") 什么是BERT?為何選擇BERT?
什么是BERT?為何選擇BERT?
BERT 是由 Google 開發(fā)的自然語言處理模型,可學習文本的雙向表示,顯著提升在情境中理解許多不同任務(wù)中的無標記文本的能力。
BERT 是整個類 BERT 模型(例如 RoBERTa、ALBERT 和 DistilBERT)系列的基礎(chǔ)。
什么是 BERT?
基于 Transformer (變換器)的雙向編碼器表示 (BERT) 技術(shù)由 Google 開發(fā),通過在所有層中共同調(diào)整左右情境,利用無標記文本預(yù)先訓練深度雙向表示。該技術(shù)于 2018 年以開源許可的形式發(fā)布。Google 稱 BERT 為“第一個深度雙向、無監(jiān)督式語言表示,僅使用純文本語料庫預(yù)先進行了訓練”(Devlin et al. 2018)。
雙向模型在自然語言處理 (NLP) 領(lǐng)域早已有應(yīng)用。這些模型涉及從左到右以及從右到左兩種文本查看順序。BERT 的創(chuàng)新之處在于借助 Transformer 學習雙向表示,Transformer 是一種深度學習組件,不同于遞歸神經(jīng)網(wǎng)絡(luò) (RNN) 對順序的依賴性,它能夠并行處理整個序列。因此可以分析規(guī)模更大的數(shù)據(jù)集,并加快模型訓練速度。Transformer 能夠使用注意力機制收集詞語相關(guān)情境的信息,并以表示該情境的豐富向量進行編碼,從而同時處理(而非單獨處理)與句中所有其他詞語相關(guān)的詞語。該模型能夠?qū)W習如何從句段中的每個其他詞語衍生出給定詞語的含義。
之前的詞嵌入技術(shù)(如 GloVe 和 Word2vec)在沒有情境的情況下運行,生成序列中各個詞語的表示。例如,無論是指運動裝備還是夜行動物,“bat”一詞都會以同樣的方式表示。ELMo 通過雙向長短期記憶模型 (LSTM),對句中的每個詞語引入了基于句中其他詞語的深度情景化表示。但 ELMo 與 BERT 不同,它單獨考慮從左到右和從右到左的路徑,而不是將其視為整個情境的單一統(tǒng)一視圖。
由于絕大多數(shù) BERT 參數(shù)專門用于創(chuàng)建高質(zhì)量情境化詞嵌入,因此該框架非常適用于遷移學習。通過使用語言建模等自我監(jiān)督任務(wù)(不需要人工標注的任務(wù))訓練 BERT,可以利用 WikiText 和 BookCorpus 等大型無標記數(shù)據(jù)集,這些數(shù)據(jù)集包含超過 33 億個詞語。要學習其他任務(wù)(如問答),可以使用適合相應(yīng)任務(wù)的內(nèi)容替換并微調(diào)最后一層。
下圖中的箭頭表示三個不同 NLP 模型中從一層到下一層的信息流。
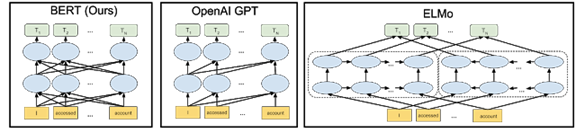
BERT 模型能夠更精細地理解表達的細微差別。例如,處理序列“Bob 需要一些藥。他的胃不舒服,可以給他拿一些抗酸藥嗎?” BERT 能更好地理解 “Bob”、“他的”和“他”都是指同一個人。以前,在“如何填寫 Bob 的處方”這一查詢中,模型可能無法理解第二句話引用的人是 Bob。應(yīng)用 BERT 模型后,該模型能夠理解所有這些關(guān)聯(lián)點之間的關(guān)系。
雙向訓練很難實現(xiàn),因為默認情況下,在前一個詞語和下一個詞語的基礎(chǔ)上調(diào)節(jié)每個詞都包括多層模型中預(yù)測的詞語。BERT 的開發(fā)者通過遮蔽語料庫中的預(yù)測詞語和其他隨機詞語解決了這個問題。BERT 還使用一種簡單的訓練技術(shù),嘗試預(yù)測給定的兩個句子 A 和 B:B 和 A 是先后還是隨機關(guān)系。
為何選擇 BERT?
自然語言處理是當今許多商業(yè)人工智能研究的中心。例如,除搜索引擎外,NLP 還用在了數(shù)字助手、自動電話響應(yīng)和車輛導航領(lǐng)域。BERT 是一項顛覆性技術(shù),它提供基于大型數(shù)據(jù)集訓練的單一模型,而且已經(jīng)證實該模型能夠在各種 NLP 任務(wù)中取得突破性成果。
BERT 的開發(fā)者表示,模型應(yīng)用范圍很廣(包括解答問題和語言推理),而且無需對任務(wù)所需的具體架構(gòu)做出大量修改。BERT 不需要使用標記好的數(shù)據(jù)預(yù)先進行訓練,因此可以使用任何純文本進行學習。
主要優(yōu)勢(用例)
BERT 可以針對許多 NLP 任務(wù)進行微調(diào)。它是翻譯、問答、情感分析和句子分類等語言理解任務(wù)的理想之選。
目標式搜索
雖然如今的搜索引擎能夠非常出色地理解人們要尋找的內(nèi)容(在人們使用正確查詢格式的前提下),但仍可以通過很多方式改善搜索體驗。對于語法能力差或不懂得搜索引擎提供商所用語言的人員而言,體驗可能令人不快。搜索引擎還經(jīng)常需要用戶嘗試同一查詢的不同變體,才能查詢到理想結(jié)果。
用戶每天在 Google 上執(zhí)行 35 億次搜索,搜索體驗改進后,一天就可以減少 10% 的搜索量,長期累積下來將大幅節(jié)省時間、帶寬和服務(wù)器資源。從業(yè)務(wù)角度來看,它還使搜索提供商能夠更好地了解用戶行為,并投放更具針對性的廣告。
通過幫助非技術(shù)用戶更準確地檢索信息,并減少因查詢格式錯誤帶來的錯誤,可以更好地理解自然語言,從而提高數(shù)據(jù)分析和商業(yè)智能工具的效果。
輔助性導航
在美國,超過八分之一的人有殘疾,而且許多人在物理和網(wǎng)絡(luò)空間中導航的能力受到了限制。對于必須使用語音來控制輪椅、與網(wǎng)站交互和操作周圍設(shè)備的人員而言,自然語言處理是生活必需品。通過提高對語音命令的響應(yīng)能力,BERT 等技術(shù)可以提高生活質(zhì)量,甚至可以在需要快速響應(yīng)環(huán)境的情況下提高人身安全。
BERT 的重要意義
機器學習研究人員
BERT 在自然語言處理方面引發(fā)的變革等同于計算機視覺領(lǐng)域的 AlexNet,在該領(lǐng)域具有顯著的革命性意義。僅需替換網(wǎng)絡(luò)的最后一層,便可針對一些新任務(wù)定制網(wǎng)絡(luò),這項功能意味著用戶可輕松將其應(yīng)用于任何感興趣的研究領(lǐng)域。無論用戶的目標是翻譯、情感分析還是執(zhí)行一些尚未提出的新任務(wù),都可以快速配置網(wǎng)絡(luò)以進行嘗試。截至目前,有關(guān)該模型的引文超過 8000 篇,其衍生用例不斷證明該模型在處理語言任務(wù)方面的先進水平。
軟件開發(fā)者
由于針對大型數(shù)據(jù)集預(yù)先訓練過的模型的廣泛可用性,BERT 大大減少了先進模型在投入生產(chǎn)時受到的計算限制。此外,將 BERT 及其衍生項納入知名庫(如 Hugging Face)意味著,機器學習專家不需要啟動和運行基礎(chǔ)模型了。
BERT 在自然語言解讀方面達到了新的里程碑,與其他模型相比展現(xiàn)了更強大的功能,能夠理解更復(fù)雜的人類語音并能更精確地回答問題。
BERT 為何可在 GPU 上表現(xiàn)更突出
對話式 AI 是人類與智能機器和應(yīng)用程序(從機器人和汽車到家庭助手和移動應(yīng)用)互動的基礎(chǔ)構(gòu)建塊。讓計算機理解人類語言及所有細微差別,并做出適當?shù)姆磻?yīng),這是 AI 研究人員長期以來的追求。但是,在采用加速計算的現(xiàn)代 AI 技術(shù)出現(xiàn)之前,構(gòu)建具有真正自然語言處理 (NLP) 功能的系統(tǒng)是無法實現(xiàn)的。
BERT 在采用 NVIDIA GPU 的超級計算機上運行,以訓練其龐大的神經(jīng)網(wǎng)絡(luò)并實現(xiàn)超高的 NLP 準確性,從而影響已知的人類語言理解領(lǐng)域。雖然目前有許多自然語言處理方法,但讓 AI 具有類似人類的語言能力仍然是難以實現(xiàn)的目標。隨著 BERT 等基于 Transformer 的大規(guī)模語言模型的出現(xiàn),以及 GPU 成為這些先進模型的基礎(chǔ)設(shè)施平臺,我們看到困難的語言理解任務(wù)快速取得了進展。數(shù)十年來,這種 AI 一直備受期待。有了 BERT,這一刻終于到來了。
模型復(fù)雜性提升了 NLP 準確性,而規(guī)模更大的語言模型可顯著提升問答、對話系統(tǒng)、總結(jié)和文章完結(jié)等自然語言處理 (NLP) 應(yīng)用程序的技術(shù)水平。BERT-Base 使用 1.1 億個參數(shù)創(chuàng)建而成,而擴展的 BERT-Large 模型涉及 3.4 億個參數(shù)。訓練高度并行化,因此可以有效利用 GPU 上的分布式處理。BERT 模型已證明能夠有效擴展為 39 億個參數(shù)的 Megatron-BERT 等大規(guī)模模型。
BERT 的復(fù)雜性以及訓練大量數(shù)據(jù)集方面的需求對性能提出了很高的要求。這種組合需要可靠的計算平臺來處理所有必要的計算,以實現(xiàn)快速執(zhí)行并提高準確性。這些模型可以處理大量無標記數(shù)據(jù)集,因此成為了現(xiàn)代 NLP 的創(chuàng)新中心,另外在很多用例中,對于即將推出的采用對話式 AI 應(yīng)用程序的智能助手而言,這些模型都是上佳之選。
NVIDIA 平臺提供可編程性,可以加速各種不同的現(xiàn)代 AI,包括基于 Transformer 的模型。此外,數(shù)據(jù)中心擴展設(shè)計加上軟件庫,以及對先進 AI 框架的直接支持,為承擔艱巨 NLP 任務(wù)的開發(fā)者提供無縫的端到端平臺。
在使用 NVIDIA 的 DGX SuperPOD 系統(tǒng)(基于連接了 HDR InfiniBand 的大規(guī)模 DGX A100 GPU 服務(wù)器集群)進行的一項測試中,NVIDIA 使用 MLPerf Training v0.7 基準實現(xiàn)了 0.81 分鐘的 BERT 訓練時間,創(chuàng)造了記錄。相比之下,Google 的 TPUv3 在同一測試中所用時間超過了 56 分鐘。
審核編輯 :李倩
-
編碼器
+關(guān)注
關(guān)注
45文章
3784瀏覽量
137452 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
5171瀏覽量
73292 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14059
原文標題:NVIDIA 大講堂 | 什么是 BERT ?
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
中科馭數(shù)DPU助力大模型訓練和推理

為何選擇GraphPad Prism
ADTF為何能贏得奧迪、博世等巨頭的青睞?

【「大模型啟示錄」閱讀體驗】如何在客服領(lǐng)域應(yīng)用大模型
開關(guān)電源輸出電容容值的選擇:為何不能太小也不能太大?
實際項目開發(fā)中為何選擇ARM? Cortex?-M4 內(nèi)核的HK32MCU?
TAS5421的參考設(shè)計中,BOM表給出的470pF緩沖電容耐壓值為何選擇250V換成50V的耐壓值可以嗎?
聯(lián)訊儀器高速光模塊 All In One 測試方案介紹 (二)

內(nèi)置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

聯(lián)訊儀器 高速光模塊 All In One 測試方案介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論