 什么是分布式文件系統
什么是分布式文件系統
我們無時無刻不在使用文件系統,進行開發時在使用文件系統,瀏覽網頁時在使用文件系統,玩手機時也在使用文件系統。
對于非專業人士來說,可能根本不知道文件系統為何物。因為,通常來說,我們在使用文件系統時一般不會感知到文件系統的存在。即使是程序開發人員,很多人對文件系統也是一知半解。
雖然文件系統經常不被感知,但是文件系統是非常重要的。在 Linux 中,文件系統是其內核的四大子系統之一;微軟的 DOS(Disk Operating System,磁盤管理系統),核心就是一個管理磁盤的文件系統,由此可見文件系統的重要性。
常見文件系統及分類
其實文件系統發展到現在,其種類也豐富多樣。比如,基于磁盤的普通本地文件系統除了 Ext4,還包括 XFS、ZFS 和 Btrfs 等。其中 Btrfs 和 ZFS 不僅可以管理一塊磁盤,還可以實現多塊磁盤的管理。不僅如此,這兩個文件系統實現了數據的冗余管理,這樣可以避免磁盤故障導致的數據丟失。除了對磁盤數據管理的文件系統,還有一些網絡文件系統。也就是說,這些文件系統看似在本地,但其實數據是在遠程的專門設備上。客戶端通過一些網絡協議實現數據的訪問,如 NFS 和 GlusterFS 等文件系統。經過幾十年的發展,文件系統的種類非常多,我們沒有辦法逐一進行介紹。下面就對主要的文件系統進行介紹。
本地文件系統
本地文件系統是對磁盤空間進行管理的文件系統,也是最常見的文件系統形態。從呈現形態上來看,本地文件系統就是一個樹形的目錄結構。本地文件系統本質上就是實現對磁盤空間的管理,實現磁盤線性空間與目錄層級結構的轉換,如下圖所示。
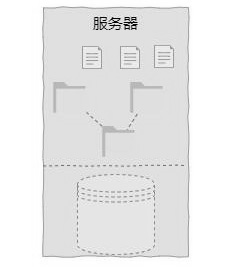
從普通用戶的角度來說,本地文件系統主要方便了對磁盤空間的使用,降低了使用難度,提高了利用效率。常見的本地文件系統有 Ext4、Btrfs、XFS 和 ZFS 等。
偽文件系統
偽文件系統是 Linux 中的概念,它是對傳統文件系統的延伸。偽文件系統并不會持久化數據,而是內存中的文件系統。它是以文件系統的形態實現用戶與內核數據交互的接口。常見的偽文件系統有 proc、sysfs 和 configfs 等。
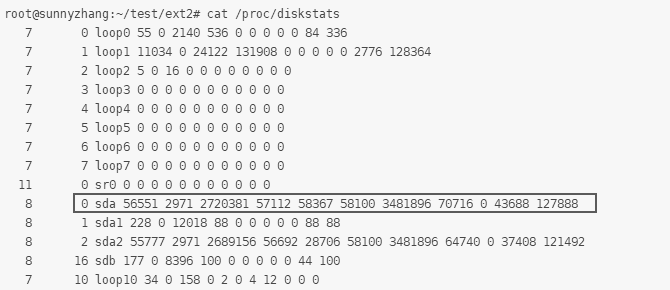
在 Linux 中,偽文件系統主要實現內核與用戶態的交互。比如,我們經常使用的 iostat 工具,其本質上是通過訪問/proc/diskstats 文件獲取信息的,如下圖所示。而該文件正是偽文件系統中的一個文件,但其內容其實是內核中對磁盤訪問的統計,它是內核某些數據結構的實例。
網絡文件系統
網絡文件系統是基于 TCP/IP 協議(整個協議可能會跨層)的文件系統,允許一臺計算機訪問另一臺計算機的文件系統,就如訪問本地文件系統一樣。網絡文件系統通常分為客戶端和服務端,其中客戶端類似本地文件系統,而服務端則是對數據進行管理的系統。網絡文件系統的使用與本地文件系統的使用沒有任何差別,只需要執行 mount 命令掛載即可。網絡文件系統也有很多種類,如 NFS 和 SMB 等。
在用戶層面,完成掛載后的網絡文件系統與本地文件系統完全一樣,看不出任何差異,對用戶是透明的。網絡文件系統就好像將遠程的文件系統映射到了本地。如下圖所示,左側是客戶端,右側是文件系統服務端。
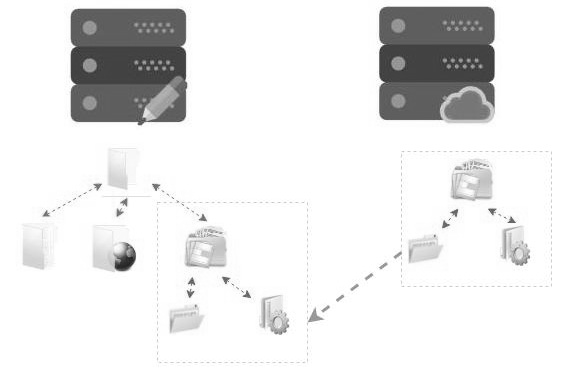
當在客戶端對服務端導出的文件系統進行掛載后,服務端的目錄樹就成為客戶端目錄樹的一顆子樹。這個子目錄對普通用戶來說是透明的,不會感知到這是一個遠程目錄,但實際上讀/寫請求需要通過網絡轉發到服務端進行處理。
集群文件系統
集群文件系統本質上也是一種本地文件系統,只不過它通常構建在基于網絡的SAN 設備上,且在多個節點中共享 SAN 磁盤。集群文件系統最大的特點是可以實現客戶端節點對磁盤介質的共同訪問,且視圖具有一致性,如圖 1-22 所示。這種視圖的一致性是指,如果在節點 0 創建一個文件,那么在節點 1 和節點 2都可以馬上看到。這個特性其實跟網絡文件系統類似,網絡文件系統也是可以在某個客戶端看到其他客戶端對文件系統的修改的。但是兩者是有差異的,集群文件系統本質上還是構建在客戶端的,而網絡文件系統則是構建在服務端的。
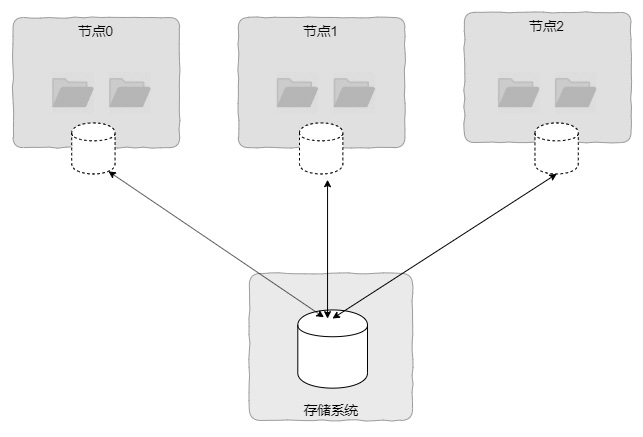
同時,對于集群文件系統來說,其最大的特點是多個節點可以同時為應用層提供文件系統服務,特別適合用于業務多活的場景,通過集群文件系統提供高可用集群機制,避免因為宕機造成服務失效。
分布式文件系統
從本質上來說,分布式文件系統其實也是一種網絡文件系統。在《計算機科學技術名詞》中給出的定義為“一種文件系統,所管理的數據資源存儲在分布式網絡節點上,提供統一的文件訪問接口”,可以看出,分布式文件系統與網絡文件系統的差異在于服務端包含多個節點,也就是服務端是可以橫向擴展的。從使用角度來說,分布式文件系統的使用與網絡文件系統的使用沒有太大的差異,也是通過執行 mount 命令掛載,客戶端的數據通過網絡傳輸到服務端進行處理。
我們發現常規的網絡文件系統最大的缺點是服務端無法實現橫向擴展。這個缺點對大型互聯網應用來說幾乎是不可容忍的。本文將介紹一下在互聯網領域應用非常廣泛的分布式文件系統。分布式文件系統最大的特點是服務端通過計算機集群實現,可以實現橫向擴展,存儲端的存儲容量和性能可以通過橫向擴展的方式實現近似線性的提升。
02
什么是分布式文件系統
分布式文件系統(Distributed File System,簡稱 DFS)是網絡文件系統的延伸,其關鍵點在于存儲端可以靈活地橫向擴展。也就是可以通過增加設備(主要是服務器)數量的方法來擴充存儲系統的容量和性能。同時,分布式文件系統還要對客戶端提供統一的視圖。也就是說,雖然分布式文件系統服務由多個節點構成,但客戶端并不感知。在客戶端來看就好像只有一個節點提供服務,而且是一個統一的分布式文件系統。
在分布式文件系統中,最出名的就是谷歌的 GFS。除此之外,還有很多開源的分布式文件系統,比較有名且應用比較廣泛的分布式文件系統有 HDFS、GlusterFS、CephFS、MooseFS 和 FastDFS 等。
分布式文件系統的具體實現有很多方法,不同的文件系統通常用來解決不同的問題,在架構上也有差異。雖然分布式文件系統有很多差異,但是有很多共性的技術點。
分布式文件系統與網絡文件系統的異同
在有些情況下,NFS 等網絡文件系統也被稱為分布式文件系統。但是在本文中,分布式文件系統是指服務端可以橫向擴展的文件系統。也就是說,分布式文件系統最大的特點是可以通過增加節點的方式增加文件系統的容量,提升性能。
當然,分布式文件系統與網絡文件系統也有很多相同的地方。比如,分布式文件系統也分為客戶端的文件系統和服務端的服務程序。同時,由于客戶端與服務端分離,分布式文件系統也要實現網絡文件系統中類似 RPC 的協議。
另外,分布式文件系統由于其數據被存儲在多個節點上,因此還有其他特點。包括但不限于以下幾點。
支持按照既定策略在多個節點上放置數據。
可以保證在出現硬件故障時,仍然可以訪問數據。
可以保證在出現硬件故障時,不丟失數據。
可以在硬件故障恢復時,保證數據的同步。
可以保證多個節點訪問的數據一致性。
由于分布式文件系統需要客戶端與多個服務端交互,并且需要實現服務端的容錯,通常來說,分布式文件系統都會實現私有協議,而不是使用 NFS 等通用協議。
03
常見分布式文件系統
分布式文件系統的具體實現方法有很多,其實早在互聯網興盛之前就有一些分布式文件系統,如 Lustre 等。早期分布式文件系統更多應用在超算領域。
隨著互聯網技術的發展,特別是谷歌的 GFS 論文的發表,分布式文件系統又得到進一步的發展。目前,很多分布式文件系統是參考谷歌發布的關于 GFS 的論文實現的。比如,大數據領域中的 HDFS 及一些開源的分布式文件系統 FastDFS 和CephFS 等。
在開源分布式文件系統方面,比較知名的項目有大數據領域的 HDFS 和通用的CephFS 和 GlusterFS 等。這幾個開源項目在實際生產中使用得相對比較多一些。接下來將對常見的分布式文件系統進行簡要的介紹。
GFS
GFS 是谷歌的一個分布式文件系統,該分布式文件系統因論文 The Google File System廣為世人所知。GFS 并沒有實現標準的文件接口,也就是其實現的接口并不與 POSIX 兼容。但包含創建、刪除、打開、關閉和讀/寫等基本接口。
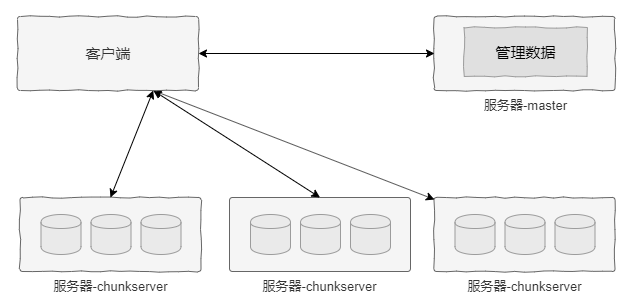
GFS 集群節點包括兩個基本角色:一個是 master,該角色的節點負責文件系統級元數據管理;另一個是 chunkserver,該角色的節點通常有很多個,用于存儲實際的數據。GFS 對于文件的管理是在 master 完成的,而數據的實際讀/寫則可以直接與 chunkserver 交互,避免 master 成為性能瓶頸。
GFS 在實現時做了很多假設,如硬件為普通商用服務器、文件大小在數百兆甚至更大及負載以順序大塊讀者為主等。其中,對于文件大小的假設尤為重要。基于該假設,GFS 默認將文件切割為 64MB 大小的邏輯塊(chunk),每個 chunk 生成一個 64 位的句柄,由 master 進行管理。
這里需要重點強調的是,每個 chunk 生命周期和定位是由 master 管理的,但是chunk 的數據則是存儲在 chunkserver 的。正是這種架構,當客戶端獲得 chunk 的位置和訪問權限后可以直接與 chunkserver 交互,而不需要 master 參與,進而避免了master 成為瓶頸。
下圖所示為 GFS 架構示意圖。
除了 GFS,還有很多類似架構的分布式文件系統。比如,在大數據領域中的HDFS,它是專用于 Hadoop 大數據存儲的分布式文件系統。其架構與 GFS 的架構類似,包含一個用于管理元數據的節點和多個存儲數據的節點,分別為 namenode和datanode。
HDFS 主要用來進行大文件的處理,它將文件按照固定大小切割,然后存儲到數據節點。同時為了保證數據的可靠性,這些數據被放到多個不同的數據節點。文件被切割的大小和同時放置數據節點的數量(副本數)是可配置的。
雖然 HDFS 是針對大文件設計的,但是也可以處理小文件。只不過對于小于切割單元的文件不進行切割。另外,HDFS 對小文件也做了一些優化,如 HAR 和SequenceFile 等方案,但 HDFS 終究不是特意為小文件設計的,因此在性能方面還有些欠缺。
除此之外,還有很多模仿 GFS 的開源分布式文件系統,如 FastDFS、MooseFS和 BFS 等。但大多數開源項目只實現了文件系統最基本的語義,嚴格來說不能稱為分布式文件系統,更像是對象存儲。
CephFS
有必要單獨介紹一下 CephFS 的原因是 CephFS 不僅實現了文件系統的所有語義,而且實現了元數據服務的多活橫向擴展。
CephFS 的架構與 GFS 的架構沒有太大差別,其突出的特點是在架構方面將GFS 的單活 master 節點擴展為多活節點。不僅可以元數據多活,而且可以根據元數據節點的負載情況實現負載的動態均衡。這樣,CephFS 不僅可以通過增加節點來實現元數據的橫向擴展,還可以調整節點負載,最大限度地使用各個節點的 CPU資源。
同時,CephFS 實現了對 POSIX 語言的兼容,在客戶端完成了內核態和用戶態兩個文件系統實現。當用戶掛載 CephFS 后,使用該文件系統可以與使用本地文件系統一樣方便。
GlusterFS
GlusterFS 是一個非常有歷史的分布式文件系統,其最大的特點是沒有中心節點。也就是 GlusterFS 并沒有一個專門的元數據節點來管理整個文件系統的元數據。
GlusterFS 抽象出卷(Volume)的概念,需要注意的是,這里的卷與 Linux LVM中的卷并非同一個概念。這里的卷是對文件系統的一個抽象,表示一個文件系統實例。當我們在集群端創建一個卷時,其實是創建了一個文件系統實例。
GlusterFS 有多種不同類型的卷,如副本卷、條帶卷和分布式卷等。正是通過這些卷特性的組合,GlusterFS 實現了數據可靠性和橫向擴展的能力。
原文標題:從文件系統到分布式文件系統
文章出處:【微信公眾號:strongerHuang】歡迎添加關注!文章轉載請注明出處。
-
接口
+關注
關注
33文章
8963瀏覽量
153334 -
存儲
+關注
關注
13文章
4508瀏覽量
87149 -
文件系統
+關注
關注
0文章
294瀏覽量
20313
原文標題:從文件系統到分布式文件系統
文章出處:【微信號:strongerHuang,微信公眾號:strongerHuang】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一文解讀在RTThread平臺上使用DFS分布式文件系統
采用信任管理的分布式文件系統TrustFs
海量郵件分布式文件系統的設計與實現
分布式文件系統數據塊聚類存儲節能策略
基于分布式文件系統元數據操作優化
盤點一下這些常見的分布式文件系統
解析夸克分布式文件系統如何實現資源共享
分布式文件系統主從式的伸縮性架構設計
2021年12種最佳分布式文件系統和對象存儲平臺榜單
云存儲中的Ceph分布式文件系統及節點選擇

分布式文件系統的設計框架
服務器數據恢復—Lustre分布式文件系統數據恢復案例
Vsan數據恢復——Vsan分布式文件系統上虛擬機不可用的數據恢復





 工商網監
工商網監
評論