 圖像分類與物件檢測兩種應用的數據格式
圖像分類與物件檢測兩種應用的數據格式
前面的系列文章里提過,TAO 工具將模型訓練的絕大部分技術難題都進行抽象化處理,大幅度減輕開發人員的負擔,唯獨數據集的收集與整理仍須由人工自行處理,這幾乎是留給操作人員的最后工作了。
大部分關于數據集的問題就是標注格式的轉換,包括 Pascal VOC、OpenImages、COCO 這些影響力較大的數據集,個別使用 .xml、.csv、.json 等不同的文件格式,包括標注欄位的內容與順序也都不盡相同,這通常是困擾使用者的第一個門檻。
好在這些格式之間的轉換,只需要一些簡單的 Python 小工具就能完成,雖然繁瑣但也沒有什么技術難度。
在https://docs.nvidia.com/tao/tao-toolkit/text/data_annotation_format.html里,提供 TAO 工具針對不同應用類型所支持的格式,簡單整理如下:
圖像分類:目錄結構格式
物件檢測:KITTI 與 COCO 格式
實例分割:COCO 格式
語義分割:UNet 格式
體態識別:COCO 格式
其他:自定義格式
這里只將使用率較高的圖像分類與物件檢測兩種應用的數據格式進行說明,其他應用的數據格式請自行參照前面提供的說明鏈接。
1、圖像分類的“目錄結構”格式:
這是以“圖像”為單位的分類應用,每張圖片只會有一個分類屬性,因此格式相對簡單,只要將圖片根據目錄結構的規則進行分類就可以。

為了配合模型訓練的工作,我們需要將數據集切割成 “train”、“val”、“test” 三大類,分別作為訓練、校驗與測試用途。
在每個數據集下面再延伸出“分類屬性”子目錄,例如做早期用于識別 0~9 手寫數字的 MNIST 數據集,就得在 train/val/test 下面各添加 “0”~“9” 共 10 個子目錄,合計是 2 層 33 個目錄結構。

如果是使用 ILSVRC 競賽的 1000 分類 ImageNet 數據的話,就得根據這 1000 個分類在三個目錄下創建 1000 個分類屬性子目錄,例如 dog、cat、person 等等,雖然很繁瑣但也不復雜,對模型訓練工具而言,圖像文件名稱是無所謂的。
數據來源通常是兩大類,第一種是自行從網上收集與手動拍攝,第二種是從現成數據集進行提取,包括 ImageNet、Pascal VOC、COCO、OpenImages 這些知名的通用數據集,都有非常豐富的資源。
但現在的最大問題是,如何從這些數據集中提取所需要的圖像,并根據“目錄結構”存放成 TAO 所支持的格式?
這個部分需要使用者自行研究所需要的數據集的結構,撰寫簡單的提取工具。例如 TAO 提供的 classification 圖像分類模型訓練范例項目中,使用 Pascal VOC 2012 數據集來進行圖像分類的模型訓練,但是這個數據集使用下圖左的路徑分布方式,與 TAO 所支持的“目錄結構”格式并不相同,那么該如何處理?

我們必須對這個數據集的相關資源有進一步了解。在 VOC 數據集的 ImageSets/Main 里存放 63個.txt 文件,刨去 train.txt、trainval.txt 與 val.txt 三個文件,其余 60 個分屬于數據集的 20 個圖像類別的三種用途,例如 xxx_trainval.txt、xxx_train.txt、xxx_val.txt,其中前者的內容是后面兩個文件的合并。
在 classification.ipynb 腳本中提供兩段數據格式轉換的 Python 代碼(請自行查閱),在 “A.Split the dataset into train/val/test” 的環節,執行以下處理:
(1) 將存放在上圖左邊 “JPEGImages” 里面的圖像文件,借助 xxx_trainval.txt 分類列表的協助,復制到上圖右方的 “formated” 下的 20 個分類子目錄; (2) 從 “formated” 的每一類圖像數據,分別切割出 train/val/test 三大分類,放到 “split” 目錄下,作為后面轉換成 tfrecords 的數據源。
經過兩次轉換處理后,在這里的數據內容就該有 3 份相同的圖像數據,只不過使用不同的路徑結構去存放而已。如果不想浪費存儲空間的話,可以將 VOCdeckit 與 formatted 兩個目錄刪除,只需要保留 split 目錄的結構就足夠。
至于其他數據的轉換,也需要使用者對該數據集有充分的了解,畢竟學習數據轉換的精力要遠遠低于自行收集的時間,絕對是劃算的。
2、物件檢測的 KITTI 格式:
絕大部分通用數據集為了提高普及度,都提供多種應用類別的標注 (annotations) 內容,其中 “物件位置 (location)” 是最基本的數據,其他還有與人體相關的骨骼結構標注、語義分割的材質標注、場景描述的標注等等,每種數據集都有其側重點,因此內容種類與格式也都不盡相同,這是大伙要使用數據集的第一個門檻。
物件檢測是比圖像分類更進一步的深度學習應用,要在一張圖像中找出符合條件的物件,數量沒有限定,就看訓練出來的模型具備哪些分類功能。
每個數據集的差異,就是將所包含的圖像,都進行不同功能與不同細膩度的標注內容,這些動輒數萬張到上千萬張的圖像、分類數量從20到數千的不同數據集,也都使用不同的文件格式去儲存這些標注內容,有些是圖像文件與標注文件一一對應,有些則是將上千萬張的標注內容全部存在一個巨大的標注文件里。
例如 COCO 數據集將數百萬張的標注存放在上百兆的 .json 文件里、 OpenImages 數據集上千萬張的標注存放在 1.3GB 的 .csv 文件中,而 Pascal VOC 與 ImageNet 的標注文件則提供一對一對應的 .txt 與 .xml 格式,莫衷一是。
事實上對應物件檢測的應用,我們只需要標注文件中最基本的元素,包括“類別”與“位置”這兩組共 5 個欄位數據就可以。類別部分有的數據集直接使用“類別名”,有的數據集只提供“類別編號”,然后再到類別文件中尋找對應;位置信息部分,有些提供“左上角”與“右下角”坐標位置,有些使用“起點坐標”與“長寬”來表示,都是一組 4 個浮點值。
因此,要從龐大的數據集中,提取我們所需要的類別與位置標注,就必須對個別標注結構進行研究,才能得到我們想要的結果,這個步驟是跳不過去的。網上雖然有很多標注格式轉換的功能,但是通用性受限制,還是需要進行局部修改。
現在來看看 TAO 工具在物件檢測模型訓練所支持KITTI格式內容,主要欄位如下:
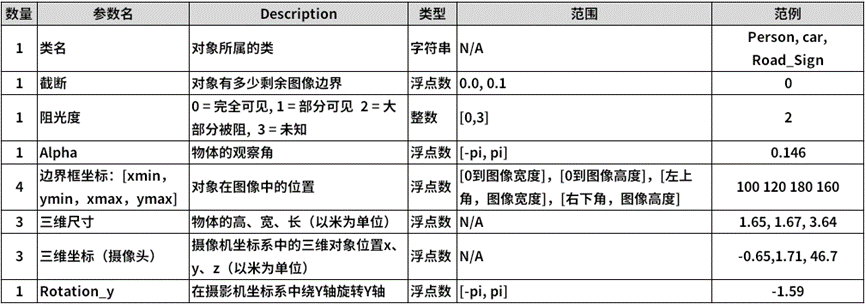
其標注文件是 .txt 純文字格式,在文件內的表達方式如下:

熟悉物件檢測應用的人,可能會覺得這個 KITTI 標注格式中,有一半以上的欄位是用不上的,為何英偉達卻十分偏好這個格式呢?
如果將視野放大到自動駕駛與 3D 應用領域的話,就能理解英偉達選擇這個格式的理由,因為 KITTI 數據集是由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦,是目前國際上最大的自動駕駛場景下的計算機視覺算法評測數據集。
在物件檢測應用中只需要用到“類名”與“邊界框坐標”這兩部分,如果從其他數據集提取數據時只要找出這 5 個數據,如果坐標格式為“起點坐標+長寬”的格式,也能簡單轉換成“起點坐標+重點坐標”形式,寫入對應的 KITTI 標注文件中,其他欄位的內容 “補 0” 就可以,所以整個轉換過程還不是太麻煩。
在 TAO 的視覺項目中的 face-mask-detection/data_utils 里,提供大約 4 轉換成 KITTI 格式的工具,能提供大家作為參考。
只要能將不同數據集之間的格式轉換弄通,就能非常高效的從龐大的數據集資源中,輕松獲取我們所需要的類別數據,進一步訓練出自己專屬的模型,因此這個過程對使用深度學習的工程師是很重要的基本工作。
原文標題:NVIDIA Jetson Nano 2GB 系列文章(58):視覺類的數據格式
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
NVIDIA
+關注
關注
14文章
5258瀏覽量
105852 -
檢測
+關注
關注
5文章
4613瀏覽量
92569 -
數據格式
+關注
關注
0文章
31瀏覽量
9024
原文標題:NVIDIA Jetson Nano 2GB 系列文章(58):?視覺類的數據格式
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用FPGA配置TVP5150,把PAL制標準視頻轉換成BT656數據格式,能否把數據流直接給SAA7121?
使用RDATAC指令后,ADS131E04傳送的數據格式以及內容是怎樣的?
API接口有哪些常見的安全問題

FP8數據格式在大型模型訓練中的應用






 工商網監
工商網監
評論