") 關(guān)于多標(biāo)簽學(xué)習(xí)的新趨勢
關(guān)于多標(biāo)簽學(xué)習(xí)的新趨勢

這里大家?guī)硪黄浯髣⑼蠋煛⒛侠砉ど蛐げɡ蠋熀?UTS Ivor W. Tsang 老師合作的 2020 年多標(biāo)簽最新的 Survey,我也有幸參與其中,負(fù)責(zé)了一部分工作。
上半年在知乎上看到有朋友咨詢多標(biāo)簽學(xué)習(xí)是否有新的 Survey,我搜索了一下,發(fā)現(xiàn)現(xiàn)有的多標(biāo)簽 Survey 基本在 2014 年之前,主要有以下幾篇:
Tsoumakas 的《Multi-label classification: An overview》(2007)
周志華老師的《A review on multi-label learning algorithms》(2013)
一篇比較小眾的,Gibaja 《Multi‐label learning: a review of the state of the art and ongoing research》2014
時過境遷,從 2012 年起,AI 領(lǐng)域已經(jīng)發(fā)生了翻天覆地的變化,Deep Learning 已經(jīng)占據(jù)絕對的主導(dǎo)地位,我們面對的問題越來越復(fù)雜,CV 和 NLP 朝著各自的方向前行。模型越來越強,我們面對的任務(wù)的也越來越復(fù)雜,其中,我們越來越多地需要考慮高度結(jié)構(gòu)化的輸出空間。多標(biāo)簽學(xué)習(xí),作為一個傳統(tǒng)的機器學(xué)習(xí)任務(wù),近年來也擁抱變化,有了新的研究趨勢。因此,我們整理了近年多標(biāo)簽學(xué)習(xí)在各大會議的工作,希望能夠為研究者們提供更具前瞻性的思考。
關(guān)于單標(biāo)簽學(xué)習(xí)和多標(biāo)簽學(xué)習(xí)的區(qū)別,這里簡單給個例子:傳統(tǒng)的圖片單標(biāo)簽分類考慮識別一張圖片里的一個物體,例如 ImageNet、CIFAR10 等都是如此,但其實圖片里往往不會只有一個物體,大家隨手往自己的桌面拍一張照片,就會有多個物體,比如手機、電腦、筆、書籍等等。在這樣的情況下,單標(biāo)簽學(xué)習(xí)的方法并不適用,因為輸出的標(biāo)簽可能是結(jié)構(gòu)化的、具有相關(guān)性的(比如鍵盤和鼠標(biāo)經(jīng)常同時出現(xiàn)),所以我們需要探索更強的多標(biāo)簽學(xué)習(xí)算法來提升學(xué)習(xí)性能。
本文的主要內(nèi)容有六大部分:
Extreme Multi-Label Classification
Multi-Label with Limited Supervision
Deep Multi-Label Classification
Online Multi-Label Classification
Statistical Multi-Label Learning
New Applications
接下去我們對這些部分進行簡單的介紹,更多細(xì)節(jié)大家也可以進一步閱讀 Survey 原文。另外,由于現(xiàn)在的論文迭代很快,我們無法完全 Cover 到每篇工作。我們的主旨是盡量保證收集的工作來自近年已發(fā)表和錄用的、高質(zhì)量的期刊或會議,保證對當(dāng)前工作的整體趨勢進行把握。如果讀者有任何想法和意見的話,也歡迎私信進行交流。 1. Extreme Multi-Label Learning (XML) 在文本分類,推薦系統(tǒng),Wikipedia,Amazon 關(guān)鍵詞匹配 [1] 等等應(yīng)用中,我們通常需要從非常巨大的標(biāo)簽空間中召回標(biāo)簽。比如,很多人會 po 自己的自拍到 FB、Ins 上,我們可能希望由此訓(xùn)練一個分類器,自動識別誰出現(xiàn)在了某張圖片中。
對 XML 來說,首要的問題就是標(biāo)簽空間、特征空間都可能非常巨大,例如 Manik Varma 大佬的主頁中給出的一些數(shù)據(jù)集[2],標(biāo)簽空間的維度甚至遠(yuǎn)高于特征維度。其次,由于如此巨大的標(biāo)簽空間,可能存在較多的 Missing Label(下文會進一步闡述)。最后,標(biāo)簽存在長尾分布[3],絕大部分標(biāo)簽僅僅有少量樣本關(guān)聯(lián)。現(xiàn)有的 XML 方法大致可以分為三類,分別為:Embedding Methods、Tree-Based Methods、One-vs-All Methods。近年來,也有很多文獻使用了深度學(xué)習(xí)技術(shù)解決 XML 問題,不過我們將會在 Section 4 再進行闡述。XML 的研究熱潮大概從 2014 年開始,Varma 大佬搭建了 XML 的 Repository 后,已經(jīng)有越來越多的研究者開始關(guān)注,多年來 XML 相關(guān)的文章理論和實驗結(jié)果并重,值得更多的關(guān)注。
2. Multi-Label with Limited Supervision 相比于傳統(tǒng)學(xué)習(xí)問題,對多標(biāo)簽數(shù)據(jù)的標(biāo)注十分困難,更大的標(biāo)簽空間帶來的是更高的標(biāo)注成本。隨著我們面對的問題越來越復(fù)雜,樣本維度、數(shù)據(jù)量、標(biāo)簽維度都會影響標(biāo)注的成本。因此,近年多標(biāo)簽的另一個趨勢是開始關(guān)注如何在有限的監(jiān)督下構(gòu)建更好的學(xué)習(xí)模型。本文將這些相關(guān)的領(lǐng)域主要分為三類: MLC with Missing Labels(MLML):多標(biāo)簽問題中,標(biāo)簽很可能是缺失的。例如,對 XML 問題來說,標(biāo)注者根本不可能遍歷所有的標(biāo)簽,因此標(biāo)注者通常只會給出一個子集,而不是給出所有的監(jiān)督信息。文獻中解決該問題的技術(shù)主要有基于圖的方法、基于標(biāo)簽空間(或 Latent 標(biāo)簽空間)Low-Rank 的方法、基于概率圖模型的方法。
Semi-Supervised MLC:MLML 考慮的是標(biāo)簽維度的難度,但是我們知道從深度學(xué)習(xí)需要更多的數(shù)據(jù),在樣本量上,多標(biāo)簽學(xué)習(xí)有著和傳統(tǒng) AI 相同的困難。半監(jiān)督 MLC 的研究開展較早,主要技術(shù)和 MLML 也相對接近,在這一節(jié),我們首先簡要回顧了近年半監(jiān)督 MLC 的一些最新工作。但是,近年來,半監(jiān)督 MLC 開始有了新的挑戰(zhàn),不少文章開始結(jié)合半監(jiān)督 MLC 和 MLML 問題。畢竟對于多標(biāo)簽數(shù)據(jù)量來說,即使標(biāo)注少量的 Full Supervised 數(shù)據(jù),也是不可接受的。因此,許多文章開始研究一類弱監(jiān)督多標(biāo)簽問題[4](Weakly-Supervised MLC,狹義),也就是數(shù)據(jù)集中可能混雜 Full labeled/missing labels/unlabeled data。我們也在文中重點介紹了現(xiàn)有的一些 WS-MLC 的工作。
Partial Multi-Label Learning(PML):PML 是近年來多標(biāo)簽最新的方向,它考慮的是一類 “難以標(biāo)注的問題”。比如,在我們標(biāo)注下方的圖片(Zhang et. al. 2020[5])的時候,諸如 Tree、Lavender 這些標(biāo)簽相對是比較簡單的。但是有些標(biāo)簽到底有沒有,是比較難以確定的,對于某些標(biāo)注者,可能出現(xiàn):“這張圖片看起來是在法國拍的,好像也可能是意大利?”。這種情況稱之為 Ambiguous。究其原因,一是有些物體確實難以辨識,第二可能是標(biāo)注者不夠?qū)I(yè)(這種多標(biāo)簽的情況,標(biāo)注者不太熟悉一些事物也很正常)。但是,很多情況下,標(biāo)注者是大概能夠猜到正確標(biāo)簽的范圍,比如這張風(fēng)景圖所在國家,很可能就是 France 或者 Italy 中的一個。我們在不確定的情況下,可以選擇不標(biāo)注、或者隨機標(biāo)注。但是不標(biāo)注意味著我們丟失了所有信息,隨機標(biāo)注意味著可能帶來噪聲,對學(xué)習(xí)的影響更大。所以 PML 選擇的是讓標(biāo)注者提供所有可能的標(biāo)簽,當(dāng)然加了一個較強的假設(shè):所有的標(biāo)簽都應(yīng)該被包含在候選標(biāo)簽集中。在 Survey 中,我們將現(xiàn)有的 PML 方法劃分為 Two-Stage Disambiguation 和 End-to-End 方法(我們 IJCAI 2019 的論文 DRAMA[6] 中,就使用了前者)。關(guān)于 PML 的更多探討,我在之前的知乎回答里面也已經(jīng)敘述過,大家也可以在我們的 Survey 中了解更多。
Other Settings:前文說過,多標(biāo)簽學(xué)習(xí)的標(biāo)簽空間紛繁復(fù)雜,因此很多研究者提出了各種各樣不同的學(xué)習(xí)問題,我們也簡單摘要了一些較為前沿的方向:
MLC with Noisy Labels (Noisy-MLC)。
MLC with Unseen Labels. (Streaming Labels/Zero-Shot/Few-Shot Labels)
Multi-Label Active Learning (MLAL)。
MLC with Multiple Instances (MIML)。
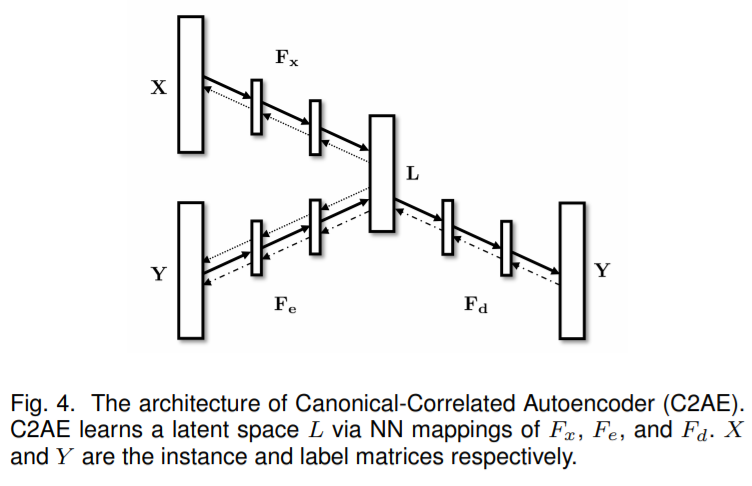
3. Deep Learning for MLC 相信這一部分是大家比較關(guān)心的內(nèi)容,隨著深度學(xué)習(xí)在越來越多的任務(wù)上展現(xiàn)了自己的統(tǒng)治力,多標(biāo)簽學(xué)習(xí)當(dāng)然也不能放過這塊香餑餑。不過,總體來說,多標(biāo)簽深度學(xué)習(xí)的模型還沒有十分統(tǒng)一的框架,當(dāng)前對 Deep MLC 的探索主要分為以下一些類別: Deep Embedding Methods:早期的 Embedding 方法通常使用線性投影,將 PCA、Compressed Sensing 等方法引入多標(biāo)簽學(xué)習(xí)問題。一個很自然的問題是,線性投影真的能夠很好地挖掘標(biāo)簽之間的相關(guān)關(guān)系嗎?同時,在 SLEEC[3]的工作中也發(fā)現(xiàn)某些數(shù)據(jù)集并不符合 Low-Rank 假設(shè)。因此,在 2017 年的工作 C2AE[7]中,Yeh 等將 Auto-Encoder 引入了多標(biāo)簽學(xué)習(xí)中。由于其簡單易懂的架構(gòu),很快有許多工作 Follow 了該方法,如 DBPC[8]等。
Deep Learning for Challenging MLC:深度神經(jīng)網(wǎng)絡(luò)強大的擬合能力使我們能夠有效地處理更多更困難的工作。因此我們發(fā)現(xiàn)近年的趨勢是在 CV、NLP 和 ML 幾大 Community,基本都會有不同的關(guān)注點,引入 DNN 解決 MLC 的問題,并根據(jù)各自的問題發(fā)展出自己的一條線。 1. XML 的應(yīng)用:對這個方面的關(guān)注主要來自與數(shù)據(jù)挖掘和 NLP 領(lǐng)域,其中比較值得一提的是 Attention(如 AttentionXML[9])機制、Transformer-Based Models(如 X-Transformer[10])成為了最前沿的工作。
2. 弱監(jiān)督 MLC 的應(yīng)用:這一部分和我們?nèi)醣O(jiān)督學(xué)習(xí)的部分相對交叉,特別的,CVPR 2019 的工作 [11] 探索了多種策略,在 Missing Labels 下訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)。 DL for MLC with unseen labels:這一領(lǐng)域的發(fā)展令人興奮,今年 ICML 的工作 DSLL[12]探索了流標(biāo)簽學(xué)習(xí),也有許多工作 [13] 將 Zero-Shot Learning 的架構(gòu)引入 MLC。 3. Advanced Deep Learning for MLC:有幾個方向的工作同樣值得一提。首先是 CNN-RNN[14]架構(gòu)的工作,近年有一個趨勢是探索 Orderfree 的解碼器 [15]。除此之外,爆火的圖神經(jīng)網(wǎng)絡(luò) GNN 同樣被引入 MLC,ML-GCN[16] 也是備受關(guān)注。特別的,SSGRL[17]是我比較喜歡的一篇工作,結(jié)合了 Attention 機制和 GNN,motivation 比較強,效果也很不錯。 總結(jié)一下,現(xiàn)在的 Deep MLC 呈現(xiàn)不同領(lǐng)域關(guān)注點和解決的問題不同的趨勢:
從架構(gòu)上看,基于Embedding、CNN-RNN、CNN-GNN的三種架構(gòu)受到較多的關(guān)注。
從任務(wù)上,在XML、弱監(jiān)督、零樣本的問題上,DNN 大展拳腳。
從技術(shù)上,Attention、Transformer、GNN在 MLC 上的應(yīng)用可能會越來越多。
4. Online Multi-Label Learning 面對當(dāng)前這么復(fù)雜而眾多的學(xué)習(xí)問題,傳統(tǒng)的全數(shù)據(jù)學(xué)習(xí)的方式已經(jīng)很難滿足我們現(xiàn)實應(yīng)用的需求了。因此,我們認(rèn)為 Online Multi-Label Learning 可能是一個十分重要,也更艱巨的問題。當(dāng)前 Off-line 的 MLC 模型一般假設(shè)所有數(shù)據(jù)都能夠提前獲得,然而在很多應(yīng)用中,或者對大規(guī)模的數(shù)據(jù),很難直接進行全量數(shù)據(jù)的使用。一個樸素的想法自然是使用 Online 模型,也就是訓(xùn)練數(shù)據(jù)序列地到達(dá),并且僅出現(xiàn)一次。然而,面對這樣的數(shù)據(jù),如何有效地挖掘多標(biāo)簽相關(guān)性呢?本篇 Survey 介紹了一些已有的在線多標(biāo)簽學(xué)習(xí)的方法,如 OUC[18]、CS-DPP[19]等。在弱監(jiān)督學(xué)習(xí)的部分,我們也回顧了近年一些在線弱監(jiān)督多標(biāo)簽的文章[20](在線弱監(jiān)督學(xué)習(xí)一直是一個很困難的問題)。
Online MLC 的工作不多,但是已經(jīng)受到了越來越多的關(guān)注,想要設(shè)計高效的學(xué)習(xí)算法并不簡單,希望未來能夠有更多研究者對這個問題進行探索。 5. Statistical Multi-Label Learning 近年,盡管深度學(xué)習(xí)更強勢,但傳統(tǒng)的機器學(xué)習(xí)理論也在穩(wěn)步發(fā)展,然而,多標(biāo)簽學(xué)習(xí)的許多統(tǒng)計性質(zhì)并沒有得到很好的理解。近年 NIPS、ICML 的許多文章都有探索多標(biāo)簽的相關(guān)性質(zhì)。一些值得一提的工作例如,缺失標(biāo)簽下的低秩分類器的泛化誤差分析 [21]、多標(biāo)簽代理損失的相合性質(zhì)[22]、稀疏多標(biāo)簽學(xué)習(xí)的 Oracle 性質(zhì)[23] 等等。相信在未來,會有更多工作探索多標(biāo)簽學(xué)習(xí)的理論性質(zhì)。
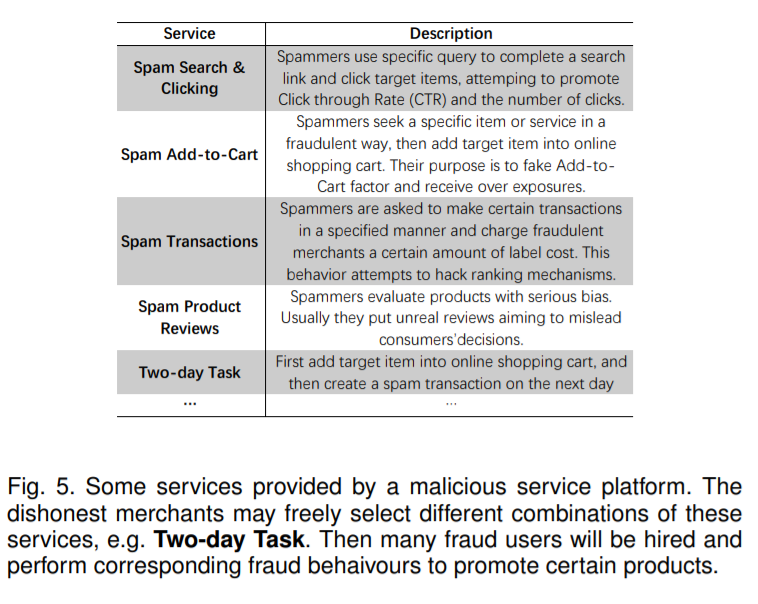
6. New Applications 講了這么多方法論,但追溯其本源,這么多紛繁復(fù)雜的問題依然是由任務(wù)驅(qū)動的,正是有許許多多現(xiàn)實世界的應(yīng)用,要求我們設(shè)計不同的模型來解決尺度更大、監(jiān)督更弱、效果更強、速度更快、理論性質(zhì)更強的 MLC 模型。因此,在文章的最后一部分,我們介紹了近年多標(biāo)簽領(lǐng)域一些最新的應(yīng)用,如 Video Annotation、Green Computing and 5G Applications、User Profiling 等。在 CV 方向,一個趨勢是大家開始探索多標(biāo)簽領(lǐng)域在視頻中的應(yīng)用 [24]。在 DM 領(lǐng)域,用戶畫像受到更多關(guān)注,在我們今年的工作 CMLP[25] 中(下圖),就探索了對刷單用戶進行多種刷單行為的分析。不過,在 NLP 領(lǐng)域,似乎大家還是主要以文本分類為主,XML-Repo[2]中的應(yīng)用還有較多探索的空間,所以我們沒有花額外的筆墨。
總結(jié) 寫這篇文章的過程中,我跟著幾位老師閱讀了很多文章,各個領(lǐng)域和方向的工作都整理了不少,盡管無法 cover 到所有工作,但是我們盡可能地把握了一些較為重要的探索的方向,也在文中較為謹(jǐn)慎地給出了一些我們的思考和建議,希望能夠給想要了解多標(biāo)簽學(xué)習(xí)領(lǐng)域的研究者一點引領(lǐng)和思考。
原文標(biāo)題:多標(biāo)簽學(xué)習(xí)的新趨勢(2020 Survey)
文章出處:【微信公眾號:通信信號處理研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4812瀏覽量
103240 -
AI
+關(guān)注
關(guān)注
88文章
34810瀏覽量
277293 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122666
原文標(biāo)題:多標(biāo)簽學(xué)習(xí)的新趨勢(2020 Survey)
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
友商跟進,共創(chuàng)一體化直流電能表新趨勢

云里物里推出全新多按鍵倉儲標(biāo)簽
NXP eIQ Time Series Studio 工具使用攻略(九)-數(shù)據(jù)標(biāo)簽
佛瑞亞談汽車產(chǎn)業(yè)發(fā)展的新趨勢與新機遇
2025車展,電機新趨勢

美能光伏亮相 SolarEX Istanbul 2025 共探光伏檢測技術(shù)新趨勢

智慧路燈綜合桿:賦能低空經(jīng)濟, 解鎖無人機場,化身低空雷達(dá),護航“空中衛(wèi)士”引領(lǐng)智慧城市新趨勢
2024世界物聯(lián)網(wǎng)大會:IOT研發(fā)的新趨勢和PLM系統(tǒng)使用
測徑儀控制軟件 趨勢圖報表一個不能少
多通道開關(guān)濾波器的創(chuàng)新者,引領(lǐng)電磁兼容技術(shù)新趨勢
多家企業(yè)將匯聚深圳,共商電機新趨勢!

光伏電站無人機智慧巡檢新趨勢
無線液位監(jiān)測技術(shù)在智能化時代的應(yīng)用新趨勢
揭秘未來辦公新趨勢:樓宇自控系統(tǒng)的智能進化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論