 為NVIDIA MLPerf Training v2.0性能提供動力的全堆棧優化
為NVIDIA MLPerf Training v2.0性能提供動力的全堆棧優化
MLPerf benchmarks 由工業界、學術界和研究實驗室的人工智能領導者組成的聯盟開發,旨在提供標準、公平和有用的深度學習性能測量。 MLPerf 訓練側重于測量時間,以便為以下任務訓練一系列常用的神經網絡:
自然語言處理
推薦系統
生物醫學圖像分割
目標檢測
圖像分類
強化學習
減少培訓時間對于加快部署時間、最小化總體擁有成本和最大化投資回報至關重要。
然而,與平臺性能一樣重要的是它的多功能性。訓練每個模型的能力,以及提供基礎設施可替代性以運行從訓練到推理的所有人工智能工作負載的能力,對于使組織能夠最大限度地實現其基礎設施投資的回報至關重要。
NVIDIA platform 具有全堆棧創新和豐富的開發人員和應用程序生態系統,仍然是唯一提交所有八個 MLPerf 訓練測試結果,以及提交所有 MLPerf 推理和 MLPerf 高性能計算( HPC )測試結果的系統。
在本文中,您將了解 NVIDIA 在整個堆棧中部署的方法,以在 MLPerf v2.0 中提供更高的性能。
全堆棧改進
NVIDIA MLPerf v2.0 提交基于經驗證的 A100 Tensor Core GPU 、 NVIDIA DGX A100 系統 以及 NVIDIA DGX SuperPOD 參考架構。許多合作伙伴還使用 A100 Tensor Core GPU 提交了結果。
通過整個堆棧(包括系統軟件、庫和算法)的持續創新,與之前使用相同 A100 Tensor Core GPU 提交的文件相比, NVIDIA 再次實現了性能改進。
與 NVIDIA MLPerf v0.7 提交的第一批 A100 Tensor Core GPU 提交相比,結果表明,每個芯片的增益高達 2.1 倍,最大規模訓練的增益為 5.7 倍(表 1 )。
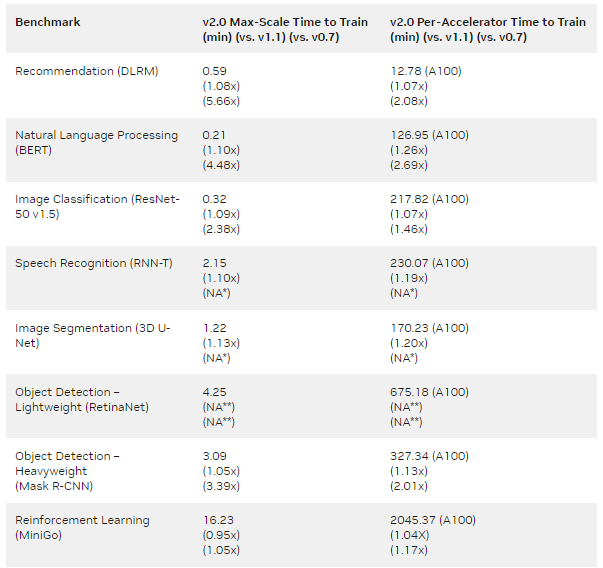
MLPERF v1.1 Submission details :
每加速器: BERT : 1.1-2066 | DLRM:1.1-2064 |掩碼 R-CNN:1.1-2066 | Resnet50 v1.5:1.1-2065 | RNN-T:1.1-2066 | 3D U-Net:1.1-2065 | MiniGo:1.1-2067
最大比例: BERT : 1.1-2083 | DLRM:1.1-2073 | Mask R-CNN:1.1-2076 | Resnet50 v1.5:1.1-2082 | SSD:1.1-2070 | RNN-T:1.1-2080 | 3D U-Net:1.1-2077 | MiniGo:1.1-2081 (*)
MLPERF v2.0 Submission details :
每加速器: BERT : 2.0-2070 | DLRM:2.0-2068 | Mask R-CNN:2.0-2070 | Resnet50 v1.5:2.0-2069 | RetinaNet:2.0-2091 | RNN-T:2.0-2066 | 3D U-Net:2.0-2060 | MiniGo:2.0-2059
最大比例: BERT : 2.0-2106 | DLRM:2.0-2098 | Mask R-CNN:2.0-2099 | Resnet50 v1.5:2.0-2107 | RetinaNet:2.0-2103 | RNN-T:2.0-2104 | 3D U-Net:2.0-2100 | MiniGo:2.0-2105
使用 8xA100 服務器訓練時間并將其乘以 8 計算出 A100 的每加速器性能。 3D U-Net 和 RNN-T 不是 MLPerf v0.7 的一部分。(**)RetinaNet 不是 MLPerf v0.7 或 v1.1 的一部分。 MLPerf 名稱和徽標是商標。
以下各節重點介紹了為實現這些改進所做的一些工作。
BERT
最新的 NVIDIA BERT 提交利用了以下優化:
順序包裝
全連接層和 GELU 層的融合
順序包裝
在前幾輪中,填充批次所需的填充相關開銷已經通過引入未添加優化進行了優化。然而,取消添加會導致緩沖區大小動態變化,因為令牌總數不再固定。
當我們不必使用 CUDA 圖時,例如當使用大批量時,這不是一個問題。然而,對于小批量,其中 CUDA 圖用于減少 CPU 開銷,動態大小的緩沖區需要針對每個可能的大小使用許多單獨的圖。為了有效利用 CUDA 圖,同時最小化填充開銷, NVIDIA 在這一輪中使用了序列打包的概念。
在來自 Transformers ( BERT )的 MLPerf 雙向編碼器表示中,訓練樣本被限制為 512 個令牌,但其令牌通常少于 512 個。由于訓練序列具有不同的長度,因此可以在 512 個令牌樣本中擬合多個序列。
序列壓縮要求預先知道訓練集序列的長度分布。序列可以合并到壓縮樣本中,這樣合并的樣本中沒有一個超過 512 個令牌的長度。
NVIDIA 使用了與另一個提交者 用于 MLPerf v1.1 類似的打包算法。 GPU 具有高度的通用編程能力,因此可以采用來自不同提交方的算法。
為了在實現復雜性和性能之間取得良好的平衡,每個樣本中最多包含三個序列。這導致每個訓練樣本包含不同數量的序列,因為一批三個樣本可以包含三到九個序列。
CUDA 圖要求每個圖的緩沖區大小隨時間固定。通過為批次中每個可能的序列數創建一個單獨的圖來處理不同數量的總序列。
對于大規模訓練,我們使用每個芯片兩個批次的大小。這轉化為五到七個單獨的圖,這遠低于開始提到的未添加優化所需的數量。
總的來說,對于 4096- GPU 和 1024- GPU 場景,該技術分別將大規模運行的結果提高了 10% 和 33% 。
全連接層和 GELU 層的融合
BERT 使用高斯誤差線性單元( GELU )激活函數,該函數遵循完全連接層。在之前提交的文件中, GELU 激活函數是作為單個內核實現的。這種方法需要額外的內存事務來進行輸入讀取和輸出寫入。
在這一輪中, NVIDIA 實現了完全連接層(矩陣乘法操作)與 GELU 激活函數的融合。這消除了對大量內存讀寫操作的需要,使總吞吐量增加了 2-4% ——每芯片批量越大,收益越大。
通常,將激活數學融合到矩陣乘法運算的末尾更有效,這意味著將 GELU 激活函數融合到不同的完全連接層中(圖 1 )。
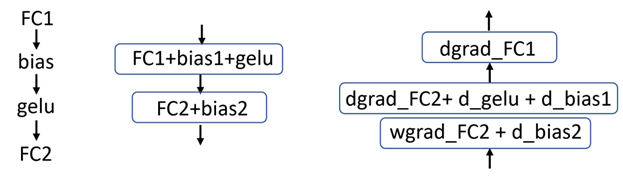
圖 1 左:在 BERT 中的操作模式,中:前向傳遞中的融合圖,右:后向傳遞中的融合圖。每個框代表一個內核。
深度學習推薦模型
最新的 NVIDIA 深度學習推薦模型( DLRM )提交再次利用了 NVIDIA Merlin HugeCTR ,一個用于推薦系統的優化開源深度神經網絡訓練框架。
內核融合
多層感知器( MLP )是 DLRM 的關鍵構建塊。為了減少全局內存的訪問次數,元素核和通用矩陣乘法( GEMM )核的融合得到了廣泛應用。
這個 NVIDIA cuBLAS 庫 最近引入了一種新的融合類型: GEMM 和 DReLU (將 ReLU 梯度計算與反向過程中的矩陣乘法運算融合)。 HugeCTR 利用這種新的融合類型來提高 MLP 的性能。
改進了計算和通信的重疊
提高 GPU 利用率對于提供最高性能非常重要。
在最新提交的文件中, NVIDIA 顯著改善了混合嵌入評估中計算和通信的重疊,以提高 GPU 利用率。具體來說,迭代 i 中密集網絡的執行通過流水線與迭代 i + 1 中嵌入的執行重疊,增加了 GPU 的利用率。
這種重疊是可能的,因為在評估階段沒有迭代之間的依賴關系。
此外,還優化了混合嵌入的前向/后向分層all-to-all操作中的幾個關鍵內核。
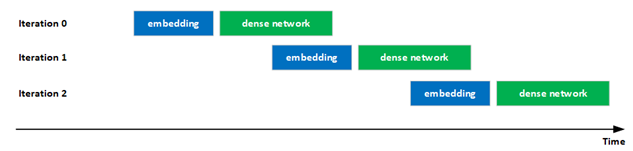
圖 2 :嵌入和密集網絡的重疊執行
ResNet-50
對于 ResNet-50 ,我們采用了以下優化來提高性能:
更好的最大規模訓練配置
更快的 cuDNN 內核
更好的最大規模訓練配置
當對模型進行大規模訓練時,如果全局批量大小不是數據集中訓練圖像的整數倍,則會在歷元的最后一次迭代中添加額外數據,以使批量大小在迭代中保持一致。如果全局批大小接近數據集的整數倍,則可以避免浪費的計算。這對于大規模訓練尤其重要,因為全局批量相對較大。
在這一輪 MLPerf 中,我們得出結論,使用 527 個節點,全局批量大小為 67456 ,顯著減少了浪費的計算,與 MLPerf v1.1 中 NVIDIA 提交的 ResNet-50 相比,性能提升了 3.5% 。
更快的 cuDNN 內核
對于提交的 ResNet50 , NVIDIA 顯著改進了 cuDNN 提取的內核。這包括針對層大小選擇更好的內核,以及針對不同分片大小優化內核實現。
從這些優化的內核采樣中,我們觀察到 MLPerf v1.1 的大規模配置的吞吐量提高了 4% 以上。
RetinaNet
NVIDIA RetinaNet 提交利用了幾種軟件優化,包括:
通道最后存儲格式和自動混合精度
使用融合加速
優化損耗塊
異步評分
CUDA 圖
通道最后存儲格式和自動混合精度
為了避免內存重組并有效提高峰值性能, NVIDIA 使用了 PyTorch 通道最后內存格式 ( NHWC 而非 NCHW )和 PyTorch 自動混合精度 (AMP)。
使用融合加速
對于 RetinaNet 提交, NVIDIA took 利用了幾個融合機會。通過 Apex 庫的 cuDNN 運行時融合用于融合 CONV-bias-ReLU 和 CONV-bias-pattern ,而 PyTorch NVFuser 用于融合元素操作,例如 scale-bias-ReLU 和 scale-bias-add-ReLU 。
cuDNN 運行時融合 Python 接口可以在 Apex repository (從apex.contrib.conv_bias_relu導入 ConvBiasReLU 或 ConvBias )中找到。
優化損耗塊
RetinaNet 損耗相關計算分為兩個階段:地面實況數據預處理和實際損耗計算。
由于地面實況數據預處理不依賴于模型輸出,部分地面實況數據處理通過 custom functions 卸載到 DALI ,使其能夠異步執行,提高了系統資源利用率。預處理的其余部分被重新實現,然后合并到模型圖中以避免抖動。
對于損耗計算,使用了優化的焦損實現,可在 Apex library 中找到。
異步評分
RetinaNet 提交指南要求在每個訓練期后進行評估(推斷和評分)。由于 OpenImages 驗證數據集中有大量圖像和邊界框,以及評分代碼的順序實現,評分時間開銷很大。
為了減輕評分開銷,特別是在大規模執行中,實現了異步評分,以便下一個訓練歷元掩蓋了前一個歷元評分過程。

圖 3 在評估中執行異步 COCO 評分
CUDA 圖
CUDA 圖 在 NVIDIA RetinaNet 提交中廣泛使用。繪制了整個模型和地面實況預處理的部分,這需要重新實現它們以適應 CUDA 圖約束。
該模型的正向和反向過程被圖形捕捉,以及地面實況預處理的部分。后者需要代碼自適應以適應 CUDA 圖約束。
有關更多信息,請參閱 用 CUDA 圖加速 PyTorch 。
掩碼 R-CNN
NVIDIA Mask R-CNN 提交使用了幾種技術來提高性能:
瓶頸塊優化
RPN 頭部融合
評價
Top-K
瓶頸塊優化
resnet主干構建為瓶頸塊堆棧,每個瓶頸塊由三個連續卷積組成。每個卷積后面跟著一個批范數和一個 ReLu 。批范數模塊有四個參數,在正向方法中計算兩個中間項需要一些數學知識。
由于批量規范被凍結,參數永遠不會更改,這意味著中間項也不會更改。為了節省時間,這些中間項只計算了一次。
ReLu 的反向傳播涉及創建和應用掩碼。在早期版本的代碼中,該掩碼以半( FP16 )精度存儲。在這一輪中, DReLU 掩碼表示為布爾值,而不是 FP16 ,以減少內存事務。
在反向傳播過程中,為三個卷積層中的每一層計算數據梯度和權重梯度。 NVIDIA 根據經驗發現,雖然數據梯度 GPU 內核使用足夠數量的 CTA 來啟動,以充分利用 GPU ,但權重梯度內核使用的 CTA 要少得多。
實現的一個優化是首先啟動數據梯度核,然后在單獨的流上啟動所有三個權重梯度核,以便它們同時運行。這減少了權重梯度的總計算時間。
Apex 中的 瓶頸塊模塊 中的 PyTorch 用戶可以使用這些優化。
RPN 頭部融合
如 RetinaNet 一節所述,實現了一個新的 Apex 模塊,該模塊融合了卷積、偏置和 ReLu 。該模塊位于 MaskR CNN 中,用于融合 RPN 頭塊中某些層的正向傳播。
評價
平均而言,評估所需的時間幾乎與培訓所需的時間相同。評估在專用節點上異步完成,但結果通過阻塞廣播與訓練節點共享。
訓練節點在開始等待評估廣播之前等待一定數量的步驟,以最小化任何評估結果等待時間。學習率曲線有兩個拐點,模型在通過最后一個拐點之前收斂的可能性極小。這就是為什么你應該等待盡可能長的時間來檢查評估結果,直到訓練通過最后一個學習率曲線拐點。
Top-K
在 PyTorch 的早期版本中, top-k 內核啟動的 CTA 數量與每 GPU 批大小成比例。當批量大小等于 1 時,這產生了較差的性能,該批量大小通常用于 NVIDIA max scale 運行。
在前幾輪中,我們使用兩階段 top-k 方法解決了這個問題,該方法是用 Python 實現的,但該解決方案并沒有得到很好的推廣。關于更普遍解決方案的工作已經在進行中。
在這一輪中, NVIDIA 與 PyTorch 團隊合作,以確保新的 top-k 實現在批量為 1 的情況下產生更好的性能,并進入 PyTorch 。完成后,以前的兩階段 top-k 實現被新的 PyTorch 模塊所取代。
3D U-Net
3D U-Net 具有多個大層,輸入通道數為 32 。對于wgrad內核,使用默認為 64x256x64 的內核意味著顯著的塊大小量化損失。
由于在 cuDNN 中引入了新的 32x256x32 wgrad內核,從而節省了分片大小量化損失。這導致 MLPerf v2.0 中單個節點的加速比 MLPerf v1.1 高出 5% 以上。
RNN-T
遞歸神經網絡傳感器( RNN-T )的預處理步驟相對密集。多虧了 DALI ,大部分預處理開銷可以通過管道傳輸并隱藏在主訓練循環下。
然而,由于輸入數據的大小可能不同,因此需要在初始迭代后重新定位內部內存緩沖區,從而增加預熱階段的長度。
DALI 最近已切換到基于內存池的分配器,其中池使用cuMem API 進行管理。這顯著減少了分配新緩沖區的開銷,在訓練中產生了更快的預熱過程。
結論
多虧了整個堆棧的優化, NVIDIA 平臺再次能夠使用經驗證的 NVIDIA A100 Tensor Core GPU 和 NVIDIA DGX A100 平臺提高 MLPerf Training v2.0 的性能。
NVIDIA 仍然是在 MLPerf 基準測試套件中提交結果的唯一平臺,包括 MLPerf 培訓、 MLPerf 推理和 MLPerf HPC 。這展示了整個平臺的性能和多功能性,隨著現代人工智能在每個計算領域的普及,這一點至關重要。
除了在 MLPerf 存儲庫中提供用于 NVIDIA MLPerf 提交的軟件外,還為 NVIDIA GPU 、 在 NGC hub 上可用 制作并優化了數十個其他模型。
NVIDIA 平臺也無處不在,為客戶提供了運行模型的選擇。 NVIDIA A100 可從所有主要服務器制造商和云服務提供商處獲得,允許您在本地、云中、混合環境或邊緣部署。
關于作者
Ashraf Eassa 是NVIDIA 加速計算集團內部的高級產品營銷經理。
Sukru Burc Eryilmaz 是 NVIDIA 計算機體系結構的高級架構師,他致力于在單節點和超級計算機規模上改進神經網絡訓練的端到端性能。他從斯坦福大學獲得博士學位,并從比爾肯特大學獲得學士學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5258瀏覽量
105849 -
gpu
+關注
關注
28文章
4915瀏覽量
130719 -
人工智能
+關注
關注
1804文章
48783瀏覽量
246858
發布評論請先 登錄
hyper-v 配置,Hyper-V配置:性能優化與高級設置
WTS-100(V2.0 GNSS) 無線定位系統(GNSS) 彩頁
新品| GPS V2.0,高性能GNSS全球定位模塊

解鎖NVIDIA TensorRT-LLM的卓越性能
ANSVG-G-A混合動態濾波補償裝置使用說明書 V2.0
NVIDIA AI助力初創企業為心理治療師提供AI工具
從TMS320TCI648x DSP的EDMA v2.0遷移到EDMA v3.0

從EDMA v2.0遷移到TMS320DM644X DMSoC的EDMA v3.0
從EDMA v2.0遷移到EDMA v3.0 TMS320C64X DSP
浪潮信息AS13000G7榮獲MLPerf? AI存儲基準測試五項性能全球第一
高鴻信安與百敖軟件完成產品兼容互認證
堆棧和內存的基本知識
如何使用Polyspace Code Prover來統計堆棧





 工商網監
工商網監
評論