") 高效框架互操作性第2部分:數(shù)據(jù)加載傳輸瓶頸和RDMA解決方案
高效框架互操作性第2部分:數(shù)據(jù)加載傳輸瓶頸和RDMA解決方案
高效的管道設(shè)計(jì)對(duì)數(shù)據(jù)科學(xué)家至關(guān)重要。在編寫(xiě)復(fù)雜的端到端工作流時(shí),您可以從各種構(gòu)建塊中進(jìn)行選擇,每種構(gòu)建塊都專(zhuān)門(mén)用于特定任務(wù)。不幸的是,在數(shù)據(jù)格式之間重復(fù)轉(zhuǎn)換容易出錯(cuò),而且會(huì)降低性能。讓我們改變這一點(diǎn)!
在本系列文章中,我們將討論高效框架互操作性的不同方面:
在第一個(gè)職位中,討論了不同內(nèi)存布局以及異步內(nèi)存分配的內(nèi)存池的優(yōu)缺點(diǎn),以實(shí)現(xiàn)零拷貝功能。
在這篇文章中,我們將重點(diǎn)介紹數(shù)據(jù)加載/傳輸過(guò)程中出現(xiàn)的瓶頸,以及如何使用遠(yuǎn)程直接內(nèi)存訪問(wèn)( RDMA )技術(shù)來(lái)緩解這些瓶頸。
在第三篇文章中,我們深入討論了端到端管道的實(shí)現(xiàn),展示了所討論的跨數(shù)據(jù)科學(xué)框架的最佳數(shù)據(jù)傳輸技術(shù)。
要了解有關(guān)框架互操作性的更多信息,請(qǐng)查看 NVIDIA GTC 2021 年會(huì)議上的演示。
數(shù)據(jù)加載和數(shù)據(jù)傳輸瓶頸
數(shù)據(jù)加載瓶頸
到目前為止,我們假設(shè)數(shù)據(jù)已經(jīng)加載到內(nèi)存中,并且使用了單個(gè) GPU 。本節(jié)重點(diǎn)介紹了 MIG 在將數(shù)據(jù)集從存儲(chǔ)器加載到設(shè)備內(nèi)存或使用單節(jié)點(diǎn)或多節(jié)點(diǎn)設(shè)置在兩個(gè) GPU 之間傳輸數(shù)據(jù)時(shí)出現(xiàn)的幾個(gè)瓶頸。然后我們討論如何克服它們。
在傳統(tǒng)工作流(圖 1 )中,當(dāng)數(shù)據(jù)集從存儲(chǔ)器加載到 GPU 內(nèi)存時(shí),數(shù)據(jù)將使用 CPU 和 PCIe 總線從磁盤(pán)復(fù)制到 GPU 內(nèi)存。加載數(shù)據(jù)至少需要兩份數(shù)據(jù)副本。第一種情況發(fā)生在將數(shù)據(jù)從存儲(chǔ)器傳輸?shù)街鳈C(jī)內(nèi)存( CPU RAM )時(shí)。將數(shù)據(jù)從主機(jī)內(nèi)存?zhèn)鬏數(shù)皆O(shè)備內(nèi)存( GPU VRAM )時(shí),會(huì)出現(xiàn)數(shù)據(jù)的第二個(gè)副本。
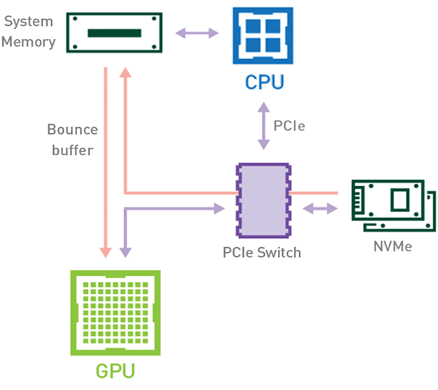
圖 1 :在傳統(tǒng)設(shè)置下,存儲(chǔ)器 CPU 內(nèi)存和 GPU 內(nèi)存之間的數(shù)據(jù)移動(dòng)。
或者,使用利用 NVIDIA Magnum IO GPUDirect Storage 技術(shù)的基于 GPU 的工作流(見(jiàn)圖 2 ),數(shù)據(jù)可以使用 PCIe 總線直接從存儲(chǔ)器流向 GPU 存儲(chǔ)器,而無(wú)需使用 CPU 或主機(jī)存儲(chǔ)器。由于數(shù)據(jù)只復(fù)制一次,因此總體執(zhí)行時(shí)間縮短。不涉及此任務(wù)的 CPU 和主機(jī)內(nèi)存也使這些資源可用于管道中其他基于 CPU 的作業(yè)。
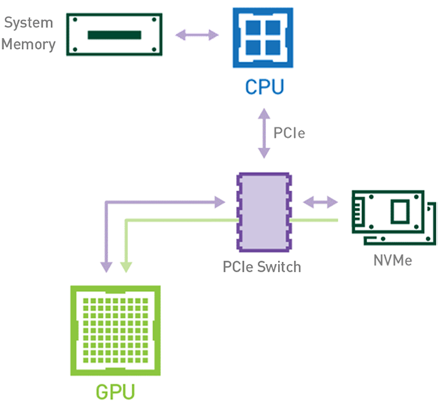
圖 2 :?jiǎn)⒂?GPU 直接存儲(chǔ)技術(shù)時(shí),存儲(chǔ)器和 GPU 內(nèi)存之間的數(shù)據(jù)移動(dòng)。
節(jié)點(diǎn)內(nèi)數(shù)據(jù)傳輸瓶頸
某些工作負(fù)載要求位于同一節(jié)點(diǎn)(服務(wù)器)中的兩個(gè)或多個(gè) GPU 之間進(jìn)行數(shù)據(jù)交換。在 NVIDIA GPUDirect Peer to Peer 技術(shù)不可用的情況下,來(lái)自源 GPU 的數(shù)據(jù)將首先通過(guò) CPU 和 PCIe 總線復(fù)制到主機(jī)固定共享內(nèi)存。然后,數(shù)據(jù)將通過(guò) CPU 和 PCIe 總線從主機(jī)固定共享內(nèi)存復(fù)制到目標(biāo) GPU 。請(qǐng)注意,數(shù)據(jù)在到達(dá)目的地之前復(fù)制了兩次,更不用說(shuō) CPU 和主機(jī)內(nèi)存都參與了這個(gè)過(guò)程。圖 3 描述了前面描述的數(shù)據(jù)移動(dòng)。
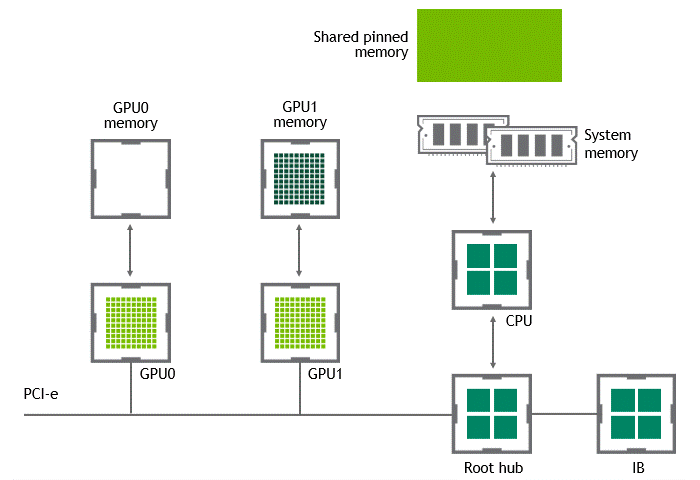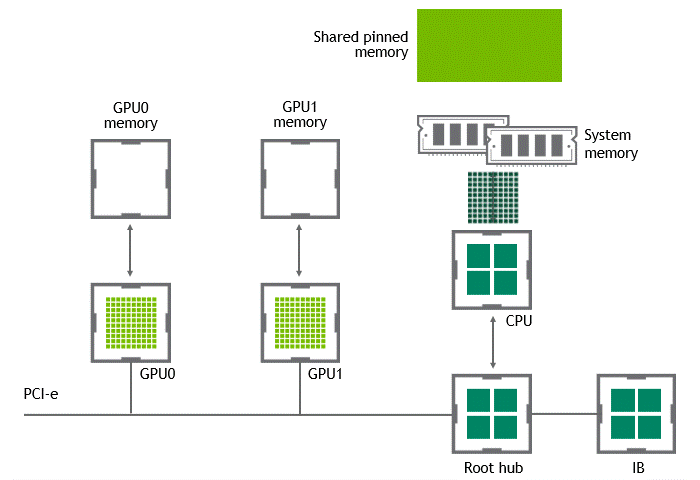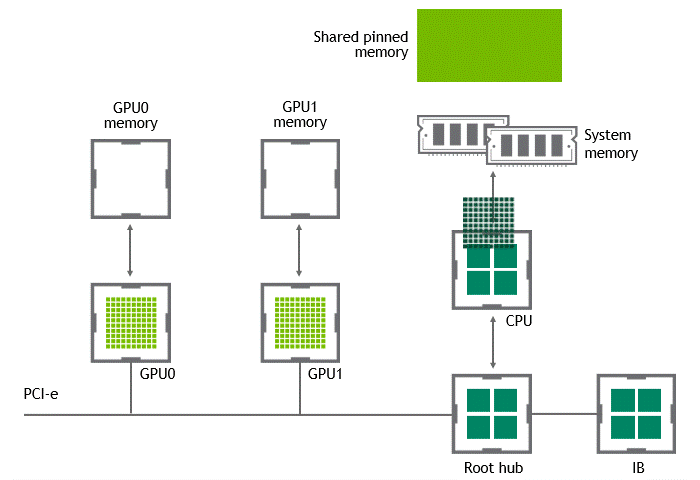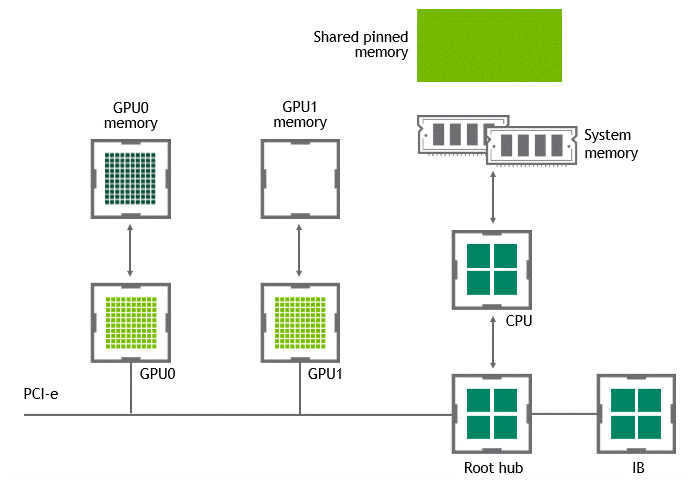
圖 3 :當(dāng) NVIDIA GPU 直接 P2P 不可用時(shí),同一節(jié)點(diǎn)中兩個(gè) GPU 之間的數(shù)據(jù)移動(dòng)。
當(dāng) GPU 直接對(duì)等技術(shù)可用時(shí),將數(shù)據(jù)從源 GPU 復(fù)制到同一節(jié)點(diǎn)中的另一 GPU 不再需要將數(shù)據(jù)臨時(shí)轉(zhuǎn)移到主機(jī)內(nèi)存中。如果兩個(gè) GPU 都連接到同一 PCIe 總線, GPU 直接 P2P 允許在不涉及 CPU 的情況下訪問(wèn)其相應(yīng)的內(nèi)存。前者將執(zhí)行相同任務(wù)所需的復(fù)制操作數(shù)量減半。圖 4 描述了剛才描述的行為。
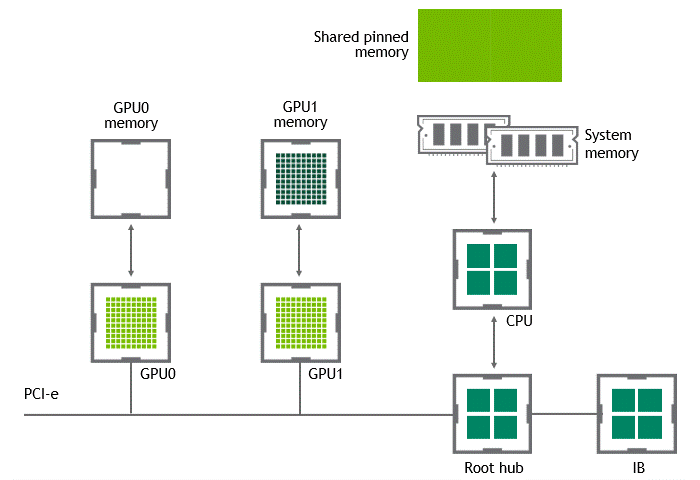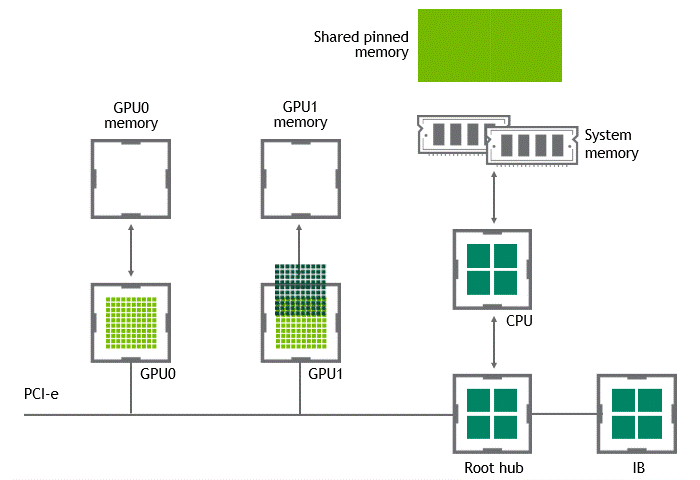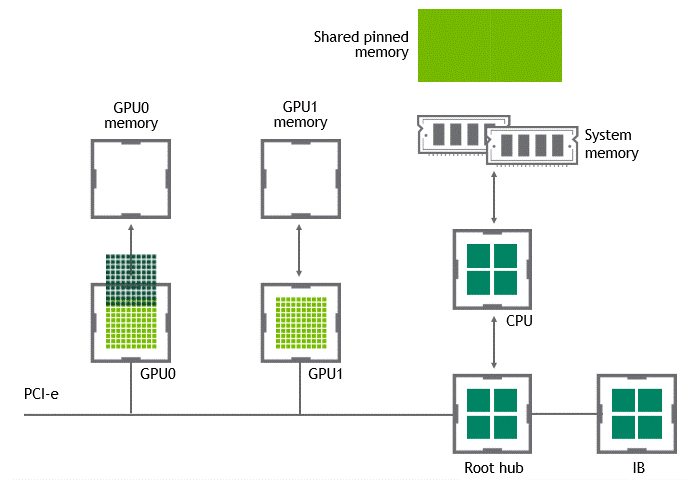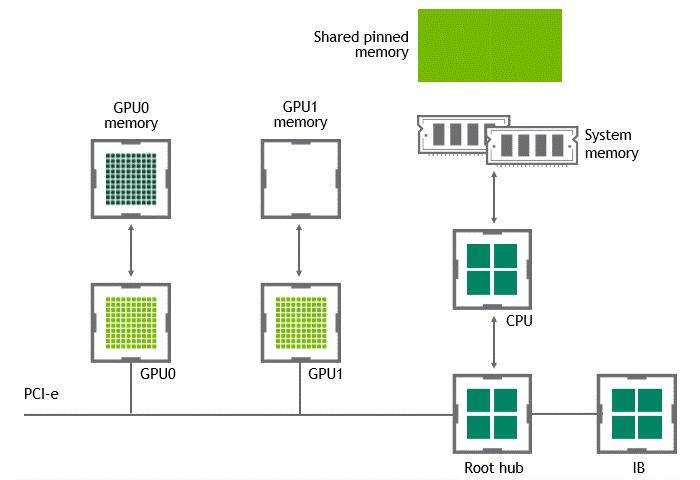
圖 4 :?jiǎn)⒂?NVIDIA GPU 直接 P2P 時(shí),同一節(jié)點(diǎn)中兩個(gè) GPU 之間的數(shù)據(jù)移動(dòng)。
節(jié)點(diǎn)間數(shù)據(jù)傳輸瓶頸
在 NVIDIA GPUDirect Remote Direct Memory Access 技術(shù)不可用的多節(jié)點(diǎn)環(huán)境中,在不同節(jié)點(diǎn)的兩個(gè) GPU 之間傳輸數(shù)據(jù)需要五個(gè)復(fù)制操作:
第一次復(fù)制發(fā)生在將數(shù)據(jù)從源 GPU 傳輸?shù)皆垂?jié)點(diǎn)中主機(jī)固定內(nèi)存的緩沖區(qū)時(shí)。
然后,該數(shù)據(jù)被復(fù)制到源節(jié)點(diǎn)的 NIC 驅(qū)動(dòng)程序緩沖區(qū)。
在第三步中,數(shù)據(jù)通過(guò)網(wǎng)絡(luò)傳輸?shù)侥繕?biāo)節(jié)點(diǎn)的 NIC 驅(qū)動(dòng)程序緩沖區(qū)。
將數(shù)據(jù)從目標(biāo)節(jié)點(diǎn) NIC 的驅(qū)動(dòng)程序緩沖區(qū)復(fù)制到目標(biāo)節(jié)點(diǎn)中主機(jī)固定內(nèi)存的緩沖區(qū)時(shí),會(huì)發(fā)生第四次復(fù)制。
最后一步需要使用 PCIe 總線將數(shù)據(jù)復(fù)制到目標(biāo) GPU 。
這樣總共進(jìn)行了五次復(fù)制操作。真是一次旅行,不是嗎?圖 5 描述了前面描述的過(guò)程。
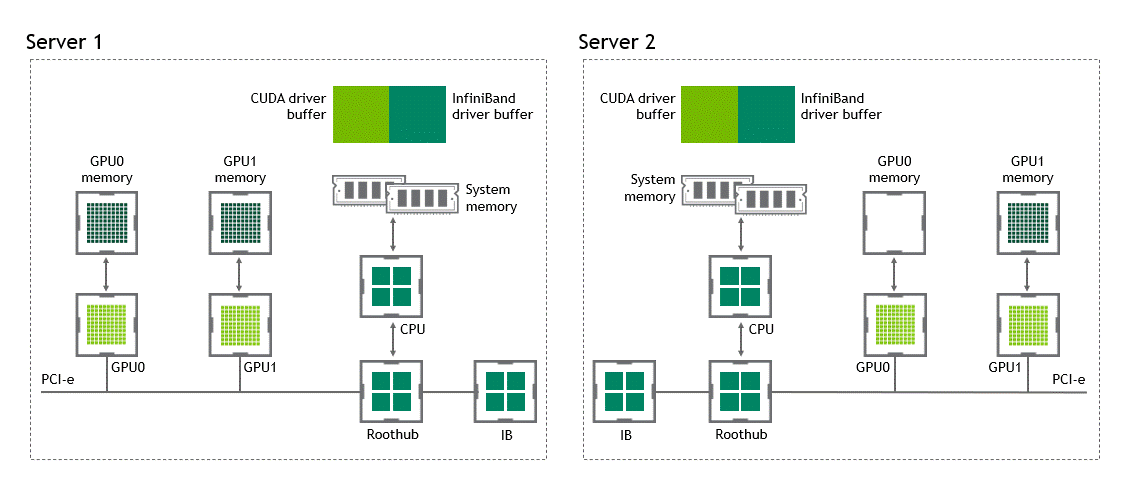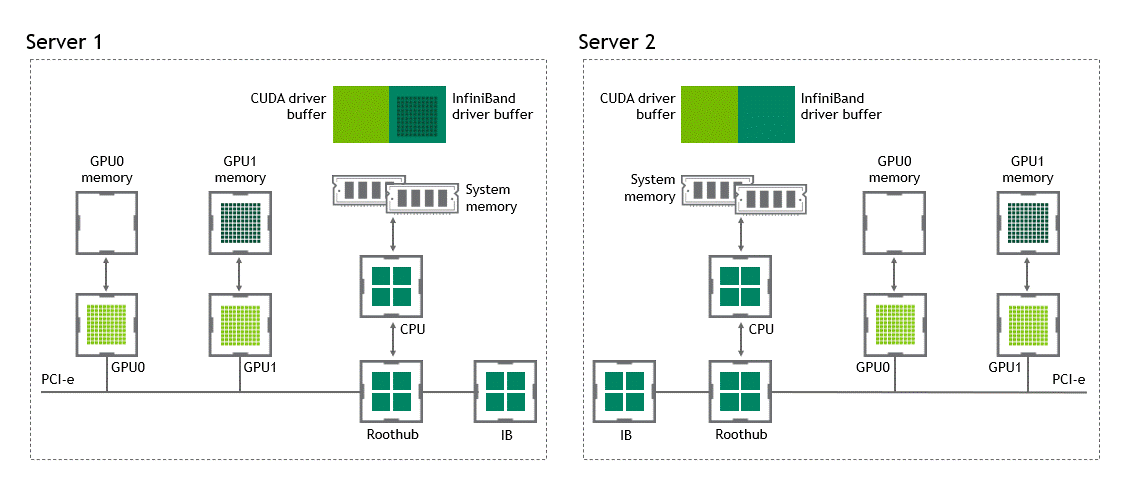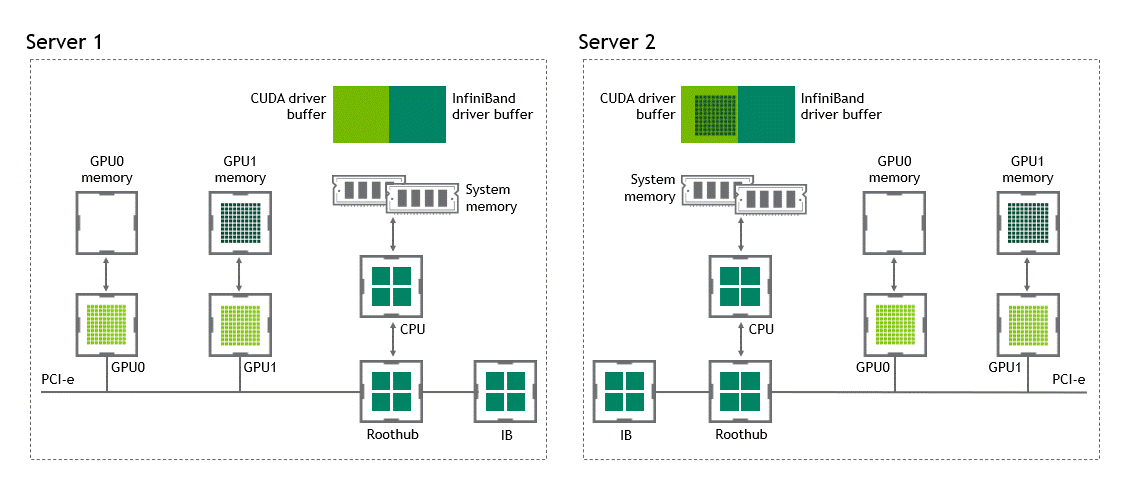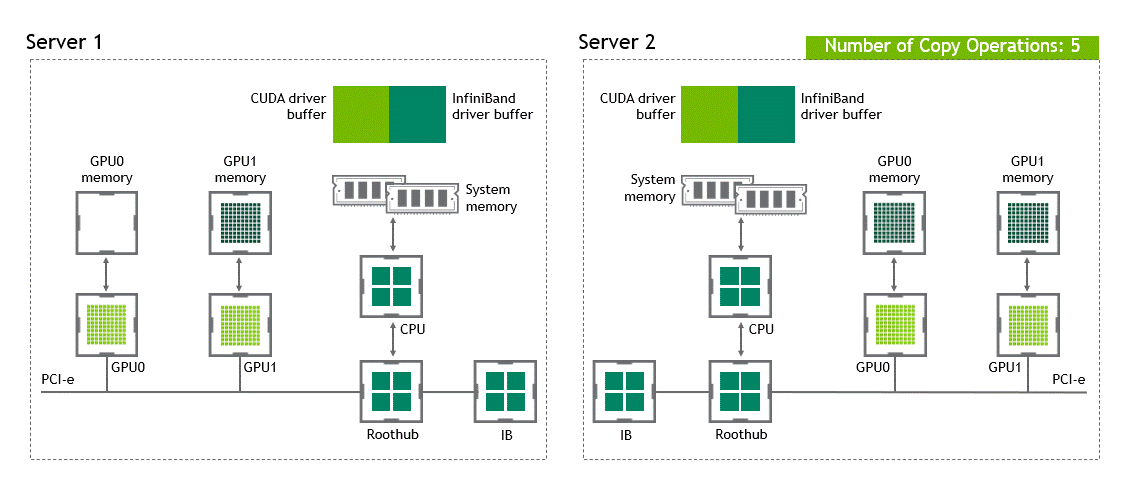
圖 5 :當(dāng) NVIDIA GPU 直接 RDMA 不可用時(shí),不同節(jié)點(diǎn)中兩個(gè) GPU 之間的數(shù)據(jù)移動(dòng)。
啟用 GPU 直接 RDMA 后,數(shù)據(jù)拷貝數(shù)將減少到一個(gè)。共享固定內(nèi)存中不再有中間數(shù)據(jù)拷貝。我們可以在一次運(yùn)行中直接將數(shù)據(jù)從源 GPU 復(fù)制到目標(biāo) GPU 。與傳統(tǒng)設(shè)置相比,這為我們節(jié)省了四個(gè)不必要的復(fù)制操作。圖 6 描述了這個(gè)場(chǎng)景。
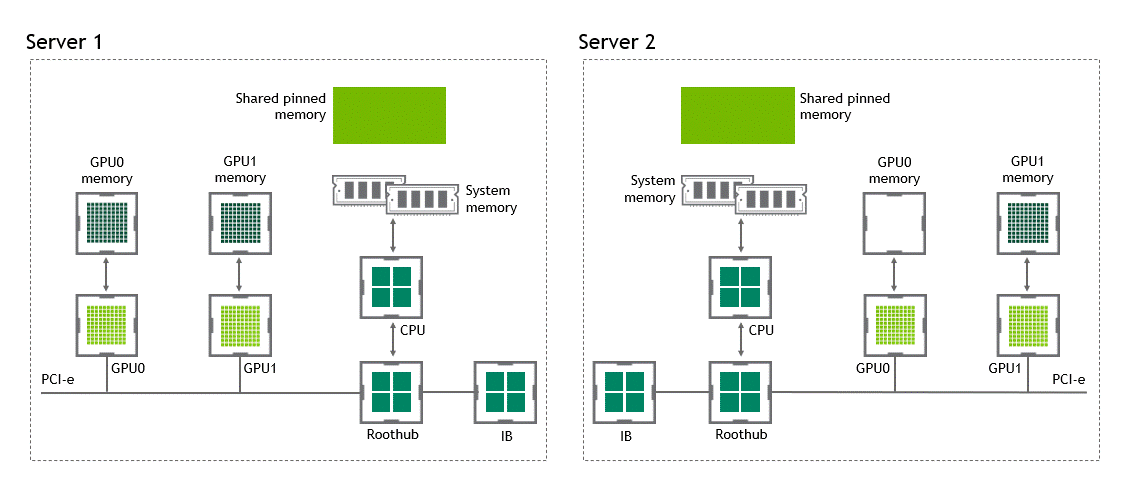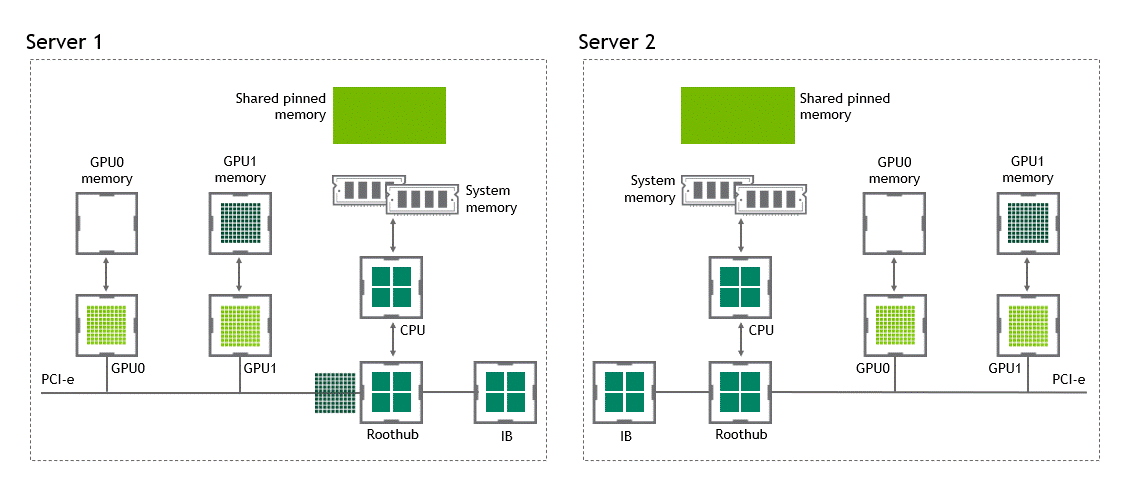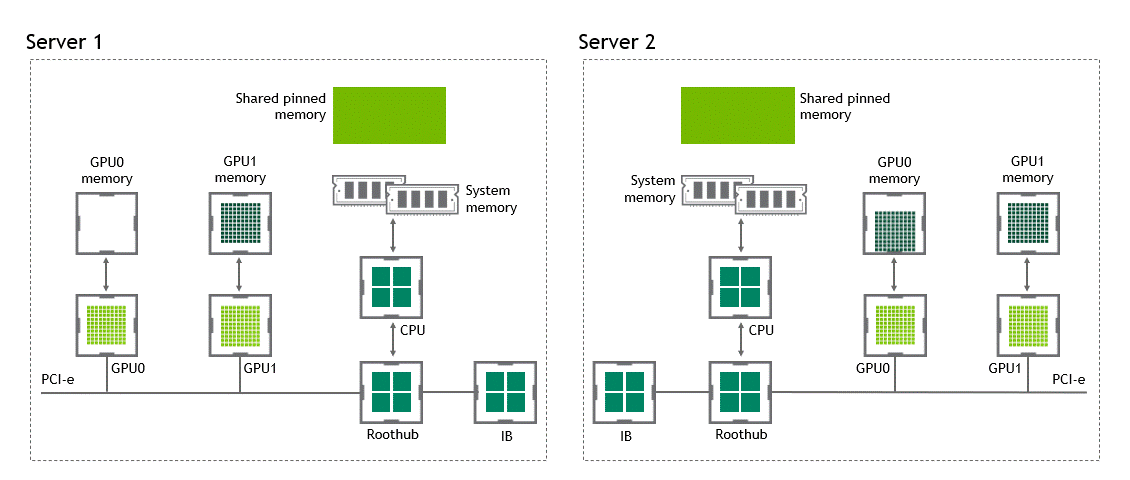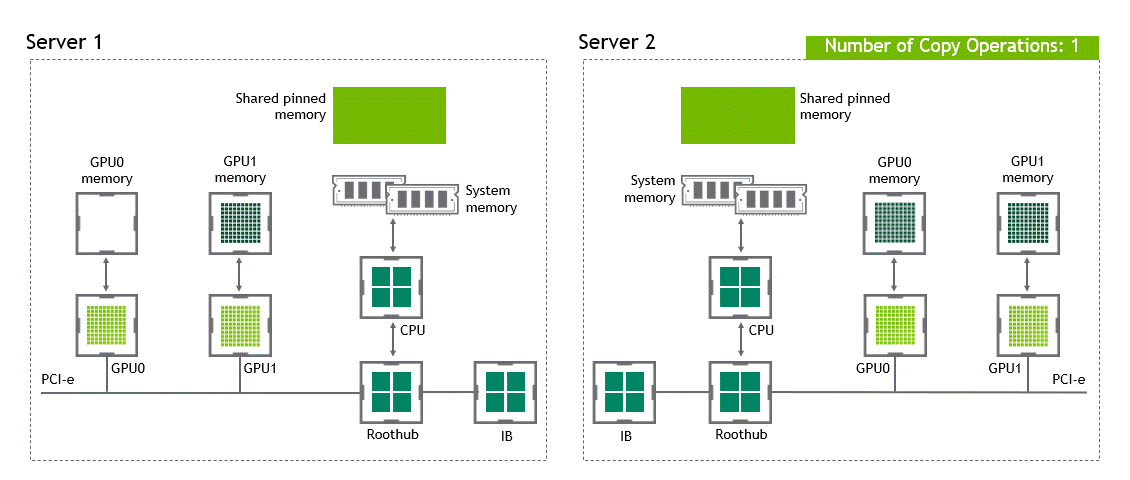
圖 6 :當(dāng) NVIDIA GPU 直接 RDMA 可用時(shí),不同節(jié)點(diǎn)中兩個(gè) GPU 之間的數(shù)據(jù)移動(dòng)。
結(jié)論
在我們的第二篇文章中,您已經(jīng)了解了如何利用 NVIDIA GPU 直接功能來(lái)進(jìn)一步加快管道的數(shù)據(jù)加載和數(shù)據(jù)分發(fā)階段。
在我們?nèi)壳牡谌糠种校覀儗⑸钊胙芯酷t(yī)學(xué)數(shù)據(jù)科學(xué)管道的實(shí)現(xiàn)細(xì)節(jié),該管道用于連續(xù)測(cè)量的心電(ECG)流中的心跳異常檢測(cè)。
關(guān)于作者
Christian Hundt 在德國(guó)美因茨的 Johannes Gutenberg 大學(xué)( JGU )獲得了理論物理的文憑學(xué)位。在他的博士論文中,他研究了時(shí)間序列數(shù)據(jù)挖掘算法在大規(guī)模并行架構(gòu)上的并行化。作為并行和分布式體系結(jié)構(gòu)組的博士后研究員,他專(zhuān)注于各種生物醫(yī)學(xué)應(yīng)用的高效并行化,如上下文感知的元基因組分類(lèi)、基因集富集分析和胸部 mri 的深層語(yǔ)義圖像分割。他目前的職位是深度學(xué)習(xí)解決方案架構(gòu)師,負(fù)責(zé)協(xié)調(diào)盧森堡的 NVIDIA 人工智能技術(shù)中心( NVAITC )的技術(shù)合作。
Miguel Martinez 是 NVIDIA 的高級(jí)深度學(xué)習(xí)數(shù)據(jù)科學(xué)家,他專(zhuān)注于 RAPIDS 和 Merlin 。此前,他曾指導(dǎo)過(guò) Udacity 人工智能納米學(xué)位的學(xué)生。他有很強(qiáng)的金融服務(wù)背景,主要專(zhuān)注于支付和渠道。作為一個(gè)持續(xù)而堅(jiān)定的學(xué)習(xí)者, Miguel 總是在迎接新的挑戰(zhàn)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5258瀏覽量
105852 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5555瀏覽量
122529
發(fā)布評(píng)論請(qǐng)先 登錄
RDMA簡(jiǎn)介2之A技術(shù)優(yōu)勢(shì)分析
樂(lè)鑫 ESP32-C6 通過(guò) Thread 1.4 互操作性認(rèn)證

智能網(wǎng)聯(lián)汽車(chē)云控系統(tǒng)第2部分:車(chē)云數(shù)據(jù)交互規(guī)范
優(yōu)化多相穩(wěn)壓器的高端FET電壓振鈴(第2部分)

如何進(jìn)行電源設(shè)計(jì)-第1部分
如何進(jìn)行電源設(shè)計(jì)–第2部分
電源設(shè)計(jì)方法-第5部分
電源設(shè)計(jì)方法-第6部分
電源設(shè)計(jì)方法-第3部分
電源設(shè)計(jì)方法-第2部分
電源設(shè)計(jì)方法-第1部分
電源設(shè)計(jì)方法-第4部分
如何進(jìn)行電源供應(yīng)設(shè)計(jì)-第3部分
互操作性對(duì)智能家居的重要性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論