 非結構化數據存儲的六大挑戰及解決方法
非結構化數據存儲的六大挑戰及解決方法
專家介紹:王伯韜
24年IT行業經驗。1998年加入國際商業機器(中國)有限公司,先后在中國技術支持中心、系統和科技事業部、企業IT架構師團隊、IBM中國系統中心等部門工作。獲得IBM高級認證系統架構師(Senior Certified IT Architect),參與過國內多家電信企業、大型公共服務機構的IT系統架構設計項目。目前擔任IBM中國科技事業部存儲團隊架構師。
真實經歷引發的思考
2022年5月2日下午12:05 我收到了以下流調短信與電話:
[北京市疾控中心提示]您好!根據市衛健委通報的新冠疫情,經流行病學調查,您與感染者存在時空交集,有感染風險。請您及時向所在社區和單位報告....
此時,發現北京健康寶已彈窗,隨后接到流調工作人員電話。
流調員:“請問您4月30日下午2點是否去過朝陽區xx商場,xx餐館”
我:“稍等我看一下……,當時沒有去過您提到的幾個地點,但是去過幾個街區之外的xx吃飯,不過有可能開車經過了您提到的地方”
流調員:“好的,那您去所在社區居委會報備,說明情況,持24小時核酸并簽署承諾書,然后可以解除彈窗。”
疫情期間當我們的身邊發現確診病例,大家都希望看到這些人的行動軌跡,如果發生了時空關聯,就會收到上面的信息和電話。目前,疫情防控已經變成了我們生活的一部分。大家都希望通過精準科學的方式找到疫情防控和正常生活的平衡點,但又談何容易。我們可以從數據流向推測和分析事件的成因。然而極致的“精準”,需要數據量足夠多,包括手機位置信息,流調人員的排查信息,現場流調信息等等。同時,數據量暴漲也是需要面對的問題。
其實,近年來各個行業的數據量都呈幾何級增長。如今,隨著傳統業務轉型,新時代業務云計算、大數據分析、人工智能等新一代應用的出現,非結構化數據并行文件存儲給各行各業帶來了諸多挑戰。
一家人工智能芯片的企業于2017年流片量產了中國首款邊緣AI芯片,2019年量產了中國首款車規級AI芯片,憑借30億美金估值成為全球估值最高的AI芯片獨角獸企業。然而,隨著企業逐漸從初創企業走向成熟,其在數據存儲、管理和調度等方面遇到了一些難題。
其中一個比較突出的問題是數據豎井。在發展初期,往往以項目方式組織資源和部署數據結構,很多項目各有數據集群,形成了一個個數據豎井,或說數據孤島。對于需要“小步快跑”的初創企業而言,這種方式無可厚非,但隨著企業規模擴大,這些相互獨立的數據豎井就會給數據管理帶來比較大的挑戰。
從更大的層面看,他們也面臨跨多云數據調度的難題。對于AI企業而言,提高模型訓練效率是至關重要的,但訓練效率的提高不僅僅依賴于計算資源,也離不開數據的及時調度。由于GPU資源分布在多個公有云上和本地,當GPU資源不斷變化時,如何讓數據也能快速地跟隨變化隨需調度,也成為企業在數據管理方面的一個核心需求。
此外,隨著數據規模的快速增長,數據管理成本也與日俱增。之前是采用算存一體的方式,計算和存儲在一個一體機上實現,隨著數據規模增長,這種方案不僅會降低計算設備運行效率,而且成本也會高企不下,因此需要性價比更高的數據存儲方案來支持企業的長遠發展。
在醫療行業,信息化起步較早,在長期的發展過程中,各業務系統都針對初始單個業務模塊的需求陸續建設了很多“煙囪工程“。此外,醫療行業對數據合規要求有其特殊性,門診電子病歷往往需要保留15年以上。數據量的增長使得存儲成本難以控制,同時管理、擴展和維護數據在線訪問的復雜性大大提高。新一代工作負載,面臨數據存儲、數據集成、數據可訪問性、應用程序數據集成等問題,無法實現現代化應用程序;環境數據分散,存儲在太多不同的地理位置,沒有數據集成,沒有通用的管理能力,數據孤島使得數據查詢和使用異常困難。這就需要一個企業級的、真正的全球共享數據湖基礎架構,更快交付洞察,底層存儲必須同時支持新時代的大數據和傳統的應用,具備安全性、可靠性和高性能。
數據管理之六大挑戰
為了應對云計算、大數據分析、人工智能等新一代應用,我們的企業往往在非結構化數據存儲中遇到諸多挑戰:
挑戰1:當前架構無法應對海量數據增長,無序擴展,存在嚴重的性能瓶頸。傳統的SAN文件系統和NAS文件系統,受限于其單個控制器的性能和元數據的處理方式,無法提供更高性能的IO訪問,NAS文件系統擴展方式是按照SAN或者NAS的控制器擴展,控制器之間不能實現并行IO操作,無法避免單機頭帶來的性能瓶頸,并因為文件目錄的名稱改變而導致應用重新定義。
挑戰2:數據孤島。企業超過50%的數據存放在離散的存儲系統中,企業環境的數據分散,存儲在太多不同的地理位置,數據孤島使得數據查詢和使用異常困難。數據量的增長使得存儲成本難以控制,同時管理、擴展和維護數據在線訪問的復雜性大大提高。
挑戰3:缺乏企業級的統一數據管理平臺。傳統的SAN文件系統和NAS文件系統本身不具備智能的、基于策略自動執行的生命周期管理,需要借助單獨的軟件或者硬件實現數據的分層和備份,導致數據管理困難。
挑戰4:無法為未來前沿技術提供有效存儲支撐。如云計算的數據需求并行存儲能夠支持多云架構,統一資源管理,數據安全和高可用。人工智能需求海量數據集存儲,大算力。大數據分析業務需求高效分析和高可用。
挑戰5:新技術帶來的潛在的基礎架構“割裂”,沒有全局的統一命名空間,難以實現數據共享和安全共享。
挑戰6:無可靠的高可用、完整性。不能統一管理和部署,提升運維復雜度。不能支持存儲異構,不同NAS機頭無法統一存儲空間。故障數據重構開銷大,對性能影響較大。
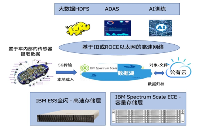
高性能ESS給出最優解
為了應對以上挑戰,IBM最新發布了基于 Spectrum Scale 的ESS3500,它包括以下特點:
1. 極致的性能和可擴展性:可以從小規模開始構建,然后逐步擴展性能和容量,無任何瓶頸,能夠提供極致的數據、元數據和閃存可擴展性。無瓶頸的架構提高了性能,從而實現極大的吞吐量和低延遲訪問。IBM ESS 3500在每個單一節點上提供1PBe,吞吐量高達91GB/秒。
2. 統一存儲,適用于集群、HDFS、文件、對象與容器環境。
3. 加速AI訓練:配合 NVIDIA DGX 系統,AI訓練時間縮短 140%。
4. 統一命名空間。實現全球協作:Spectrum Scale 通過主動文件管理分布式磁盤高速緩存技術,跨不同存儲和位置隨時隨地訪問數據,在數據中心或全球范圍內實現應用加速。
5. 數據完整性和安全性:認證、加密、安全和復制選項,用于滿足業務和法規需求。
最后,我想說的是……
各行各業的數字化難題不斷涌現,IBM伴隨很多客戶,一步步突破最新的AI和云計算的性能極限,成就了他們的創新和發展。疫情防控也一樣,不僅需要技術的支撐,也需要各方的共同努力、每個人的積極配合,希望世界早日恢復生機蓬勃。
原文標題:我們期望的 “精準”,談何容易
文章出處:【微信公眾號:IBM中國】歡迎添加關注!文章轉載請注明出處。
-
IBM
+關注
關注
3文章
1813瀏覽量
75545 -
數據管理
+關注
關注
1文章
312瀏覽量
19961 -
數據存儲
+關注
關注
5文章
997瀏覽量
51640
原文標題:我們期望的 “精準”,談何容易
文章出處:【微信號:IBMGCG,微信公眾號:IBM中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
DDN攜手NVIDIA釋放非結構化數據的AI價值
從零到一:如何利用非結構化數據中臺快速部署AI解決方案

非結構化數據中臺:企業AI應用安全落地的核心引擎
彈性云服務器通過什么存儲數據和文件?
IBM Storage -?支持AI應用場景的數據存儲軟硬件解決方案
AIGC與傳統內容生成的區別 AIGC的優勢和挑戰
結構化布線在AI數據中心的關鍵作用
六類非屏蔽網絡模塊有哪些
戴爾升級非結構化存儲與數據管理,AI創新引領新變革
基于深度學習的三維點云分類方法





 工商網監
工商網監
評論