 Vokenization是一種比GPT-3更智能的視覺語言模型
Vokenization是一種比GPT-3更智能的視覺語言模型

學習人工智能,最好的辦法就是先考上大學,學好計算機和數學,其次就是生個孩子。這可不是一個段子。有了孩子之后,你會能更好理解人工智能到底是如何發生的。看著一個牙牙學語的小嬰兒開始對這個世界發生好奇,終于有一天開始指著一個毛茸茸的東西叫出“貓咪”的時候,你可能就會理解教會一個孩子說話并不比教會人工智能認出一只貓更容易。
人工智能靠大量的算力和數據,而人類靠著五感,還有我們那個低功率的大腦。不過,很快你就會對小孩子的學習能力驚訝不已,他會指著各種他不認識的東西問你“這是什么”,直到你不勝其煩。等到再長大一些,小孩子就不會滿足于僅僅知道這些東西的名字,開始想你發問“為什么會這樣”,再次把你問到山窮水盡。
我們知道,現在人工智能領域,圖像識別和自然語言處理(NLP)正處在如日中天的發展階段。在眾多單項上面,圖像識別的能力要遠遠高于普通人,甚至比專家還好,NLP的翻譯、聽讀、寫作能力更是與專業人士不相上下,特別今年推出的GPT-3,更是以超大參數規模這種氪金方式來實現逆天的寫作能力。
但這又怎樣?盡管GPT-3可以編造出一大段看起來很真實的假新聞,但它仍然是靠著過去的文本經驗來認知世界的,它會在很多常識性的問題上犯下低級錯誤,比如在回答“太陽有幾只眼睛”的反常識問題上,GPT-3照樣一本正經的給出“太陽有一只眼睛”的答案。如果是一個人第一次碰到這種問題,它往往并不是從文本里找答案,而是真的會去看一眼太陽的。而這正是我們人類掌握語言、傳遞信息最常見的一種方式。
受此啟發,最近北卡羅來納大學教堂山分校的研究人員設計了一種新的AI模型來改變GPT-3的這種缺陷,他們把這一技術稱之為“Vokenization”,可以賦予像GPT-3這樣的語言模型以“看”的能力。這個思路很好理解,我們從來不是靠一種方式來認識世界的,而把語言處理和機器視覺聯系起來,才能更好地讓人工智能來接近人的認識能力。那么這種“Voken”技術到底好不好用,正是本文要重點介紹的。
無所不能的GPT-3,卻“不知道自己在說什么”
今年5月份正式出道的GPT-3,一度成為“無所不能”的代名詞,OpenAI推出的這個第三代NLP語言模型,包含1750億個參數,采用了英文維基百科、數字化圖書、互聯網網頁等超大規模語料進行訓練,是現有的規模最大、也最復雜的語言模型。從GPT-3對外API接口開放之后,研究者就從GPT03的強大文本生成能力中挖掘出層出不窮的應用,從答題、寫小說、編新聞到寫代碼、做圖表等等。但GPT-3也印證了“出道即巔峰”這句話,也是從一開始就爭議不斷。人們對其實際的應用前景表示極大的懷疑。
我們復習下GPT-3的作用原理。GPT-3采用的是少示例(Few-shot)學習的方式,對于一個特定的語言任務,只需要給定任務描述,并給出幾個從輸入到輸出的映射示例,甚至只是給出一個開頭的文本,GPT-3就可以根據前景預設自動生成相關下文,以此來完成對話、答題、翻譯和簡單的數學計算等任務。GPT-3的優勢就在于預訓練模型不需要使用大量標記的訓練數據進行微調,這種便利性為普通人進行相關語言任務的使用上消除了障礙。
盡管GPT-3在很多領域的表現都令人折服,文本的質量高到能騙過大多數人類(無法分辨到底是機器寫的還是人類寫的),但是GPT-3本身的缺陷仍然非常明顯。事實上,GPT-3的訓練方式決定了它并不是真正理解“語義”,而是能夠基于龐大的語料數據,進行海量搜索,匹配相應的答案。在這一過程中,GPT-3只是通過純粹統計學的方法“建立起聯系”,但是并沒有真正理解語義。比如在一個幫助患者減輕焦慮情緒的問答中,“患者”表示感覺很糟,想要自殺的時候,GPT-3直接回復了“你可以”。
GPT-3的問題就像是上世紀80年代John Searle提出的“中文屋實驗”里的那個并不懂中文的翻譯者,GPT-3也只是手握著一本“無所不知”的百科全書,但是它并不清楚這個世界運行的真實邏輯,更無法解決具體場景下的具體情況。之前,紐約大學的兩位教授就聯名指出人們對GPT-3作用的高估,在《傲慢自大的 GPT-3:自己都不知道自己在說什么》里提到,它(GPT-3)本身并不具有 “革命性” 的變化,也不能真正理解語義,如果某項工作的 “結果” 非常重要,那么你不能完全信任人工智能。
簡單來說就是,人工智能如果想要突破文本的統計意義而理解語義,那就必須要將文本和現實世界建立起聯系。顯然,這一點GPT-3還不能做到。為了能夠讓語言文本和實際的世界建立起聯系,研究人員決定將語言模型和機器視覺結合起來,研究者們需要用一個包含文本和圖像的數據集從頭開始訓練一個新模型,這就是被稱作“Vokenization”的視覺語言數據集模型。
Vokenization:如何成為既好用又夠用的數據集
我們首先如何來理解這兩種模型的差異呢?如果你問一下GPT-3這樣一個問題,“綿羊是什么顏色?”它的回答中出現“黑色”的可能和“白色”一樣多,因為它能在大量文本中看到“Black Sheep”(害群之馬)這個詞。而如果你問一個圖像識別模型,它就不會從抽象的文本中學習,而是更直接從現實的圖像中學習,指出“這是一只白色綿羊”,而“這是一只黑色綿羊”。
我們既需要一個知識特別豐富的機器人,也需要一個能夠看懂現實狀況的機器人,只有把二者結合起來,才是人工智能更接近和人類交流合作的樣子。但這個過程并不那么容易實現。實際上,我們常用的圖像描述是不適用的。比如下面這張圖,通常的描述,只能識別出物體“貓”,或者和貓常常一起出現的局部事物“水杯、毛線球、盒子和貓爪”,并沒有描述出這只貓的狀態和相互關系。
相比單純的對象標注,Vokenization視覺語言數據集就需要對圖像進行一組帶有描述性標題的編輯。例如,下圖的標題會是“一只坐在正在打包的行李箱中的橙色的貓”,這和典型的圖像數據集不同,它不僅是用一個名詞(例如:貓)來標記主要對象,而是給AI模型標注出了如何使用動詞和介詞的相互關聯和作用。
但是這類視覺語言數據集的缺陷在于其數量實在太少,數據的生成和管理過程太久,相比較維基百科這種純文本包含近30億個單詞,這僅僅只占GPT-3數據集的0.6%的這樣的規模相比,像微軟的MS COCO(上下文通用對象)這樣的可視化語言數據集才包含700萬個數據,對于訓練一個成熟的AI模型來說顯然是不夠的。
“Vokenization”的出現就是要解決這個問題。像GPT-3是通過無監督學習來訓練的,這不需要手動標記數據,才使它極易去擴展規模。Vokenization也采用了無監督的學習方法,將MS COCO中的小數據量增加到英文維基百科的級別。解決了數據源的數量差異問題,Vokenination還要面臨第二個挑戰,就是解決視覺監督和自然語言文本之間的聯接問題。
Voken代替Token:讓文本“看懂”世界
一般來看,自然語言中的詞匯中很大一部分是沒有視覺特征的,這為視覺監督提出了主要的挑戰。我們知道,在AI訓練語言模型中的單詞被稱之為Token(標記),而研究人員則把視覺語言模型中與每個Token相關的圖像稱之為Voken。而Vokenizer就代表為一個Token尋找一個Voken的算法,Vokenization就代表整個算法模型實現的過程。
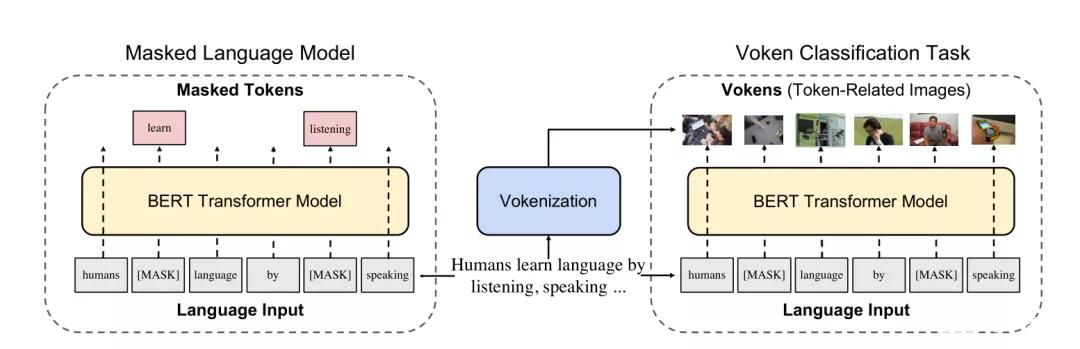
Vokenization的過程,就不是從圖像數據集開始為圖像標注標題,而是從一個語言數據集開始,采用無監督學習的方式,將每個單詞與圖像進行匹配,實現一個高擴展性,這就是解決第一個挑戰的具體思路。與此同時,研究者還要解決第二個挑戰的單詞和圖像的關聯性問題。
GPT-3使用的是“單詞嵌入”的方式,基于上下文來創建每個單詞的數學表示,然后依賴這些嵌入把單詞變成句子,把句子組合成段落。Vokenization采取了一種并行的嵌入技術用于掃描圖像的視覺模式。研究者舉的一個案例是,將貓出現在床上的頻率和出現在樹上的頻率繪制成一個表格,并用這些信息創建一只“貓”的Voken。
研究者就在MS COCO數據集上同時采用了兩種嵌入技術,把圖像轉換成視覺嵌入,把字幕轉換成文字嵌入。這樣做的優勢之處在于,這兩種嵌入可以在一個三維空間中繪制出來,并看到文字嵌入和視覺嵌入在圖形中的相互關聯,一只“貓”的視覺嵌入應該會和文本中的“貓”的嵌入相重疊。這能夠解決什么問題呢?這給文本Token提供了一種圖像化的Voken匹配,使得它能夠有更加情景化的表示,對于一個抽象的詞來說,也可以根據不同的上下文情境,具有了完全不同的意思。
比如,“Contact”這個詞,在下圖左側的Voken的匹配下,它就代表“聯系信息”的意思,在下圖右側的Voken的匹配下,就代表了“撫摸一只貓”的意思。說到這里,我們大概就能理解Voken的作用。當GPT-3模型對于一些文本概念無法準確理解其語境和相應語義的時候,它就容易開始自我發揮,胡言亂語,而一旦通過給這個Token找到圖像化的Voken實例,就可以真正理解這個詞的實際涵義。
現在,研究人員通過在MS COCO中創建的視覺和單詞嵌入方法來訓練Vokenizer算法,在英語維基百科中已經為40%的Token找到了Voken,盡管不到一半,但至少是30億單詞的數據集中的40%。基于這一數據集,研究人員重新訓練了谷歌開發的BERT模型,并且在6種不同的語言理解的測試中測試了這一新模型,結果顯示改進后的BERT在幾個測試方面都表現良好。
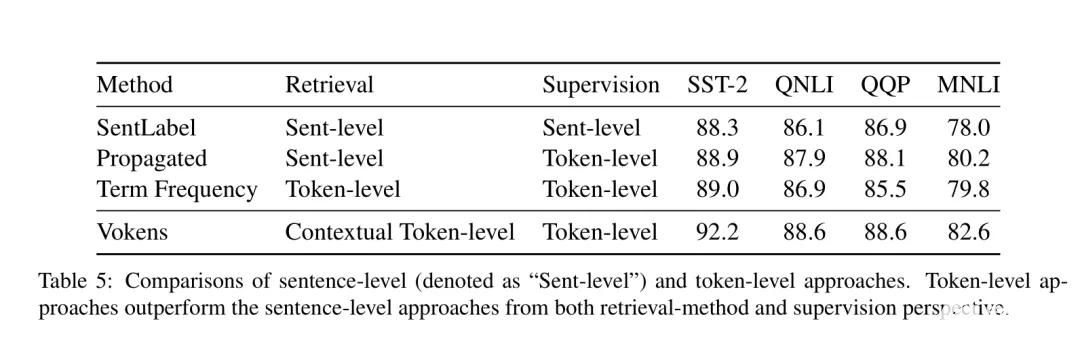
Vokenization現在還只是處在研究階段,我們也只能從其論文的結果中窺探這一模型的效果,至于這項新的視覺語言化技術的應用和展示,還有待后面我們進一步追蹤觀察。不敢怎樣,在無監督學習幫助下的視覺語言模型,成為NLP領域剛剛閃現的一朵火花,為自然語言處理打開了新的思路,使得純粹的文本訓練開始和圖像識別聯系起來。這就像讓一個博聞強記的機器人從“自顧自說話”,變得可以聽見和看見外界的真實狀況,能夠成為那個“睜開眼睛看世界”的人工智能。
最后,讓我們重溫一個經典的場景,在海倫凱勒的自傳中,她描述了自己如何學會“Water”這個單詞的含義。又盲又聾的海倫總是搞混“杯子”和“水”的指代,直到她的老師沙利文女士帶著她來到噴池邊,一邊感受著清涼的泉水,一邊感受著沙利文在她手心寫下的“Water”,她這才終于明白了“水”的真實指代和含義。用她的話說“不知怎么回事,語言的秘密突然被揭開了,我終于知道水就是流過我手心的一種物質。這個叫“水”的字喚醒了我的靈魂……”
幸好,人類在失去光明和聽覺之后,僅能通過觸覺還能理解語言的奧秘,那么對于人工智能來說,擁有了強大的圖像識別能力,又有近乎無限的文本知識,那么,未來AI將能否通向一條具有像人類在日常經驗中學習的常識之路嗎?
fqj
-
人工智能
+關注
關注
1805文章
48887瀏覽量
247749 -
nlp
+關注
關注
1文章
490瀏覽量
22543
發布評論請先 登錄

一種基于正交與縮放變換的大模型量化方法

OpenAI即將推出GPT-5模型

OpenAI將發布更智能GPT模型及AI智能體工具
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
NaVILA:加州大學與英偉達聯合發布新型視覺語言模型
基于視覺語言模型的導航框架VLMnav
Llama 3 與 GPT-4 比較
英偉達預測機器人領域或迎“GPT-3時刻”
Jim Fan展望:機器人領域即將迎來GPT-3式突破
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜






 工商網監
工商網監
評論