") 如何在Prompt Learning下引入外部知識達(dá)到好文本分類效果
如何在Prompt Learning下引入外部知識達(dá)到好文本分類效果

背景
利用Prompt Learning(提示學(xué)習(xí))進(jìn)行文本分類任務(wù)是一種新興的利用預(yù)訓(xùn)練語言模型的方式。在提示學(xué)習(xí)中,我們需要一個標(biāo)簽詞映射(verbalizer),將[MASK]位置上對于詞表中詞匯的預(yù)測轉(zhuǎn)化成分類標(biāo)簽。例如{POLITICS: "politics", SPORTS: "sports"} 這個映射下,預(yù)訓(xùn)練模型在[MASK]位置對于politics/sports這個標(biāo)簽詞的預(yù)測分?jǐn)?shù)會被當(dāng)成是對POLITICS/SPORTS這個標(biāo)簽的預(yù)測分?jǐn)?shù)。
手工定義或自動搜索得到的verbalizer有主觀性強(qiáng)覆蓋面小等缺點,我們使用了知識庫來進(jìn)行標(biāo)簽詞的擴(kuò)展和改善,取得了更好的文本分類效果。同時也為如何在Prompt Learning下引入外部知識提供了參考。
方法
我們提出使用知識庫擴(kuò)展標(biāo)簽詞,通過例如相關(guān)詞詞表,情感詞典等工具,基于手工定義的初始標(biāo)簽詞進(jìn)行擴(kuò)展。例如,可以將{POLITICS: "politics", SPORTS: "sports"} 擴(kuò)展為以下的一些詞:
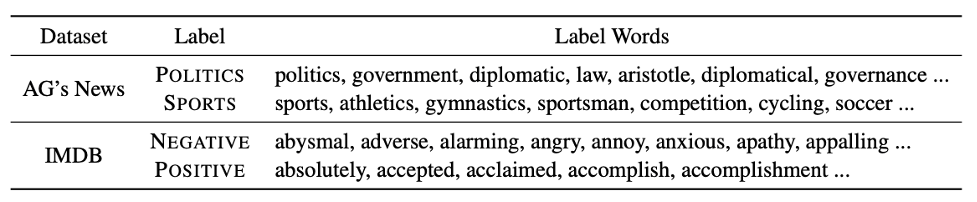
表1: 基于知識庫擴(kuò)展出的標(biāo)簽詞。
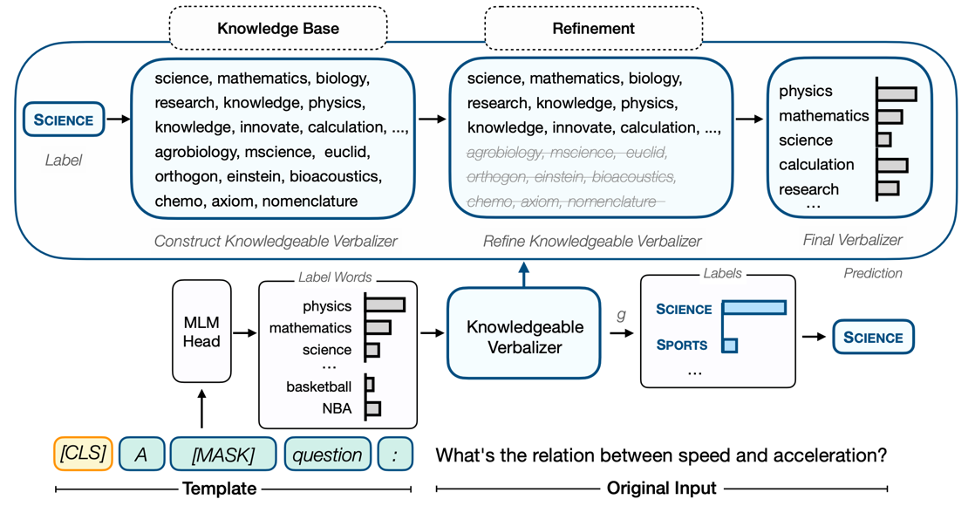
圖1: 以問題分類任務(wù)為例的KPT流程圖。
之后我們可以通過一個多對一映射將多個詞上的預(yù)測概率映射到某個標(biāo)簽上。
但是由于知識庫不是為預(yù)訓(xùn)練模型量身定做的,使用知識庫擴(kuò)展出的標(biāo)簽詞具有很大噪音。例如SPORTS擴(kuò)展出的movement可能和POLITICS相關(guān)性很大,從而引起混淆;又或者POLITICS擴(kuò)展出的machiavellian(為奪取權(quán)力而不擇手段的)則可能由于詞頻很低不容易被預(yù)測到,甚至被拆解成多個token而不具有詞語本身的意思。
因此我們提出了三種精調(diào)以及一種校準(zhǔn)的方法。
01
頻率精調(diào)
我們利用預(yù)訓(xùn)練模型M本身對于標(biāo)簽詞v的輸出概率當(dāng)成標(biāo)簽詞的先驗概率,用來估計標(biāo)簽詞的先驗出現(xiàn)頻率。我們把頻率較小的標(biāo)簽詞去掉。
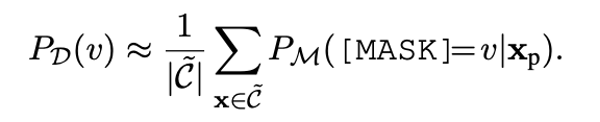
公式1: 頻率精調(diào)。C代表語料庫。
02
相關(guān)性精調(diào)
有的標(biāo)簽詞和標(biāo)簽相關(guān)性不大,有些標(biāo)簽詞會同時和不同標(biāo)簽發(fā)生混淆。我們利用TF-IDF的思想來賦予每個標(biāo)簽詞一個對于特定類別的重要性。
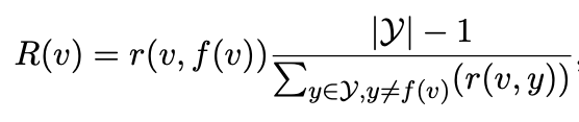
公式2: 相關(guān)性精調(diào),r(v,y)是一個標(biāo)簽詞v和標(biāo)簽y的相關(guān)性,類似于TF項。右邊一項則類似IDF項,我們要求這一項大也就是要求v和其非對應(yīng)類相關(guān)性小。
03
可學(xué)習(xí)精調(diào)
在少樣本實驗中,我們可以為每個標(biāo)簽詞賦予一個可學(xué)習(xí)的權(quán)重,因此每個標(biāo)簽詞的重要性就變成:
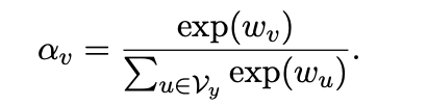
公式3:可學(xué)習(xí)的標(biāo)簽詞權(quán)重。
04
基于上下文的校準(zhǔn)
在零樣本實驗中不同標(biāo)簽詞的先驗概率可能差得很多,例如預(yù)測 basketball可能天然比fencing大,會使得很多小眾標(biāo)簽詞影響甚微。我們使用校準(zhǔn)的方式來平衡這種影響。
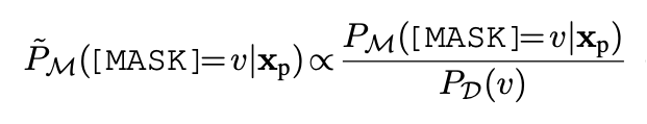
公式4: 基于上下文的校準(zhǔn),分母是公式1中的先驗概率。
使用上以上這些精調(diào)方法,我們知識庫擴(kuò)展的標(biāo)簽詞就能有效使用了。
實驗
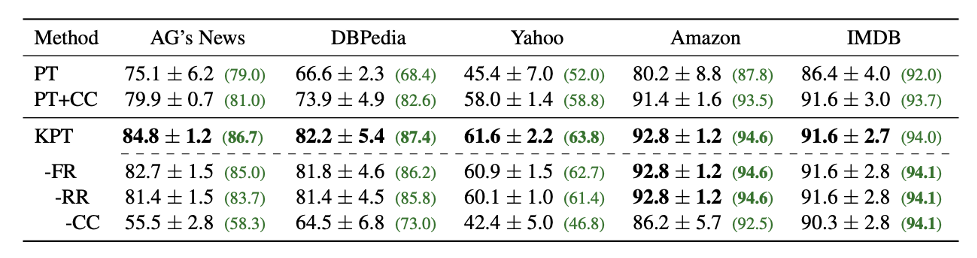
表2:零樣本文本分類任務(wù)。
如表2所示,零樣本上相比于普通的Prompt模板,性能有15個點的大幅長進(jìn)。相比于加上了標(biāo)簽詞精調(diào)的也最多能有8個點的提高。我們提出的頻率精調(diào),相關(guān)性精調(diào)等也各有用處。
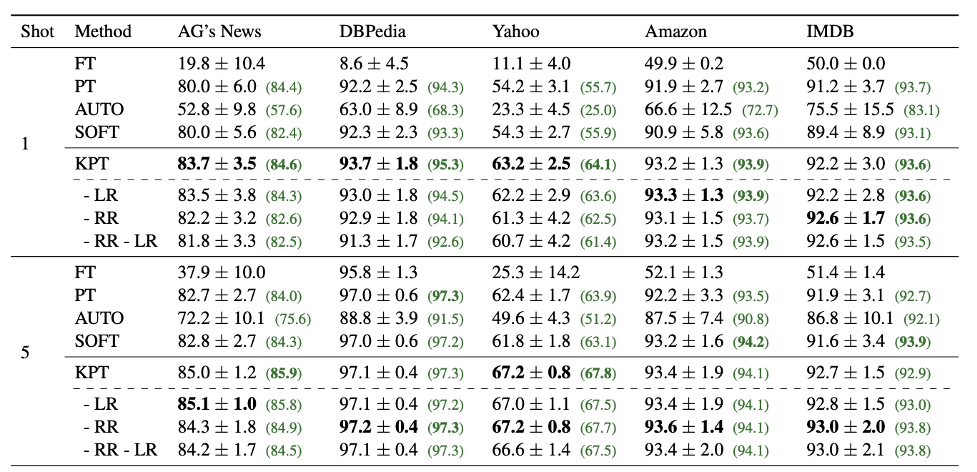
表3:少樣本文本分類任務(wù)。
如表3所示,在少樣本上我們提出的可學(xué)習(xí)精調(diào)搭配上相關(guān)性精調(diào)也有較大提升。AUTO和SOFT都是自動的標(biāo)簽詞優(yōu)化方法,其中SOFT以人工定義的標(biāo)簽詞做初始化,可以看到這兩種方法的效果都不如KPT。
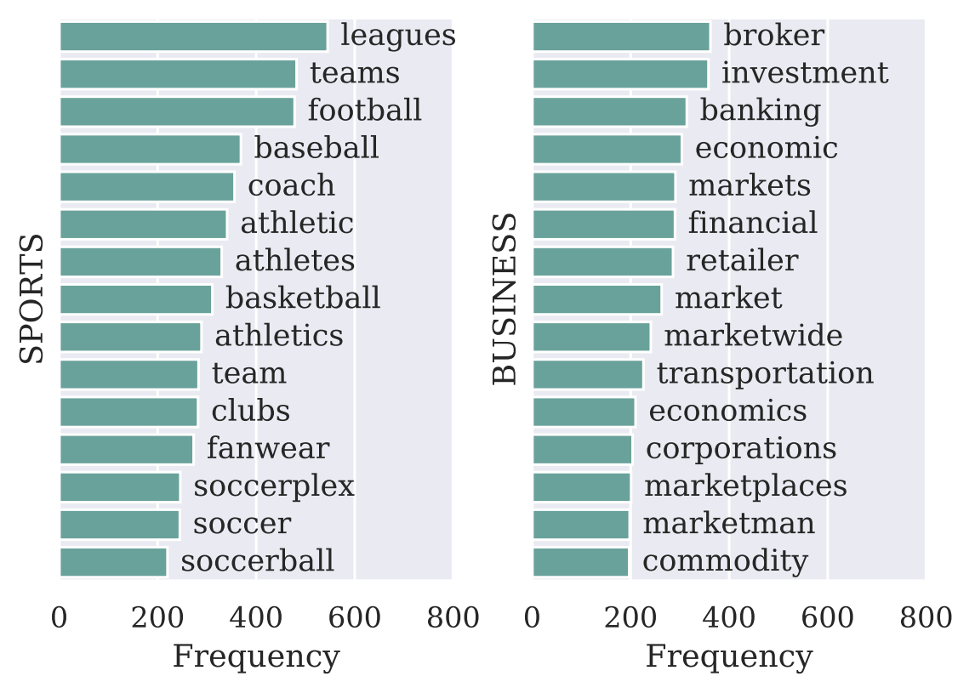
圖2: SPORTS和BUSINESS類的知識庫擴(kuò)展的標(biāo)簽詞對于預(yù)測的貢獻(xiàn)。
標(biāo)簽詞的可視化表明,每一條句子可能會依賴不同的標(biāo)簽詞進(jìn)行預(yù)測,完成了我們增加覆蓋面的預(yù)期。
總結(jié)
最近比較受關(guān)注的Prompt Learning方向,除了template的設(shè)計,verbalizer的設(shè)計也是彌補(bǔ)MLM和下游分類任務(wù)的重要環(huán)節(jié)。我們提出的基于知識庫的擴(kuò)展,直觀有效。同時也為如何在預(yù)訓(xùn)練模型的的利用中引入外部知識提供了一些參考。
審核編輯:郭婷
-
頻率
+關(guān)注
關(guān)注
4文章
1561瀏覽量
60352 -
知識庫
+關(guān)注
關(guān)注
0文章
12瀏覽量
6782
原文標(biāo)題:ACL2022 | KPT: 文本分類中融入知識的Prompt Verbalizer
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
《仿盒馬》app開發(fā)技術(shù)分享-- 分類模塊頂部導(dǎo)航列表彈窗(16)
如何在熱敏打印機(jī)中實現(xiàn)圖片的灰階打印效果嗎?
《AI Agent 應(yīng)用與項目實戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識庫
在Video Mode下,DLP6500穩(wěn)定的幀頻能達(dá)到多少呢?
如何使用自然語言處理分析文本數(shù)據(jù)
如何在文本字段中使用上標(biāo)、下標(biāo)及變量

AI對話魔法 Prompt Engineering 探索指南

RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實現(xiàn)Yolov5分類檢測
如何在TMS320C6727 DSP上創(chuàng)建基于延遲的音頻效果

【AWTK使用經(jīng)驗】如何在AWTK顯示阿拉伯文本






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論