") 一種可以編碼局部信息的結(jié)構(gòu)T2T module,并證明了T2T的有效性
一種可以編碼局部信息的結(jié)構(gòu)T2T module,并證明了T2T的有效性
深度學(xué)習(xí)實(shí)戰(zhàn)
前面提到過ViT,但是ViT在數(shù)據(jù)量不夠巨大的情況下是打不過ResNet的。于是ViT的升級(jí)版T2T-ViT橫空出世了,速度更快性能更強(qiáng)。T2T-ViT相比于ViT,參數(shù)量和MACs(Multi-Adds)減少了200%,性能在ImageNet上又有2.5%的提升。T2T-ViT在和ResNet50模型大小差不多的情況下,在ImageNet上達(dá)到了80.7%的準(zhǔn)確率。論文的貢獻(xiàn):
證明了通過精心設(shè)計(jì)的Transformer-based的網(wǎng)絡(luò)(T2T module and efficient backbone),是可以打敗CNN-based的模型的,而且不需要在巨型的訓(xùn)練集(如JFT-300M)上預(yù)訓(xùn)練。
提出了一種可以編碼局部信息的結(jié)構(gòu)T2T module,并證明了T2T的有效性。
展示了在設(shè)計(jì)CNNs backbone時(shí)用到的architecture engineering經(jīng)驗(yàn)同樣適用于設(shè)計(jì)Transformer-based的模型,通過大量的實(shí)驗(yàn)證明深且窄(deep-narrow)的網(wǎng)絡(luò)能夠增加feature的豐富性和減少冗余。
Why T2T-ViT?
先來說下ViT[1],ViT在從頭開始訓(xùn)練(trained from scratch) ImageNet時(shí),效果甚至比CNN-based的模型還差。這顯然是不能讓人足夠滿意的,文中分析了兩點(diǎn)原因:
(1)由于ViT是采用對(duì)原圖像分塊,然后做Linear Projection得到embedding。但是通過實(shí)驗(yàn)發(fā)現(xiàn),這種基于原圖像的簡單tokenization并沒有很好地學(xué)到圖像的邊緣或者線條這種低級(jí)特征,導(dǎo)致ViT算法的學(xué)習(xí)效率不高,難以訓(xùn)練,因此ViT需要大量的數(shù)據(jù)進(jìn)行訓(xùn)練。
(2)在有限的計(jì)算資源和有限的數(shù)據(jù)的情況下,ViT冗余的attention主干網(wǎng)絡(luò)難以學(xué)得豐富的特征。
所以為了克服這些限制,提出了Tokens-To-Token Vision Transformers(T2T-Vit)。為了證明上面的結(jié)論,還做了一個(gè)實(shí)驗(yàn),可視化了ResNet、ViT和T2T-ViT所學(xué)到的特征的差異。
綠色的框中表示了模型學(xué)到的一些諸如邊緣和線條的low-level structure feature,紅色框則表示模型學(xué)到了不合理的feature map,這些feature或者接近于0,或者是很大的值。從這個(gè)實(shí)驗(yàn)可以進(jìn)一步證實(shí),CNN會(huì)從圖像的低級(jí)特征學(xué)起,這個(gè)在生物上是說得通的,但是通過可視化來看,ViT的問題確實(shí)不小,且不看ViT有沒有學(xué)到低級(jí)的特征,后面的網(wǎng)絡(luò)層的feature map甚至出現(xiàn)了異常值,這個(gè)是有可能導(dǎo)致錯(cuò)誤的預(yù)測的,同時(shí)反映了ViT的學(xué)習(xí)效率差。 Tokens-to-Token:Progressive Tokenization
為了解決ViT的問題,提出了一種漸進(jìn)的tokenization去整合相鄰的tokens,從tokens到token,這種做法不僅可以對(duì)局部信息的建模還能減小token序列的長度。整個(gè)T2T的操作分為兩個(gè)部分:重構(gòu)(re-structurization)和軟劃分(soft split)。(1)Re-structurization假設(shè)上一個(gè)網(wǎng)絡(luò)層的輸出為T,T經(jīng)過Transformer層得到T',Transformer是包括mutil-head self-attention和MLP的,因此從T到T'可以表示為T' = MLP(MSA(T)),這里MSA表示mutil-head self-attention,MLP表示多層感知機(jī),上述兩個(gè)操作后面都省略了LN。經(jīng)過Transformer層后輸出也是token的序列,為了重構(gòu)局部的信息,首先把它還原為原來的空間結(jié)構(gòu),即從一維reshape為二維,記作I。I = Reshape(T'),reshape操作就完成了從一維的向量到二維的重排列。整個(gè)操作可以參見上圖的step1。(2)Soft Split與ViT那種hard split不同,T2T-ViT采用了soft split,說直白點(diǎn)就是不同的分割部分會(huì)有overlapping。I會(huì)被split為多個(gè)patch,然后每個(gè)patch里面的tokens會(huì)拼接成一個(gè)token,也就是這篇論文的題目tokens to token,這個(gè)步驟也是最關(guān)鍵的一個(gè)步驟,因?yàn)檫@個(gè)步驟從圖像中相鄰位置的語義信息聚合到一個(gè)向量里面。同時(shí)這個(gè)步驟會(huì)使tokens序列變短,單個(gè)token的長度會(huì)變長,符合CNN-based模型設(shè)計(jì)的經(jīng)驗(yàn)deep-narrow。 T2T module
在T2T模塊中,依次通過Re-structurization和Soft Split操作,會(huì)逐漸使tokens的序列變短。整個(gè)T2T模塊的操作可以表示如下:
由于是soft split所以tokens的序列長度會(huì)比ViT大很多,MACs和內(nèi)存占用都很大,因此對(duì)于T2T模塊來說,只能減小通道數(shù),這里的通道數(shù)可以理解為embedding的維度,還使用了Performer[2]來進(jìn)一步減少內(nèi)存的占用。 Backbone
為了增加特征的豐富性和減少冗余,需要探索一個(gè)更有效的backbone。從DenseNet、Wide-ResNets、SENet、ResNeXt和GhostNet尋找設(shè)計(jì)的靈感,最終發(fā)現(xiàn):(1)在原ViT的網(wǎng)絡(luò)結(jié)構(gòu)上采用deep-narrow的原則,增加網(wǎng)絡(luò)的深度,減小token的維度,可以在縮小模型參數(shù)量的同時(shí)提升性能。(2)使用SENet[3]中的channel attention對(duì)ViT會(huì)有提升,但是在使用deep-narrow的結(jié)構(gòu)下提升很小。 Architecture
T2T-ViT由T2T module和T2T-ViT backbone組成。PE是position embedding。對(duì)于T2T-ViT-14來說,由14個(gè)transformer layers組成,backbone中的hidden dimensions是384。對(duì)比ViT-B/16,ViT-B/16有12個(gè)transformer layers,hidden dimensions是768,模型大小和MACs是T2T-ViT-14整整三倍。 Experiments
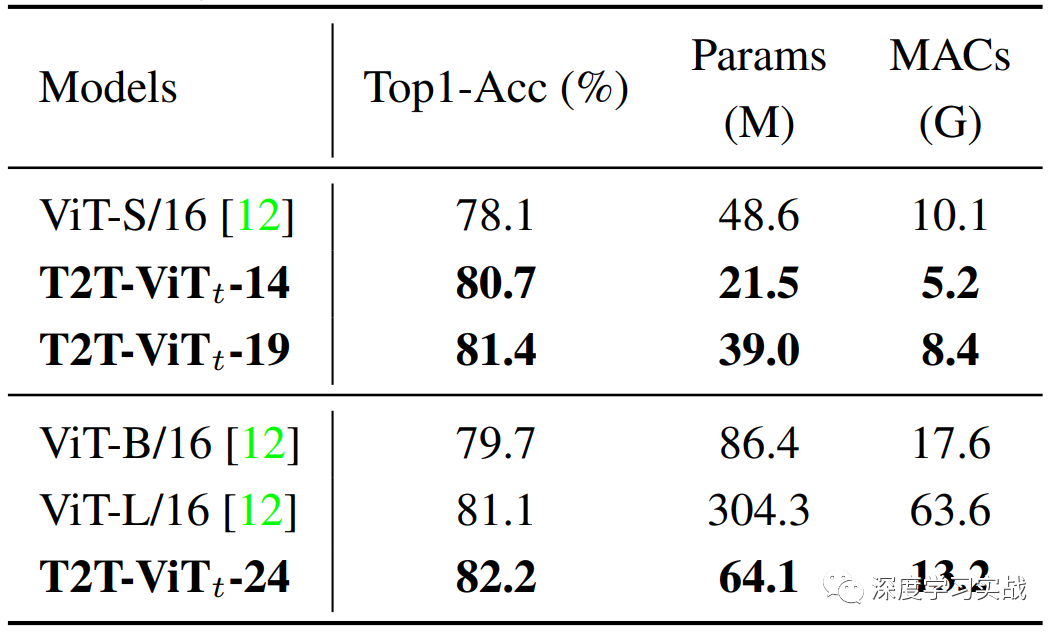
在不使用預(yù)訓(xùn)練時(shí),T2T-ViT和ViT的對(duì)比,可以看到T2T-ViT真的是完勝ViT啊,不僅模型比你小,精度還比你高。
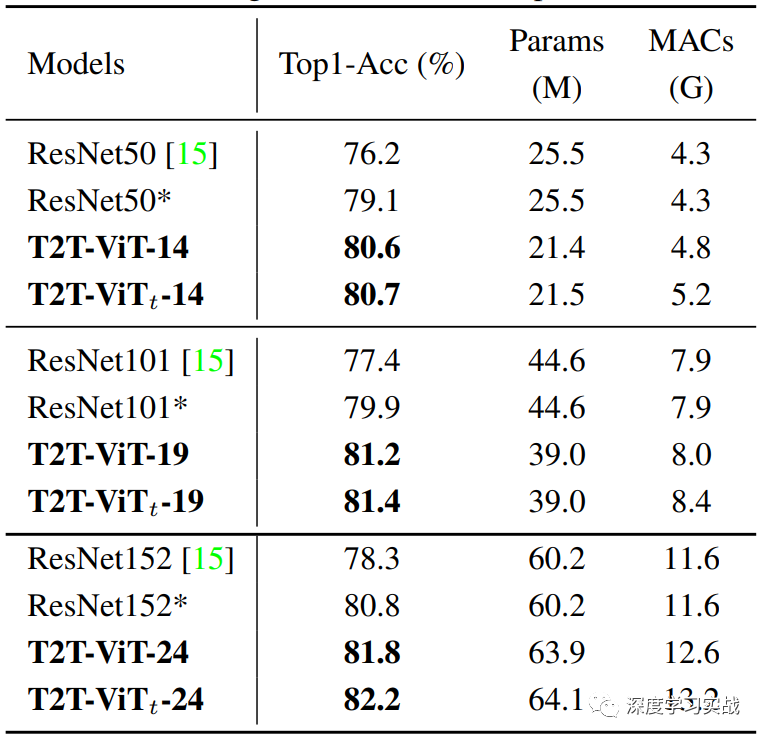
不僅完勝ViT,ResNet也不在話下,說實(shí)話看到這個(gè)結(jié)果的時(shí)候真的可以說Transformer戰(zhàn)勝了CNN了。 Conclusion
T2T-ViT通過重構(gòu)圖像的結(jié)構(gòu)性信息,克服了ViT的短板,真正意義上擊敗了CNN。通過提出tokens-to-token的process,逐漸聚合周圍的token,增強(qiáng)局部性信息。這篇論文中不僅探索了Transformer-based的網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計(jì),證明了在Transformer-based模型中deep-narrow要好于shallow-wide,還取得了很好的性能表現(xiàn)。 Reference
[1]A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. [2]K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020. [3]Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
責(zé)任編輯:lq
-
可視化
+關(guān)注
關(guān)注
1文章
1250瀏覽量
21698 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122583 -
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22669
原文標(biāo)題:Tokens to-Token ViT:真正意義上擊敗了CNN
文章出處:【微信號(hào):gh_a204797f977b,微信公眾號(hào):深度學(xué)習(xí)實(shí)戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
瑞薩RZ T2M與RZ T2L微控制器的編碼器接口使用有何差異

FA15-220S06E2D4(-T)(-TS) FA15-220S06E2D4(-T)(-TS)

BK15-500S24H2N6(-T)(-TS) BK15-500S24H2N6(-T)(-TS)
74LVC2T45;74LVCH2T45雙電源轉(zhuǎn)換收發(fā)器規(guī)格書

MHMF082L1T2M-MINAS A6N系列 介紹 松下

MS5046T/5047T/5048T/5048N——2kSPS、16bit Σ-Δ ADC
MHMF082A1T2-操作手冊(cè) - PANATERM Ver6.0 松下
MHMF042A1T2-操作手冊(cè) - PANATERM Ver6.0 松下
MHMF042A1T2-MINAS A6N系列 介紹 松下
設(shè)計(jì)雙T陷波器遇到的疑問求解
MHMF041A1T2-MINAS A6N系列 介紹 松下
MHMF022L1T2-操作手冊(cè) - PANATERM Ver6.0 松下
使用PGA300EVM-034,選項(xiàng)ADC Calibration Mode里的“3P-1T” “2P-2T” “3P-3T” 是什么意思?
瑞薩RZ/T系列MPU的中斷重入實(shí)現(xiàn)

MHMF021L1T2-MINAS A6N系列 介紹 松下





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論