") 中文文本糾錯(cuò)任務(wù)
中文文本糾錯(cuò)任務(wù)
最近在梳理中文文本糾錯(cuò)任務(wù),文本根據(jù)搜集到的文章整理成的任務(wù)簡介,在此先感謝大佬們分享的高質(zhì)量資料。
1
任務(wù)簡介
中文文本糾錯(cuò)是針對(duì)中文文本拼寫錯(cuò)誤進(jìn)行檢測與糾正的一項(xiàng)工作,中文的文本糾錯(cuò),應(yīng)用場景很多,諸如輸入法糾錯(cuò)、輸入預(yù)測、ASR 后糾錯(cuò)等等,例如:
-
寫作輔助:在內(nèi)容寫作平臺(tái)上內(nèi)嵌糾錯(cuò)模塊,可在作者寫作時(shí)自動(dòng)檢查并提示錯(cuò)別字情況。從而降低因疏忽導(dǎo)致的錯(cuò)誤表述,有效提升作者的文章寫作質(zhì)量,同時(shí)給用戶更好的閱讀體驗(yàn)。
-
公文糾錯(cuò):針對(duì)公文寫作場景,提供字詞、標(biāo)點(diǎn)、專名、數(shù)值內(nèi)容糾錯(cuò),包含領(lǐng)導(dǎo)人姓名、領(lǐng)導(dǎo)人職位、數(shù)值一致性等內(nèi)容的檢查與糾錯(cuò),輔助進(jìn)行公文審閱校對(duì)。
-
搜索糾錯(cuò):用戶在搜索時(shí)經(jīng)常輸入錯(cuò)誤,通過分析搜索query的形式和特征,可自動(dòng)糾正搜索query并提示用戶,進(jìn)而給出更符合用戶需求的搜索結(jié)果,有效屏蔽錯(cuò)別字對(duì)用戶真實(shí)需求的影響。
-
語音識(shí)別對(duì)話糾錯(cuò)將文本糾錯(cuò)嵌入對(duì)話系統(tǒng)中,可自動(dòng)修正語音識(shí)別轉(zhuǎn)文本過程中的錯(cuò)別字,向?qū)υ捓斫庀到y(tǒng)傳遞糾錯(cuò)后的正確query,能明顯提高語音識(shí)別準(zhǔn)確率,使產(chǎn)品整體體驗(yàn)更佳
圖片來源---百度大腦AI開放平臺(tái)-文本糾錯(cuò):https://ai.baidu.com/tech/nlp_apply/text_corrector
2
中文拼寫常見錯(cuò)誤類型
| 錯(cuò)誤類型 | 示例 |
|---|---|
| 同音字相似錯(cuò)誤 | 強(qiáng)烈推薦-墻裂推薦、配副眼睛-配副眼鏡 |
| 近音字相似錯(cuò)誤 | 牛郎織女-流浪織女 |
| 字形相似錯(cuò)誤 | 頑強(qiáng)拼搏-頑強(qiáng)拼博 |
| 詞序混亂 | 兩戶人家-兩家人戶 |
| 缺字少字 | 浩瀚星海-浩瀚星 |
| 中文全拼拼寫 | 天下-tianxia |
| 中文首字母縮寫 | 北京-bj |
| 中文簡拼 | 明星大偵探-明偵 |
| 語法錯(cuò)誤 | 無法言說-言說無法 |
我們把中文常見錯(cuò)誤總結(jié)分為三類:1、用詞錯(cuò)誤,由于輸入法等原因?qū)е碌倪x詞錯(cuò)誤,其主要表現(xiàn)為音近,形近等;2、文法/句法錯(cuò)誤,該類錯(cuò)誤主要是由于對(duì)語言不熟悉導(dǎo)致的如多字、少字、亂序等錯(cuò)誤,其錯(cuò)誤片段相對(duì)較大;3、知識(shí)類錯(cuò)誤,該類錯(cuò)誤可能由于對(duì)某些知識(shí)不熟悉導(dǎo)致的錯(cuò)誤,要解決該類問題,通常得引入外部知識(shí)、常識(shí)等。
當(dāng)然,針對(duì)確定場景,這些問題并不一定全部存在,比如輸入法中需要處理1234,搜索引擎需要處理1234567,ASR 后文本糾錯(cuò)只需要處理12,其中5主要針對(duì)五筆或者筆畫手寫輸入等。
3
主流技術(shù)
中文本糾錯(cuò)的 paper 很多,整體來看,可以統(tǒng)一在一個(gè)框架下,即三大步: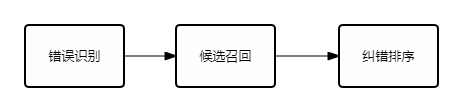
- 錯(cuò)誤識(shí)別
該階段主要目的在于,判斷文本是否存在錯(cuò)誤需要糾正,如果存在則傳遞到后面兩層。這一階段可以提高整體流程的效率。
錯(cuò)誤識(shí)別/檢測的目標(biāo)是識(shí)別輸入句子可能存在的問題,采用序列表示(Transformer/LSTM)+CRF的序列預(yù)測模型,這個(gè)模型的創(chuàng)新點(diǎn)主要包括:1、詞法/句法分析等語言先驗(yàn)知識(shí)的充分應(yīng)用;2、特征設(shè)計(jì)方面,除了DNN相關(guān)這種泛化能力比較強(qiáng)的特征,還結(jié)合了大量hard統(tǒng)計(jì)特征,既充分利用DNN模型的泛化能力,又對(duì)低頻與OOV(Out of Vocabulary)有一定的區(qū)分;3、最后,根據(jù)字粒度和詞粒度各自的特點(diǎn),在模型中對(duì)其進(jìn)行融合,解決詞對(duì)齊的問題
- 候選召回
候選召回指的是,識(shí)別出具體的錯(cuò)誤點(diǎn)之后,需要進(jìn)行錯(cuò)誤糾正,為了達(dá)到更好的效果以及性能,需要結(jié)合歷史錯(cuò)誤行為,以及音形等特征召回糾錯(cuò)候選。主要可分為兩部分工作:離線的候選挖掘,在線的候選預(yù)排序。離線候選挖掘利用大規(guī)模多來源的錯(cuò)誤對(duì)齊語料,通過對(duì)其模型,得到不同粒度的錯(cuò)誤混淆矩陣。在線候選預(yù)排序主要是針對(duì)當(dāng)前的錯(cuò)誤點(diǎn),對(duì)離線召回的大量糾錯(cuò)候選,結(jié)合語言模型以及錯(cuò)誤混淆矩陣的特征,控制進(jìn)入糾錯(cuò)排序階段的候選集數(shù)量與質(zhì)量。
該階段主要目的在于,利用一種或多種策略(規(guī)則或模型),生成針對(duì)原句的糾正候選。這一階段是整體流程召回率的保證,同時(shí)也是一個(gè)模型的上限。
- 糾錯(cuò)排序
該階段主要目的在于,在上一階段基礎(chǔ)上,利用某種評(píng)分函數(shù)或分類器,結(jié)合局部乃至全局的特征,針對(duì)糾正候選進(jìn)行排序,最終排序最高(如沒有錯(cuò)誤識(shí)別階段,則仍需比原句評(píng)分更高或評(píng)分比值高過閾值,否則認(rèn)為不需糾錯(cuò))的糾正候選作為最終糾錯(cuò)結(jié)果。
4
中文文本糾錯(cuò)評(píng)測
數(shù)據(jù)集
SIGHANBake-off2013:[http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html](http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html)
SIGHANBake-off2014:[http://ir.itc.ntnu.edu.tw/lre/clp14csc.html](http://ir.itc.ntnu.edu.tw/lre/clp14csc.html)
SIGHANBake-off2015:[http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html](http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html)
中文輸入糾錯(cuò)的評(píng)測數(shù)據(jù)主要包括SIGHAN Bake-off 2013/2014/2015這三個(gè)數(shù)據(jù)集,均是針對(duì)繁體字進(jìn)行的糾錯(cuò)。其中,只有SIGHAN Bake-off 2013是針對(duì)母語使用者的,而另外兩個(gè)是針對(duì)非母語使用者。
評(píng)價(jià)指標(biāo)
這里主要羅列一下常用的評(píng)測指標(biāo)。在錯(cuò)誤識(shí)別子任務(wù)中,常用的評(píng)測指標(biāo)有:
-
FAR(錯(cuò)誤識(shí)別率):沒有筆誤卻被識(shí)別為有筆誤的句子數(shù)/沒有筆誤的句子總數(shù)
-
DA(識(shí)別精準(zhǔn)率):正確識(shí)別是否有筆誤的句子數(shù)(不管有沒有筆誤)/句子總數(shù)
-
DP(識(shí)別準(zhǔn)確率):識(shí)別有筆誤的句子中正確的個(gè)數(shù)/識(shí)別有筆誤的句子總數(shù)
-
DR(識(shí)別找回率):識(shí)別有筆誤的句子中正確的個(gè)數(shù)/有筆誤的句子總數(shù)
-
DF1(識(shí)別F1值):2 * DP * DR/ (DP + DR)
-
ELA(錯(cuò)誤位置精準(zhǔn)率):位置識(shí)別正確的句子(不管有沒有筆誤)/句子總數(shù)
-
ELP(錯(cuò)誤位置準(zhǔn)確率):正確識(shí)別出筆誤所在位置的句子/識(shí)別有筆誤的句子總數(shù)
-
ELR(錯(cuò)誤位置召回率):正確識(shí)別出筆誤所在位置的句子/有筆誤的句子總數(shù)
-
ELF1(錯(cuò)誤位置準(zhǔn)確率):2ELPELR / (ELP+ELR)在錯(cuò)誤糾正任務(wù)中,常用的評(píng)測指標(biāo)為:
-
LA位置精確率:識(shí)別出筆誤位置的句子/總的句子
-
CA修改精確率:修改正確的句子/句子總數(shù)
-
CP修改準(zhǔn)確率:修改正確的句子/修改過的句子
雖然文本糾錯(cuò)具體會(huì)分為錯(cuò)誤識(shí)別和錯(cuò)誤修正兩部分,并分別構(gòu)造評(píng)價(jià)指標(biāo)。但考慮到端到端任務(wù),我們評(píng)價(jià)完整的糾錯(cuò)過程:
- 應(yīng)該糾錯(cuò)的,即有錯(cuò)文本記為 P,不該糾錯(cuò)的,即無錯(cuò)文本記為 N
- 對(duì)于該糾錯(cuò)的,糾錯(cuò)對(duì)了,記為 TP,糾錯(cuò)了或未糾,記為 FP
- 對(duì)于不該糾錯(cuò)的,未糾錯(cuò),記為 TN,糾錯(cuò)了,記為 FN。通常場景下,差準(zhǔn)比查全更重要,F(xiàn)N 更難接受,本來對(duì)了改成錯(cuò)的這個(gè)更離譜,可構(gòu)造下述評(píng)價(jià)指標(biāo):,其中
5
相關(guān)方法
相關(guān)論文
整理來自:https://blog.csdn.net/qq_36426650/article/details/122807019
- 【1】DCSpell:A Detector-Corrector Framework for Chinese Spelling Error Correction(SIGIR2021)
- 【2】Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction- (ACL2021)
- 【3】Correcting Chinese Spelling Errors with Phonetic Pre-training(ACL2021)
- 【4】PLOME:Pre-trained with Misspelled Knowledge for Chinese Spelling Correction(ACL2021)
- 【5】PHMOSpell:Phonological and Morphological Knowledge Guided Chinese Spelling Check(ACL2021)
- 【6】Exploration and Exploitation: Two Ways to Improve Chinese Spelling Correction Models(ACL2021)
- 【7】Dynamic Connected Networks for Chinese Spelling Check(2021ACL)
- 【8】Global Attention Decoder for Chinese Spelling Error Correction(ACL2021)
- 【9】Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking(ACL2021)
- 【10】SpellBERT: A Lightweight Pretrained Model for Chinese Spelling Check(EMNLP2021)
- 【11】A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check(EMNLP2018)
- 【12】Adversarial Semantic Decoupling for Recognizing Open-Vocabulary Slots(EMNLP2020)
- 【13】Chunk-based Chinese Spelling Check with Global Optimization(EMNLP2020)
- 【14】Confusionset-guided Pointer Networks for Chinese Spelling Check(ACL2019)
- 【15】Context-Sensitive Malicious Spelling Error Correction(WWW2019)
- 【16】FASPell:A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm (2019ACL)
- 【17】SpellGCN:Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check (2020ACL)
- 【18】Spelling Error Correction with Soft-Masked BERT(ACL2020)
在OpenReview上提交至ARR2022的相關(guān)稿件有:
- 【1】Exploring and Adapting Chinese GPT to Pinyin Input Method 【PDF】
- 【2】The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking 【PDF】【Code】【Data】
- 【3】Sparsity Regularization for Chinese Spelling Check【PDF】
- 【4】Pre-Training with Syntactic Structure Prediction for Chinese Semantic Error Recognition【PDF】
- 【5】ECSpellUD: Zero-shot Domain Adaptive Chinese Spelling Check with User Dictionary【PDF】
- 【6】SpelLM: Augmenting Chinese Spell Check Using Input Salience【PDF】【Code】【Data】
- 【7】Pinyin-bert: A new solution to Chinese pinyin to character conversion task【PDF】
簡單總結(jié)一下目前CSC的方法:
-
基于BERT:以為CSC時(shí)是基于token(字符)級(jí)別的預(yù)測任務(wù),輸入輸出序列長度一致,因此非常類似預(yù)訓(xùn)練語言模型的Masked Language Modeling(MLM),因此現(xiàn)如今絕大多數(shù)的方法是基于MLM實(shí)現(xiàn)的。而在BERT問世前,CSC則以RNN+Decoder、CRF為主;
-
多模態(tài)融合:上文提到CSC涉及到字音字形,因此有一些方法則是考慮如何將Word Embedding、Glyphic Embedding和Phonetic Embedding進(jìn)行結(jié)合,因此涌現(xiàn)出一些多模態(tài)方法;
6
最新技術(shù)
- FASPell(愛奇藝)
技術(shù)方案 FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
code: https://github.com/iqiyi/FASPell
- SpellGCN (阿里)
技術(shù)方案 SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check
code: https://github.com/ACL2020SpellGCN/SpellGCN
- Soft-Mask BERT (字節(jié))
技術(shù)方案:Spelling Error Correction with Soft-Masked BERT
code: https://github.com/hiyoung123/SoftMaskedBert
- Spelling Correction as a Foreign Language (ebay)
技術(shù)方案 Spelling Correction as a Foreign Language
7
中文糾錯(cuò)的開源項(xiàng)目
pycorrector
https://github.com/shibing624/pycorrector
中文文本糾錯(cuò)工具。支持中文音似、形似、語法錯(cuò)誤糾正,python3開發(fā)。pycorrector實(shí)現(xiàn)了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多種模型的文本糾錯(cuò),并在SigHAN數(shù)據(jù)集評(píng)估各模型的效果。
correction
https://github.com/ccheng16/correction
大致思路:
- 使用語言模型計(jì)算句子或序列的合理性
- bigram, trigram, 4-gram 結(jié)合,并對(duì)每個(gè)字的分?jǐn)?shù)求平均以平滑每個(gè)字的得分
- 根據(jù)Median Absolute Deviation算出outlier分?jǐn)?shù),并結(jié)合jieba分詞結(jié)果確定需要修改的范圍
- 根據(jù)形近字、音近字構(gòu)成的混淆集合列出候選字,并對(duì)需要修改的范圍逐字改正
- 句子中的錯(cuò)誤會(huì)使分詞結(jié)果更加細(xì)碎,結(jié)合替換字之后的分詞結(jié)果確定需要改正的字
- 探測句末語氣詞,如有錯(cuò)誤直接改正
Cn_Speck_Checker
https://github.com/PengheLiu/Cn_Speck_Checker
- 使用了貝葉斯定理
- 初始化所有潛在中文詞的先驗(yàn)概率,將文本集(50篇醫(yī)學(xué)文章)分詞后,統(tǒng)計(jì)各個(gè)中文詞的出現(xiàn)頻率即為其先驗(yàn)概率
- 當(dāng)給定一待糾錯(cuò)單詞時(shí),需要找出可能的正確單詞列表,這里根據(jù)字符距離來找出可能的正確單詞列表
- 對(duì)構(gòu)造出來的單詞做了一次驗(yàn)證后再將其加入候選集合中,即判斷了下該詞是否為有效單詞,根據(jù)其是否在單詞模型中
- 程序原理:
chinese_correct_wsd
https://github.com/taozhijiang/chinese_correct_wsd
- 用于用戶輸入語句的同音自動(dòng)糾錯(cuò)
- 使用到了同義詞詞林
- 方法:
Autochecker4Chinese
https://github.com/beyondacm/Autochecker4Chinese
- 構(gòu)造一個(gè)詞典來檢測中文短語的拼寫錯(cuò)誤,key是中文短語,值是在語料庫中的頻率
- 對(duì)于該字典中未出現(xiàn)的任何短語,檢測器會(huì)將其檢測為拼寫錯(cuò)誤的短語
- 使用編輯距離為錯(cuò)誤拼寫的短語制作正確的候選列表
- 對(duì)于給定的句子,使用jieba做分割
- 在分段完成后獲取分段列表,檢查其中是否存在保留短語,如果不存在,那么它是拼寫錯(cuò)誤的短語
- 方法:
8
參考資料
- 中文糾錯(cuò)(Chinese Spelling Correct)最新技術(shù)方案總結(jié)
- 中文文本糾錯(cuò)算法--錯(cuò)別字糾正的二三事
- 中文文本糾錯(cuò)算法走到多遠(yuǎn)了?
- 中文輸入糾錯(cuò)任務(wù)整理
- nlp 中文文本糾錯(cuò)_百度中文糾錯(cuò)技術(shù)
- 中文拼寫檢測(Chinese Spelling Checking)相關(guān)方法、評(píng)測任務(wù)、榜單
- 中文(語音結(jié)果)的文本糾錯(cuò)綜述 Chinese Spelling Check
- https://github.com/shibing624/pycorrector
審核編輯 :李倩
-
語音識(shí)別
+關(guān)注
關(guān)注
39文章
1774瀏覽量
113965 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4372瀏覽量
64292 -
文本
+關(guān)注
關(guān)注
0文章
119瀏覽量
17378
原文標(biāo)題:中文文本糾錯(cuò)任務(wù)簡介
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
把樹莓派打造成識(shí)別文本的“神器”!

阿里云通義開源長文本新模型Qwen2.5-1M
如何優(yōu)化自然語言處理模型的性能
如何使用自然語言處理分析文本數(shù)據(jù)
Linux計(jì)劃任務(wù)介紹
圖紙模板中的文本變量
如何在文本字段中使用上標(biāo)、下標(biāo)及變量

如何使用 Llama 3 進(jìn)行文本生成
TMS320硬件應(yīng)用程序(包含掃描的文本)

TMS320C64x+和TMS320C674x的檢錯(cuò)糾錯(cuò)機(jī)制
【AWTK使用經(jīng)驗(yàn)】如何在AWTK顯示阿拉伯文本

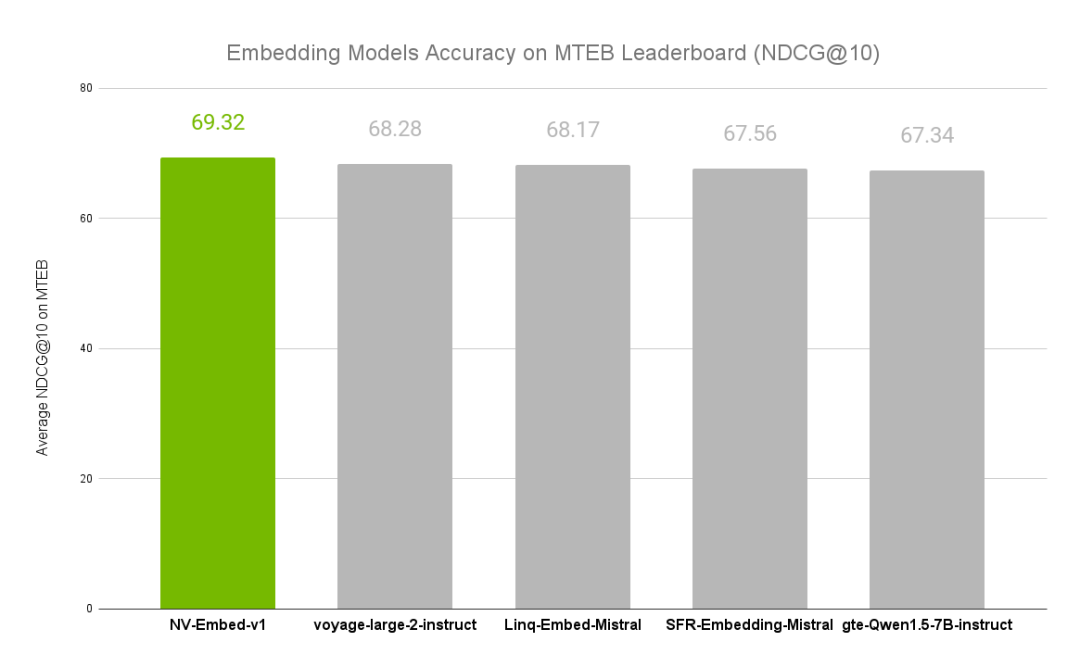
NVIDIA文本嵌入模型NV-Embed的精度基準(zhǔn)
如何學(xué)習(xí)智能家居?8:Text文本實(shí)體使用方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論