") FPGA上的HBM性能實測結(jié)果分析
FPGA上的HBM性能實測結(jié)果分析
本文是第一篇詳細介紹HBM在FPGA上性能實測結(jié)果的頂會論文(FCCM2020,Shuhai: Benchmarking High Bandwidth Memory on FPGAs),文章,目前采用Chiplet技術(shù)的光口速率可以達到驚人的2Tbps。而本文介紹的同樣采用Chiplet技術(shù)的HBM,訪存帶寬高達425GB/s,那么采用這樣光口和緩存的網(wǎng)卡會是一種怎樣的高性能呢?對NIC或者Switch內(nèi)部的總線帶寬又有怎樣的要求呢?我們期待著能夠用2Tbps接口和HBM技術(shù)的NIC或者Switch的出現(xiàn)。
隨著高帶寬內(nèi)存(HBM)的發(fā)展,F(xiàn)PGA正變得越來越強大,HBM 給了FPGA 更多能力去緩解再一些應用中遇到的內(nèi)存帶寬瓶頸和處理更多樣的應用。然而,HBM 的性能表現(xiàn)我們了解地還不是特別精準,尤其是在 FPGA 平臺上。這篇文章我們將會在HBM 的說明書和它的實際表現(xiàn)之間建立起橋梁。我們使用的是一款非常棒的 FPGA,Xilinx ALveo U280,有一個兩層的HBM 子系統(tǒng)。在最后,我們提出了豎亥,一款讓我們測試出所有HBM 基礎性能的基準測試工具。基于FPGA 的測試平臺相較于CPU/GPU 平臺來說會更位準確,因為噪聲會更少,后者有著復雜的控制邏輯和緩存層次。我們觀察到 1)HBM 提供高達425 GB/s 的內(nèi)存帶寬,2)如何使用HBM 會給性能表現(xiàn)帶來巨大的影響,這也印證了揭開 HBM 特性的重要性,這可以讓我們選擇最佳的使用方式。作為對照,我們同樣將豎亥應用在DDR4上來展現(xiàn)DDR4 和HBM 的不同。豎亥可以被輕松部署在其他FPGA 板卡上,我們會將豎亥開源,造福社會。
1. 引言
現(xiàn)代計算機系統(tǒng)的計算能力隨著 CMOS技術(shù)的發(fā)展持續(xù)提升,典型的例子就是應用更多的核心在同樣的區(qū)域中或者增加額外的功能到核里面去(SIMD、AVX、SGX等)。與此相反,DRAM內(nèi)存的帶寬發(fā)展地十分緩慢。因此處理器和內(nèi)存之間的差距越來越大,并且隨著多核設計而變得更嚴重。HBM被提出用于提供高得多的帶寬能力。HBM2 能提供高達900 GB/s 的內(nèi)存帶寬。
與同一代GPU相比,F(xiàn)PGA 帶寬能力要低幾個數(shù)量級,傳統(tǒng)的FPGA有兩個DRAM內(nèi)存通道,每個提供19.2GB/s的內(nèi)存帶寬。因此FPGA不能完成很多對帶寬能力要求高的應用。因此Xilinx將HBM引用到新一代FPGA中去。HBM有潛力成為改變目前局面的特性。
盡管有著潛力去解決處理器和內(nèi)存間的差距,應用HBM到FPGA上還是有很多阻礙。HBM的特性不為人們所了解。盡管和DRAM有著相同的die,HBM的特性和前者完全不同。Xilinx的HBM子系統(tǒng)也引入了很多新特性例如switch。Switch的特性同樣不為我們所了解。這些東西都會阻礙開發(fā)者利用FPGA上的HBM。
在最后我們提出了豎亥,一個可以用來測試HBM特性的基準測試工具。據(jù)我們所致,豎亥是第一個系統(tǒng)性測試FPGA上的HBM的測試平臺。我們通過以下四個方面來證明豎亥的用處。
F1:HBM提供巨大的內(nèi)存帶寬:在我們的測試平臺上,HBM提供高達425 GB/s的內(nèi)存帶寬,比傳統(tǒng)使用兩個DDR4來說要高一個數(shù)量級。雖然只有GPU的一半,但是這對FPGA來說也是一個巨大的進步。
F2:地址映射策略很重要:不同的地址映射策略會帶來數(shù)量級的速度差異。這也意味著要根據(jù)應用的不同選取不同的映射策略。
F3:HBM延時要比DDR4高很多:HBM和FPGA的聯(lián)系是通過transceiver,帶來了額外的糾錯碼和串行并行轉(zhuǎn)換的開銷。豎亥測試出在頁命中情況下,HBM的延時是122.2ns,而DDR4僅為73.3ns。
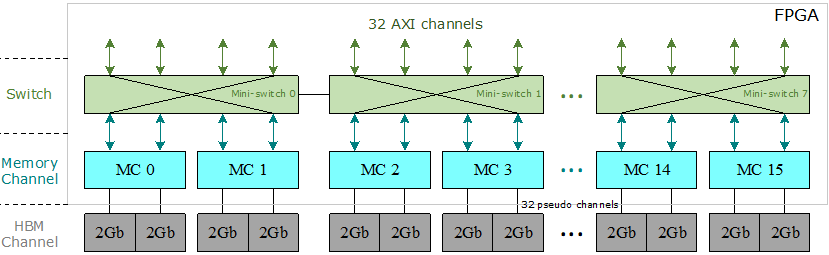
圖1:Xilinx HBM子系統(tǒng)架構(gòu)
F4:FPGA可以更精準地測量:我們將豎亥直接連接HBM模塊,使得更容易解釋測量結(jié)果,而使用CPU/GPU會引出更多的噪聲,例如緩存的影響。因此我們主張豎亥是一個更好的選項來測量內(nèi)存。
2. 背景
HBM芯片采用了最新的IC封裝技術(shù),例如直通硅通孔(TSV),堆疊式DRAM和2.5D封裝[13],[18]。HBM的基本結(jié)構(gòu)由底部的基本邏輯芯片和頂部堆疊的4或8核心DRAM芯片組成。所有管芯均通過TSV互連。Xilinx在FPGA內(nèi)部集成了兩個HBM堆棧和一個HBM控制器。每個HBM堆棧都分為八個獨立的存儲通道,其中每個存儲通道又分為兩個64位偽通道。如圖1所示,只允許偽通道訪問與其關(guān)聯(lián)的HBM通道,該通道具有自己的內(nèi)存地址區(qū)域。Xilinx的HBM子系統(tǒng)具有16個存儲通道,32個偽通道和32個HBM通道。
在16個存儲通道的頂部,有32個與用戶邏輯交互的AXI通道。每個AXI通道均遵循標準AXI3協(xié)議[44],以向FPGA程序員提供經(jīng)過驗證的標準化接口。每個AXI通道都與一個HBM通道(或偽通道)相關(guān)聯(lián),因此每個AXI通道僅被允許訪問其自己的內(nèi)存區(qū)域。為了使每個AXI通道都能訪問整個HBM空間,Xilinx引入了在32個AXI通道和32個偽通道之間的switch[41],[44]。但是,由于其巨大的資源消耗,該switch尚未完全實現(xiàn)。相反,Xilinx提供了八個小型switch,其中每個小型switch為四個AXI通道及其相關(guān)的偽通道提供服務,并且在每個AXI通道都可以訪問同一小型switch中的任何偽通道,該小型switch被完全實現(xiàn)。具有相同的延遲和吞吐量。此外,兩個相鄰的微型switch之間有兩個雙向連接,用于全局尋址。
3. 豎亥的基本架構(gòu)
在本節(jié)中,我們介紹設計方法,然后是豎亥的軟件和硬件組件。
A.設計方法論
在本小節(jié)中,我們總結(jié)了兩個具體挑戰(zhàn)C1和C2,然后介紹豎亥如何來應對這兩個挑戰(zhàn)。
C1:高層洞察力。在某種意義上,使我們的基準測試框架對FPGA程序員有意義是至關(guān)重要的,因為我們應該輕松地向FPGA程序員提供更詳盡的解釋,而不是僅僅令人費解的內(nèi)存時序參數(shù)(例如行預充電時間TRP),這可用于改善FPGA上HBM存儲器的使用。
C2:易于使用。
在對FPGA進行基準測試時,可能需要做一些小改動才能重新配置FPGA,很難實現(xiàn)易用性。因此,我們打算最大程度地減少重新配置的工作,以使在基準測試任務之間無需重新配置FPGA。換句話說,我們的基準測試框架應該允許我們將一個FPGA實例用于大量的基準測試任務,而不僅僅是一個任務。
我們的方法。我們使用豎亥應對上述兩個挑戰(zhàn)。為了解決第一個挑戰(zhàn)C1,豎亥允許直接分析FPGA程序員使用的典型存儲器訪問模式的性能特征,并提供整體性能的詳盡說明。為了解決第二個挑戰(zhàn),即C2,豎亥使用基準電路的運行時參數(shù)化功能來覆蓋各種基準測試任務,而無需重新配置FPGA。通過基準測試中實現(xiàn)的訪問模式,我們可以揭示FPGA上HBM和DDR4的基本特性。
豎亥采用基于兩個組件的軟件-硬件協(xié)同設計方法:軟件組件(III-B小節(jié))和硬件組件(III-C小節(jié))。軟件組件的主要作用是在運行時參數(shù)方面為FPGA程序員提供靈活性。利用這些運行時參數(shù),在對HBM和DDR4進行基準測試時,我們無需頻繁地重新配置FPGA。硬件組件的主要作用是保證性能。更準確地說,豎亥應該能夠在FPGA上展現(xiàn)HBM存儲器在最大可實現(xiàn)的存儲器帶寬和最小可實現(xiàn)的延遲方面的性能潛力。為此,基準測試電路本身不能在任何時候成為瓶頸。
B.軟件組件
豎亥的軟件組件旨在提供用戶友好的接口,以便FPGA開發(fā)人員可以輕松地使用豎亥來對HBM存儲器進行基準測試并獲得相關(guān)的性能特征。為此,我們介紹了一種廣泛用于FPGA編程的存儲器訪問模式:重復順序遍歷(RST),如圖2所示。

圖2:在豎亥中使用的內(nèi)存訪問模式
RST模式遍歷一個存儲區(qū)域,一個數(shù)據(jù)陣列按順序存儲數(shù)據(jù)元素。RST重復掃描起始地址為A的大小為W的存儲區(qū)域,并且每次讀取步長為S字節(jié)的B個字節(jié),其中B和S為2的冪。在我們測試的FPGA上,訪問大小B應為由于HBM / DDR4存儲器應用程序數(shù)據(jù)寬度的限制,對于HBM(或DDR4),其值不得小于32(或64)。步幅S不應大于工作集大小W。參數(shù)匯總在表I中。我們計算出RST發(fā)出的第i個存儲器讀/寫事務的地址T [i],如公式1所示。可以使用簡單的算法來實現(xiàn)計算,從而減少了FPGA資源的數(shù)量,并可能實現(xiàn)更高的頻率。盡管這公式非常簡單,但是它能幫助我們了解FPGA上的HBM和DDR。
表格1:運行時參數(shù)總結(jié)

T[i] = A + (i × S)%W 公式(1)
C.硬件組件
豎亥的硬件組件由一個PCIe模塊,M個延遲模塊,一個參數(shù)模塊和M個引擎模塊組成,如圖3所示。在下面,我們討論每個模塊的實現(xiàn)細節(jié)。
1)引擎模塊:我們直接將實例化的引擎模塊連接到AXI通道,以便引擎模塊直接服務于AXI接口,例如AXI3和AXI4 [2],[42],它由基礎內(nèi)存IP核提供,HBM和DDR4。AXI接口包含五個不同的通道:讀取地址(RA),讀取數(shù)據(jù)(RD),寫入地址(WA),寫入數(shù)據(jù)(WD)和寫入響應(WR)[42]。此外,引擎模塊的輸入時鐘正是來自相關(guān)AXI通道的時鐘。例如,在對HBM進行基準測試時,引擎模塊的時鐘頻率為450MHz,因為其AXI通道最多允許450MHz。使用同一時鐘有兩個好處。首先,跨不同時鐘區(qū)域所需的FIFO不會引入額外的噪聲,例如更長的延遲。其次,引擎模塊能夠容納其關(guān)聯(lián)的AXI通道,不會導致內(nèi)存帶寬容量的低估。
用Verilog編寫的引擎模塊由兩個獨立的模塊組成:寫入模塊和讀取模塊。寫模塊為三個與寫相關(guān)的通道WA,WD和WR提供服務,而讀模塊為兩個與讀相關(guān)的通道RA和RD提供服務。
寫模塊。該模塊包含一個狀態(tài)機,該狀態(tài)機可以從CPU執(zhí)行內(nèi)存寫入任務。該任務具有初始地址A,寫入數(shù)N,訪問大小B,步幅S和工作集大小W。公式1中指定了每個存儲器寫事務的地址。該模塊還探測WR通道,以驗證動態(tài)存儲器寫的工作已成功完成。
讀取模塊。讀取模塊包含一個狀態(tài)機,該狀態(tài)機可以從CPU中執(zhí)行內(nèi)存讀取任務。該任務具有初始地址A,讀取事務數(shù)N,訪問大小B,幅度S和工作集大小W。與寫入模塊不同,寫入模塊僅測量可實現(xiàn)的吞吐量,讀取模塊還測量每個模塊的延遲。當測試速度時,該模塊會一直嘗試滿足RA和RD。
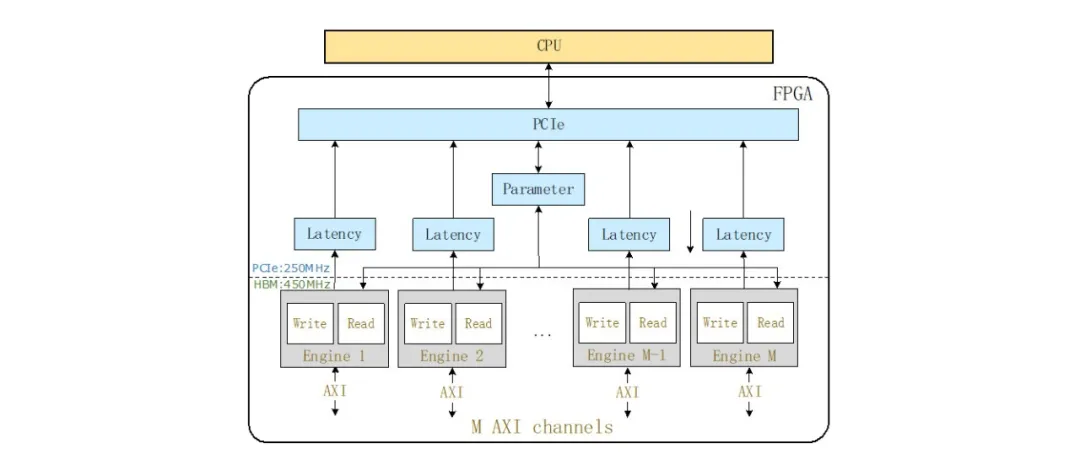
圖3:總硬件架構(gòu),支持M個硬件引擎同時運行,在我們的實驗中,M是32
2)PCIe模塊:我們直接在時鐘頻率為250MHz的PCIe模塊中部署了用于PCI Express(PCIe)IP內(nèi)核的Xilinx DMA/橋接子系統(tǒng)。我們的PCIe驅(qū)動程序?qū)PGA上的運行時參數(shù)映射給用戶,以便用戶能夠使用軟件代碼直接與FPGA交互。這些運行時參數(shù)決定存儲在參數(shù)模塊中的控制和狀態(tài)寄存器。
3)參數(shù)模塊:參數(shù)模塊維護運行時參數(shù)并通過PCIe模塊與主機CPU通信,從CPU接收運行時參數(shù)(例如S),并將吞吐量數(shù)據(jù)返回給CPU。
收到運行時參數(shù)后,我們將使用它們來配置M個引擎模塊,每個引擎模塊都需要兩個256位控制寄存器來存儲其運行時參數(shù):每個引擎模塊中的一個寄存器用于讀取模塊,另一個寄存器用于寫入模塊。在256位寄存器中,W占用32位,S占用32位,N占用64位,B占用32位,而A占用64位。剩余的32位保留供將來使用。設置完所有引擎之后,用戶可以觸發(fā)啟動信號以開始吞吐量/延遲測試。
參數(shù)模塊還負責將吞吐量編號(64位狀態(tài)寄存器)返回給CPU。每個引擎模塊專用一個狀態(tài)寄存器。
4)延遲模塊:我們?yōu)閷S糜贏XI通道的每個引擎模塊實例化一個延遲模塊。等待時間模塊存儲大小為1024的等待時間列表,其中等待時間列表由關(guān)聯(lián)的引擎模塊寫入并由CPU讀取。它的大小是一個綜合參數(shù)。每個包含一個8位寄存器的等待時間,指從讀取操作的發(fā)出到數(shù)據(jù)從存儲控制器到達操作的延遲。
4. 實驗設置
在本節(jié)中,我們介紹經(jīng)過測試的硬件平臺(第IV-A小節(jié))和探討的地址映射策略(第IV-B小節(jié)),然后是硬件資源消耗(第IV-C小節(jié))和我們的基準測試方法(IV-D小節(jié))。
A.硬件平臺
我們在Xilinx的Alevo U280 [43]上進行實驗,該實驗具有兩個總?cè)萘繛?GB的HBM堆棧和兩個總?cè)萘繛?2GB的DDR4內(nèi)存通道。理論HBM內(nèi)存帶寬可以達到450 GB / s(450M * 32 * 32B / s),而DDR4內(nèi)存理論帶寬可以達到38.4GB / s(300M * 2 * 64B / s)。
B.地址映射政策
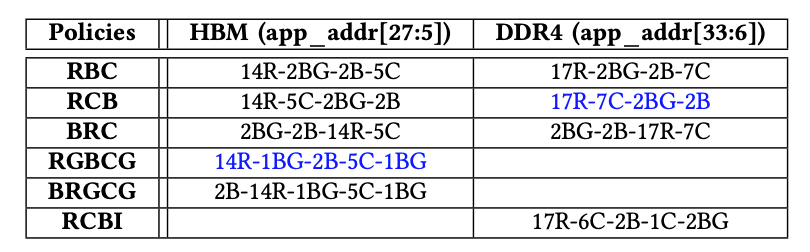
可以使用多種策略將應用程序地址映射到內(nèi)存地址,其中不同的地址位映射到存儲塊,行或列地址。選擇正確的映射策略對于最大化整體內(nèi)存吞吐量至關(guān)重要。表II中匯總了為HBM和DDR4啟用的策略,其中“ xR”表示x位用于行地址,“xBG”表示x位用于存儲體組地址,“ xB”表示x位用于存儲體地址,“ xC”表示x位用于列地址。HBM和DDR4的默認策略分別為“RGBCG”和“ RCB”。“-”代表地址串聯(lián)。如果沒有特別指定,我們始終對HBM和DDR4使用默認的內(nèi)存地址映射策略。例如,HBM的默認策略是RGBCG。
表格2:地址映射策略,藍色的是默認
C.資源消耗明細
在本小節(jié)中,我們將敘述7種資源的消耗。
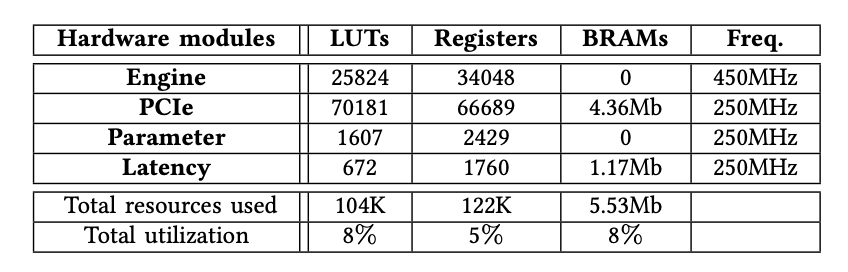
對HBM進行基準測試時,表III列出了每個實例化模塊的確切FPGA資源消耗。我們觀察到,豎亥只需要少量的資源來實例化32個引擎模塊以及PCIe模塊等其他組件,總資源利用率不到8%。
表格3:資源消耗量
D.測試方法
我們旨在揭示豎亥使用下Xilinx FPGA上的HBM堆棧的底層細節(jié)。作為衡量標準,我們在必要時還分析了同一FPGA板U280上DDR4的性能特征[43]。當我們對HBM通道進行基準測試時,我們將HBM和DDR4的性能特征進行了比較(在第五節(jié)中)。我們認為,針對HBM通道獲得的數(shù)字可以推廣到其他計算設備,例如具有HBM內(nèi)存的CPU或GPU。在HBM內(nèi)存控制器內(nèi)部對switch進行基準測試時,由于DDR4內(nèi)存控制器不包含,因此我們不與DDR進行比較(第六節(jié))。
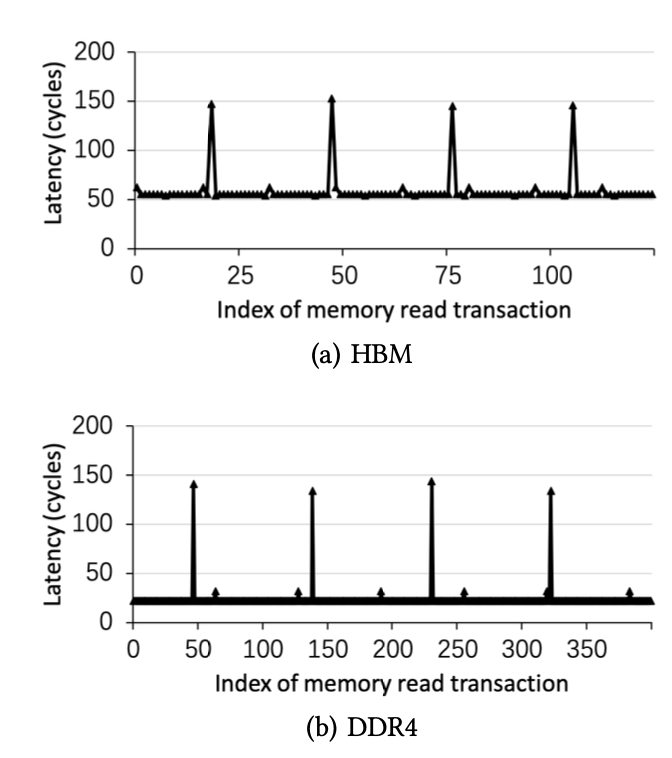
圖4:刷新指令帶來更高的訪問延時周期性地出現(xiàn)在HBM和DDR4中
5. 對HBM通道進行基準測試
在本節(jié)中,我們旨在揭示Xilinx FPGA上使用Shuhai的HBM通道的詳細信息。
A.刷新間隔的影響
當存儲通道正在運行時,應重復刷新存儲單元,以使每個存儲單元中的信息都不會丟失。在刷新周期中,不允許正常的內(nèi)存讀取和寫入事務訪問內(nèi)存。我們觀察到,經(jīng)歷內(nèi)存刷新周期的內(nèi)存事務比允許直接訪問內(nèi)存芯片的普通內(nèi)存讀/寫事務的等待時間長得多。因此,我們能夠通過利用正常和非刷新內(nèi)存事務之間的內(nèi)存延遲差異來大致確定刷新間隔。特別地,我們利用豎亥來測量串行存儲器讀取操作的延遲。圖4說明了B = 32,S = 64,W = 0x1000000和N = 20000的情況。我們有兩個觀察結(jié)果。首先,對于HBM和DDR4,與刷新命令一致的存儲器讀取事務具有顯著更長的延遲,這表明需要發(fā)出足夠多的動態(tài)存儲器事務來分攤刷新命令的負面影響。其次,對于HBM和DDR4,都定期計劃刷新命令,任何兩個連續(xù)刷新命令之間的間隔大致相同。
B.內(nèi)存訪問延遲
為了準確地測量內(nèi)存延遲,當內(nèi)存控制器處于“空閑”狀態(tài)時,即內(nèi)存控制器中不存在其他未決內(nèi)存事務的情況下,我們利用豎亥來測量連續(xù)內(nèi)存讀取事務的延遲。以最小的延遲將請求的數(shù)據(jù)返回到讀取的事務。我們旨在確定三種不同狀態(tài)下的延遲:page hit、page miss、page closed。
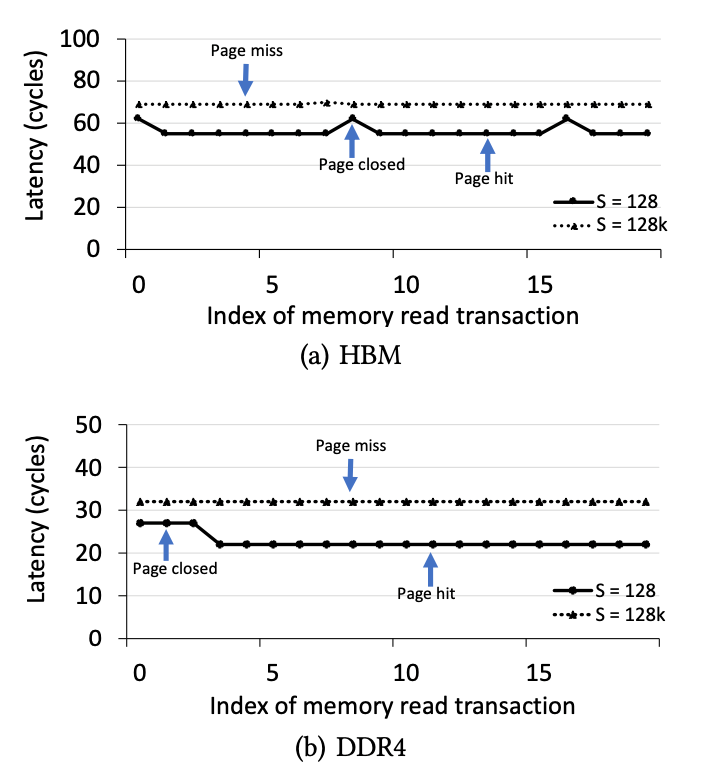
圖5.三種狀態(tài)(page hit、page closed、page miss)的延時
PageHit(頁面命中):當內(nèi)存事務訪問其存儲區(qū)中打開的行時,將發(fā)生“頁面命中”狀態(tài),因此在訪問列之前不需要“預充電”和“激活”命令,從而將等待時間降至最低。
PageClosed(頁面關(guān)閉):當內(nèi)存事務訪問其對應存儲體已關(guān)閉的行時,將發(fā)生“頁面關(guān)閉”狀態(tài),因此在訪問列之前需要行Activate命令。
PageMiss(頁面丟失):當內(nèi)存事務訪問的行與存儲區(qū)中的活動行不匹配時,將發(fā)生“頁面丟失”狀態(tài),因此在訪問列之前發(fā)出了一個Precharge命令和一個Activate命令,這導致了最大的延遲。
我們準確測量B = 32,W = 0x1000000,N = 2000且S發(fā)生變化的情況下的等待時間數(shù)。直觀地講,小S導致?lián)糁型豁撁娴目赡苄院芨撸骃可能導致?lián)糁型豁撁驽e過頁面。在本實驗中,我們使用兩個S值:128和128K。
我們使用情況S = 128來確定頁面命中和頁面關(guān)閉事務的等待時間。S = 128小于頁面大小,因此大多數(shù)讀取事務將訪問一個打開的頁面,如圖5所示。其余點說明頁面關(guān)閉事務的等待時間,因為小S導致大量讀取特定內(nèi)存區(qū)域中的事務。我們使用S = 128K的情況來確定頁面丟失事務的等待時間。S = 128K導致HBM和DDR4的每個內(nèi)存事務發(fā)生頁面丟失。
總結(jié):我們在表IV中總結(jié)了HBM和DDR的延遲。我們有兩個觀察結(jié)果。首先,在相同的類別(如頁面點擊)下,HBM上的內(nèi)存訪問延遲比DDR4上高約50納秒。這意味著當在FPGA上運行對延遲敏感的應用程序時,HBM可能有劣勢。其次,延遲數(shù)是準確的,證明了豎亥的效率。
表格4.HBM和DDR4的內(nèi)存訪問,HBM的延時要高于DDR4
C.地址映射策略的效果
在本小節(jié)中,我們研究了不同內(nèi)存地址映射策略對可實現(xiàn)吞吐量的影響。特別地,在不同的映射策略下,我們使用步幅S和訪問大小B來測量內(nèi)存吞吐量,同時將工作集大小W(= 0x10000000)保持足夠大。圖6說明了HBM和DDR4的不同地址映射策略的吞吐量趨勢。我們有五個觀察到的現(xiàn)象。
首先,不同的地址映射策略會導致明顯的性能差異。例如,圖6a說明,當S為1024而B為32時,HBM的默認策略(RGBCG)幾乎比策略(BRC)快10倍,這說明為內(nèi)存應用程序選擇正確的地址映射策略的重要性。
其次,即使HBM和DDR4采用相同的地址映射策略,其吞吐量趨勢也大不相同,這證明了豎亥等基準平臺對評估不同的FPGA板或不同的存儲器的重要性。
第三,對于HBM和DDR4上的S和B的任何組合,默認策略始終會帶來最佳性能,這表明默認設置是合理的。
第四,較小的訪問大小導致較低的存儲器吞吐量,如圖6a,6e所示,這意味著FPGA程序員應增加空間局部性,以從HBM和DDR4獲得更高的存儲器吞吐量。
第五,大的S(> 8K)總是導致內(nèi)存帶寬利用率極低,這表明保持空間局部性極為重要。換句話說,不保留空間局部性的隨機內(nèi)存訪問將遇到低內(nèi)存吞吐量。
我們得出結(jié)論,選擇正確的地址映射策略對于優(yōu)化FPGA上的存儲器吞吐量至關(guān)重要。
D.儲存組的影響
在本小節(jié)中,我們研究了存儲組的影響,與DDR3相比,存儲組是DDR4的新功能。同時訪問多個存儲組有助于我們減輕DRAM時序限制的負面影響,而這種限制在幾代DRAM上并未得到改善。通過訪問多個存儲組可能會獲得更高的內(nèi)存吞吐量。因此,我們使用引擎模塊來驗證儲存組的效果(圖6)。我們有兩個觀察到的結(jié)果。
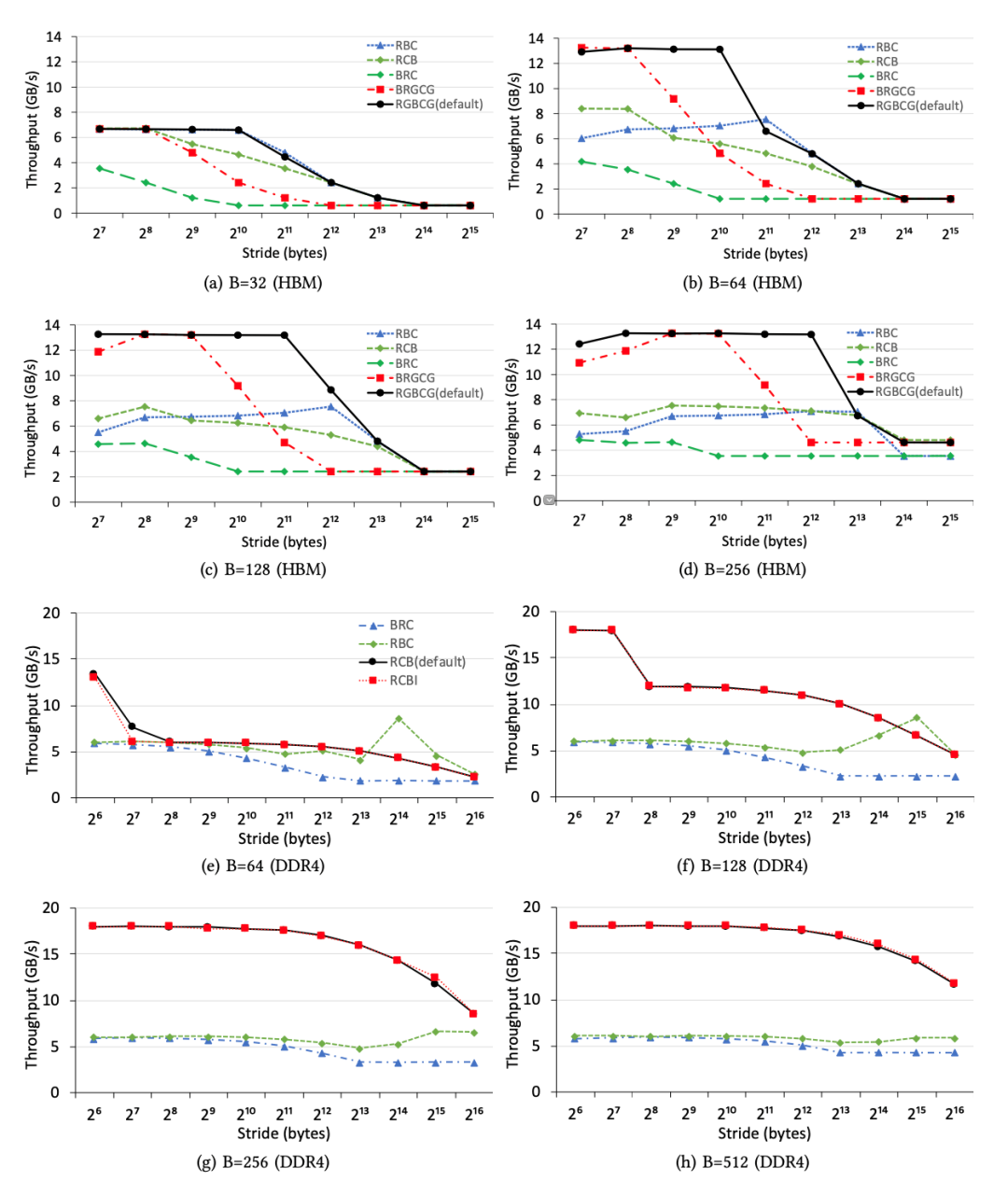
圖6.在所有地址映射策略下,具有不同訪問大小和跨度的HBM通道和DDR4通道之間的內(nèi)存吞吐量比較。在本實驗中,我們使用AXI通道0訪問其關(guān)聯(lián)的HBM通道0,以從單個HBM通道獲得最佳性能。我們使用DDR4通道0獲得DDR4吞吐量數(shù)字。我們觀察到,不同的地址映射策略會導致性能最高提高一個數(shù)量級,并且就吞吐量趨勢而言,HBM的性能特征與DDR4的性能特征不同。
首先,如圖6a,6b,6c,6d所示,使用默認地址映射策略,HBM允許使用較大步幅,同時仍保持高吞吐量。根本原因是,即使由于大的S而沒有充分利用每個行緩沖區(qū),存儲組級并行性也能夠使我們飽和利用內(nèi)存帶寬。
其次,在某些映射策略下,純順序讀取并不總是導致最高吞吐量。圖6b,6c說明,當S從128增加到2048時,較大的S在策略“ RBC”下可以實現(xiàn)較高的內(nèi)存吞吐量,因為較大的S允許同時訪問更多激活的存儲組,而較小的S可能導致僅一個活動的儲存組響應用戶的存儲請求。
我們得出結(jié)論,在HBM和DDR4下利用儲存組級并行性來實現(xiàn)高內(nèi)存吞吐量至關(guān)重要。
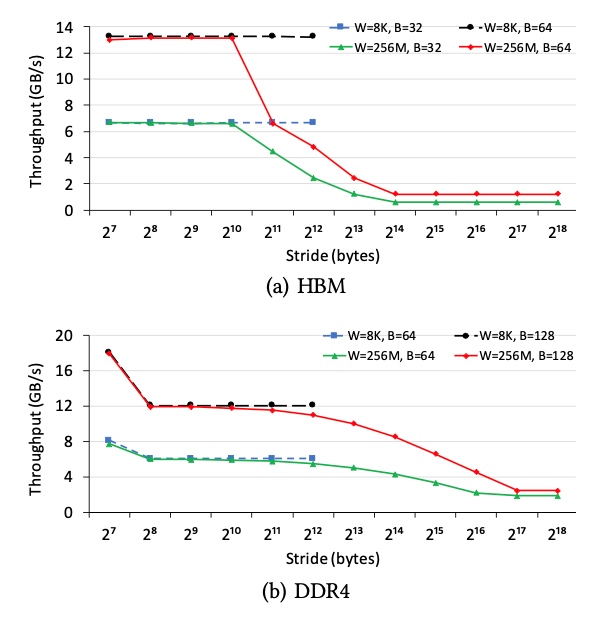
圖7.空間局部性的影響,局部性能緩解大的步幅S的影響
E.內(nèi)存訪問局部性的影響
在本小節(jié)中,我們研究了內(nèi)存訪問局部性對內(nèi)存吞吐量的影響。我們更改訪問大小B和步幅S,并將工作集大小W設置為兩個值:256M和8K。W = 256M的情況是指無法從任何內(nèi)存訪問局部性受益,而W = 8K的情況是指受益的情況。圖7說明了HBM和DDR4上不同參數(shù)設置的吞吐量。我們有兩個觀察結(jié)果。
首先,內(nèi)存訪問局部確實提高了大的S的情況下的內(nèi)存吞吐量。例如,在HBM上,(B = 32,W = 8K和S = 4K)情況下速度為6.7 GB / s,而(B = 32,W= 256M和S = 4K)僅為2.4 GB / s,這表明內(nèi)存訪問位置能夠消除較大步幅S的負面影響。其次,當S較小時,內(nèi)存訪問局部性不能增加內(nèi)存吞吐量。相比之下,由于片上緩存的帶寬比片外存儲器要高得多,因此內(nèi)存訪問局部性可以顯著提高現(xiàn)代CPU / GPU的總吞吐量[19]。
F.總內(nèi)存吞吐量
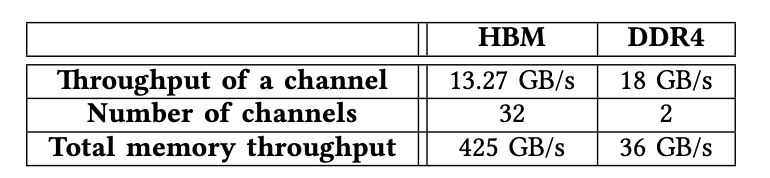
在本小節(jié)中,我們探討了HBM和DDR4的總可實現(xiàn)內(nèi)存吞吐量(表V)。當我們使用所有32條AXI通道進行測試時,經(jīng)過測試的FPGA卡U280上的HBM系統(tǒng)能夠提供高達425GB / s(13.27 GB / s * 32)的內(nèi)存吞吐量。
當我們同時訪問經(jīng)過測試的FPGA卡上的兩個DDR4通道時,內(nèi)存能夠提供高達36 GB / s(18 GB / s * 2)的內(nèi)存吞吐量。我們觀察到,HBM系統(tǒng)的內(nèi)存吞吐量是DDR4內(nèi)存的10倍,這表明增強了HBM的FPGA使我們能夠加速內(nèi)存密集型應用程序,而這通常是在GPU上進行加速的。
表格5.HBM和DDR4訪問速度對比,HBM要快一個數(shù)量級
6. 在HBM控制器中對switch進行基準測試
每個HBM堆棧將內(nèi)存地址空間劃分為16個獨立的偽通道,每個偽通道均與映射到特定地址范圍[41],[44]的AXI端口相關(guān)。因此,需要使用32×32開關(guān)來確保每個AXI端口都可以訪問整個地址。在HBM存儲器控制器中完全實現(xiàn)的32×32開關(guān)需要大量邏輯資源。因此,該switch僅被部分實現(xiàn),從而顯著減少了資源消耗,但實現(xiàn)了特定訪問模式的較低性能。我們在本節(jié)中的目標是揭示switch的性能特征。
A.AXI通道和HBM通道之間的性能
在本小節(jié)中,我們將在時延和吞吐量方面測試任何一個AXI通道和任何HBM通道之間的性能特征。在完全實現(xiàn)的switch中,從任何AXI通道訪問任何HBM通道的性能特征都應該大致相同。但是,在當前的實現(xiàn)中,相對距離可能起著重要的作用。
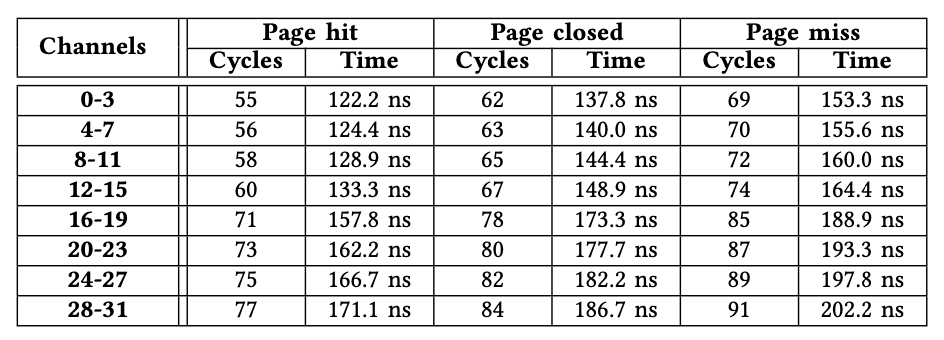
1)內(nèi)存延遲:由于篇幅所限,我們僅使用所有AXI通道(從0到31)到HBM通道0發(fā)出的內(nèi)存讀取事務來演示內(nèi)存訪問延遲。對其他HBM通道的訪問具有相似的性能特征。與V-B小節(jié)中的實驗設置相似,我們還使用引擎模塊來確定B = 32,W = 0x1000000,N = 2000以及S變化的情況下的準確等待時間。表VI說明了32個AXI通道之間的等待時間差異。我們有兩個觀察結(jié)果。
首先,延遲差異最多可以達到22個周期。例如,對于頁面命中事務,來自AXI通道31的訪問需要77個周期,而來自AXI通道0的訪問僅需要55個周期。其次,來自同一微型switch中任何AXI通道的訪問等待時間是相同的,這表明該微型switch已完全實現(xiàn)。例如,與AXI通道4-7關(guān)聯(lián)的微型switch對所有通道都顯示相同的內(nèi)存訪問延遲。我們得出結(jié)論,AXI通道應訪問其關(guān)聯(lián)的HBM通道或靠近它的HBM通道,以最大程度地減少延遲。
表格6.從32個AXI通道訪問HBM通道0的延時,距離越遠延時越高,可以達到22個周
2)內(nèi)存吞吐量:我們使用引擎模塊來測量從任何AXI通道(從0到31)到HBM通道0的內(nèi)存吞吐量,設置為B =64,W = 0x1000000,N = 200000,并且改變S。圖8說明了從每個小型switch中的AXI通道到HBM通道0的內(nèi)存吞吐量。我們觀察到AXI通道能夠?qū)崿F(xiàn)大致相同的內(nèi)存吞吐量,而不管它們的位置如何。
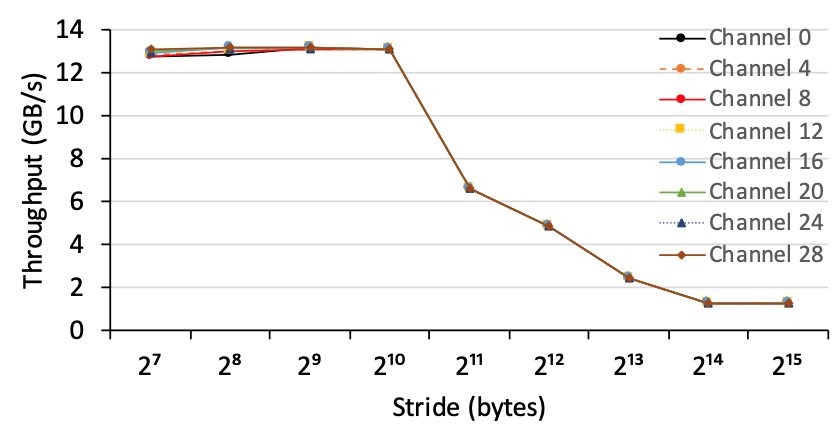
圖8,從八個AXI通道到HBM通道1的內(nèi)存吞吐量,其中每個AXI通道都來自小switch。每個AXI通道在訪問HBM通道1時具有大致相同的吞吐量,即使它們的訪問延遲可能明顯不同
B.AXI通道之間的干擾
在本小節(jié)中,我們通過使用不同數(shù)量(例如2、4和6)的AXI通道同時訪問同一HBM通道1,來檢查AXI通道之間的干擾影響。我們還改變了B的大小。表VII顯示了具有不同的B值和不同的AXI通道的吞吐量。空值表示該AXI通道未參與吞吐量測試。我們有兩個觀察結(jié)果。首先,當遠程AXI通道數(shù)量增加時,總吞吐量會略有下降,這表明交換機能夠以合理有效的方式為多個AXI通道提供內(nèi)存事務。其次,以循環(huán)方式安排微型switch中的兩個橫向連接和四個主機。以AXI通道4、5、8和9同時訪問且B = 32的情況為例,遠程AXI通道8和9的總吞吐量大致等于AXI通道4或5的總吞吐量。
7. 相關(guān)工作
就我們所知,豎亥是第一個全面地在FPGA上對HBM進行基準測試的平臺。我們將與豎亥密切相關(guān)的工作進行對比:1)在FPGA上對傳統(tǒng)存儲器進行基準測試;2)使用HBM進行數(shù)據(jù)處理;3)加速FPGA的應用。
表格7.遠程AXI通道之間的沖突影響。我們使用不同數(shù)量(2、4或6)的遠程AXI通道來訪問HBM通道1,以測量吞吐量(GB / s)。當遠程AXI通道的數(shù)量為2時,AXI通道4和5處于活動狀態(tài) 。當僅使用本地AXI通道1訪問HBM通道1時,對于B = 32,B = 64或B =128的情況,吞吐量為6.67、12.9或13.3 GB / s。空值表示相應的AXI通道 不參與特定的基準測試。
在FPGA上對傳統(tǒng)內(nèi)存進行基準測試。先前的工作[20],[22],[23],[47]試圖通過使用高級語言(例如OpenCL)在FPGA上對傳統(tǒng)存儲器(例如DDR3)進行基準測試。相反,我們在最先進的FPGA上對HBM進行基準測試。
使用HBM/ HMC進行數(shù)據(jù)處理。先前的工作[4],[6],[15],[16],[21],[26],[27],[46]使用HBM來加速其應用,例如哈希表深度學習和流式傳輸通過利用Intel KnightsLanding(KNL)的HBM [12]提供的高內(nèi)存帶寬。相比之下,我們在Xilinx FPGA板上測試了HBM的性能。
使用FPGA加速應用程序。先前的作品[1],[3],[5],[7],[8],[9],[10],[11],[14],[17],[24],[25], [28],[29],[30],[31],[32],[33],[34],[35],[36],[37],[38],[39],[40] ] [45]使用FPGA加速了廣泛的應用,例如數(shù)據(jù)庫和深度學習推理。相反,無論應用如何,我們都在最新的FPGA上系統(tǒng)地對HBM進行基準測試。
8. 結(jié)論
高帶寬存儲器(HBM)增強了FPGA,以解決IO密集應用程序的存儲器帶寬瓶頸。但是,HBM的性能特征仍未在FPGA上進行定量和系統(tǒng)的分析。我們通過在具有兩層HBM2子系統(tǒng)的最新FPGA上對HBM堆棧進行基準測試來揭秘。相應的,我們建議使用豎亥來對HBM的基本細節(jié)進行測試。從獲得的基準測試數(shù)據(jù)中,我們觀察到:1)HBM提供高達425 GB / s的內(nèi)存帶寬,大約是最新GPU的內(nèi)存帶寬的一半,2)如何使用HBM對性能有著顯著影響,這反過來證明了揭露HBM特征的重要性。豎亥可以很容易地推廣到其他FPGA板或其他的存儲器模塊。我們將使相關(guān)的基準測試代碼開源,以便可以探索新的FPGA板并比較各個板的結(jié)果。
源代碼鏈接:https://github.com/RC4ML/Shuhai 。
9. 參考文獻
[1]Altera. Guidance for Accurately Benchmarking FPGAs, 2007.
[2]Arm. AMBA AXI and ACE Protocol Specification, 2017.
[3]M. Asiatici and P. Ienne. Stop crying over your cache miss rate:
Handlingefficiently thousands of outstanding misses in fpgas. In FPGA,
2019.
[4]B. Bramas. Fast Sorting Algorithms using AVX-512 on Intel Knights
Landing.CoRR, 2017.
[5]E. Brossard, D. Richmond, J. Green, C. Ebeling, L. Ruzzo, C. Olson, and
S.Hauck. A model for programming data-intensive applications on
fpgas:A genomics case study. In SAAHPC, 2012.
[6]X. Cheng, B. He, E. Lo, W. Wang, S. Lu, and X. Chen. Deploying hash
tableson die-stacked high bandwidth memory. In CIKM, 2019.
[7]Y.-k. Choi, J. Cong, Z. Fang, Y. Hao, G. Reinman, and P. Wei. A QuantitativeAnalysis on Microarchitectures of Modern CPU-FPGA
Platforms.In DAC, 2016.
[8]Y.-K. Choi, J. Cong, Z. Fang, Y. Hao, G. Reinman, and P. Wei. In-Depth
Analysison Microarchitectures of Modern Heterogeneous CPU-FPGA
Platforms.ACM Trans. Reconfigurable Technol. Syst., 2019.
[9]J. Fowers, K. Ovtcharov, K. Strauss, E. S. Chung, and G. Stitt. A high memory bandwidthfpga accelerator for sparse matrix-vector
multiplication.In FCCM, 2014.
[10]Q. Gautier, A. Althoff, Pingfan Meng, and R. Kastner. Spector: An
OpenCLFPGA benchmark suite. In FPT, 2016.
[11]Z. Istva ?n, D. Sidler, and G. Alonso. Runtime parameterizable regular
expressionoperators for databases. In FCCM, 2016.
[12]Jim Jeffers and James Reinders and Avinash Sodani. Intel Xeon Phi
ProcessorHigh Performance Programming Knights Landing Edition,
2016.
[13]H. Jun, J. Cho, K. Lee, H. Son, K. Kim, H. Jin, and K. Kim. Hbm (high
bandwidthmemory) dram technology and architecture. In IMW, 2017.
[14]S. Jun, M. Liu, S. Xu, and Arvind. A transport-layer network for
distributedfpga platforms. In FPL, 2015.
[15]S. Khoram, J. Zhang, M. Strange, and J. Li. Accelerating graph analytics
byco-optimizing storage and access on an fpga-hmc platform. In FPGA,
2018.
[16]A. Li, W. Liu, M. R. B. Kristensen, B. Vinter, H. Wang, K. Hou,
A.Marquez, and S. L. Song. Exploring and Analyzing the Real Impact
ofModern On-Package Memory on HPC Scientific Kernels. In SC, 2017.
[17]Z. Liu, Y. Dou, J. Jiang, Q. Wang, and P. Chow. An fpga-based processor
fortraining convolutional neural networks. In FPT, 2017.
[18]J. Macri. Amd’s next generation gpu and high bandwidth memory
architecture:Fury. In Hot Chips, 2015.
[19]S. Manegold, P. Boncz, and M. L. Kersten. Generic database cost models
forhierarchical memory systems. In PVLDB, 2002.
[20]K.Manev,A.Vaishnav,andD.Koch.Unexpecteddiversity:Quantitative
memoryanalysis for zynq ultrascale+ systems. In FPT, 2019.
[21]H. Miao, M. Jeon, G. Pekhimenko, K. S. McKinley, and F. X. Lin. Streambox-hbm:Stream analytics on high bandwidth hybrid memory.
InASPLOS, 2019.
[22]S. W. Nabi and W. Vanderbauwhede. Mp-stream: A memory perfor-
mancebenchmark for design space exploration on heterogeneous hpc
devices.In IPDPSW, 2018.
[23]S. W. Nabi and W. Vanderbauwhede. Smart-cache: Optimising memory
accessesfor arbitrary boundaries and stencils on fpgas. In IPDPSW, 2019.
[24]M. J. H. Pantho, J. Mandebi Mbongue, C. Bobda, and D. Andrews. Trans- parentAcceleration of Image Processing Kernels on FPGA-Attached Hybrid Memory CubeComputers. In FPT, 2018.
[25]H. Parandeh-Afshar, P. Brisk, and P. Ienne. Efficient synthesis of compressortrees on fpgas. In ASP-DAC, 2008.
[26]I. B. Peng, R. Gioiosa, G. Kestor, P. Cicotti, E. Laure, and S. Markidis.Exploring the performance benefit of hybrid memory system on hpc environments.In IPDPSW, 2017.
[27]C. Pohl and K.-U. Sattler. Joins in a heterogeneous memory hierarchy:Exploiting high-bandwidth memory. In DAMON, 2018.
[28]N. Ramanathan, J. Wickerson, F. Winterstein, and G. A. Constantinides. A casefor work-stealing on fpgas with opencl atomics. In FPGA, 2016.
[29]S. Taheri, P. Behnam, E. Bozorgzadeh, A. Veidenbaum, and A. Nicolau. Affix:Automatic acceleration framework for fpga implementation of
openvxvision algorithms. In FPGA, 2019.
[30]D. B. Thomas, L. Howes, and W. Luk. A Comparison of CPUs, GPUs,
FPGAs,and Massively Parallel Processor Arrays for Random Number
Generation.In FPGA, 2009.
[31]S. I. Venieris and C. Bouganis. fpgaconvnet: A framework for mapping
convolutionalneural networks on fpgas. In FCCM, 2016.
[32]J. Wang, Q. Lou, X. Zhang, C. Zhu, Y. Lin, and D. Chen. Design flow ofaccelerating hybrid extremely low bit-width neural network
inembedded fpga. In FPL, 2018.
[33]Z.Wang,B.He,andW.Zhang.AstudyofdatapartitioningonOpenCL-
basedFPGAs. In FPL, 2015.
[34]Z. Wang, B. He, W. Zhang, and S. Jiang. A performance analysis
frameworkfor optimizing OpenCL applications on FPGAs. In HPCA,
2016.
[35]Z. Wang, K. Kara, H. Zhang, et al. Accelerating Generalized Linear
Modelswith MLWeaving: A One-size-fits-all System for Any-precision
Learning.VLDB, 2019.
[36]Z. Wang, J. Paul, H. Y. Cheah, B. He, and W. Zhang. Relational query
processingon OpenCL-based FPGAs. In FPL, 2016.
[37]Z. Wang, J. Paul, B. He, and W. Zhang. Multikernel data partitioning
withchannel on OpenCL-based FPGAs. TVLSI, 2017.
[38]Z. Wang, S. Zhang, B. He, and W. Zhang. Melia: A MapReduce
frameworkon OpenCL-based FPGAs. TPDS, 2016.
[39]J. Weberruss, L. Kleeman, D. Boland, and T. Drummond. Fpga
accelerationof multilevel orb feature extraction for computer vision.
InFPL, 2017.
[40]G. Weisz, J. Melber, Y. Wang, K. Fleming, E. Nurvitadhi, and J. C. Hoe.
Astudy of pointer-chasing performance on shared-memory processor-
fpgasystems. In FPGA, 2016.
[41]M. Wissolik, D. Zacher, A. Torza, and B. Day. Virtex UltraScale+ HBM
FPGA:A Revolutionary Increase in Memory Performance, 2019.
[42]Xilinx. AXI Reference Guide, 2011.
[43]Xilinx. Alveo U280 Data Center Accelerator Card Data Sheet, 2019.
[44]Xilinx. AXI High Bandwidth Memory Controller v1.0, 2019.
[45]Q. Xiong, R. Patel, C. Yang, T. Geng, A. Skjellum, and M. C. Herbordt.
Ghostsz:A transparent fpga-accelerated lossy compression framework.
InFCCM, 2019.
[46]Y. You, A. Bulu ?c, and J. Demmel. Scaling deep learning on gpu and
knightslanding clusters. In SC, 2017.
[47]H. R. Zohouri and S. Matsuoka, “The memory controller wall: Bench-marking the intel fpga sdk for opencl memory interface,” in H2RC, 2019.
-
FPGA
+關(guān)注
關(guān)注
1643文章
21979瀏覽量
614495 -
DRAM
+關(guān)注
關(guān)注
40文章
2343瀏覽量
185225 -
HBM
+關(guān)注
關(guān)注
1文章
408瀏覽量
15131
發(fā)布評論請先 登錄
HBM3E量產(chǎn)后,第六代HBM4要來了!

HBM格局生變!傳三星HBM3量產(chǎn)供貨英偉達,國內(nèi)廠商積極布局
概倫電子芯片級HBM靜電防護分析平臺ESDi介紹
LTC2654在使用過程中,想去評估它實際的輸出負載調(diào)整度,但是實測的結(jié)果為3LSB/mA左右,為什么?
美光發(fā)布HBM4與HBM4E項目新進展
ESD HBM測試差異較大的結(jié)果分析

AI時代核心存力HBM(上)
HBM與GDDR內(nèi)存技術(shù)全解析

ADS8320 Datasheet 7.4.2吐數(shù)規(guī)則與實測結(jié)果不符合是為什么?
如何優(yōu)化FPGA設計的性能
繼HBM上車之后,移動HBM有望用在手機上
SK海力士9月底將量產(chǎn)12層HBM3E高性能內(nèi)存
HBM上車?HBM2E被用于自動駕駛汽車
實測分享,瑞芯微RK3588八核國產(chǎn)處理器性能測評!確實“遙遙領先”!
FPGA 高級設計:時序分析和收斂
- 設計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設計
- 連接器
- 行業(yè)應用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設備
- 機器人
- 安全設備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應鏈服務 PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論