 說話人識別和驗證系統解決方案
說話人識別和驗證系統解決方案

說話人識別和驗證系統的應用與日俱增。該技術的使用有助于控制和訪問自動駕駛汽車、計算機、手機和其他設備。還建立了各種機器學習模型來保護說話人識別和驗證系統。這是通過分析聲音的情緒反應和壓力水平來檢測對個人的威脅以及觸發他們安全的機制來實現的。
介紹
說話者和驗證系統根據一個人的聲音或講話的特性來識別說話者。人類每天都習慣于識別和響應說話者,但通過技術進行語音識別是復雜的,需要大量計算。由于數字信號處理和計算機系統的進步,自動說話人識別系統的使用在過去十年中變得普遍。
說話人識別系統的組成部分
說話人識別系統包括三個部分:
說話人識別:從一組登記的說話人中查明說話人的身份。目標是從已存儲的幾個模型中找到合適的揚聲器。(檢查多人)
說話人驗證:驗證未知聲音是否屬于某個說話人。當一個人將自己標識為 John Doe/Jane Doe 時,說話人驗證系統會將語音數據與錄制的模型進行比較,以確定說話人的身份是否與他/她聲稱的身份相符。(檢查聲稱的身份)
說話者分類:根據語音的特殊特征(基于從語音內容中提取的特征)將包含說話者語音的音頻流劃分為同質段/時間幀,以對說話者進行身份分類。
說話人驗證系統的應用
訪問控制:一個人必須說出一個特定的短語來表明自己的身份,才能訪問受限場所和特權信息。
交易認證:一個人必須說出一個特定的短語來識別他/她自己,以啟動電話銀行/信用卡授權或類似的交易。
揚聲器驗證系統基礎知識

圖 1:揚聲器驗證基礎
Front-End 部分捕獲說話者的聲音,并將語音信號轉換為一組代表說話者特征的特征向量。后端部分將特征向量與說話者的存儲模型(即通用背景模型,如下所述)進行比較,以確定它們匹配的精確程度以驗證說話者的身份。一旦說話者的聲音與數據庫中的聲音模型匹配,他們就可以訪問。
用于記錄和創建“揚聲器模型”的機制的變化增加了復雜性。由于可變的語音/語音保真度,說話人識別/驗證變得更加復雜。例如,在銀行使用高分辨率、高保真錄音機創建揚聲器模型時,語音保真度會有所不同,但基于語音的交易是使用具有嘈雜背景的手機完成的。
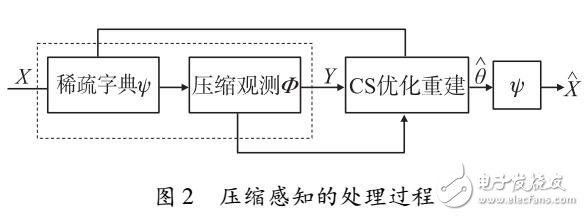
說話人識別/驗證流程圖
最初創建了一個大型模型數據庫,其中包含許多說話者和來自這些說話者的數小時語音數據。錄音包含來自不同來源的各種高保真和低保真語音輸入。分析從大量語音數據中提取的特征并訓練模型以創建通用的男性/女性模型。該模型數據庫被稱為“通用背景模型”(UBM)。
然后,創建想要識別/驗證自己的說話者模型數據庫。該模型數據庫被稱為“揚聲器模型”。該模型是從“通用背景模型”派生/創建的,該模型對通用男性/女性聲音進行分類。目標揚聲器型號與 UBM 略有不同。這些差異被記錄并保存在“揚聲器模型”數據庫中。
現在,當這個人說:“我是 John Doe”時,這個語音片段被記錄下來并分割成 10 毫秒的幀,并通過特征提取模型,產生語音的一些特征/特征。
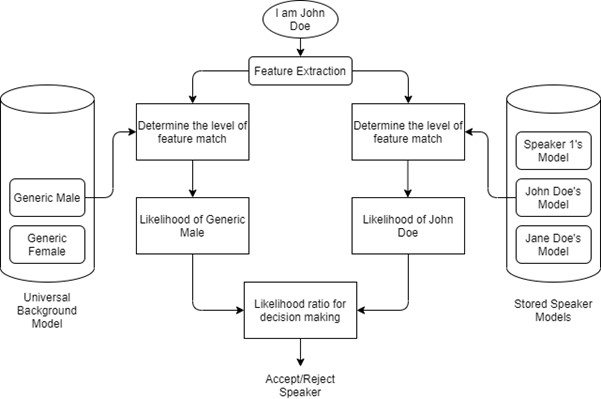
圖 2:說話人驗證流程圖
如果 John Doe 想要驗證他的名字,我們將從輸入語音“I am John Doe”中提取的特征輸入到他的說話人模型(特征提取)中,該模型確定特征匹配的水平并計算它是“John多伊'。
然后,對于相同的輸入聲音,“我是 John Doe”,我們將提取的特征輸入到通用背景模型中,以確定特征匹配的水平,并得出他是普通男性聲音的可能性。
決策的似然比由上述兩個似然比得出。接受/拒絕決定是基于根據呼叫者是“John Doe”的可能性和呼叫者是普通男性的可能性(基于通用背景模型)計算的某個閾值做出的。
eInfochips 為基于語音和音頻的中間件提供嵌入式系統和軟件開發、移植、優化、支持和維護解決方案,其中包括:DSP 域中的編碼器、解碼器、預處理和后處理算法。還提供語音/音頻相關工具和服務的維護和開發。eInfochips 還迎合了多核平臺上自定義算法的實現和并行化。
作者:瑞詩凱詩·阿加什
Rhishikesh Agashe 是 eInfochips 技術團隊的一員,他在 IT 行業擁有近 19 年的經驗。4 年的企業家生涯和 15 年的嵌入式領域經驗,其中他的大部分經驗是在嵌入式媒體處理領域,他參與了音頻和語音算法的實施。
審核編輯:湯梓紅
-
識別系統
+關注
關注
1文章
154瀏覽量
19131
發布評論請先 登錄
DSP嵌入式說話人識別系統設計方案
基于Cohort相似度的說話人識別
DSP嵌入式說話人識別系統的設計方案
基于MAP+CMLLR的說話人識別中發聲力度問題






 工商網監
工商網監
評論