 三種LM任務形式:單向LM,雙向LM,序列到序列LM
三種LM任務形式:單向LM,雙向LM,序列到序列LM
今天分享一個論文UniLM[1],核心點是掌握三種LM任務形式:單向LM,雙向LM,序列到序列LM;
1. 生成任務
NLP任務大致可以分為NLU和NLG兩種;Bert在NLU任務上效果很好,但是天生不適合處理生成任務。
原因在于Bert的預訓練過程是使用的MLM,和生成任務的目標并不一致。
生成任務目標是每次蹦出來一個詞,只能看到當前位置之前的詞匯。
而Bert采用的是雙向的語言模型,除了mask的單詞,兩個方向的詞匯都可以被看到。
所以對Bert的一個改進思路就是讓它在具有NLU能力的時候,同時兼備NLG能力。
2. 三種LM任務
UniLM做的就是這樣一個事情。
具體的實現方式是設計了一系列的完形填空任務,這些完形填空任務的不同之處在于對上下文的定義。
從左到右的LM:使用mask單詞的左側單詞來預測被遮掩的單詞
從右到左的LM:和上面第一個相比就是方向的變化,使用mask單詞的右側單詞來預測遮掩的單詞
雙向LM:就是當前mask的左右詞匯都可以看到
sequence-to-sequence LM:這個就是UniLM能夠具有生成能力的關鍵。我們的輸入是source句子和target句子,mask單詞在target上,那么當前mask的上下文就是source句子的所有單詞和target句子中mask單詞左側的詞匯可以被看到
我們把從左到右LM和從右到左LM我們歸為一種任務叫單向LM;
有個點需要注意,三個任務是一起優化的,具體來講是這樣做的:
在訓練的時候,1/3的時候使用雙向LM,1/3的時候使用序列到序列 LM,1/6的時候使用從左到右的LM,1/6的時間使用從右到做的LM。
我們是使用不同的Mask矩陣來對應不同任務輸入數據形式。
文中使用的是這樣一張圖來展示:
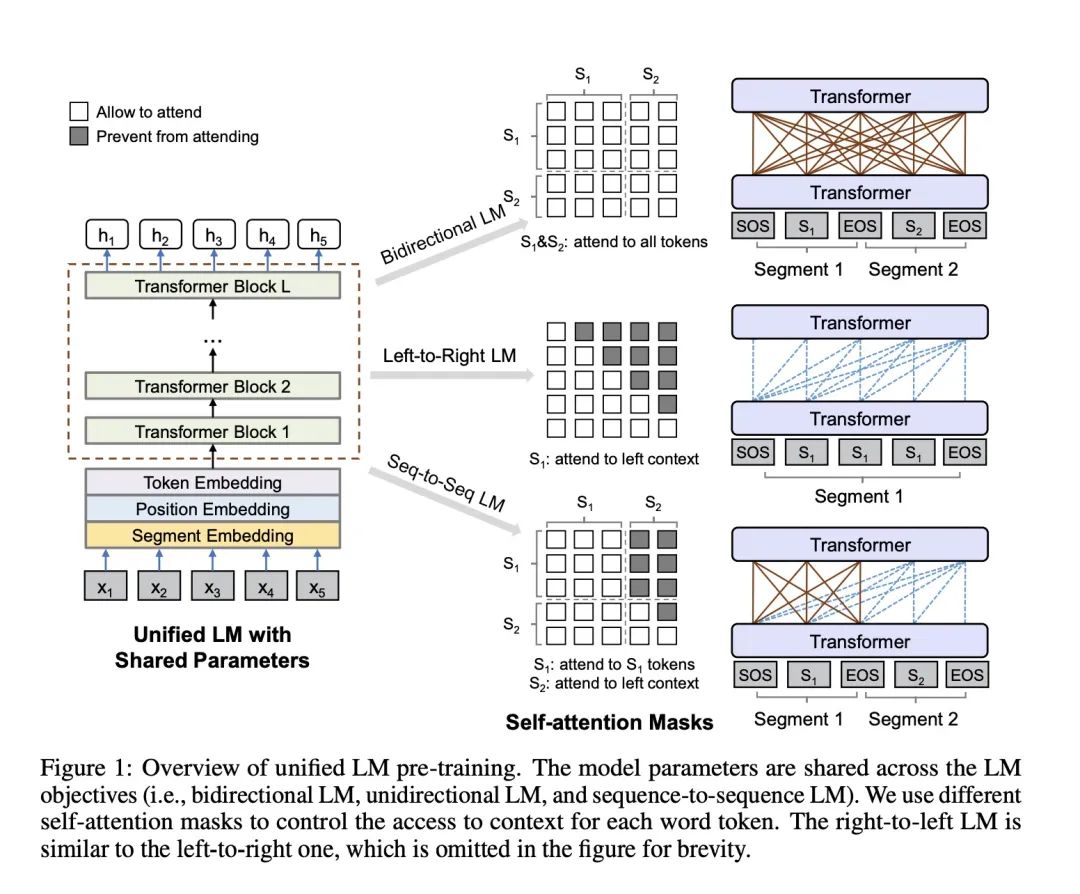
UniLM不同mask
3. 其他細枝末節
Gelu 激勵函數
24層TRM,最大長度512,1024Hidden Size,16Heads,340M參數量
初始化使用Bert Large
15%被mask,其中80%真正替換mask,10%隨機替換,10%不動。替換的時候,80% 的時候替換單個token,20%的時候替換bigram 或者 trigram
第四個步驟類似中文實體詞的mask,也算是一點改進。
有個細節點需要注意的是,作者強調,不同的segment embedding用來區分不同LM任務。
Bert的時候,區分上下句子,我們使用0和1,在這里,我們使用這個segment embedding用來區分任務:
比如說,雙向對應0和1;單向left-right對應2;單向right-left對應3;序列對應4和5;
4. 總結
掌握以下幾個細節點就可以:
聯合訓練三種任務:單向LM,雙向LM,序列LM
segment embedding可以區分不同的任務形式
mask的時候15% 的有被替換的概率,其中80% 被真正替換。在這80%真正替換的里面有80%單個token被替換,20%的二元或者三元tokens被替換
參考資料
[1]
Unified Language Model Pre-training for Natural Language Understanding and Generation: https://arxiv.org/pdf/1905.03197.pdf,
責任編輯:xj
原文標題:如何讓BERT具有文本生成能力
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
自然語言
+關注
關注
1文章
291瀏覽量
13615 -
nlp
+關注
關注
1文章
490瀏覽量
22524
原文標題:如何讓BERT具有文本生成能力
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
LM5171 80V 雙通道雙向降壓-升壓控制器數據手冊
LM74700DDFEVM:適用于LM74700-Q1的評估模塊

LM74502EVM:LM74502和LM74502H理想二極管控制器評估模塊
LM74502Q1EVM:適用于LM74502-Q1和LM74502H-Q1理想二極管的評估模塊
LM74704Q1EVM、LM74703-Q1、LM74704-Q1理想二極管控制器評估模塊
如何使用 LM5157x、LM5158x 設計升壓轉換器
如何使用LM5157x/LM5158x設計隔離型反激式轉換器
LM339能用LM324代替嗎
LM324D和LM324KADR有什么不同?
LM12454/LM12458/LM12H458 12位符號數據采集系統數據表





 工商網監
工商網監
評論