 OpenStack云平臺監控數據采集及處理的實踐與優化
OpenStack云平臺監控數據采集及處理的實踐與優化
陳云煒 李偉波 陳蔡濤
睿哲科技股份有限公司
在OpenStack云平臺中,對資源的監控與計量是確保云平臺穩定運行的標準配置,也恰恰是日常最讓人煩惱的問題。尤其在公有云平臺中,對資源的監控與計量不僅可以向業務使用者展現業務對資源的使用情況,還可以成為按需計費模式下的計費依據,但是監控數據的準確性、實時性以及海量監控數據的處理、儲存和索引性能等都具有挑戰性的工作。說到運維監控,大家熟知的有Zabbix、Cacti、Nagios等傳統的開源運維監控系統;這些監控系統都很強大也很靈活,從普通的業務使用上來說,經過相關的配置、插件定制甚至是二次開發,完全可以完成對系統資源的監控與計量功能。但這些監控系統畢竟是獨立的監控系統,并沒有與OpenStack云平臺進行契合,在OpenStack云平臺中增刪業務資源時,這些監控系統是無感知的,也就是不能自動地對OpenStack云平臺的資源進行自動監控。并且OpenStack是一個多租戶的云平臺,以上這些開源的監控系統中要做到不同租戶的資源數據分別監控與計量以及索引,還是比較復雜的。所幸OpenStack社區有Ceilometer項目來實現OpenStack集群資源監控與計量的功能。Ceilometer項目從OpenStack Folsom版本開始發布,經過不斷的迭代,功能也逐漸豐富,包含了監控、計量與告警等功能,并且通過OpenStack的endpoint RESTful API以及消息隊列,可以非常好地與OpenStack中的其他項目相結合,實現分租戶的自動化的資源監控和計量。然而由于Ceilometer在運行性能上的一些原因,社區逐漸地Ceilometer項目進行了功能的拆分:Ceilometer主要實現資源數據的采集,將計量和數據存儲功能分拆成為Gnocchi項目,將告警功能拆分成為Aodh項目。本文僅涉及Ceilometer數據采集和Gnocchi數據處理和存儲兩個部分,并且基于OpenStack Ocata版及之后版本的Ceilometer和Gnocchi進行分析。
二、Ceilometer與Gnocchi架構
1.Ceilometer架構和基本概念
在OpenStack中Ceilometer主要負責數據采集,其采用類似于agent加server的結構,大致的架構如下圖1所示:
圖 1
其數據采集是由agent端來完成的,在Ceilometer中有compute、central、ipmi等類型的agent,一般常用的是compute和central兩種類型的agent:
Compute agent:負責收集OpenStack部署中各個計算節點上VM實例的資源使用數據。Compute agent須在每個計算節點上安裝,并且需要與虛擬機管理程序(Hypervisor)進行密切的交互以獲得VM虛擬機實例的相關資源數據。不同類型的Hypervisor提供了不同的API,因此Compute agent所能收集的數據受限于Hypervisor API所能提供的數據類型。
Central agent:負責輪詢公共RESTful API,以收集未通過消息隊列發布消息的OpenStack組件的相關資源情況,還可以通過SNMP收集硬件相關的資源。例如:OpenStack Networking、OpenStack Object Storage、OpenStack Block Storage等資源的使用情況均由Central agent輪詢RESTful API來進行收集。
IPMI agent:負責收集OpenStack部署的各個計算節點上的IPMI傳感器數據和Intel節點管理器數據。此agent需要節點安裝了ipmitol程序以支持IPMI數據收集。
Ceilometer agent采集到的數據需要發送到server端進行匯總、分析和儲存,在ceilometer中數據的發送方式是由publisher來定義和處理的,收集到的每種類型的數據都可以使用一個或多個publisher發送,在OpenStack的Ocata版本中,Ceilometer agent采集到的數據依然默認是采用notifier://類型的publisher發送到消息隊列中。Ceilometer agent采集到的原始數據稱為Meter,Meter是資源使用的某個計量項,它的屬性包括:名稱(name)、單位 (unit)、類型(cumulative:累計值,delta:變化值、gauge:離散或者波動值)以及對應的資源屬性等;某些數據在采集到時可能還不符合相關格式,因此可以在發送數據前進行一些轉換,這個轉換稱為Transformer,一條Meter數據可以經過多個Transformer處理后再由publisher發送,流程簡圖如下圖2所示:
圖 2
在消息隊列中由Ceilometer collector充當一個server的角色來消費消息隊列中的收集到的監控數據消息。Ceilometer collector可將采集到的數據進一步加工和處理,然后將數據通過HTTP方式發送到Gnocchi組件中進行處理和儲存,并且后續的數據索引讀取也是由Gnocchi進行處理。但Ceilometer也保留了舊版本的一些功能,可以選擇舊版本Ceilometer的方式將數據直接存入一些數據庫中。
2.Gnocchi架構和基本概念
Gnocchi 提供數據存儲服務,是一個時間序列數據庫,為Ceilometer提供存儲后端,致力于解決Ceilometer應用中所面臨的大規模存儲和索引時間序列數據的性能問題。Gnocchi不僅解決了大規模時間序列數據存取的性能問題,同時還把OpenStack云平臺中多租戶等特性考慮在內。引用Gnocchi官方的一張圖,其架構如下圖3所示:
圖 3
由以上架構圖可以看出Gnocchi主要有兩個核心部件:API和Metricd,并且依賴于三個外部組件:Measure Storage、Aggregate Storage、Index。
Measure Storage:measures是Gnocchi對數據的第三層劃分,是實際的監控數據。因此Measure Storage用于保存實際監控數據,并且是臨時保存的,在Gnocchi處理后會刪除其中已處理的數據。
Aggregate Storage:首先要理解Aggregate是什么。Gnocchi采用了一種獨特的時間序列存儲方法:它不是存儲原始數據點,而是在存儲它們之前對它們按照預定義的策略進行聚合計算,僅保存處理后的數據。所以Gnocchi在讀取這些數據時會非常快,因為它只需要讀取預先聚合計算好的結果。因此Aggregate Storage是用于保存用戶時間看到的聚合計算后的結果數據。
Index:通常是一個關系型數據庫,用于索引resources和metrics,以使得可以快速地從Measure Storage或Aggregate Storage中取出所需要的數據。
API:即gnocchi-api服務進程,通過Indexer和Storage的driver,提供查詢和操作ArchivePolicy,Resource,Metric,Measure的接口,并將新到來的Measure存入Measure Storage。
Metricd:即gnocchi-metricd服務進程,根據Metric定義的ArchivePolicy規則,周期性地從Measure Storage中匯總聚合計算measures,以及對Aggregate Storage中的數據執行數據聚合計算和清理過期數據等動作,并將聚合的結果數據保存到Aggregate Storage。
結合圖2和圖3來看,在Ceilometer collector中收集到的數據通過Gnocchi這個publisher發到到gnocchi-api,再由gnocchi-api將收集到的數據寫入到Measure Storage。Metricd會周期性地檢索Measure Storage是否有數據需要處理,并將Measure Storage中的數據依次取出進行聚合計算,在將計算結果保存到Aggregate Storage后也將Measure Storage中已處理的measures原始數據刪除。
在Gnocchi中,將API和Metricd均設計成無狀態的服務,因此可以很方便地進行橫向擴展。并且對于運行的gnocchi-metriccd守護程序或gnocchi-API端點的數量沒有限制,可以根據系統的負載大小調整相關服務進程的數量即可提升系統的處理能力。
三、Ceilometer與Gnocchi的實踐與優化
上文簡述了Ceilometer和Gnocchi的基本架構和一些基本概念,下文將講述這兩個組件在實際系統中的一些應用,以及遇到的一些問題和解決方法。
1.Ceilometer的實踐與優化
Ceilometer的部署按照官方文檔進行安裝和配置,一般在控制節點運行ceilometer-central、ceilometer-collector和ceilometer-notification服務、在計算節點運行ceilometer-compute服務。然而官方默認的配置并不能完全符合我們的業務需求,需要進一步優化配置。
首先,Ceilometer agent所需要收集的數據是由polling.yaml配置文件來定義的,配置文件路徑為:/etc/ceilometer/polling.yaml,而默認的配置是執行所有定義在ceilometer Python包entry_points.txt中的收集器來收集發送所有數據:
圖 4
然而這個“全量”的配置可能會導致ceilometer agent代碼層面的錯誤,使得收集數據的流程中斷。尤其是對于Ceilometer的Compute agent,上文講到,Ceilometer的Compute agent所能收集的數據受限于Hypervisor API所能提供的數據類型,而ceilometer entry_points.txt中定義了所有不同平臺的收集器,那么肯定會有一些收集器不適用當前平臺環境的,從而導致在執行這些收集器時程序出錯:
圖 5
從數據層面來看,我們應該只收集那些業務系統關心的數據;因為收集過多的無用數據時會給傳輸、處理和儲存都帶來額外的性能開銷,尤其是在使用消息隊列傳輸監控數據時,消息隊列中大量的消息堆積將會導致消息隊列服務占用大量的內存。因此,我們需要優化配置,定制化地執行收集器收集我們所需的數據。例如,在計算節點,我們如果僅需收集實例虛擬機的CPU、內存、磁盤還有虛擬網卡的資源使用情況,并根據各種資源的所需求的實時性定制其發送數據的頻率,簡要配置示例如下圖6所示:
圖 6
其中的interval是發送數據間隔,單位是秒。而meters則是需要收集的數據類型,其參數值需要根據當前Ceilometer所能收集的數據類型來設定,當前Ceilometer所支持采集的數據類型在/etc/ceilometer/gnocchi_resources.yaml文件中的metrics域所定義,其值同時會對應到Gnocchi中的資源類型,然后才可以在后續的Gnocchi中檢索和處理。
其次的優化是我們需要增加Ceilometer collector的進程數。在上文中提及,在OpenStack Ocata版本中,ceilometer agent收集到的數據依然是先通過消息隊列發送給ceilometer collector處理然后再發送到Gnocchi。而在Ceilometer中collector默認的進程數(即collector workers數量)是1,當集群的虛擬機數量越來越多時以及采集的數據量越來越大時,因Ceilometer collector處理消息速度過慢就會出現消息堆積的情況,由于collector響應不及時還可能導致大量的Unacked消息的出現,如下圖7:
圖 7
出現此類情況后可通過修改/etc/ceilometer/ceilometer.conf的配置,增加collector的workers進程數即可解決。Collector的workers進程數可根據集群的規模以及收集的數據量以及數據上報頻率來設定,建議在滿足消息隊列中的消息不會持續堆積的情況下再增加1~2個workers進程,以滿足未來一段時間內集群虛擬機不斷增加所帶來的監控數據增長。
而在OpenStack Ocata版本之后的Ceilometer中,還可以通過修改所有Ceilometer agent中的/etc/ceilometer/pipeline.yaml配置文件,將其中的publishers從notifier://改為gnocchi://,然后ceilometer agent收集到的數據即可直接發送到Gnocchi的API中,不再需要Ceilometer collector作中轉,避免了通過消息隊列發送給Ceilometer collector處理再轉發到Gnocchi帶來的額外性能消耗:
圖 8
2.Gnocchi的實踐與優化
Gnocchi是一個致力于解決Ceilometer應用中所面臨的大規模存儲和索引時間序列數據的性能問題的組件,因此在Gnocchi中涉及到比較多關于性能方面的參數。
首先是Gnocchi API,其API不僅承擔了接收上報的原始監控數據并儲存到Measure Storage的任務,還承擔著業務系統通過API從Aggregate Storage索引和取出所需數據的任務。在生產環境中,Gnocchi API一般以WSGI或uWSGI應用的形式來運行,可通過Apache的mod_wsgi來運行gnocchi-api,官方的默認配置如下圖9:
圖 9
可根據集群規模的大小調整單個API實例中的進程數和線程數來提高API的并發量;并且Gnocchi API是無狀態的,因此在集群規模較大時,可通過部署多個gnocchi-api實例,然后通過負載均衡分發請求到每個gnocchi-api,以此提升gnocchi-api的并發量。
然后是Gnocchi的Metricd,即gnocchi-metricd服務進程,是Gnocchi中最核心的部分。gnocchi-metricd不僅負責了周期性地到Measure Storage中取出并計算聚合新的監控數據,還負責了按照預定策略,周期性地到Aggregate Storage中重新計算聚合舊的監控數據,并且刪除已過期的監控數據。因此gnocchi-metricd服務屬于計算與I/O都是密集型的進程,需要配置好恰當的gnocchi-metricd workers進程數。如果gnocchi-metricd進程數過少,則會導致Measure Storage有大量的meansures積壓,并且也會導致Aggregate Storage中有待重新計算聚合的meansures出現積壓,可在OpenStack控制節點中執行gnocchi status命令查看gnocchi-metricd當前的數據處理狀態,如圖10:
圖 10
一般來說,gnocchi-metricd的workers進程數應該在滿足meansures不會持續增加的情況下再增加2個以上的workers進程,以滿足未來一段時間內集群虛擬機不斷增加所帶來的監控數據增長。gnocchi-metricd服務也是無狀態的,因此在集群規模較大時,可通過在多個機器上部署gnocchi-metricd實例,然后協同處理集群的meansures監控數據。
然后是Gnocchi中依賴的一個Index數據庫和兩個存儲數據的Storage。Index可選MySQL或PostgreSQL等關系型數據庫,并且其保存的數據是規整的關系數據,僅用于查詢索引,數據量不會很大,因此一般不會出現性能瓶頸。而Measure Storage和Aggregate Storage承載了Gnocchi的大部分的I/O操作,在海量監控數據前,其性能至關重要。Gnocchi官方支持的Measure Storage和Aggregate Storage類型有普通的本地文件File、Ceph、Swift、Amazon S3等,在Gnocchi 4.0版本中還增加了Redis。官方的配置中推薦使用Ceph作為Measure Storage和Aggregate Storage,而在實踐的過程中發現,如果Gnocchi 4.0以下的版本直接使用性能一般的Ceph集群來當作Measure Storage和Aggregate Storage時,在運行一段時間后就可能會出現一些奇怪的性能問題。如圖11,Ceph集群會頻繁地出現OSD ops blocked的警告,甚至出現OSD 自動down的問題:
圖 11
進而查看OSD的日志發現OSD之間有大量的heartbeat check no reply以heartbeat_map出現had timed out的情況:
圖 12
圖 13
在此情況下Ceph集群幾乎在一種不可用狀態,大量的讀寫請求被Blocked,運行在Ceph集群中的虛擬機和Cinder Volume也大量失去了響應,而此時gnocchi-api和gnocchi-metricd日志中也出現大量的rados讀寫Ceph集群超時的錯誤:
圖 14
在此類情況下需要把gnocchi-api和gnocchi-metricd進程退出,并把Ceph中存儲gnocchi數據的pool刪除,待數據重新平衡才可恢復。
通過調試和摸索,發現其原因是Ceph對海量小文件的存儲支持還比較差,尤其是在多副本的情況下儲存Gnocchi的監控數據,其總數據量是成倍的增加,究其原因這還得從Ceph的存儲原理來進行分析。首先需要了解在Ceph中是以Object來儲存文件的,Object的大小由RADOS限定(通常為2MB或者4MB),當文件超過這個容量大小之后就會按照每個Object的容量對文件進行拆分,每個對象都會有一個唯一的OID用于尋址,由ino與ono生成,ino即是文件的File ID,用于在全局唯一標示每一個文件,而ono則是分片的編號。Ceph分割文件為對象后并不會直接將對象存儲進OSD中,因為對象的size很小,在一個大規模的集群中可能有數以億計個對象,這么多對象光是遍歷尋址,速度就已經很緩慢了。因此Ceph中引入PG(Placement Group)的概念,這是一個邏輯上的組,Object通過crush算法映射到一組OSD上,每個PG里包含完整的副本關系,比如3個數據副本分布到一個PG里的3個不同的OSD上。下面引用Ceph論文中的一張圖(圖15)可以比較直觀地理解,將文件按照指定的對象大小分割成多個對象,每個對象根據hash映射到某個PG,然后再根據crush算法映射到后端的某幾個OSD上:
圖 15
不同的對象有可能落到同一個PG里,在Ceph實現里,當PG存在op(operations)時,在OSD的處理線程中就會給PG加鎖,一直到queue_transactions里把事務放到journal的隊列里(以filestore為例)才釋放PG的鎖。從這里可以看出,對于同一個PG里的不同對象,是通過PG鎖來進行并發的控制,好在這個過程中沒有涉及到對象的I/O,效率還是很高的;對于不同PG的對象,可以直接進行并發訪問。
在Ceph中,每一個pool的PG數都是在創建pool的時候根據集群規模大小計算得出的合理值來設置的,也就是說每一個pool里的PG數是有限的。在Gnocchi的監控數據中,每條數據的內容都很小,并且每條監控數據就是一個Object,當海量小文件存到一個PG數量較少的Ceph pool中時,就會出現單個PG中包含太多的Object的情況,雖然PG鎖的效率很高,但是在大量小文件讀寫時依然有可能出現處理不過來的情況,從而就會出現op blocked。
另一方面,OSD端處理op時是將op劃分為多個shard,然后每個shard里可以配置多個線程,PG按照取模的方式映射到不同的shard里進行處理。一般來說,系統給每個OSD配置的處理線程都是比較少的,如果Gnocchi pool的PG在OSD端一直占用大量處理線程,那么其他Ceph pool的 PG的op就會處于等待處理狀態,這時也會出現op blocked的情況,而OSD線程占用嚴重時甚至可能導致OSD進程異常退出。在OSD端,除了將數據寫入磁盤(Filestore)外還需要寫入文件的Extended Attributes (XATTRs)到文件系統或omap(Object Map)中,面對海量的小文件讀寫,OSD的壓力I/O壓力會明顯增重。
因此在Gnocchi中的數據量達到一定程度時,就可能會對Ceph存儲集群產生不利的影響。在出現這種情況下,以下是一些解決的方案:
方案一:在Gnocchi 4.0以下的版本中,使用Swift或本地文件File作為Measure Storage和Aggregate Storage。亦或者使用Swift或本地文件File作為Measure Storage,而Aggregate Storage繼續使用Ceph;因為Measure Storage中保存的是原始的監控數據,數據的文件條目量大并且都是小文件,而Aggregate Storage中保存的是聚合計算后的結果數據,數據量相對較小。但如果Ceph集群的性能不是很好,尤其是Ceph中的OSD數量較少時,并且監控的數據量相對較大,以及需要保存較長一段時間時,不建議使用Ceph。
方案二:升級OpenStack中的Gnocchi版本到4.0及以上,繼續使用Ceph作為Measure Storage和Aggregate Storage。Gnocchi在4.0及之后的版本代碼中做了優化,當使用Ceph作為Measure Storage時,Measure Storage中保存的measures是保存在Ceph OSD的omap中而不是OSD的Object文件,omap中的數據是保存在Leveldb、Rocksdb等數據庫中,所以measures的數據并不會寫到磁盤中,以此緩解OSD的I/O壓力。Aggregate Storage中的數據依然是保存為Ceph的Object文件。但是在小型Ceph集群中,如果監控數據量比較大時,依然會對Ceph集群產生一定的性能影響。
方案三:升級OpenStack中的Gnocchi版本到4.0及以上,使用Redis作為Measure Storage,使用Swift或Ceph作為Aggregate Storage。此方案性能最優,因為Measure Storage中保存的measures文件量大但容量小,measures需要經過gnocchi-api寫入Measure Storage,gnocchi-metricd讀出處理,然后gnocchi-metricd從Measure Storage刪除等步驟。使用Redis這個內存型的數據庫不僅可以解決Measure Storage海量小文件讀寫頻繁的需求,并且內存高速I/O帶寬的優勢使得gnocchi-api和gnocchi-metricd在I/O處理上性能更高,系統并發性能更好。
四、結語
以上對Ceilometer監控數據采集和Gnocchi數據處理的架構和流程作了簡要的分析,并且分析了筆者在將Gnocchi和Ceph存儲結合使用時出現的一些問題,這些問題在出現在生產環境中是非常致命的,不僅導致大規模的業務不可用,甚至還可能導致數據丟失的風險。因此在搭建OpenStack集群時,預先按照集群規模、采集的數據量等等規劃好監控數據的保存方案,對生產環境上線后的穩定性意義深遠。
審核編輯:符乾江
-
智能計算
+關注
關注
0文章
190瀏覽量
16679 -
云平臺
+關注
關注
1文章
1416瀏覽量
40032 -
OpenStack
+關注
關注
1文章
72瀏覽量
19268 -
Ceph
+關注
關注
1文章
24瀏覽量
9527
發布評論請先 登錄
工業設備運行數據采集管理平臺是什么
數據采集網關與工業組態云平臺有什么聯系
海為PLC數據采集遠程監控平臺方案
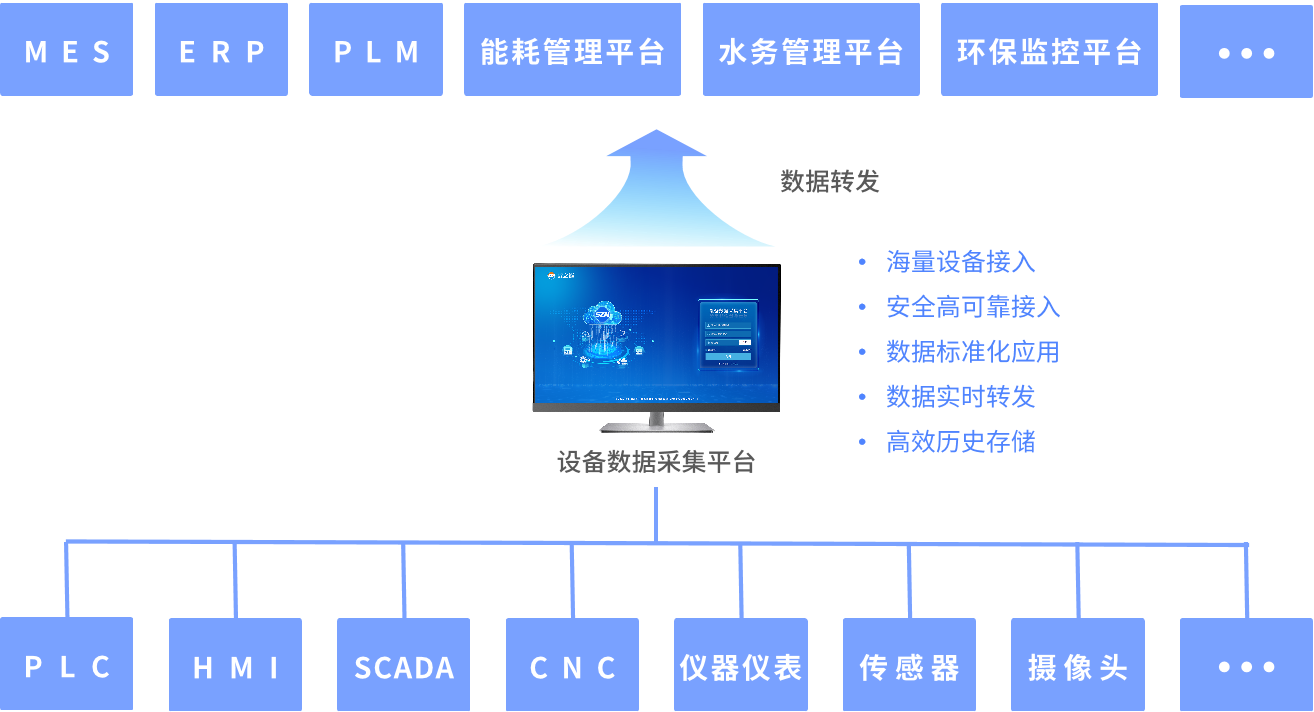
可與MES系統集成的數據采集監控平臺
opc數據采集平臺的應用場景
工控數據采集物聯網平臺是什么
水利數據采集遠程監控平臺是什么
基于工業網關和云平臺的工廠設備數據采集解決方案






 工商網監
工商網監
評論