 Python機器學習庫談Scikit-learn技術
Python機器學習庫談Scikit-learn技術
Scikit-learn是使用最廣泛的Python機器學習庫之一。它有標準化和簡單的接口,用于數據預處理和模型訓練、優化以及評估。
這個項目最初是由David Cournapeau 開發的Google Summer of Code 項目,并于2010年首次公開發布。自創建以來,該庫已經發展成為一個豐富的生態系統,用于開發機器學習模型。隨著時間的推移,該項目開發了許多方便的功能,以增強其易用性。在本文中,我將介紹你可能不知道的10個關于Scikit-learn最有用的特性。
1. 內置數據集
Scikit-learn API內置了各種toy和real-world數據集[1]。這些可以便捷地通過一行代碼訪問,如果你正在學習或只是想快速嘗試新功能,這會非常有用。
你還可以使用make_regression()、make_blobs()和make_classification()生成合成數據集。所有加載實用程序都提供了返回已拆分為X(特征)和y(目標)的數據選項,以便它們可以直接用于訓練模型。
2. 獲取公開數據集
如果你想直接通過Scikit-learn訪問更多的公共可用數據集,請了解,有一個方便的函數datasets.fetch_openml,可以讓您直接從openml.org網站[2]獲取數據。這個網站包含超過21000個不同的數據集,可以用于機器學習項目。
3. 內置分類器來訓練baseline
在為項目開發機器學習模型時,首先創建一個baseline模型是非常有必要的。這個模型在本質上應該是一個“dummy”模型,比如一個總是預測最頻繁出現的類的模型。這就提供了一個基準,用來對你的“智能”模型進行基準測試,這樣你就可以確保它的性能比隨機結果更好。
Scikit learn包括用于分類任務的DummyClassifier() 和用于基于回歸問題的 DummyRegressor()。
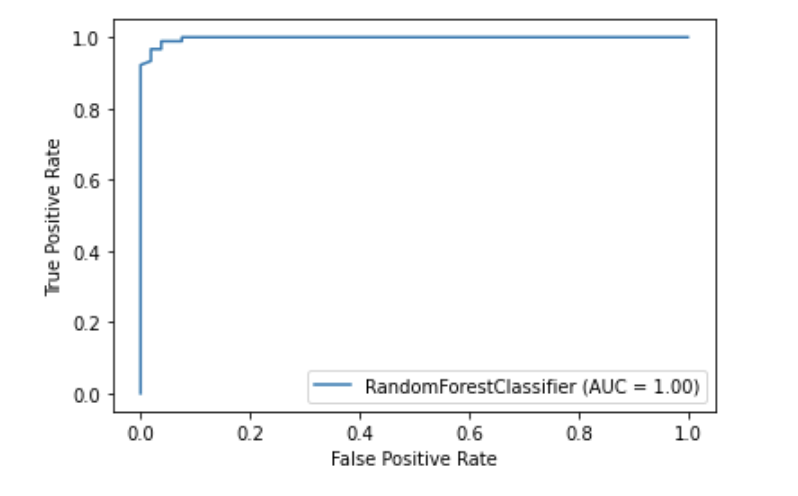
4. 內置繪圖api
Scikit learn有一個內置的繪圖API,允許你在不導入任何其他庫的情況下可視化模型性能。包括以下繪圖:部分相關圖、混淆矩陣、精確召回曲線和ROC曲線。
5. 內置特征選擇方法
提高模型性能的一種技術是只使用最好的特征集或通過刪除冗余特征來訓練模型。這個過程稱為特征選擇。
Scikit learn有許多函數來執行特征選擇。一個示例為 SelectPercentile(),該方法根據所選的統計方法選擇性能最好的X百分位特征進行評分。
6. 機器學習pipeline
除了為機器學習提供廣泛的算法外,Scikit learn還具有一系列用于「預處理」和「轉換數據」的功能。為了促進機器學習工作流程的再現性和簡單性,Scikit learn創建了管道(pipeline),允許將大量預處理步驟與模型訓練階段鏈接在一起。
管道將工作流中的所有步驟存儲為單個實體,可以通過「fit」和「predict」方法調用該實體。在管道對象上調用fit方法時,預處理步驟和模型訓練將自動執行。
7. ColumnTransformer
在許多數據集中,你將擁有不同類型的特征,需要應用不同的預處理步驟。例如,可能有分類數據和連續數據的混合,你可能希望通過one-hot編碼將分類數據轉換為數字,并縮放數字變量。
Scikit-learn管道有一個名為ColumnTransformer的函數,它允許你通過索引或指定列名來輕松指定要對哪些列應用最適當的預處理。
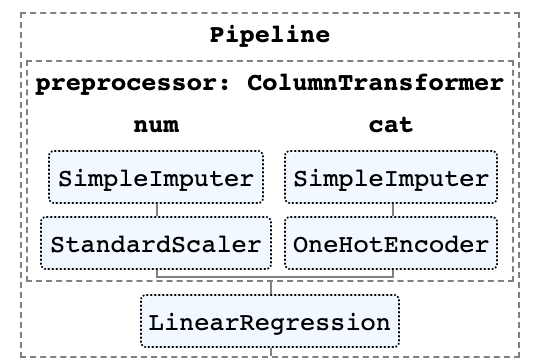
8. 管道的HTML形式
管道通常會變得非常復雜,尤其是在處理真實世界的數據時。因此,scikit-learn提供了一種方法來輸出管道中步驟的HTML圖表[3],非常方便。
9. 可視化 樹模型
plot_tree() 函數允許你創建決策樹模型中的步驟圖。
10. 豐富的第三方擴展
許多第三方庫可以更好地擴展scikit-learn的特性。舉個栗子,category-encoders庫,它為分類特性提供了更大范圍的預處理方法,以及ELI5包以實現更大的模型可解釋性。這兩個包也可以直接在Scikit-learn管道中使用。
本文參考資料
[1]toy和real-world數據集: https://scikit-learn.org/stable/datasets/index.html
[2]openml.org網站: https://www.openml.org/home
[3]HTML圖表: https://scikit-learn.org/stable/modules/compose.html#visualizing-composite-estimators
-
機器學習
+關注
關注
66文章
8492瀏覽量
134125 -
python
+關注
關注
56文章
4825瀏覽量
86232
原文標題:關于Scikit-Learn你(也許)不知道的10件事
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論