") 文本生成領域一些常見的模型進行了梳理和介紹
文本生成領域一些常見的模型進行了梳理和介紹

本文章對文本生成領域一些常見的模型進行了梳理和介紹。Seq2Seq 是一個經(jīng)典的文本生成框架,其中的Encoder-Decoder思想貫徹文本生成領域的整個過程。Pointer-Generator Networks是一個生成式文本摘要的模型,其采用的兩種經(jīng)典方法對于其他文本生成領域也有很重要的借鑒價值。SeqGAN模型將強化學習和GAN網(wǎng)絡引入到文本生成的過程中,是對文本生成領域的一個方向上的嘗試。GPT 對于文本生成領域有重大意義,是在文本生成領域使用預訓練模型的一個重大嘗試。生成句子是否符合正常語句表達也是文本生成領域的一個重大問題,生成的句子不僅需要沒有語法問題,同時符合正常的表達方式和邏輯也是一個很重要的評價指標,最后一節(jié)將介紹一種方法來對該指標進行評價。
1 分享內(nèi)容
介紹 Seq2Seq 模型
介紹 Pointer-Generator Networks模型
介紹 SeqGAN 模型
介紹 GPT-2 預訓練模型
介紹如何判斷生成句子是否符合正常語句表達
2 Seq2Seq模型介紹
seq2seq 是一個 Encoder–Decoder 結(jié)構(gòu)的網(wǎng)絡,它的輸入是一個序列,輸出也是一個序列, Encoder 中將一個可變長度的信號序列變?yōu)楣潭ㄩL度的向量表達,Decoder 將這個固定長度的向量變成可變長度的目標的信號序列。
快樂大本營有一期節(jié)目,嘉賓之間依次傳話,有趣的是傳到后面經(jīng)常會出現(xiàn)意思完全相反的現(xiàn)象,這個傳話可以類比成一個Encoder–Decoder過程。每個人對上一個人的聲音會在腦海里面形成一個理解,這個過程類似于Encoder,即將上一個人的聲音編碼成一個腦海里面形成的理解。最后我們把對腦海里面形成的理解用聲音表達出來,這個過程類似于Decoder階段。
2.1 Seq2Seq 工作流程
Seq2Seq的經(jīng)典應用場景是機器翻譯。如下是 Seq2Seq 模型工作的流程:
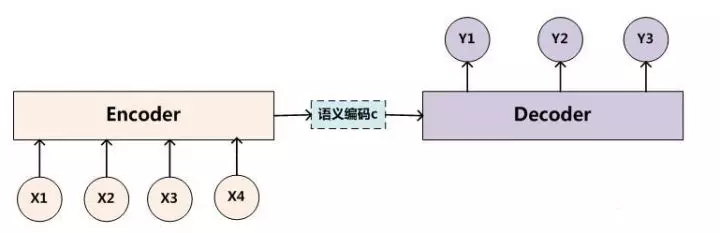
最基礎的 Seq2Seq模型 包含了三個部分, Encoder、Decoder 以及連接兩者的中間狀態(tài)向量 C,Encoder通過學習輸入,將其編碼成一個固定大小的狀態(tài)向量 C(也稱為語義編碼),繼而將 C 傳給Decoder,Decoder再通過對狀態(tài)向量 C 的學習來進行輸出對應的序列。
Encoder和decoder里面包含多個RNN 單元,通常是 LSTM 或者 GRU 。Basic Seq2Seq 有很多弊端的,首先 Encoder 將輸入編碼為固定大小狀態(tài)向量(hidden state)的過程實際上是一個“信息有損壓縮”的過程。如果信息量越大,那么這個轉(zhuǎn)化向量的過程對信息造成的損失就越大。同時,隨著 sequence length的增加,意味著時間維度上的序列很長,RNN 模型也會出現(xiàn)梯度彌散。最后,基礎的模型連接 Encoder 和 Decoder 模塊的組件僅僅是一個固定大小的狀態(tài)向量,這使得Decoder無法直接去關注到輸入信息的更多細節(jié)。
由于 Basic Seq2Seq 的種種缺陷,隨后引入了 Attention 的概念,Attention在decoder過程中的每一步,都會給出每個encoder輸出的特定權重,然后根據(jù)得到權重加權求和,從而得到一個上下文向量,這個上下文向量參與到decoder的輸出中,這樣大大減少了上文信息的損失,能夠取得更好的表現(xiàn),對于attention如何在Seq2Seq中使用,下一節(jié)將會有更加詳細的講解。
3 Pointer-Generator Networks模型
Pointer-Generator Networks 用于生成式文本摘要領域,其相比較于普通的Seq2Seq模型,主要的改點在于
(1) 避免SeqSeq模型在摘要生成時經(jīng)常出現(xiàn)的重復詞現(xiàn)象
(2)解決了OOV現(xiàn)象,即生成的詞除了包含上下文已有的詞以外,也可以生成上下文中沒有的詞。
3.1 基線 Seq2Seq+Attention 模型
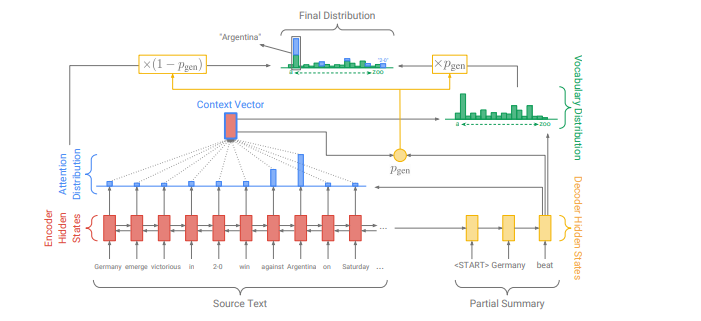
這里是一個標準的attention計算。encoder的第i個hidden_state,是t時刻decoder的狀態(tài),是學習參數(shù)。attention計算一般有兩種方式,第一種方式是先經(jīng)過decoder單元(LSTM或者GRU,這里使用的LSTM)之后,再使用其輸出來計算attention。第二種則表示使用上一個單元(t-1時刻)的hidden_state先計算attention,得到context vector,將其作為t時刻單元的輸入。該模型使用的是第二種方式。
(1)
(2)
(3)
利用LSTM單元的輸出和context vector()的contact來計算詞的概率,并定義其損失函數(shù)。
(4)
(5)
(6)
(7)
3.2 Pointer-generator network 網(wǎng)絡
增加,區(qū)間范圍[0,1],表示decoder網(wǎng)絡生成一個vocab中的詞,還是從原文本中抽取一個詞的概率。當>=0.5時,=0,當其小于0.5時,=0。的計算公式如下所示:
(8)
(9)
3.3 Coverage mechanism:
實現(xiàn)方式,在計算t時刻的attention,即context vector 時,不僅僅考慮t時刻的hidden_state, 同時考慮已經(jīng)生成的內(nèi)容,這里通過0到t-1刻的attention的權重來體現(xiàn),權重比較大的詞表示已經(jīng)考慮過了,在后面的計算過程中減少其比重。計算公式:(10)
同時,式(1)中計算權重矩陣的公式也做了相應修改,如式(11)。
(11)
定義了coverage loss,這在實驗部分被證明是非常有必要的。關于這個損失函數(shù)的定義,取得是當前詞前面所有時刻的累計權重和當前時刻權重的最小值,這種方式綜合考慮到一個詞在文中多次出現(xiàn)和一個詞在當前狀態(tài)最大概率出現(xiàn)的的情況,既不完全偏向于多次出現(xiàn)的詞,同時也不過分考慮當前狀態(tài)最大概率出現(xiàn)的詞。
(12)
整體的損失函數(shù):
(13)
4 SeqGAN 模型介紹
核心思想是將GAN與強化學習的Policy Gradient算法結(jié)合到一起,這也正是D2IA-GAN在處理Generator的優(yōu)化時使用的技巧。
SeqGAN的出發(fā)點也是意識到了標準的GAN在處理像序列這種離散數(shù)據(jù)時會遇到的困難,主要體現(xiàn)在兩個方面:Generator難以傳遞梯度更新,Discriminator難以評估非完整序列。
對于前者,給出的解決方案相對比較熟悉,即把整個GAN看作一個強化學習系統(tǒng),用Policy Gradient算法更新Generator的參數(shù);對于后者,則借鑒了蒙特卡洛樹搜索(Monte Carlo tree search,MCTS)的思想,對任意時刻的非完整序列都可以進行評估。
對于強化學習和對抗神經(jīng)網(wǎng)絡在文本生成領域的結(jié)合,可以做個簡單的類比,從而可以加深對SeqGAN的理解。我們可以將文本生成過程中的生成器,理解成強化學習的策略器,每次選擇生成詞可以看作是強化學習過程中的動作選擇,判別器可以看作是強化學習的環(huán)境,其作用是對每次的動作給出相應的反饋。
4.1 SeqGAN 數(shù)學推導過程
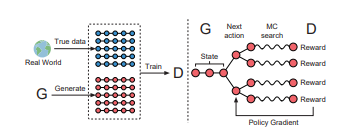
根據(jù)強化學習相關知識,我們可以定義SeqGAN的的回報函數(shù)。優(yōu)化過程就是最大化強化學習的回報函數(shù)
(1)
由于判別器只能評價一個完成序列,因此可以計算前T-1個序列已經(jīng)生成的情況下,最后一個動作的Q值。
(2)
但是在強化學習的過程中不僅需要的是最后一個動作的Q值,而且需要任意時刻的Q值,因此,對于一個任意時刻的Q值,可以通過MC采樣的方式來進行近似計算,MC會采樣多個完整的序列,通過計算采樣后的完整序列回報的均值,當作當前時刻的Q值。
(3)
判別器的訓練,判別器的訓練目標是給出真實樣本和生成樣本的分數(shù),目標是最大化真實樣本的分數(shù),最小化生成樣本的分數(shù),下面是其損失函數(shù)的公式。
(4)
將(1)中的公式展開成按照時間累計求和的形式,可以得到下面的的公式
(5)
將任意時刻的期望回報用累計回報近似代替,可以得到下面公式。
(6)
利用反向傳播更新生成器的參數(shù)。
(7)
4.2 SeqGAN缺點
SeqGAN模型主要耗時操作是在MC的采樣過程,因為對于每一個時刻的累計回報都是通過采樣的方式的進行估算近似,當需要生成的序列比較長時,采樣需要的次數(shù)會急速的增長。同時當采樣次數(shù)比較少的情況下,近似估計的結(jié)果會偏差較大。
5 GPT-2 預訓練模型
bert 模型雖然在文本分類領域取得了驚人的效果,但是考慮到BERT是一個雙向語言模型,充分利用了上下文信息,所以在文本分類領域效果優(yōu)于GPT無可厚非,但是BERT模型也正是因為雙向的語言模型的特點,導致其在文本生成領域表現(xiàn)不佳。由于文本生成本身的特性,每次生成時候,只能看見上文,并不能看見下文,所以并不適合雙向的語言模型。GPT-2在文本生成領域的驚人表現(xiàn),讓我們不禁想要去探索,是因為什么使得GPT-2在本文生成領域表現(xiàn)如此強力,下面我們對比BERT模型來詳細介紹GPT-2。
從結(jié)構(gòu)上來說GPT-2 是使用「transformer 解碼器模塊」構(gòu)建的,而 BERT 則是通過「transformer 編碼器」模塊構(gòu)建的。二者一個很關鍵的不同之處在于:GPT-2 就像傳統(tǒng)的語言模型一樣,一次只輸出一個單詞(token)。這種模型之所以效果好是因為在每個新單詞產(chǎn)生后,該單詞就被添加在之前生成的單詞序列后面,這個序列會成為模型下一步的新輸入。這種機制叫做自回歸(auto-regression),同時也是令 GPT-2模型效果拔群的重要思想。
GPT-2,以及一些諸如 TransformerXL 和 XLNet 等后續(xù)出現(xiàn)的模型,本質(zhì)上都是自回歸模型,而 BERT 則不然。這就是一個權衡的問題了。雖然沒有使用自回歸機制,但 BERT 獲得了結(jié)合單詞前后的上下文信息的能力,從而取得了更好的效果。XLNet 使用了自回歸,并且引入了一種能夠同時兼顧前后的上下文信息的方法。
5.1 帶掩碼的注意力模型
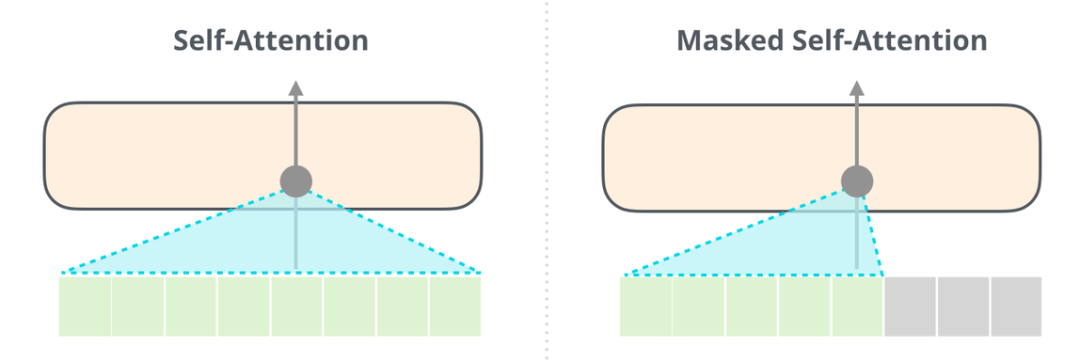
能夠清楚地區(qū)分 BERT 使用的自注意力(self-attention)模塊和 GPT-2 使用的帶掩碼的自注意力(masked self-attention)模塊很重要。普通的自注意力模塊允許一個位置看到它右側(cè)單詞的信息(如下左圖),而帶掩碼的自注意力模塊則不允許這么做,他會將該詞后面的詞通過掩碼的方式將其屏蔽掉。
利用掩碼方式一個最大的優(yōu)勢在于,我們后續(xù)的注意力機制模塊,可以通過矩陣運算的方式直接進行,大大優(yōu)化了計算效率。
5.2 只包含解碼器的模塊
這些解碼器模塊和 transformer 原始論文中的解碼器模塊相比,并沒有很大的差別,僅僅只是將第二層的自注意力層給去掉,原本的自注意力層中,會把encoder層的輸出和上一層的結(jié)果進行注意力計算。但是GPT-2使用的是循環(huán)結(jié)構(gòu),每次把新生成的詞添加到原有的序列后面,然后再重新參與計算。通過這種方式,將encoder給去掉了。這樣OpenAI 的 GPT-2 模型就用了這種只包含編碼器(decoder-only)的模塊。
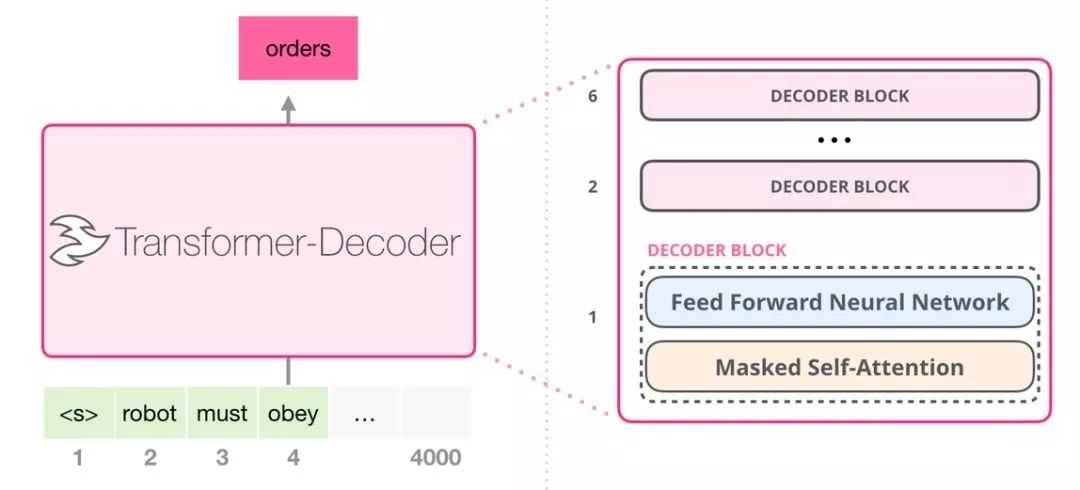
5.3 GPT-2 內(nèi)部生成機制
給定GPT-2一點提示,然后GPT-2根據(jù)提示開始進行生成,每次只能生成一個單詞,然后將生成的單詞加入到提示中,層層開始處理,最終生成一個完整的序列。但是會存在一個問題,每次選擇第一個單詞,這樣的生成序列變成唯一了,只有選擇第二個或者第三個推薦詞以后,才能跳出唯一的現(xiàn)象,因此GPT-2有一個top-k參數(shù),模型會從概率前k大的單詞中選擇下一個單詞。
6 如何判斷生成句子是否符合正常語句表達
在我們生成的句子中,總是存在一些句子看起來通順,但是實際并沒有意義,或者存在邏輯錯誤。比如“北京是新中國的首都”,這句話是沒有問題的,但是我們將北京替換成南京,顯然這樣的句子并沒有語法錯誤,但是如果生成的句子是這樣的話,很可能會被請去喝茶。
句子符合正常語句表達,對于機器而言我們應該怎么評價呢,顯然,如果我們注意到新中國、首都這兩個詞,那么我們能夠很快判斷出現(xiàn)北京明顯比南京更加常見。按照這個思想,可以把這個問題換個角度來描述,我們是希望在前面詞出現(xiàn)的條件下,后續(xù)詞出現(xiàn)的概率應該最大,并且后面詞出現(xiàn)的前提下,前面詞出現(xiàn)的概率也應該最大。
6.1 模型損失函數(shù)
對于一個給定的序列Y{}我們可以定義其損失為:
其中對于Loss函數(shù)而言是一個超參數(shù),我們可以通過調(diào)整其來達到一個更好的效果,通常而言,根據(jù)總體序列的長度來選擇一個合理的。
6.2 判別模型的選擇
當序列比較長時,推薦使用Transform結(jié)構(gòu)模型,考慮到長文本需要預測的次數(shù)比較多,Transform比起RNN結(jié)構(gòu)更加有利于并行運算,速度會更快。
-
模型
+關注
關注
1文章
3517瀏覽量
50383 -
文本
+關注
關注
0文章
119瀏覽量
17452 -
強化學習
+關注
關注
4文章
269瀏覽量
11596
原文標題:AI也能精彩表達:幾種經(jīng)典文本生成模型一覽
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
關于鴻蒙App上架中“AI文本生成模塊的資質(zhì)證明文件”的情況說明
NVIDIA RTX 5880 Ada顯卡部署DeepSeek-R1模型實測報告

飛凌RK3588開發(fā)板上部署DeepSeek-R1大模型的完整指南(一)

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術解讀
【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
一些常見的動態(tài)電路

分享一些常見的電路





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論