 通過深度學習為蒙娜麗莎添加動畫效果
通過深度學習為蒙娜麗莎添加動畫效果

背景
坊間傳聞,當您在房間里走動時,蒙娜麗莎的眼睛會一直盯著您。
這就是所謂的“蒙娜麗莎效應”。興趣使然,我最近就編寫了一個可互動的數字肖像,通過瀏覽器和攝像頭將這一傳說變成現實。
這個項目的核心是利用 TensorFlow.js、深度學習和一些圖像處理技術。總體思路如下:首先,我們必須為蒙娜麗莎的頭部以及從左向右注視的眼睛生成一系列圖像。從這個動作池中,我們根據觀看者的實時位置連續選擇并顯示單個幀。
TensorFlow.js
https://tensorflow.google.cn/js
接下來,我將從技術層面詳細介紹該項目的設計和實現過程:
通過深度學習為蒙娜麗莎添加動畫效果
圖像動畫是一種調整靜止圖像的技術。使用基于深度學習的方式,我可以生成極其生動的蒙娜麗莎注視動畫。
具體來說,我使用了 Aliaksandr Siarohin 等人在 2019 年發布的一階運動模型 (First Order Motion Model, FOMM)。直觀地講,此方法由兩個模塊構成:一個模塊用于提取運動,另一個模塊用于生成圖像。運動模塊從攝像頭記錄的視頻中檢測關鍵點并進行局部仿射變換 (Affine Transformation)。然后,將在相鄰幀之間這些關鍵點的值的差值作為預測密集運動場的網絡的輸入,并且用作遮擋掩模 (Occlusion Mask),遮擋掩模可以指定或根據上下文推斷需要修改的圖像區域。之后,圖像生成網絡會檢測面部特征,并生成最終輸出,即根據運動模塊結果重繪源圖像。
一階運動模型
http://papers.nips.cc/paper/8935-first-order-motion-model-for-image-animation.pdf
我之所以選擇 FOMM 是因為它易于使用。此領域以前使用的模型都“針對特定目標”:需要提供詳細的特定目標數據才能添加動畫效果,而 FOMM 則不需要知道這些數據。更為重要的是,這些作者發布了開箱即用的開源實現,其中包含預先訓練的面部動畫權重。因此,將該模型應用到蒙娜麗莎的圖像上就變得十分簡單:我只需將倉庫克隆到 Colab Notebook,生成一段我眼睛四處觀看的簡短視頻,并將其與蒙娜麗莎頭部的屏幕截圖一起傳進模型。得到的影片超級棒。我最終僅使用了 33 張圖片就完成了最終的動畫的制作。
源視頻和 FOMM 生成的圖像動畫預測示例
使用 FOMM 生成的幀示例
圖像融合
雖然我可以根據自己的目的重新訓練該模型,但我決定保留 Siarohin 得到的權重,以免浪費時間和計算資源。但是,這意味著得到的幀的分辨率較低,且輸出僅有主體的頭部。介于我希望最終圖像包含整個蒙娜麗莎,即包括手部、軀干和背景,我選擇將生成的頭部動畫疊加到油畫圖像上。
頭部幀疊加到基礎圖像上的示例:為了說明問題,此處顯示的版本來自項目的早期迭代,其中頭部幀存在嚴重的分辨率損失
然而,這帶來了一系列難題。查看上述示例時,您會發現,模型輸出的分辨率較低(由于經過了 FOMM 的扭曲程序,背景附帶有一些細微的更改),從而導致頭部幀在視覺上有突出的效果。換句話說,很明顯這是一張照片疊加在另一張照片上面。為了解決這個問題,我使用 Python 對圖像進行了一些處理,將頭部圖像“融合”到基礎圖像中。
首先,我將頭部幀重新 resize 到其原始分辨率。然后,我構造一個新的幀,該幀的每個像素值由原圖像素和模型輸出的像素求均值后加權 (alpha) 求得,離頭部中心越遠的像素權值越低。
用于確定 alpha 的函數改編自二維 sigmoid,其表達式為:
其中,j 確定邏輯函數的斜率,k 為拐點,m 為輸入值的中點。以下是函數的圖形表示:
我將上述過程應用到動畫集中的所有 33 個幀之后,得到的每個合成幀都會讓人深信不疑這就是一個圖像:
通過 BlazeFace 跟蹤觀看者的頭部
此時,剩下的工作就是確定如何通過攝像頭來跟蹤用戶并顯示相應的幀。
當然,我選擇了 TensorFlow.js 來完成此工作。這個庫提供了一組十分可靠的模型,用于檢測人體,經過一番研究和思考后,我選擇了 BlazeFace。
BlazeFace
https://github.com/tensorflow/tfjs-models/tree/master/blazeface
BlazeFace 是基于深度學習的目標識別模型,可以檢測人臉和面部特征。它經過專門訓練,可以使用移動相機輸入。它特別適合我的這個項目,因為我預計大部分觀看者都會以類似方式(即頭部位于框內、正面拍攝以及非常貼近相機)使用攝像頭,無論是使用移動設備還是筆記本電腦。
但是,在選擇此模型時,我最先考慮到的是它異常快的檢測速度。為了讓這一項目有意義,我必須能夠實時運行整個動畫,包括面部識別步驟。BlazeFace 采用 Single-Shot 檢測 (SSD) 模型,這是一種基于深度學習的目標檢測算法,在網絡的一次正向傳遞中可以同時移動邊界框并檢測目標。BlazeFace 的輕量檢測器能夠以每秒 200 幀的速度識別面部特征。
BlazeFace 在給定輸入圖像時的捕獲內容演示:包圍人體頭部以及面部特征的邊界框
選定模型后,我持續將用戶的攝像頭數據輸入 BlazeFace 中。每次運行后,模型都會輸出一個含有面部特征及其相應二維坐標位置的數組。借助此數組,我計算兩只眼睛之間的中點,從而粗略估算出面部中心的 X 坐標。
最后,我將此結果映射到介于 0 與 32 之間的某個整數。您可能還記得,其中的每一個值分別表示動畫序列中的一個幀,0 表示蒙娜麗莎的眼睛看向左側,32 表示她的眼睛看向右側。之后,就是在屏幕上顯示結果了。
責任編輯:lq
-
模塊
+關注
關注
7文章
2785瀏覽量
50016 -
圖像處理
+關注
關注
27文章
1326瀏覽量
57876 -
深度學習
+關注
關注
73文章
5557瀏覽量
122656
原文標題:“來自蒙娜麗莎的凝視”— 結合 TensorFlow.js 和深度學習實現
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
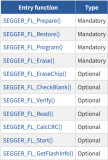
如何通過SFL為設備添加Flash編程支持
BP神經網絡與深度學習的關系
NPU在深度學習中的應用
激光雷達技術的基于深度學習的進步
AI大模型與深度學習的關系
AI深度噪音抑制技術






 工商網監
工商網監
評論