有一些值得注意的差異:
--tokenizer-type已切換為GPT2BPETokenizer;
--lr-decay-style已切換為cosine decay等等。
另外,GPT2使用來自BERT的不同參數初始化,用于訓練深度殘差網絡。要使用此初始化來訓練BERT,請使用--deep-init。
1pythonpretrain_gpt2.py 2--num-layers24 3--hidden-size1024 4--num-attention-heads16 5--batch-size8 6--seq-length1024 7--max-position-embeddings1024 8--train-iters320000 9--savecheckpoints/gpt2_345m 10--loadcheckpoints/gpt2_345m 11--resume-dataloader 12--train-datawikipedia 13--lazy-loader 14--tokenizer-typeGPT2BPETokenizer 15--cache-dircache 16--split949,50,1 17--distributed-backendnccl 18--lr0.00015 19--lr-decay-stylecosine 20--weight-decay1e-2 21--clip-grad1.0 22--warmup.01 23--checkpoint-activations 24--fp16
-
計算機
+關注
關注
19文章
7636瀏覽量
90264 -
AI
+關注
關注
88文章
34407瀏覽量
275682 -
語言建模
+關注
關注
0文章
5瀏覽量
6315
原文標題:NLP界“威震天”襲來!英偉達1小時成功訓練BERT,83億參數打造史上最大語言模型
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI大模型不再依賴英偉達GPU?蘋果揭秘自研大模型

特朗普要叫停英偉達對華特供版 英偉達H20出口限制 或損失55億美元
英偉達Cosmos-Reason1 模型深度解讀
英偉達發布Nemotron-CC大型AI訓練數據庫
英偉達推出基石世界模型Cosmos,解決智駕與機器人具身智能訓練數據問題





 工商網監
工商網監
評論