 深度學習下的AI微表情研究
深度學習下的AI微表情研究

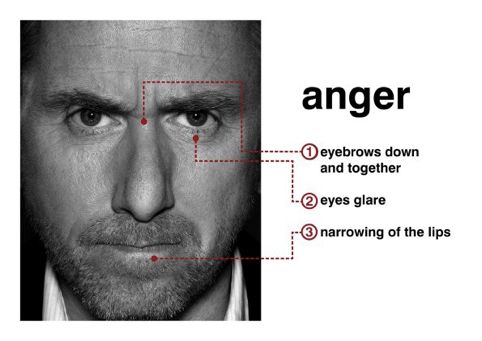
人是善于通過表情偽裝情緒的動物,但心理學家卻能夠通過“微表情”來揭示人們試圖隱藏的真實情緒。 所謂微表情,是一種持續時間極短、在人們試圖掩飾自己真實情緒時泄露出來的面部動作。 如果看過美劇《Lie to Me》,應該對微表情不會陌生。男主卡爾?萊特曼是一個微表情專家,他不需要借助測謊儀之類的設備,也不需要收集各種證據,甚至不需要對話,只需要觀察細微的表情變化便可以判斷一個人是否說謊。 之所以能夠這樣,是因為人們在體驗情緒時會有一系列肌肉動作不自覺地表現出來。 例如人們在憤怒時,眉毛會緊皺下垂,,眼瞼和嘴唇緊張:
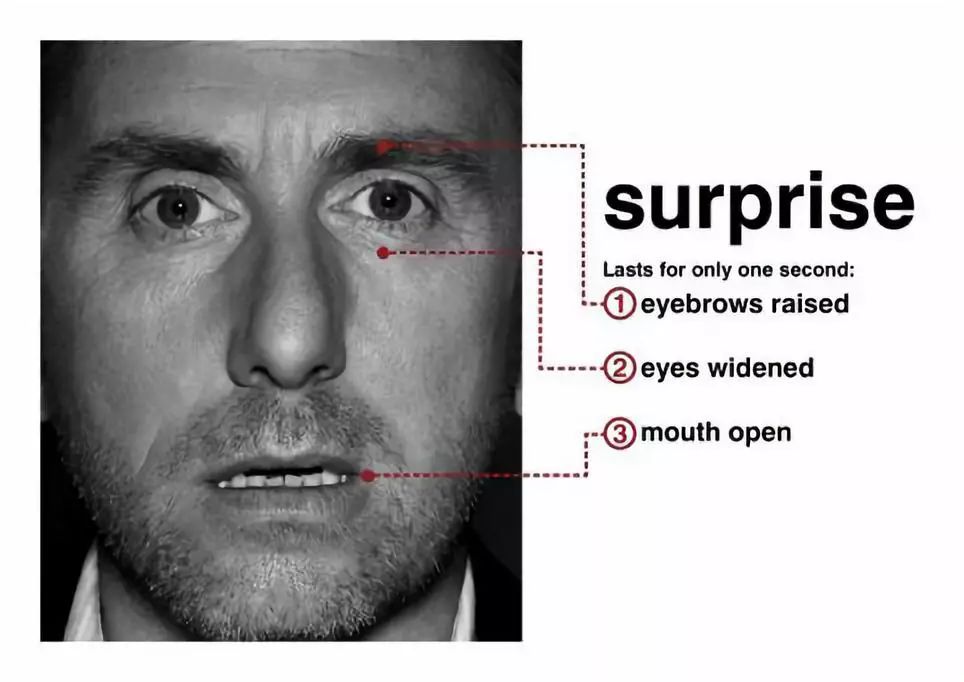
或者一個人在對事物表示驚訝時,下顎會自然下垂,嘴唇和嘴巴放松,眼睛張大,眼瞼和眉毛會微微上抬:
當然,我們知道面部表情是可以受主觀意識控制,例如一個人可能因其知識、閱歷、能力等原因,在內心波濤洶涌的時候做到面不改色。然而,微表情是面部肌肉條件反射地表現出情緒所對應的行為。正是因為如此,微表情往往能夠揭示人類試圖隱藏的真實情緒。 但正如對微表情的定義,微表情持續時間短暫、變化幅度微弱和動作區域較少,很多時候人們很難注意到其存在。只有那些經過大量訓練的專家才能準確地檢測,而且不同的專家還往往會判斷不一致。靠人工來觀察微表情真的是一個耗費人力、耗費時間,而且準確度低的事情! 停! 耗費人力物力、工作機械、需要大量專家……這不正是機器學習所擅長的嗎?事實上,目前已有許多學者在用機器學習的方法進行微表情研究了。
一、方法
對微表情的研究,在方法上事實上類似于人臉識別,一般包含檢測和識別兩個具體問題。 對于人臉識別,一般都是先進行人臉檢測,然后對檢測到的人臉進行識別。這個過程同樣也適用于微表情識別:先從一段長視頻中把發生微表情的視頻片段檢測出來,然后識別該微表情屬于哪一類微表情。
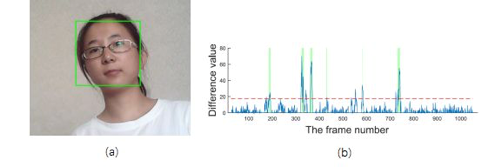
人臉檢測和微表情檢測 微表情檢測,就是指在一段視頻流中,檢測出是否包含微表情,并標記微表情的起點(onset)、峰值(apex)和終點(offset)。起點(onset) 是指微表情出現的時間;峰值(apex) 是指微表情幅度最大的時間; 終點(offset) 是指微表情消失的時間。 微表情識別是指給定一個已經分割好的微表情片斷,通過某種算法,識別該微表情的情緒種類(例如厭惡、悲傷、驚訝、憤怒、恐懼、快樂等)。如同三維動態表情識別一樣,其處理的對象是視頻片斷,而不只是單幅圖像。對其處理過程中,不僅要考慮空間上的模式,還要考慮時間上的模式。所以許多微表情識別的算法都考慮了時空模式。 相對于微表情檢測來說,微表情識別的難度要小一點。所以對微表情的研究一般從微表情識別開始入手。 不過對微表情的檢測和定位往往會更有實用價值。如果能在一段視頻中準確地檢測和定位到某個時間點有微表情出現,那么就說明這個人在這個時間點上可能會有異常。
二、數據集
事實上對于微表情研究,最難的是如何收集足夠多的、質量高的微表情數據集。 目前微表情數據庫并不多,已知的有:USF-HD數據庫,Polikovsky數據庫, SMIC數據庫, CASME數據庫, CASME II數據庫,SAMM數據庫,CAS(ME)2數據庫。在這八個數據庫中,前兩個都是非自然誘發的,且非公開的。 另外5個數據集,CASME、CASME II、CAS(ME)2是中國科學院心理研究所傅小蘭團隊所建立,SMIC是由芬蘭奧魯大學趙國英團隊建立。各個數據集的細節如下表所示:
五個公開發表的微表情數據庫 需要強調的是,這些數據庫的樣本量都非常小,到目前為止,公開發表的微表情樣本只有不到800個。是典型的小樣本問題。這就造成當前基于深度學習的方法在微表情問題上無法完全發揮出它應有的威力。 事實上,微表情數據庫的建立非常困難。一個原因是微表情的誘發很難,研究者往往要求被試觀看情緒視頻,激發他們的情緒同時要求他們偽裝自己的表情。有些被試可能并沒有出現微表情或者出現得很少。 另一方面,微表情的編碼也十分費時費力。微表情的編碼依賴于肉眼,需要觀察者慢速觀看視頻,并且選擇臉部運動的起始、高峰、結束并計算他們的時長。而且對于微表情的情緒標定,目前沒有統一的標準。 微表情數據庫面臨的另外的問題。因為微表情的運動幅度非常小,并且相對于常規表情常常是局部的運動,導致在情緒分類上并不是很明確,所以不同數據庫的情緒標定標準不一樣,所以相似的運動被作為不同類的微表情而不同的運動被視作為同類的表情。這一特點導致使用各種數據庫進行微表情識別算法訓練得出的結果并不一致。 此外,由于微表情持續時間短、強度低且經常是局部運動,現在的許多微表情數據庫視頻質量并不能滿足微表情識別分析的需要,這需要具有更高的時間和空間分辨率的視頻片段才能進一步改進目前的識別算法。 一句話:微表情建庫,重要性非常高,問題非常多,困難非常大。
三、現狀
近幾年來,微表情受到越來越多學者們的關注。
2009-2016年計算機科學領域中微表情論文發文量的統計(數據來自Scopus) 上圖對2009-2016年計算機科學領域中微表情論文發文量進行了統計。可以看出,近三年來,有關微表情論文的發文量在急劇增長。2009-2016年一共發文81篇,其中2016年就發文30篇,占總數37%。特別是2013年兩個微表情數據庫(CASME和SMIC)公開發布以后,微表情相關的論文發文量逐年遞增。 目前,國外做的較好的以芬蘭奧魯大學趙國英團隊為主,他們為微表情識別提出了一個系統的框架,并且公開以布了一個微表情數據庫SMIC。其他包括馬來西亞Multimedia大學的John See團隊、英國曼徹斯特都會大學的Moi Hoon Yap團隊、美國南佛羅里達大學的Shreve、日本筑波大學的Polikovsky和日本早稻田大學Yao等。 而國內做微表情檢測和識別的科研機構主要有中國科學院心理研究所傅小蘭團隊,前面提到的三個數據庫都是他們建立的。其次還有東南大學鄭文明團隊、山東大學賁晛燁團隊、復旦大學張軍平團隊、清華大學劉永進團隊、中山大學的鄭偉詩團隊等。可以看出,國內在這方面有相對較多的研究隊伍。 從微表情論文發文數量可以看出,微表情檢測和識別的研究屬于一個小眾的研究。其限制的主要原因在于大規模、高質量、公開的數據資源的稀缺。所以,用機器學習方法做微表情研究,面臨的一個重要的問題便是:如何建立大規模、高質量的數據庫資源。這面臨著從硬件,到軟件,到標準的一系列嚴峻挑戰。
-
AI
+關注
關注
88文章
35168瀏覽量
280153 -
人臉識別
+關注
關注
77文章
4089瀏覽量
84323 -
深度學習
+關注
關注
73文章
5561瀏覽量
122811
原文標題:深度學習下的微表情研究:困難、進展及趨勢
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
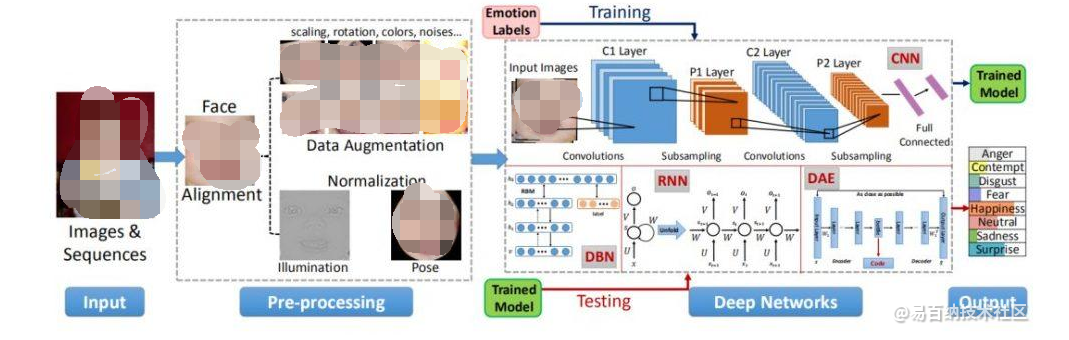
微表情識別-深度學習探索情感






 工商網監
工商網監
評論