 一文讓你徹底搞懂計算機網絡層
一文讓你徹底搞懂計算機網絡層
前面我們學習了運輸層如何為客戶端和服務器輸送數據的,提供進程端到端的通信。那么下面我們將學習網絡層實際上是怎樣實現主機到主機的通信服務的。幾乎每個端系統都有網絡層這一部分。所以,網絡層必然是很復雜的。下面我將花費大量篇幅來介紹一下計算機網絡層的知識。
網絡層概述
網絡層是 OSI 參考模型的第三層,它位于傳輸層和鏈路層之間,網絡層的主要目的是實現兩個端系統之間透明的數據傳輸。
網絡層的作用從表面看上去非常簡單,即將分組從一臺主機移動到另外一臺主機。為了實現這個功能,網絡層需要兩種功能
轉發:因為在互聯網中有很多路由器的存在,而路由器是構成互聯網的根本,路由器最重要的一個功能就是分組轉發,當一個分組到達某路由器的一條輸入鏈路時,該路由器會將分組移動到適當的輸出鏈路。轉發是在數據平面中實現的唯一功能。
在網絡中存在兩種平面的選擇
數據平面(data plane):負責轉發網絡流量,如路由器交換機中的轉發表(我們后面會說)。
控制平面(control plane):控制網絡的行為,比如網絡路徑的選擇。
路由選擇:當分組由發送方流向接收方時,網絡層必須選擇這些分組的路徑。計算這些路徑選擇的算法被稱為路由選擇算法(routing algorithm)。
也就是說,轉發是指將分組從一個輸入鏈路轉移到適當輸出鏈路接口的路由器本地動作。而路由選擇是指確定分組從源到目的地所定位的路徑的選擇。我們后面會經常提到轉發和路由選擇這兩個名詞。
那么此處就有一個問題,路由器怎么知道有哪些路徑可以選擇呢?
每臺路由器都有一個關鍵的概念就是轉發表(forwarding table)。路由器通過檢查數據包標頭中字段的值,來定位轉發表中的項來實現轉發。標頭中的值即對應著轉發表中的值,這個值指出了分組將被轉發的路由器輸出鏈路。如下圖所示
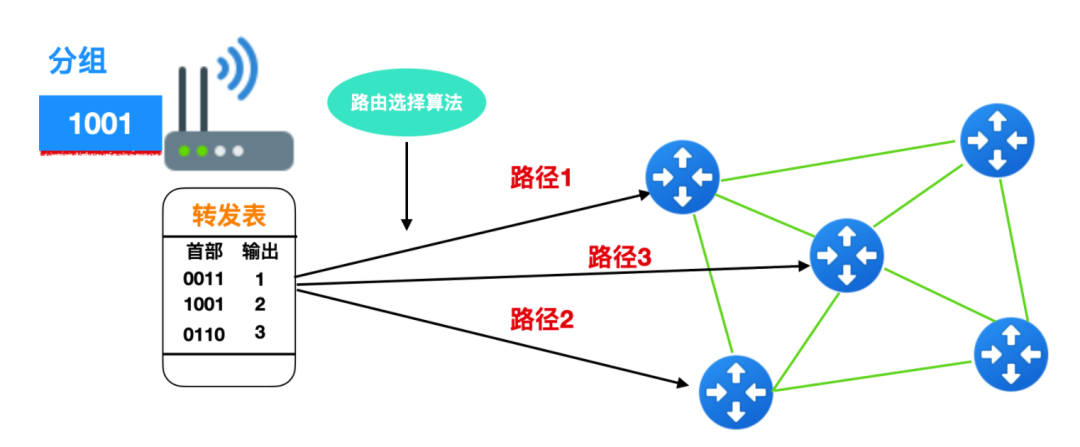
上圖中有一個 1001 分組到達路由器后,首先會在轉發表中進行索引,然后由路由選擇算法決定分組要走的路徑。每臺路由器都有兩種功能:轉發和路由選擇。下 面我們就來聊一聊路由器的工作原理。
路由器工作原理
下面是一個路由器體系結構圖,路由器主要是由 4 個組件構成的
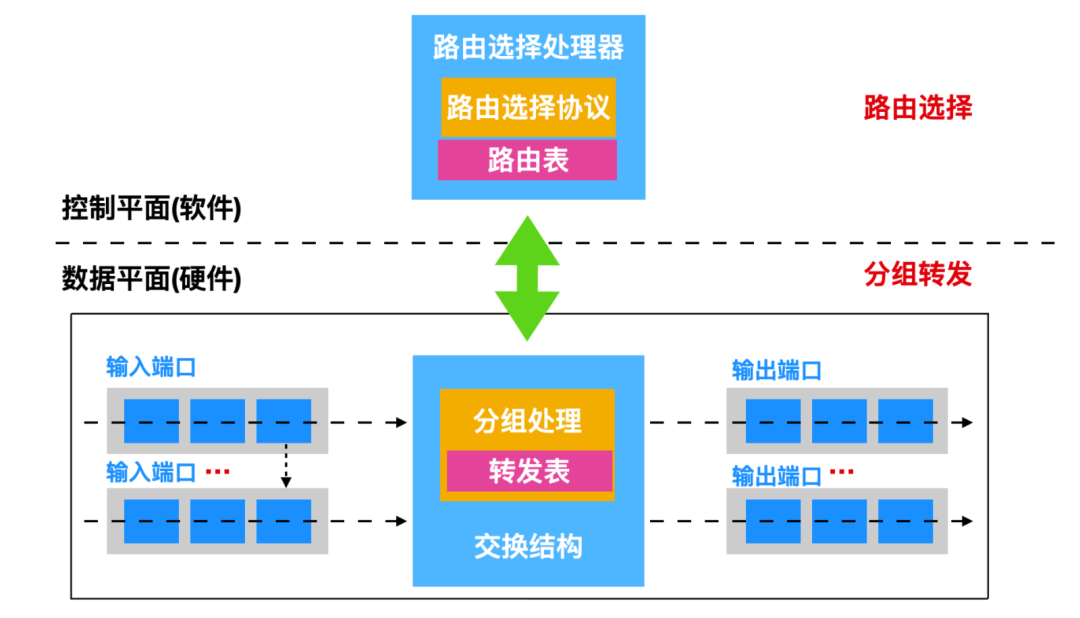
輸入端口:輸入端口(input port)有很多功能。線路終端功能和數據鏈路處理功能,這兩個功能實現了路由器的單個輸入鏈路相關聯的物理層和數據鏈路層。輸入端口查找/轉發功能對路由器的交換功能來說至關重要,由路由器的交換結構來決定輸出端口,具體來講應該是查詢轉發表來確定的。
交換結構:交換結構(Switching fabric)就是將路由器的輸入端口連接到它的輸出端口。這種交換結構相當于是路由器內部的網絡。
輸出端口:輸出端口(Output ports)通過交換結構轉發分組,并通過物理層和數據鏈路層的功能傳輸分組,因此,輸出端口作為輸入端口執行反向數據鏈接和物理層功能。
路由選擇處理器:路由選擇處理器(Routing processor)在路由器內執行路由協議,維護路由表并執行網絡管理功能。
上面只是這幾個組件的簡單介紹,其實這幾個組件的組成并不像描述的那樣簡單,下面我們就來深入聊一聊這幾個組件。
輸入端口
上面介紹了輸入端口有很多功能,包括線路終端、數據處理、查找轉發,其實這些功能在輸入端口的內部有相應的模塊,輸入端口的內部實現如下圖所示
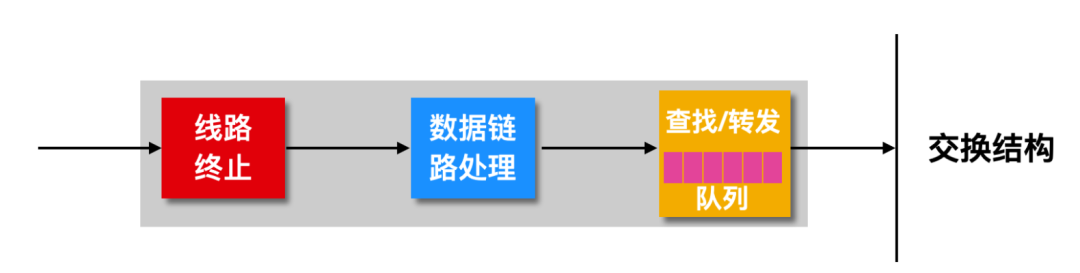
每個輸入端口中都有一個路由處理器維護的路由表的副本,根據路由處理器進行更新。這個路由表的副本能 夠使每個輸入端口進行切換,而無需經過路由處理器統一處理。這是一種分散式的切換,這種方式避免了路 由選擇器統一處理造成轉發瓶頸。
在輸入端口處理能力有限的路由器中,輸入端口不會進行交換功能,而是由路由處理器統一處理,然后根據 路由表查找并將數據包轉發到相應的輸出端口。
一般這種路由器不是單獨的路由器,而是工作站或者服務器充當的路由,這種路由器內部中,路由處理器其實就是CPU,而輸入端口其實只是網卡。
輸入端口會根據轉發表定位輸出端口,然后再會進行分組轉發,那么現在就有一個問題,是不是每一個分組都有自己的一條鏈路呢?如果分組數量非常大,到達億級的話,也會有億個輸出端口路徑嗎?
我們的潛意識中顯然不是的,來看下面一個例子。
下面是三個輸入端口對應了轉發表中的三個輸出鏈路的示例

可以看到,對于這個例子來說,路由器轉發表中不需要那么多條鏈路,只需要四條就夠,即對應輸出鏈路 0 1 2 3 。也就是說,能夠使用 4 個轉發表就可以實現億級鏈路。
如何實現呢?
使用這種風格的轉發表,路由器分組的地址前綴(prefix)會與該表中的表項進行匹配。
如果存在一個匹配項,那么就會轉發到對應的鏈路上,可能不好理解,我舉個例子來說吧。
比如這時有一個分組是 11000011 10010101 00010000 0001100 到達,因為這個分組與 11000011 10010101 00010000 相匹配,所以路由器會轉發到 0 鏈路接口上。如果一個前綴不匹配上面三個輸出鏈路中的一種,那么路由器將向鏈路接口 3 進行轉發。
路由匹配遵循最長前綴原則(longest prefix matching rule),最長匹配原則故名思義就是如果有兩個匹配項一個長一個短的話,就匹配最長的。
一旦通過查找功能確定了分組的輸出端口后,那么該分組就會進入交換結構。在進入交換結構時,如果交換結構正在被使用,就會阻塞新到的分組,等到交換結構調度新的分組。
交換結構
交換結構是路由器的核心功能,通過交換功能把分組從輸入端口轉發至輸出端口,這就是交換結構的主要功能。交換結構有多種形式,主要分為通過內存交換、通過總線交換、通過互聯網絡進行交換,下面我們分開來探討一下。
經過內存交換:最開始的傳統計算機就是使用內存交換的,在輸入端口和輸出端口之間是通過 CPU 進行的。輸入端口和輸出端口的功能就好像傳統操作系統中的 I/O 設備一樣。當一個分組到達輸入端口時,這個端口會首先以中斷的方式向路由選擇器發出信號,將分組從輸入端口拷貝到內存中。然后,路由選擇處理器從分組首部中提取目標地址,在轉發表中找出適當的輸出端口進行轉發,同時將分組復制到輸出端口的緩存中。
這里需要注意一點,如果內存帶寬以每秒讀取或者寫入 B 個數據包,那么總的交換機吞吐量(數據包從輸入端口到輸出端口的總速率) 必須小于 B/2。
經過總線交換:在這種處理方式中,總線經由輸入端口直接將分組傳送到輸出端口,中間不需要路由選擇器的干預。總線的工作流程如下:輸入端口給分組分配一個標簽,然后分組經由總線發送給所有的輸出端口,每個輸出端口都會判斷標簽中的端口和自己的是否匹配,如果匹配的話,那么這個輸出端口就會把標簽拆掉,這個標簽只用于交換機內部跨越總線。如果同時有多個分組到達路由器的話,那么只有一個分組能夠被處理,其他分組需要再進入交換結構前等待。
經過互聯網絡交換:克服單一、共享式總線帶寬限制的一種方法是使用一個更復雜的互聯網絡。如下圖所示
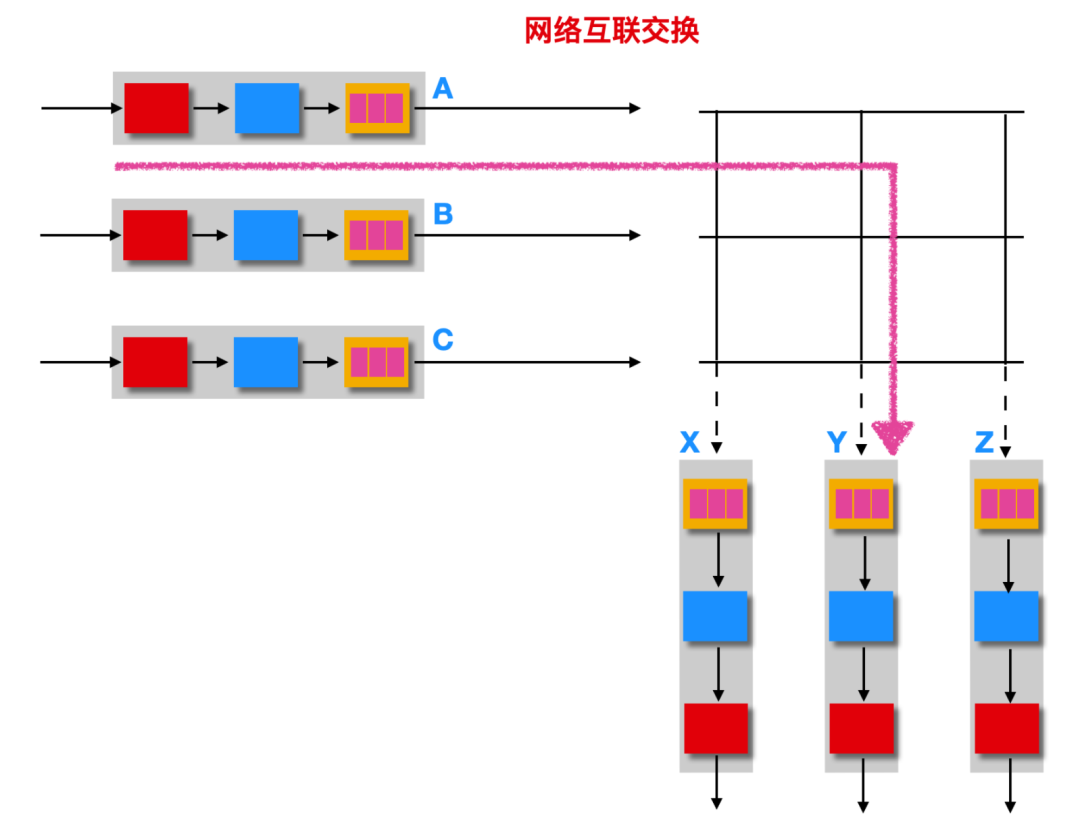
每條垂直的的總線在交叉點與每條水平的總線交叉,交叉點通過交換結構控制器能夠在任何時候開啟和閉合。當分組到達輸入端口 A 時,如果需要轉發到端口 X,交換機控制器會閉合 A 到 X 交叉部分的交叉點,然后端口 A 在總線上進行分組轉發。這種網絡互聯式的交換結構是非阻塞的(non-blocking)的,也就是說 A -> X 的交叉點閉合不會影響 B -> Y 的鏈路。如果來自兩個不同輸入端口的兩個分組其目的地為相同的輸出端口的話,這種情況下只能有一個分組被交換,另外一個分組必須進行等待。
輸出端口處理
如下圖所示,輸出端口處理取出已經存放在輸出端口內存中的分組并將其發送到輸出鏈路上。包括選擇和去除排隊的分組進行傳輸,執行所需的鏈路層和物理層的功能。

在輸入端口中有等待進入交換的排隊隊列,而在輸出端口中有等待轉發的排隊隊列,排隊的位置和程度取決于流量負載、交換結構的相對頻率和線路速率。
隨著隊列的不斷增加,會導致路由器的緩存空間被耗盡,進而使沒有內存可以存儲溢出的隊列,致使分組出現丟包(packet loss),這就是我們說的在網絡中丟包或者被路由器丟棄。
何時出現排隊
下面我們通過輸入端口的排隊隊列和輸出端口的排隊隊列來介紹一下可能出現的排隊情況。
輸入隊列
如果交換結構的處理速度沒有輸入隊列到達的速度快,在這種情況下,輸入端口將會出現排隊情況,到達交換結構前的分組會加入輸入端口隊列中,以等待通過交換結構傳送到輸出端口。
為了描述清楚輸入隊列,我們假設以下情況:
使用網絡互聯的交換方式;
假定所有鏈路的速度相同;
在鏈路中一個分組由輸入端口交換到輸出端口所花的時間相同,從任意一個輸入端口傳送到給定的輸出端口;
分組按照 FCFS 的方式,只要輸出端口不同,就可以進行并行傳送。但是如果位于任意兩個輸入端口中的分組是發往同一個目的地的,那么其中的一個分組將被阻塞,而且必須在輸入隊列中等待,因為交換結構一次只能傳輸一個到指定端口。
如下圖所示
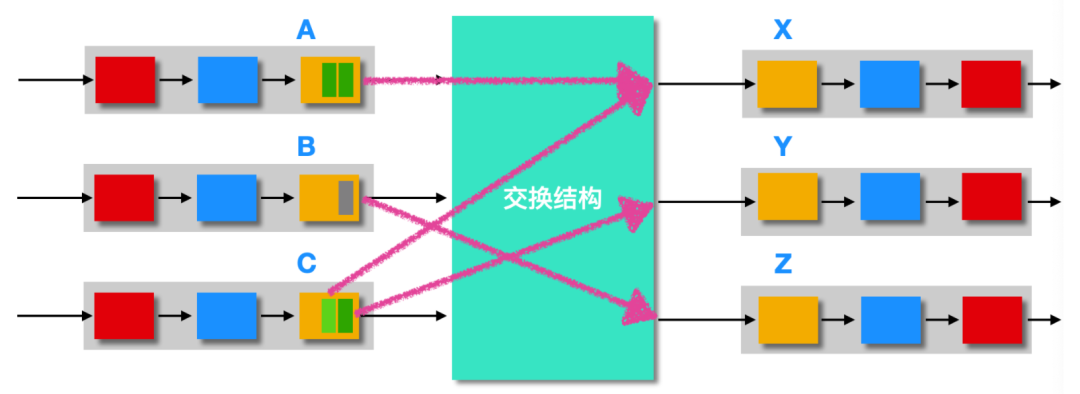
在 A 隊列中,輸入隊列中的兩個分組會發送至同一個目的地 X,假設在交換結構正要發送 A 中的分組,在這個時候,C 隊列中也有一個分組發送至 X,在這種情況下,C 中發送至 X 的分組將會等待,不僅如此,C 隊列中發送至 Y 輸出端口的分組也會等待,即時 Y 中沒有出現競爭的情況。這種現象叫做線路前部阻塞(Head-Of-The-Line, HOL)。
輸出隊列
我們下面討論輸出隊列中出現等待的情況。假設交換速率要比輸入/輸出的傳輸速率快很多,而且有 N 個輸入分組的目的地是轉發至相同的輸出端口。在這種情況下,在向輸出鏈路發送分組的過程中,將會有 N 個新分組到達傳輸端口。因為輸出端口在一個單位時間內只能傳輸一個分組,那么這 N 個分組將會等待。然而在等待 N 個分組被處理的過程中,同時又有 N 個分組到達,所以 ,分組隊列能夠在輸出端口形成。這種情況下最終會因為分組數量變的足夠大,從而耗盡輸出端口的可用內存。
如果沒有足夠的內存來緩存分組的話,就必須考慮其他的方式,主要有兩種:一種是丟失分組,采用棄尾(drop-tail)的方法;一種是刪除一個或多個已經排隊的分組,從而來為新的分組騰出空間。
網絡層的策略對 TCP 擁塞控制影響很大的就是路由器的分組丟棄策略。在最簡單的情況下,路由器的隊列通常都是按照 FCFS 的規則處理到來的分組。由于隊列長度總是有限的,因此當隊列已經滿了的時候,以后再到達的所有分組(如果能夠繼續排隊,這些分組都將排在隊列的尾部)將都被丟棄。這就叫做尾部丟棄策略。
通常情況下,在緩沖填滿之前將其丟棄是更好的策略。
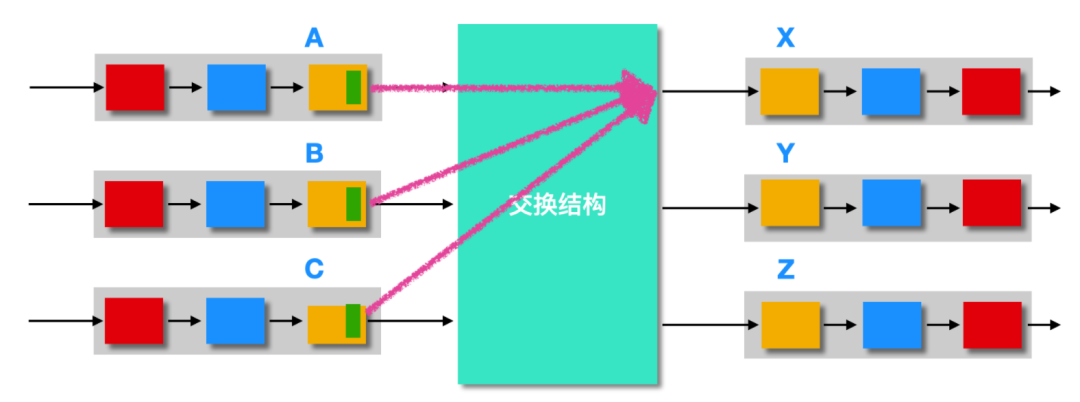
如上圖所示,A B C 每個輸入端口都到達了一個分組,而且這個分組都是發往 X 的,同一時間只能處理一個分組,然后這時,又有兩個分組分別由 A B 發往 X,所以此時有 4 個分組在 X 中進行等待。
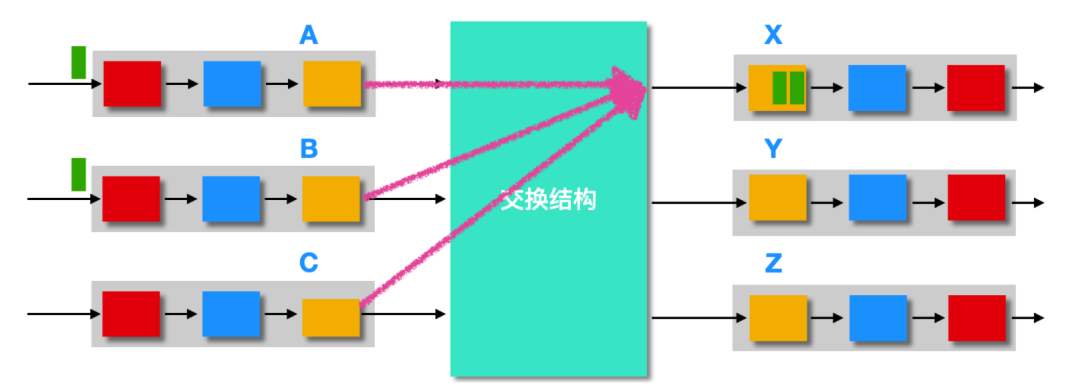
等上一個分組被轉發完成后,輸出端口就會選擇在剩下的分組中根據分組調度(packet scheduleer)選擇一個分組來進行傳輸,我們下面就會聊到分組傳輸。
分組調度
現在我們來討論一下分組調度次序的問題,即排隊的分組如何經輸出鏈路傳輸的問題。我們生活中有無數排隊的例子,但是我們生活中一般的排隊算法都是先來先服務(FCFS),也是先進先出(FIFO)。
先進先出
先進先出就映射為數據結構中的隊列,只不過它現在是鏈路調度規則的排隊模型。
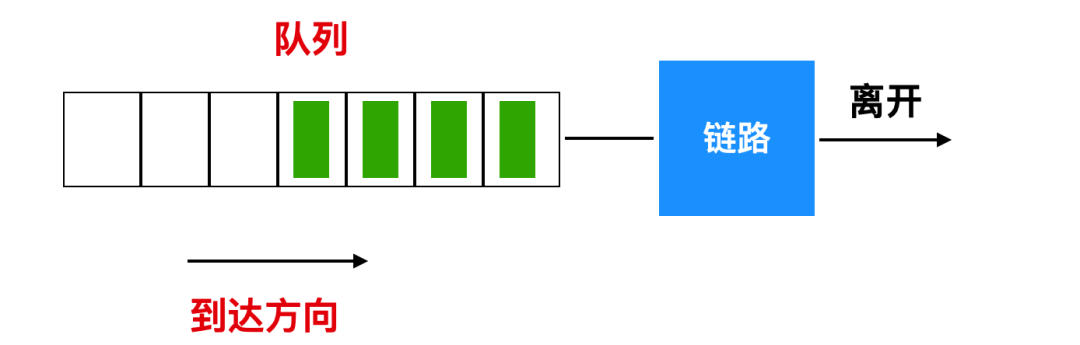
FIFO 調度規則按照分組到達輸出鏈路隊列的相同次序來選擇分組,先到達隊列的分組將先會被轉發。在這種抽象模型中,如果隊列已滿,那么棄尾的分組將是隊列末尾的后面一個。
優先級排隊
優先級排隊是先進先出排隊的改良版本,到達輸出鏈路的分組被分類放入輸出隊列中的優先權類,如下圖所示
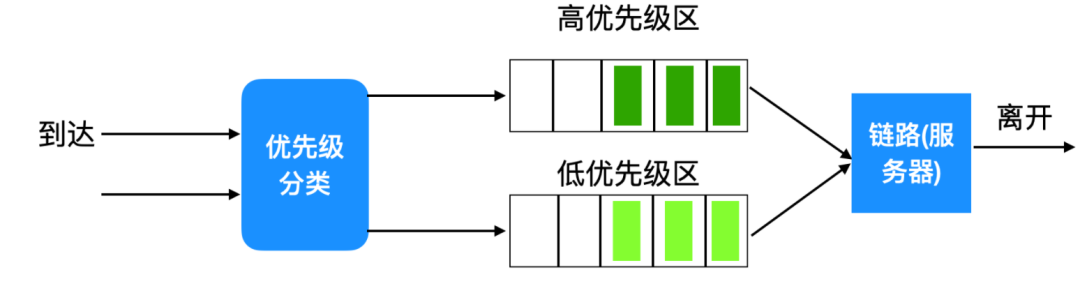
通常情況下,每個優先級不同的分組有自己的優先級類,每個優先級類有自己的隊列,分組傳輸會首先從優先級高的隊列中進行,在同一類優先級的分組之間的選擇通常是以 FIFO 的方式完成。
循環加權公平排隊
在循環加權公平規則(round robin queuing discipline)下,分組像使用優先級那樣被分類。然而,在類之間卻不存在嚴格的服務優先權。循環調度器在這些類之間循環輪流提供服務。如下圖所示

在循環加權公平排隊中,類 1 的分組被傳輸,接著是類 2 的分組,最后是類 3 的分組,這算是一個循環,然后接下來又重新開始,又從 1 -> 2 -> 3 這個順序進行輪詢。每個隊列也是一個先入先出的隊列。
這是一種所謂的保持工作排隊(work-conserving queuing)的規則,就是說如果輪詢的過程中發現有空隊列,輸出端口不會等待分組,而是繼續輪詢下面的隊列。
IP 協議
路由器對分組進行轉發后,就會把數據包傳到網絡上,數據包最終是要傳遞到客戶端或者服務器上的,那么數據包怎么知道要發往哪里呢?起到關鍵作用的就是 IP 協議。
IP 主要分為三個部分,分別是IP 尋址、路由和分包組包。下面我們主要圍繞這三點進行闡述。
IP 地址
既然一個數據包要在網絡上傳輸,那么肯定需要知道這個數據包到底發往哪里,也就是說需要一個目標地址信息,IP 地址就是連接網絡中的所有主機進行通信的目標地址,因此,在網絡上的每個主機都需要有自己的 IP 地址。
在 IP 數據報發送的鏈路中,有可能鏈路非常長,比如說由中國發往美國的一個數據報,由于網絡抖動等一些意外因素可能會導致數據報丟失,這時我們在這條鏈路中會放入一些中轉站,一方面能夠確保數據報是否丟失,另一方面能夠控制數據報的轉發,這個中轉站就是我們前面聊過的路由器,這個轉發過程就是路由控制。
路由控制(Routing)是指將分組數據發送到最終目標地址的功能,即使網絡復雜多變,也能夠通過路由控制到達目標地址。因此,一個數據報能否到達目標主機,關鍵就在于路由器的控制。
這里有一個名詞,就是跳,因為在一條鏈路中可能會布滿很多路由器,路由器和路由器之間的數據報傳送就是跳,比如你和隔壁老王通信,中間就可能會經過路由器 A-> 路由器 B -> 路由器 C 。
那么一跳的范圍有多大呢?
一跳是指從源 MAC 地址到目標 MAC 地址之間傳輸幀的區間,這里引出一個新的名詞,MAC 地址是啥?
MAC 地址指的就是計算機的物理地址(Physical Address),它是用來確認網絡設備位置的地址。在 OSI 網絡模型中,網絡層負責 IP 地址的定位,而數據鏈路層負責 MAC 地址的定位。MAC 地址用于在網絡中唯一標示一個網卡,一臺設備若有一或多個網卡,則每個網卡都需要并會有一個唯一的 MAC 地址,也就是說 MAC 地址和網卡是緊密聯系在一起的。
路由器的每一跳都需要詢問當前中轉的路由器,下一跳應該跳到哪里,從而跳轉到目標地址。而不是數據報剛開始發送后,網絡中所有的通路都會顯示出來,這種多次跳轉也叫做多跳路由。
IP 地址定義
現如今有兩個版本的 IP 地址,IPv4 和 IPv6,我們首先探討一下現如今還在廣泛使用的 IPv4 地址,后面再考慮 IPv6 。
IPv4 由 32 位正整數來表示,在計算機內部會轉化為二進制來處理,但是二進制不符合人類閱讀的習慣,所以我們根據易讀性的原則把 32 位的 IP 地址以 8 位為一組,分成四組,每組之間以.進行分割,再將每組轉換為十進制數。如下圖所示
那么上面這個 32 位的 IP 地址就會被轉換為十進制的 156.197.1.1。
除此之外,從圖中我們還可以得到如下信息
每個這樣 8 位位一組的數字,自然是非負數,其取值范圍是 [0,255]。
IP 地址的總個數有 2^32 次冪個,這個數值算下來是4294967296,大概能允許 43 億臺設備連接到網絡。實際上真的如此嗎?
實際上 IP 不會以主機的個數來配置的,而是根據設備上的網卡(NIC)進行配置,每一塊網卡都會設置一個或者多個 IP 地址,而且通常一臺路由器會有至少兩塊網卡,所以可以設置兩個以上的 IP 地址,所以主機的數量遠遠達不到 43 億。
IP 地址構造和分類
IP 地址由網絡標識和主機標識兩部分組成,網絡標識代表著網絡地址,主機標識代表著主機地址。網絡標識在數據鏈路的每個段配置不同的值。網絡標識必須保證相互連接的每個段的地址都不重復。而相同段內相連的主機必須有相同的網絡地址。IP 地址的主機標識則不允許在同一網段內重復出現。
舉個例子來說:比如說我在石家莊(好像不用比如昂),我所在的小區的某一棟樓就相當于是網絡標識,某一棟樓的第幾戶就相當于是我的主機標識,當然如果你有整棟樓的話,那就當我沒說。你可以通過xx省xx市xx區xx路xx小區xx棟來定位我的網絡標識,這一棟的第幾戶就相當于是我的網絡標識。
IP 地址分為四類,分別是A類、B類、C類、D類、E類,它會根據 IP 地址中的第 1 位到第 4 位的比特對網絡標識和主機標識進行分類。
A 類:(1.0.0.0 - 126.0.0.0)(默認子網掩碼:255.0.0.0 或 0xFF000000)第一個字節為網絡號,后三個字節為主機號。該類 IP 地址的最前面為 0 ,所以地址的網絡號取值于 1~126 之間。一般用于大型網絡。
B 類:(128.0.0.0 - 191.255.0.0)(默認子網掩碼:255.255.0.0 或 0xFFFF0000)前兩個字節為網絡號,后兩個字節為主機號。該類 IP 地址的最前面為 10 ,所以地址的網絡號取值于 128~191 之間。一般用于中等規模網絡。
C 類:(192.0.0.0 - 223.255.255.0)(子網掩碼:255.255.255.0 或 0xFFFFFF00)前三個字節為網絡號,最后一個字節為主機號。該類 IP 地址的最前面為 110 ,所以地址的網絡號取值于 192~223 之間。一般用于小型網絡。
D 類:是多播地址。該類 IP 地址的最前面為 1110 ,所以地址的網絡號取值于 224~239 之間。一般用于多路廣播用戶。
E 類:是保留地址。該類 IP 地址的最前面為 1111 ,所以地址的網絡號取值于 240~255 之間。
為了方便理解,我畫了一張 IP 地址分類圖,如下所示
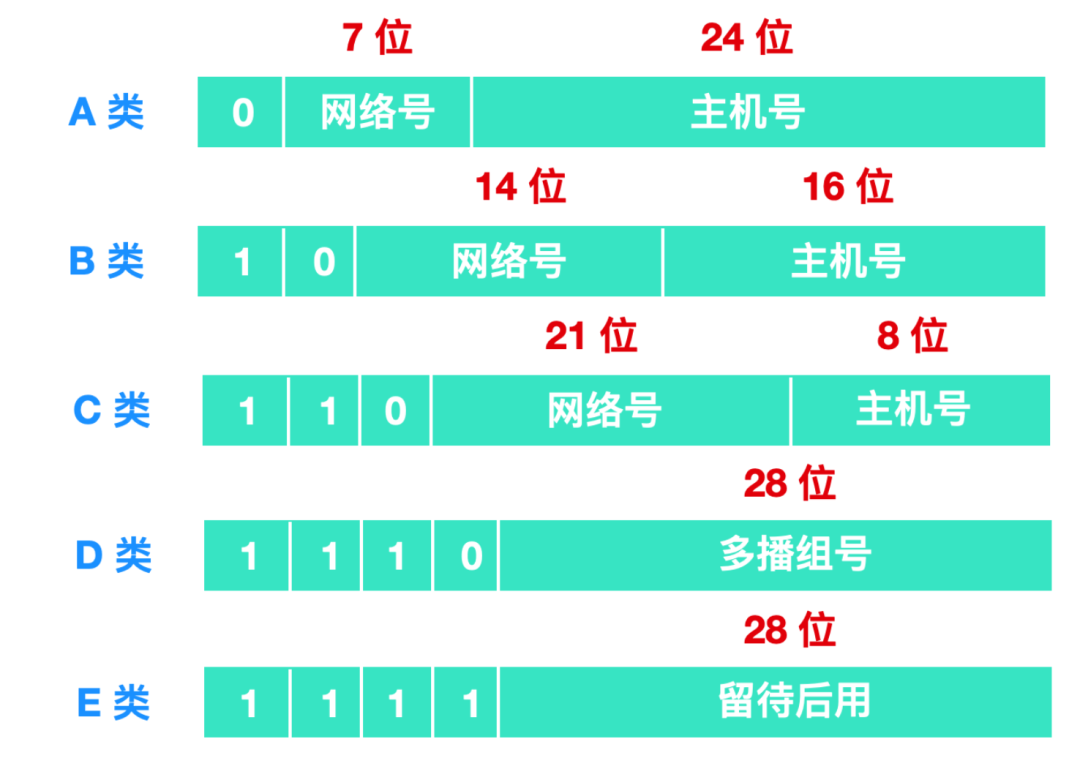
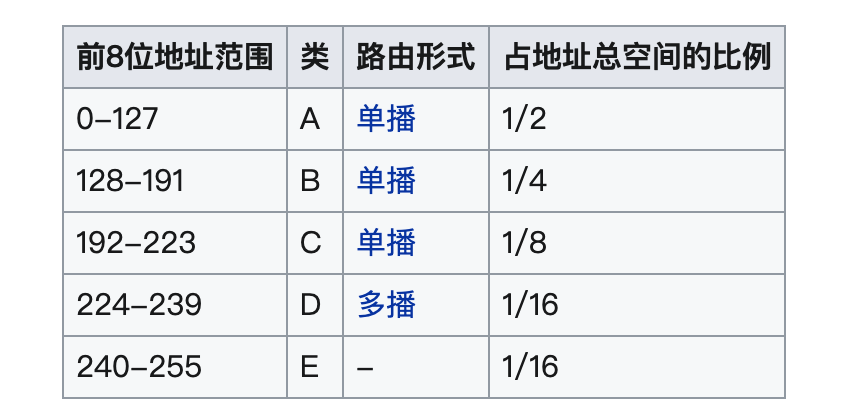
根據不同的 IP 范圍,有下面不同的地總空間分類
子網掩碼
子網掩碼(subnet mask)又叫做網絡掩碼,它是一種用來指明一個 IP 地址的哪些位標識的是主機所在的網絡。子網掩碼是一個 32位 地址,用于屏蔽 IP 地址的一部分以區別網絡標識和主機標識。
一個 IP 地址只要確定了其分類,也就確定了它的網絡標識和主機標識,由此,各個分類所表示的網絡標識范圍如下

用1表示 IP 網絡地址的比特范圍,0表示 IP 主機地址的范圍。將他們用十進制表示,那么這三類的表示如下

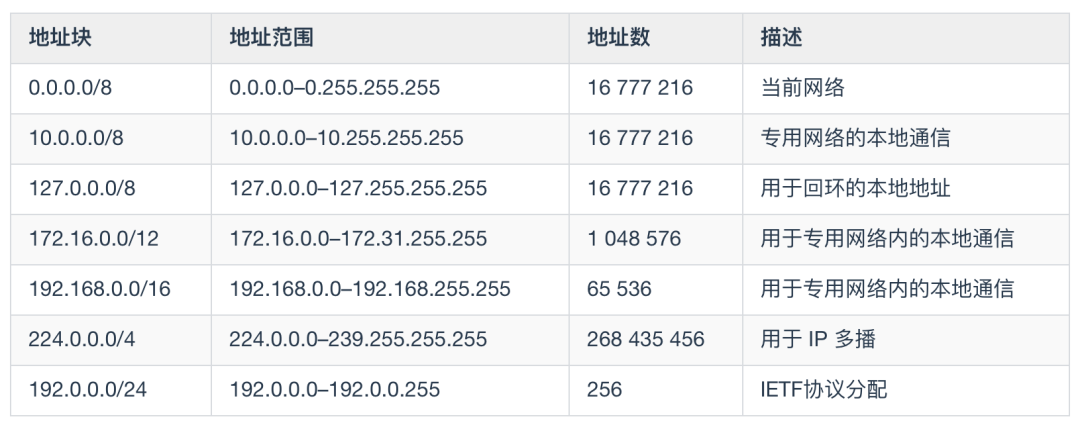
保留地址
在IPv4 的幾類地址中,有幾個保留的地址空間不能在互聯網上使用。這些地址用于特殊目的,不能在局域網外部路由。
IP 協議版本
目前,全球 Internet 中共存有兩個IP版本:IP 版本 4(IPv4)和IP 版本6(IPv6)。IP 地址由二進制值組成,可驅動 Internet 上所有數據的路由。IPv4 地址的長度為 32 位,而 IPv6 地址的長度為 128 位。
Internet IP 資源由Internet 分配號碼機構(IANA)分配給區域 Internet 注冊表(RIR),例如 APNIC,該機構負責根 DNS ,IP 尋址和其他 Internet 協議資源。
下面我們就一起認識一下 IP 協議中非常重要的兩個版本 IPv4 和 IPv6。
IPv4
IPv4 的全稱是Internet Protocol version 4,是 Internet 協議的第四版。IPv4 是一種無連接的協議,這個協議會盡最大努力交付數據包,也就是說它不能保證任何數據包能到達目的地,也不能保證所有的數據包都會按照正確的順序到達目標主機,這些都是由上層比如傳輸控制協議控制的。也就是說,單從 IP 看來,這是一個不可靠的協議。
前面我們講過網絡層分組被稱為數據報,所以我們接下來的敘述也會圍繞著數據報展開。
IPv4 的數據報格式如下
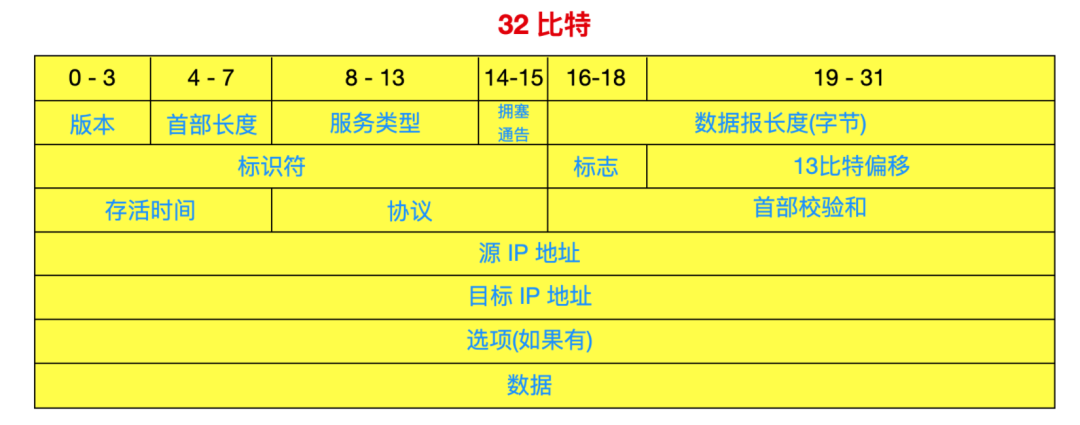
IPv4 數據報中的關鍵字及其解釋
版本字段(Version)占用 4 bit,通信雙方使用的版本必須一致,對于 IPv4 版本來說,字段值是 4。
首部長度(Internet Header Length)占用 4 bit,首部長度說明首部有多少 32 位(4 字節)。由于 IPv4 首部可能包含不確定的選項,因此這個字段被用來確定數據的偏移量。大多數 IP 不包含這個選項,所以一般首部長度設置為 5, 數據報為 20 字節 。
服務類型(Differential Services Codepoint,DSCP)占用 6 bit,以便使用不同的 IP 數據報,比如一些低時延、高吞吐量和可靠性的數據報。服務類型如下表所示
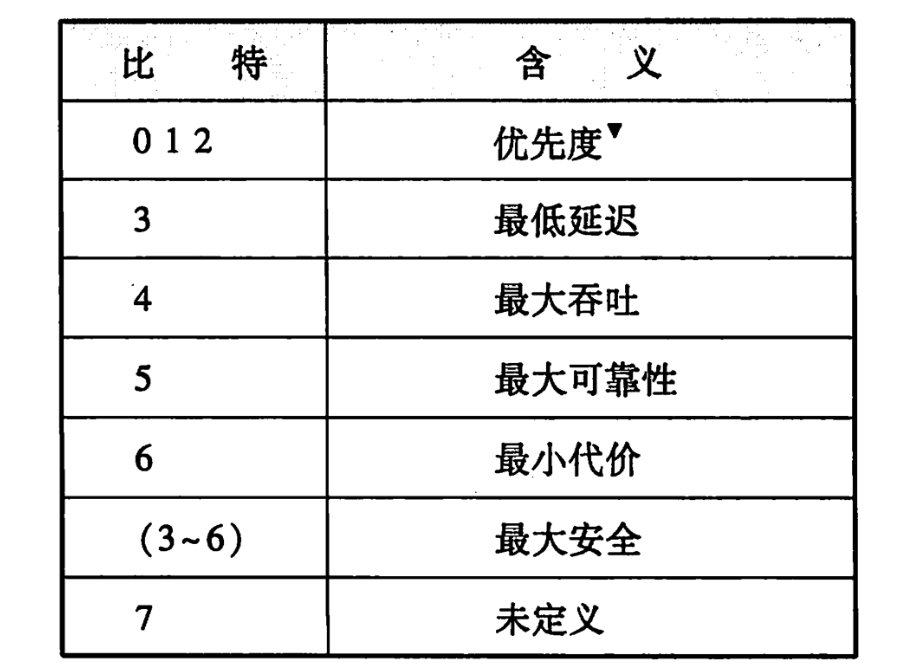
擁塞通告(Explicit Congestion Notification,ECN)占用 2 bit,它允許在不丟棄報文的同時通知對方網絡擁塞的發生。ECN 是一種可選的功能,僅當兩端都支持并希望使用,且底層網絡支持時才被使用。最開始 DSCP 和 ECN 統稱為 TOS,也就是區分服務,但是后來被細化為了 DSCP 和 ECN。
數據報長度(Total Length)占用 16 bit,這 16 位是包括在數據在內的總長度,理論上數據報的總長度為 2 的 16 次冪 - 1,最大長度是 65535 字節,但是實際上數據報很少有超過 1500 字節的。IP 規定所有主機都必須支持最小 576 字節的報文,但大多數現代主機支持更大的報文。當下層的數據鏈路協議的最大傳輸單元(MTU)字段的值小于 IP 報文長度時,報文就必須被分片。
標識符(Identification)占用 16 bit,這個字段用來標識所有的分片,因為分片不一定會按序到達,所以到達目標主機的所有分片會進行重組,每產生一個數據報,計數器加1,并賦值給此字段。
標志(Flags)占用 3 bit,標志用于控制和識別分片,這 3 位分別是
0 位:保留,必須為0;
1 位:禁止分片(Don’t Fragment,DF),當 DF = 0 時才允許分片;
2 位:更多分片(More Fragment,MF),MF = 1 代表后面還有分片,MF = 0 代表已經是最后一個分片。
如果 DF 標志被設置為 1 ,但是路由要求必須進行分片,那么這條數據報回丟棄
分片偏移(Fragment Offset)占用 13 位,它指明了每個分片相對于原始報文開頭的偏移量,以 8 字節作單位。
存活時間(Time To Live,TTL)占用 8 位,存活時間避免報文在互聯網中迷失,比如陷入路由環路。存活時間以秒為單位,但小于一秒的時間均向上取整到一秒。在現實中,這實際上成了一個跳數計數器:報文經過的每個路由器都將此字段減 1,當此字段等于 0 時,報文不再向下一跳傳送并被丟棄,這個字段最大值是 255。
協議(Protocol)占用 8 位,這個字段定義了報文數據區使用的協議。協議內容可以在 https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml 官網上獲取。
首部校驗和(Header Checksum)占用 16 位,首部校驗和會對字段進行糾錯檢查,在每一跳中,路由器都要重新計算出的首部檢驗和并與此字段進行比對,如果不一致,此報文將會被丟棄。
源地址(Source address)占用 32 位,它是 IPv4 地址的構成條件,源地址指的是數據報的發送方
目的地址(Destination address)占用 32 位,它是 IPv4 地址的構成條件,目標地址指的是數據報的接收方
選項(Options)是附加字段,選項字段占用 1 - 40 個字節不等,一般會跟在目的地址之后。如果首部長度 > 5,就應該考慮選項字段。
數據不是首部的一部分,因此并不被包含在首部檢驗和中。
在 IP 發送的過程中,每個數據報的大小是不同的,每個鏈路層協議能承載的網絡層分組也不一樣,有的協議能夠承載大數據報,有的卻只能承載很小的數據報,不同的鏈路層能夠承載的數據報大小如下。
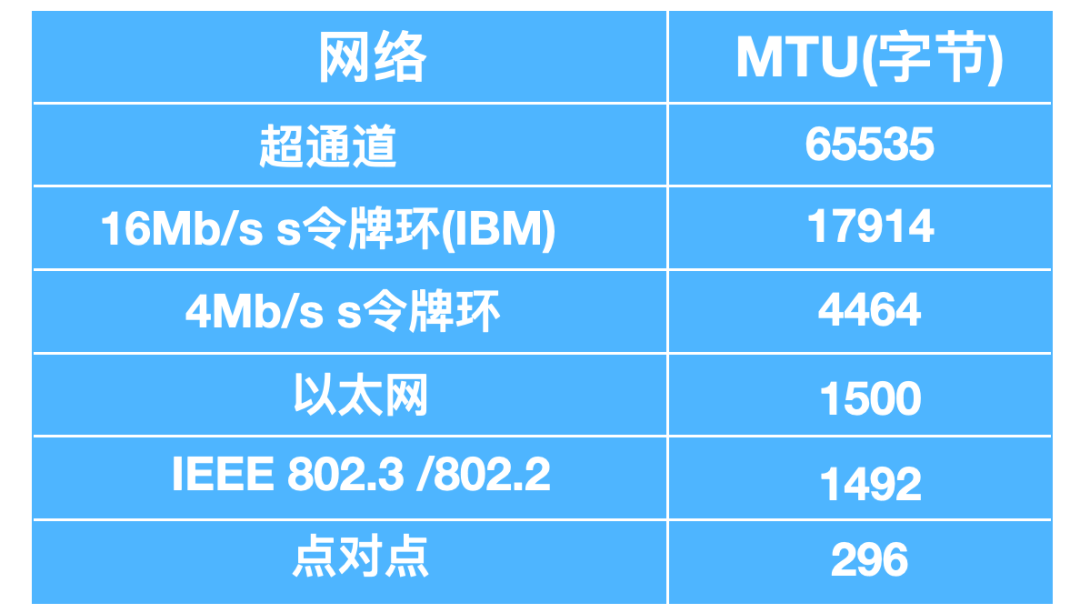
IPv4 分片
一個鏈路層幀能承載的最大數據量叫做最大傳輸單元(Maximum Transmission Unit, MTU),每個 IP 數據報封裝在鏈路層幀中從一臺路由器傳到下一臺路由器。因為每個鏈路層所支持的最大 MTU 不一樣,當數據報的大小超過 MTU 后,會在鏈路層進行分片,每個數據報會在鏈路層單獨封裝,每個較小的片都被稱為片(fragement)。
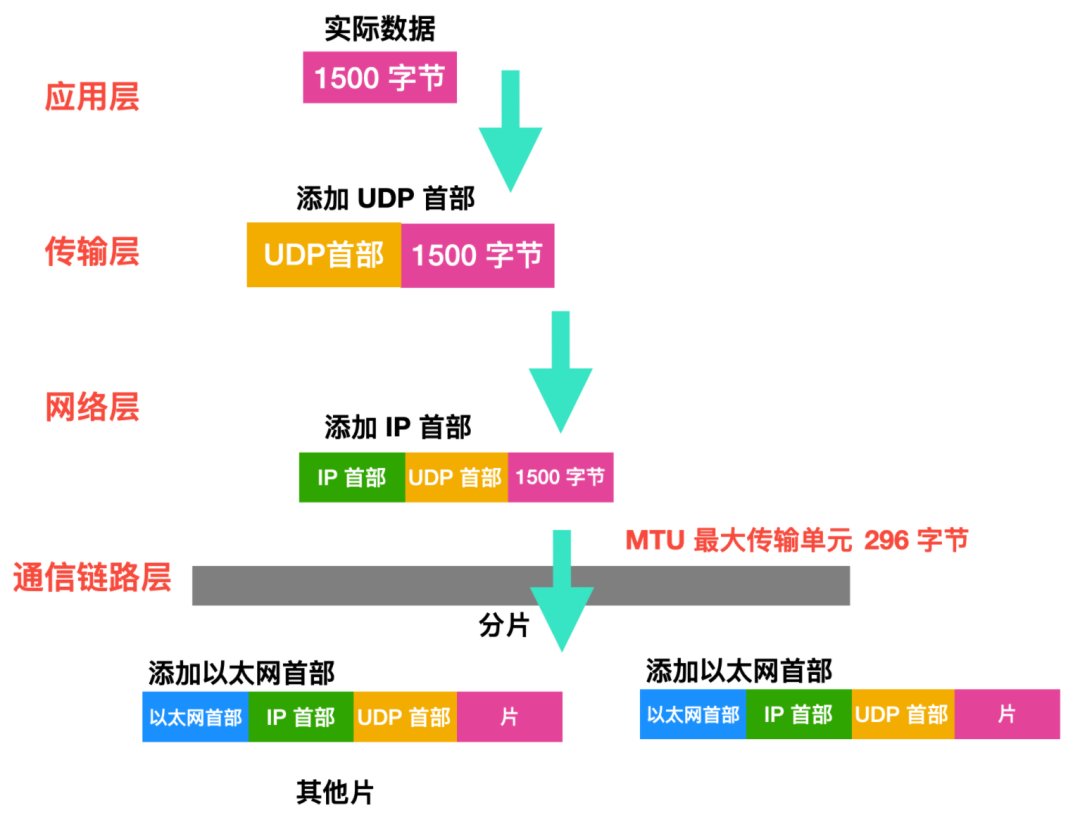
每個片在到達目的地后會進行重組,準確的來說是在運輸層之前會進行重組,TCP 和 UDP 都會希望發送完整的、未分片的報文,出于性能的原因,分片重組不會在路由器中進行,而是會在目標主機中進行重組。
當目標主機收到從發送端發送過來的數據報后,它需要確定這些數據報中的分片是否是由源數據報分片傳遞過來的,如果是的話,還需要確定何時收到了分片中的最后一片,并且這些片會如何拼接一起成為數據報。
針對這些潛在的問題,IPv4 設計者將標識、標志和片偏移放在 IP 數據報首部中。當生成一個數據報時,發送主機會為該數據報設置源和目的地址的同時貼上標識號。發送主機通常將它發送的每個數據報的標識 + 1。當某路由器需要對一個數據報分片時,形成的每個數據報具有初始數據報的源地址、目標地址和標識號。當目的地從同一發送主機收到一系列數據報時,它能夠檢查數據報的標識號以確定哪些數據是由源數據報發送過來的。由于 IP 是一種不可靠的服務,分片可能會在網路中丟失,鑒于這種情況,通常會把分片的最后一個比特設置為 0 ,其他分片設置為 1,同時使用偏移字段指定分片應該在數據報的哪個位置。
IPv4 尋址
IPv4 支持三種不同類型的尋址模式,分別是
單播尋址模式:在這種模式下,數據只發送到一個目的地的主機。
廣播尋址模式:在此模式下,數據包將被尋址到網段中的所有主機。這里客戶端發送一個數據包,由所有服務器接收:
組播尋址模式:此模式是前兩種模式的混合,即發送的數據包既不指向單個主機也不指定段上的所有主機
IPv6
隨著端系統接入的越來越多,IPv4 已經無法滿足分配了,所以,IPv6 應運而生,IPv6 就是為了解決 IPv4 的地址耗盡問題而被標準化的網際協議。IPv4 的地址長度為 4 個 8 字節,即 32 比特, 而 IPv6 的地址長度是原來的四倍,也就是 128 比特,一般寫成 8 個 16 位字節。
從 IPv4 切換到 IPv6 及其耗時,需要將網絡中所有的主機和路由器的 IP 地址進行設置,在互聯網不斷普及的今天,替換所有的 IP 是一個工作量及其龐大的任務。我們后面會說。
我們先來看一下 IPv6 的地址是怎樣的
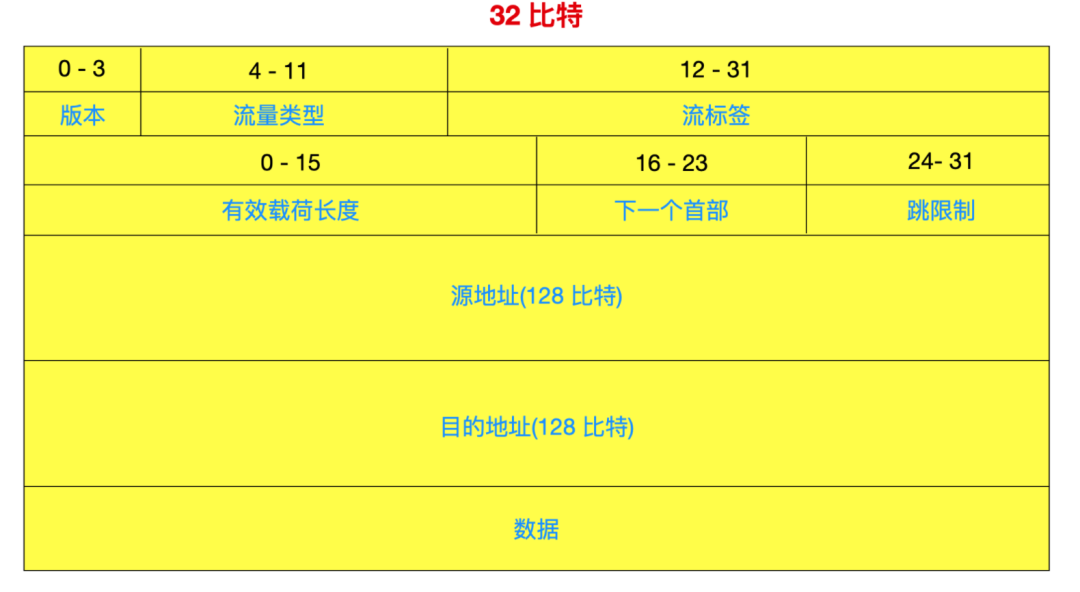
版本與 IPv4 一樣,版本號由 4 bit 構成,IPv6 版本號的值為 6。
流量類型(Traffic Class)占用 8 bit,它就相當于 IPv4 中的服務類型(Type Of Service)。
流標簽(Flow Label)占用 20 bit,這 20 比特用于標識一條數據報的流,能夠對一條流中的某些數據報給出優先權,或者它能夠用來對來自某些應用的數據報給出更高的優先權,只有流標簽、源地址和目標地址一致時,才會被認為是一個流。
有效載荷長度(Payload Length)占用 16 bit,這 16 比特值作為一個無符號整數,它給出了在 IPv6 數據報中跟在鼎昌 40 字節數據報首部后面的字節數量。
下一個首部(Next Header)占用 8 bit,它用于標識數據報中的內容需要交付給哪個協議,是 TCP 協議還是 UDP 協議。
跳限制(Hop Limit)占用 8 bit,這個字段與 IPv4 的 TTL 意思相同。數據每經過一次路由就會減 1,減到 0 則會丟棄數據。
源地址(Source Address)占用 128 bit (8 個 16 位 ),表示發送端的 IP 地址。
目標地址(Destination Address)占用 128 bit (8 個 16 位 ),表示接收端 IP 地址。
可以看到,相較于 IPv4 ,IPv6 取消了下面幾個字段
標識符、標志和比特偏移:IPv6 不允許在中間路由器上進行分片和重新組裝。這種操作只能在端系統上進行,IPv6 將這個功能放在端系統中,加快了網絡中的轉發速度。
首部校驗和:因為在運輸層和數據鏈路執行了報文段完整性校驗工作,IP 設計者大概覺得在網絡層中有首部校驗和比較多余,所以去掉了。IP 更多專注的是快速處理分組數據。
選項字段:選項字段不再是標準 IP 首部的一部分了,但是它并沒有消失,而是可能出現在 IPv6 的擴展首部,也就是下一個首部中。
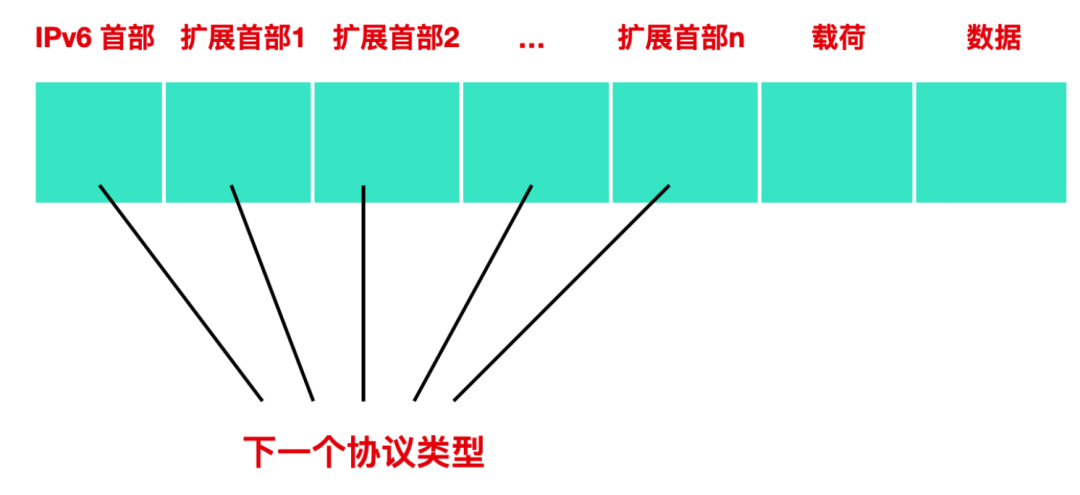
IPv6 擴展首部
IPv6 首部長度固定,無法將選項字段加入其中,取而代之的是 IPv6 使用了擴展首部
擴展首部通常介于 IPv6 首部與 TCP/UDP 首部之間,在 IPv4 中可選長度固定為40 字節,在 IPv6 中沒有這樣的限制。IPv6 的擴展首部可以是任意長度。擴展首部中還可以包含擴展首部協議和下一個擴展字段。
IPv6 首部中沒有標識和標志字段,對 IP 進行分片時,需要使用到擴展首部。
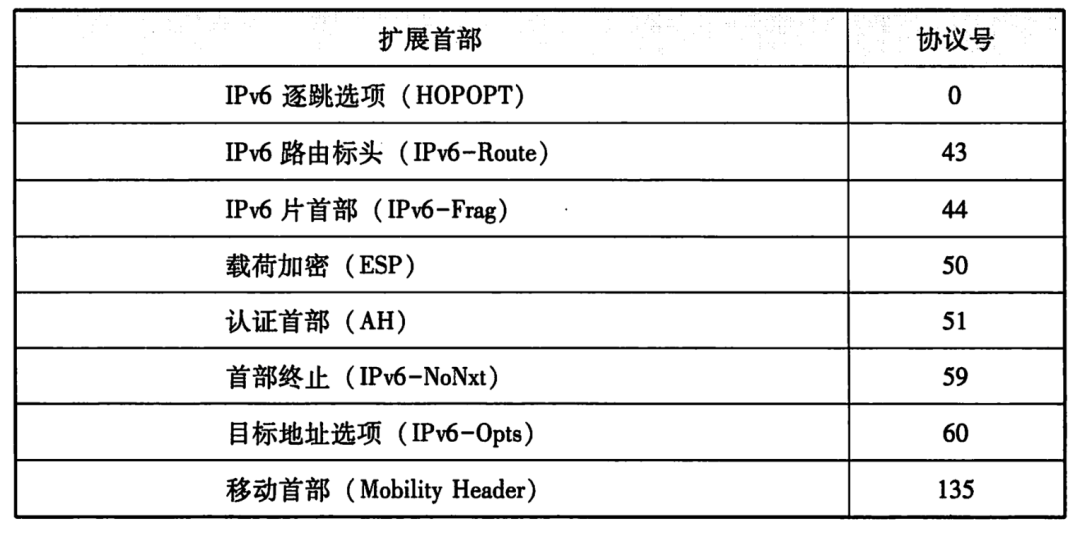
具體的擴展首部表如下所示
下面我們來看一下 IPv6 都有哪些特點
IPv6 特點
IPv6 的特點在 IPv4 中得以實現,但是即便實現了 IPv4 的操作系統,也未必實現了 IPv4 的所有功能。而 IPv6 卻將這些功能大眾化了,也就表明這些功能在 IPv6 已經進行了實現,這些功能主要有
地址空間變得更大:這是 IPv6 最主要的一個特點,即支持更大的地址空間。
精簡報文結構: IPv6 要比 IPv4 精簡很多,IPv4 的報文長度不固定,而且有一個不斷變化的選項字段;IPv6 報文段固定,并且將選項字段,分片的字段移到了 IPv6 擴展頭中,這就極大的精簡了 IPv6 的報文結構。
實現了自動配置:IPv6 支持其主機設備的狀態和無狀態自動配置模式。這樣,沒有DHCP 服務器不會停止跨段通信。
層次化的網絡結構:IPv6 不再像 IPv4 一樣按照 A、B、C等分類來劃分地址,而是通過 IANA -> RIR -> ISP 這樣的順序來分配的。IANA 是國際互聯網號碼分配機構,RIR 是區域互聯網注冊管理機構,ISP 是一些運營商(例如電信、移動、聯通)。
IPSec:IPv6 的擴展報頭中有一個認證報頭、封裝安全凈載報頭,這兩個報頭是 IPsec 定義的。通過這兩個報頭網絡層自己就可以實現端到端的安全,而無需像 IPv4 協議一樣需要其他協議的幫助。
支持任播:IPv6 引入了一種新的尋址方式,稱為任播尋址。
IPv6 地址
我們知道,IPv6 地址長度為 128 位,他所能表示的范圍是 2 ^ 128 次冪,這個數字非常龐大,幾乎涵蓋了你能想到的所有主機和路由器,那么 IPv6 該如何表示呢?
一般我們將 128 比特的 IP 地址以每 16 比特為一組,并用:號進行分隔,如果出現連續的 0 時還可以將 0 省略,并用::兩個冒號隔開,記住,一個 IP 地址只允許出現一次兩個連續的冒號。
下面是一些 IPv6 地址的示例
二進制數表示

用十六進制數表示

出現兩個冒號的情況
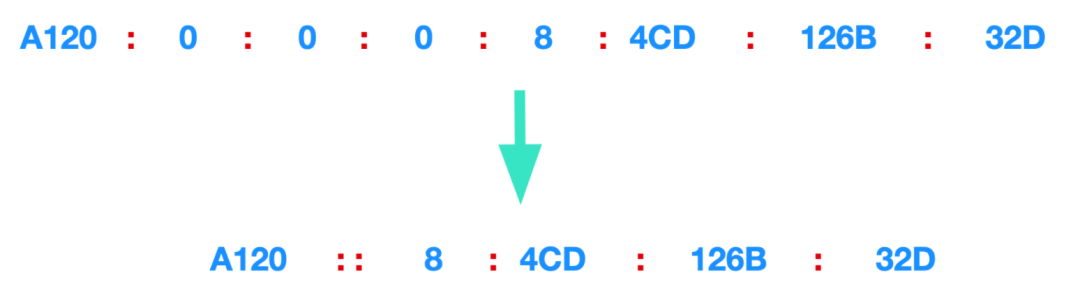
如上圖所示,A120 和 4CD 中間的 0 被 :: 所取代了。
如何從 IPv4 遷移到 IPv6
我們上面聊了聊 IPv4 和 IPv6 的報文格式、報文含義是什么、以及 IPv4 和 IPv6 的特征分別是什么,看完上面的內容,你已經知道了 IPv4 現在馬上就變的不夠用了,而且隨著 IPv6 的不斷發展和引用,雖然新型的 IPv6 可以做到向后兼容,即 IPv6 可以收發 IPv4 的數據報,但是已經部署的具有 IPv4 能力的系統卻不能夠處理 IPv6 數據報。所以 IPv4 噬需遷移到 IPv6,遷移并不意味著將 IPv4 替換為 IPv6。這僅意味著同時啟用 IPv6 和 IPv4。
那么現在就有一個問題了,IPv4 如何遷移到 IPv6 呢?這就是我們接下來討論的重點。
標志
最簡單的方式就是設置一個標志日,指定某個時間點和日期,此時全球的因特網機器都會在這時關機從 IPv4 遷移到 IPv6 。上一次重大的技術遷移是在 35 年前,但是很顯然,不用我過多解釋,這種情況肯定是不行的。影響不可估量不說,如何保證全球人類都能知道如何設置自己的 IPv6 地址?一個設計數十億臺機器的標志日現在是想都不敢想的。
隧道技術
現在已經在實踐中使用的從 IPv4 遷移到 IPv6 的方法是隧道技術(tunneling)。
什么是隧道技術呢?
隧道技術是一種使用互聯網絡的基礎設施在網絡之間的傳輸數據的方式,使用隧道傳遞的數據可以是不同協議的數據幀或包。使用隧道技術所遵從的協議叫做隧道協議(tunneling protocol)。隧道協議會將這些協議的數據幀或包封裝在新的包頭中發送。新的包頭提供了路由信息,從而使封裝的負載數據能夠通過互聯網絡進行傳遞。
使用隧道技術一般都會建一個隧道,建隧道的依據如下:
比如兩個 IPv6 節點(下方 B、E)要使用 IPv6 數據報進行交互,但是它們是經由兩個 IPv4 的路由器進行互聯的。那么我們就需要將 IPv6 節點和 IPv4 路由器組成一個隧道,如下圖所示

借助于隧道,在隧道發送端的 IPv6 節點可將整個 IPv6 數據報放到一個 IPv4 數據報的數據(有效載荷)字段中,于是,IPv4 數據報的地址被設置為指向隧道接收端的 IPv6 的節點,比如上面的 E 節點。然后再發送給隧道中的第一個節點 C,如下所示
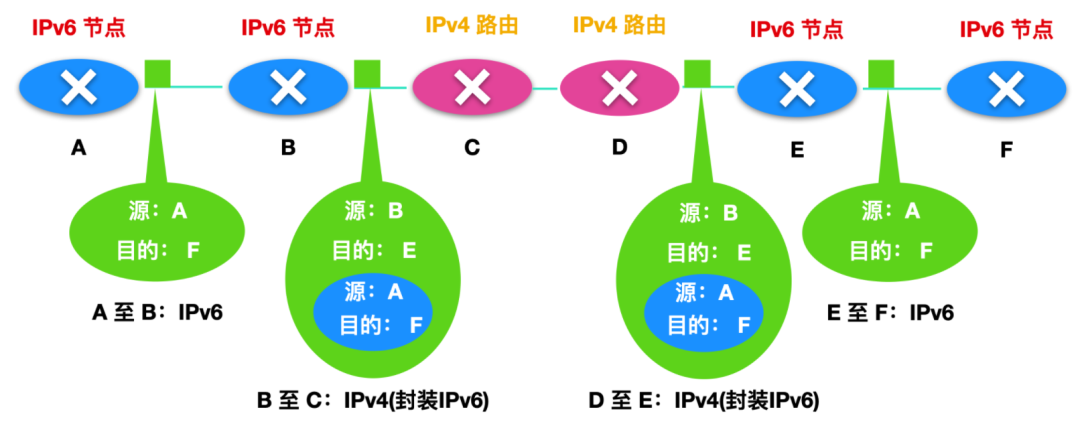
隧道中間的 IPv4 提供路由,路由器不知道這個 IPv4 內部包含一個指向 IPv6 的地址。隧道接收端的 IPv6 節點收到 IPv4 數據報,會確定這個 IPv4 數據報含有一個 IPv6 數據報,通過觀察數據報長度和數據得知。然后取出 IPv6 數據報,再為 IPv6 提供路由,就好像兩個節點直接相連傳輸數據報一樣。
總結
這篇文章是計算機網絡系列的連載文章,這篇我們主要探討了網絡層的相關知識、路由器的內部構造、路由器如何實現轉發的,IP 協議相關內容:包括 IP 地址、IPv4 和 IPv6 的相關內容,最后我們探討了如何使 IPv4 遷移到 IPv6 。
原文標題:我畫了 40 張圖就是為了讓你搞懂計算機網絡層
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
計算機
+關注
關注
19文章
7545瀏覽量
88672 -
網絡
+關注
關注
14文章
7600瀏覽量
89274
原文標題:我畫了 40 張圖就是為了讓你搞懂計算機網絡層
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機網絡架構的演進
量子計算機與普通計算機工作原理的區別
工業計算機類型介紹

計算機局域網技術是什么
計算機存儲系統的構成
應用于計算機網絡服務器晶振SG3225HBN(X1G005141000500)
計算機網絡中常見的默認端口號及其用途
一文了解TCP/IP協議





 工商網監
工商網監
評論