 CUDA簡介: CUDA編程模型概述
CUDA簡介: CUDA編程模型概述
本章和下一章中使用的向量加法示例的完整代碼可以在 vectorAddCUDA示例中找到。
2.1 內核
CUDA C++ 通過允許程序員定義稱為kernel的 C++ 函數來擴展 C++,當調用內核時,由 N 個不同的 CUDA 線程并行執行 N 次,而不是像常規 C++ 函數那樣只執行一次。
使用__global__聲明說明符定義內核,并使用新的<<<...>>>執行配置語法指定內核調用的 CUDA 線程數(請參閱C++ 語言擴展)。 每個執行內核的線程都有一個唯一的線程 ID,可以通過內置變量在內核中訪問。
作為說明,以下示例代碼使用內置變量threadIdx將兩個大小為 N 的向量 A 和 B 相加,并將結果存儲到向量 C 中:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
這里,執行 VecAdd() 的 N 個線程中的每一個線程都會執行一個加法。
2.2 線程層次
為方便起見,threadIdx 是一個 3 分量向量,因此可以使用一維、二維或三維的線程索引來識別線程,形成一個一維、二維或三維的線程塊,稱為block。 這提供了一種跨域的元素(例如向量、矩陣或體積)調用計算的方法。
線程的索引和它的線程 ID 以一種直接的方式相互關聯:對于一維塊,它們是相同的; 對于大小為(Dx, Dy)的二維塊,索引為(x, y)的線程的線程ID為(x + y*Dx); 對于大小為 (Dx, Dy, Dz) 的三維塊,索引為 (x, y, z) 的線程的線程 ID 為 (x + y*Dx + z*Dx*Dy)。
例如,下面的代碼將兩個大小為NxN的矩陣A和B相加,并將結果存儲到矩陣C中:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<>>(A, B, C);
...
}
每個塊的線程數量是有限制的,因為一個塊的所有線程都應該駐留在同一個處理器核心上,并且必須共享該核心有限的內存資源。在當前的gpu上,一個線程塊可能包含多達1024個線程。
但是,一個內核可以由多個形狀相同的線程塊執行,因此線程總數等于每個塊的線程數乘以塊數。
塊被組織成一維、二維或三維的線程塊網格(grid),如下圖所示。網格中的線程塊數量通常由正在處理的數據的大小決定,通常超過系統中的處理器數量。
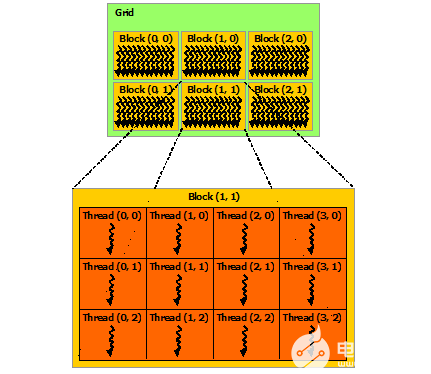
<<<...>>>語法中指定的每個塊的線程數和每個網格的塊數可以是int或dim3類型。如上例所示,可以指定二維塊或網格。
網格中的每個塊都可以由一個一維、二維或三維的惟一索引標識,該索引可以通過內置的blockIdx變量在內核中訪問。線程塊的維度可以通過內置的blockDim變量在內核中訪問。
擴展前面的MatAdd()示例來處理多個塊,代碼如下所示。
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<>>(A, B, C);
...
}
線程塊大小為16×16(256個線程),盡管在本例中是任意更改的,但這是一種常見的選擇。網格是用足夠的塊創建的,這樣每個矩陣元素就有一個線程來處理。為簡單起見,本例假設每個維度中每個網格的線程數可以被該維度中每個塊的線程數整除,盡管事實并非如此。
程塊需要獨立執行:必須可以以任何順序執行它們,并行或串行。 這種獨立性要求允許跨任意數量的內核以任意順序調度線程塊,如下圖所示,使程序員能夠編寫隨內核數量擴展的代碼。
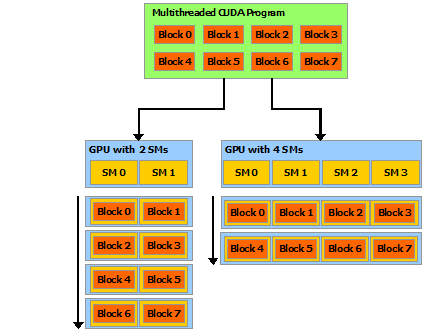
塊內的線程可以通過一些共享內存共享數據并通過同步它們的執行來協調內存訪問來進行協作。 更準確地說,可以通過調用__syncthreads()內部函數來指定內核中的同步點;__syncthreads()充當屏障,塊中的所有線程必須等待,然后才能繼續。Shared Memory給出了一個使用共享內存的例子。 除了__syncthreads()之外,Cooperative Groups API還提供了一組豐富的線程同步示例。
為了高效協作,共享內存是每個處理器內核附近的低延遲內存(很像 L1 緩存),并且__syncthreads()是輕量級的。
2.3 存儲單元層次
CUDA 線程可以在執行期間從多個內存空間訪問數據,如下圖所示。每個線程都有私有的本地內存。 每個線程塊都具有對該塊的所有線程可見的共享內存,并且具有與該塊相同的生命周期。 所有線程都可以訪問相同的全局內存。
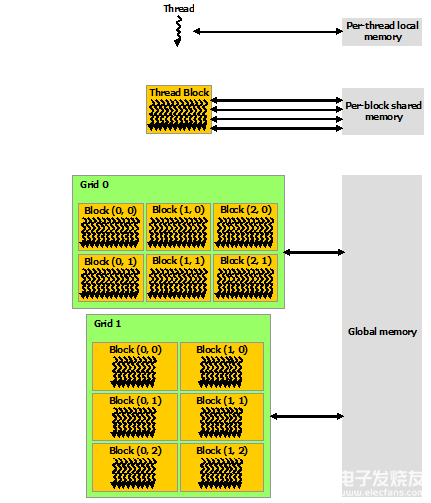
還有兩個額外的只讀內存空間可供所有線程訪問:常量和紋理內存空間。 全局、常量和紋理內存空間針對不同的內存使用進行了優化(請參閱設備內存訪問)。 紋理內存還為某些特定數據格式提供不同的尋址模式以及數據過濾(請參閱紋理和表面內存)。
全局、常量和紋理內存空間在同一應用程序的內核啟動中是持久的。
2.4 異構編程
如下圖所示,CUDA 編程模型假定 CUDA 線程在物理獨立的設備上執行,該設備作為運行 C++ 程序的主機的協處理器運行。例如,當內核在 GPU 上執行而 C++ 程序的其余部分在 CPU 上執行時,就是這種情況。
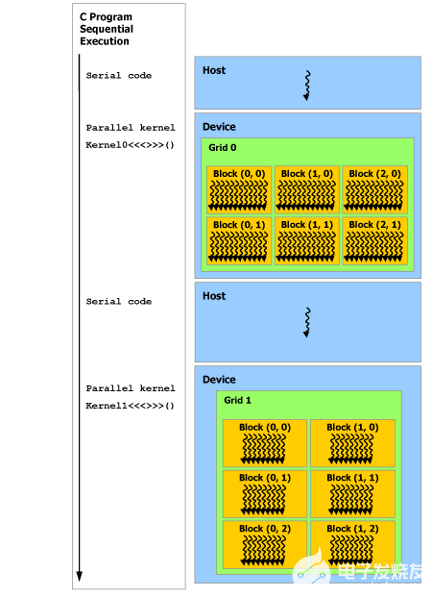
CUDA 編程模型還假設主機(host)和設備(device)都在 DRAM 中維護自己獨立的內存空間,分別稱為主機內存和設備內存。因此,程序通過調用 CUDA 運行時(在編程接口中描述)來管理內核可見的全局、常量和紋理內存空間。這包括設備內存分配和釋放以及主機和設備內存之間的數據傳輸。
統一內存提供托管內存來橋接主機和設備內存空間。托管內存可從系統中的所有 CPU 和 GPU 訪問,作為具有公共地址空間的單個連貫內存映像。此功能可實現設備內存的超額訂閱,并且無需在主機和設備上顯式鏡像數據,從而大大簡化了移植應用程序的任務。有關統一內存的介紹,請參閱統一內存編程。
注:串行代碼在主機(host)上執行,并行代碼在設備(device)上執行。
2.5 異步SIMT編程模型
在 CUDA 編程模型中,線程是進行計算或內存操作的最低抽象級別。 從基于 NVIDIA Ampere GPU 架構的設備開始,CUDA 編程模型通過異步編程模型為內存操作提供加速。 異步編程模型定義了與 CUDA 線程相關的異步操作的行為。
異步編程模型為 CUDA 線程之間的同步定義了異步屏障的行為。 該模型還解釋并定義了如何使用 cuda::memcpy_async 在 GPU計算時從全局內存中異步移動數據。
2.5.1 異步操作
異步操作定義為由CUDA線程發起的操作,并且與其他線程一樣異步執行。在結構良好的程序中,一個或多個CUDA線程與異步操作同步。發起異步操作的CUDA線程不需要在同步線程中.
這樣的異步線程(as-if 線程)總是與發起異步操作的 CUDA 線程相關聯。異步操作使用同步對象來同步操作的完成。這樣的同步對象可以由用戶顯式管理(例如,cuda::memcpy_async)或在庫中隱式管理(例如,cooperative_groups::memcpy_async)。
同步對象可以是cuda::barrier或cuda::pipeline。這些對象在Asynchronous Barrier和Asynchronous Data Copies using cuda::pipeline.中進行了詳細說明。這些同步對象可以在不同的線程范圍內使用。作用域定義了一組線程,這些線程可以使用同步對象與異步操作進行同步。下表定義了CUDA c++中可用的線程作用域,以及可以與每個線程同步的線程。

這些線程作用域是在CUDA標準c++庫中作為標準c++的擴展實現的。
2.6 Compute Capability
設備的Compute Capability由版本號表示,有時也稱其“SM版本”。該版本號標識GPU硬件支持的特性,并由應用程序在運行時使用,以確定當前GPU上可用的硬件特性和指令。
Compute Capability包括一個主要版本號X和一個次要版本號Y,用X.Y表示
主版本號相同的設備具有相同的核心架構。設備的主要修訂號是8,為NVIDIA Ampere GPU的體系結構的基礎上,7基于Volta設備架構,6設備基于Pascal架構,5設備基于Maxwell架構,3基于Kepler架構的設備,2設備基于Fermi架構,1是基于Tesla架構的設備。
次要修訂號對應于對核心架構的增量改進,可能包括新特性。
Turing是計算能力7.5的設備架構,是基于Volta架構的增量更新。
CUDA-Enabled GPUs列出了所有支持 CUDA 的設備及其計算能力。Compute Capabilities給出了每個計算能力的技術規格。
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5267瀏覽量
105906 -
gpu
+關注
關注
28文章
4920瀏覽量
130778 -
人工智能
+關注
關注
1804文章
48820瀏覽量
247280
發布評論請先 登錄
使用NVIDIA CUDA-X庫加速科學和工程發展
借助PerfXCloud和dify開發代碼轉換器

【「大模型啟示錄」閱讀體驗】對大模型更深入的認知
使用英特爾AI PC為YOLO模型訓練加速






 工商網監
工商網監
評論