 Kubernetes是如何解決資源拓撲感知調度的呢
Kubernetes是如何解決資源拓撲感知調度的呢
資源競爭與資源感知問題
從CPU的體系結構上來看,現代CPU多采用NUMA架構和方式。
NUMA架構是非對稱的,每個NUMA node上會有自己的物理CPU內核,以及每個NUMA node之間也共享L3 Cache。同時,內存也分布在每個NUMA node上的。某些開啟了超線程的CPU,一個物理CPU內核在操作系統上會呈現兩個邏輯的核。
實際上,CPU內核是分布在NUMA node上,NUMA node內本身就有一些親和性的元素。
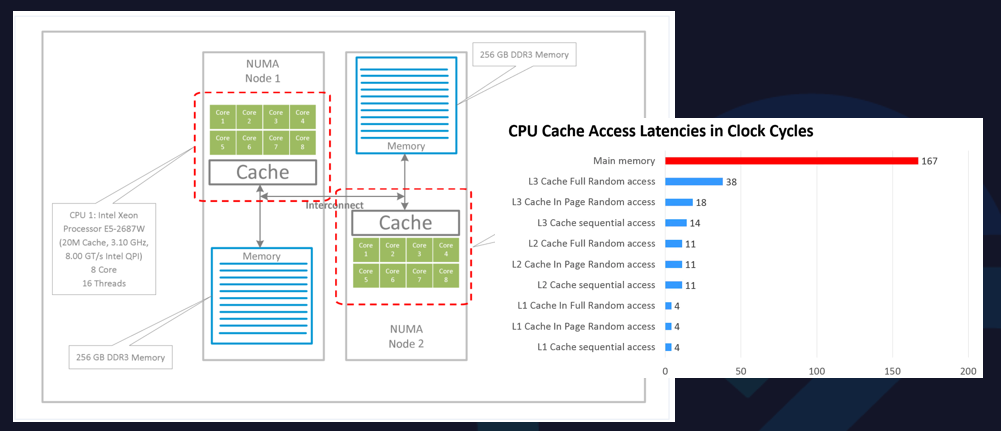
右圖中,CPU開始的訪問速度是不一樣的。
如果程序都跑在同一個NUMA node上,可以更好地去共享一些L3 Cache,L3 Cache的訪問速度會很快。如果L3 Cache沒有命中,可以到內存中讀取數據,訪存速度會大大降低。
因此,從CPU體系結構中可以看到,如果采用一些錯誤的CPU分配方式,可能會導致進程訪存速度急劇下降,嚴重影響應用程序的性能。
在這樣的體系結構下,存在云計算中常見的吵鬧的鄰居問題。當多個容器在節點上共同運行時,由于資源分配的不合理,會對CPU本身的性能造成影響。
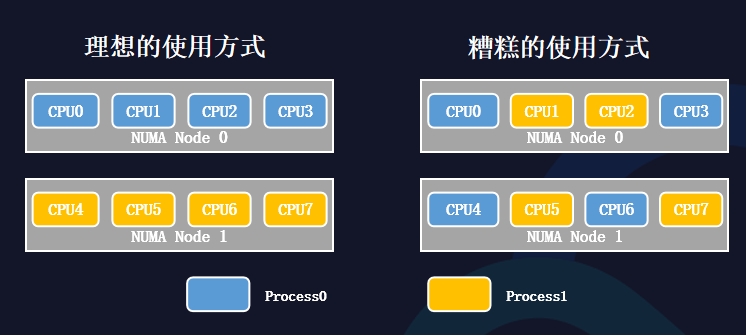
從理想的使用方式來看,如果每個進程都使用各自的CPU內核,并且不會跨NUMA node訪問,相互之間不會有太多爭搶。
從糟糕的使用方式來看,如果兩個進程的CPU內核在分配時,可能會沒有遵循NUMA的親和性,會帶來很大的性能問題,體現在三個方面:
CPU爭搶帶來頻繁的上下文切換時間;
頻繁的進程切換導致CPU高速緩存失敗;
跨NUMA訪存會帶來更嚴重的性能瓶頸。
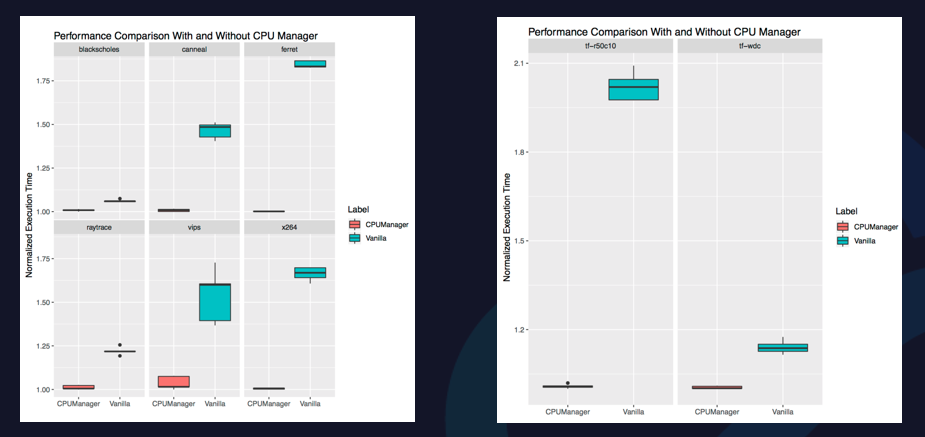
Kubernetes中有CPU Manager的功能,CPU Manager可以做一些CPU核心的分配工作。上圖是Kubernetes的一些數據呈現。
在Guaranteed和Burstable兩種Pod混部測試下,將CPU Manager執行時間做基準,如果是原生Kubernetes的方式在不同測試下,性能有較大波動,最差可能會達到1.8倍左右。
在Stand-Alone Workloads的情況下,做CPU的綁定和完全不做CPU綁定,執行時間差別很大。因為劇烈的CPU爭搶以及頻繁的上下文切換,會導致約1倍的性能差距。

在吵鬧的鄰居問題下,Kubernetes是如何解決的呢?
CPU Manager是其中的一個解決方法,它被放在Kubelet中,CPUSet將會被CPU Manager分在Default和Exclusive兩個池子中。
Default主要在兩種情況下使用。一種是系統守護進程:kube-reserved、system-reserved,另一種是特殊類型的Pod:Burstable、BestEffort、請求非整數CPU的Guaranteed。
Exclusive是完全排他的CPU池,主要在兩種情況下使用。一種是Pod:請求整數CPU的Guaranteed,另一種是Topology Manager:滿足拓撲管理器定義的要求。
但原生Kubernetes也存在局限性。
調度器不感知節點資源拓撲。
Kubernetes中調度器只負責為Pod選擇節點,并不感知節點NUMA拓撲結構,Pod的CPU分配交給Kubelet完成。當節點單NUMA node上沒有足夠的CPU時,Pod啟動失敗,控制器重建Pod后會陷入死循環。
CPUSet分配策略過于單一。
Kubernetes中CPU Manager默認為請求整數CPU的Guaranteed Pod分配獨占的CPUSet,但實際上Pod想定制自己的CPU分配策略,可能只是想分配到一個NUMA node內,或是固定CPU甚至是不做綁核。
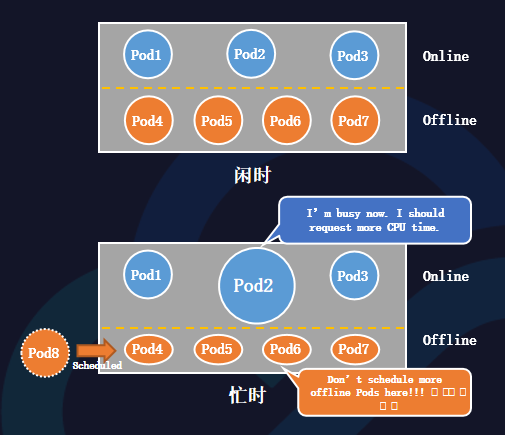
在混部場景下,也存在離線算力感知問題。
當在線與離線任務混部在同一臺主機上,在線閑時,離線任務可以充分使用資源,提升主機利用率;在線忙時,離線任務會被在線搶占,等待資源釋放。
當離線可用算力受在線干擾動態變化時,調度器僅感知節點靜態資源(Kubelet采集)。
如果忙時調度過多的離線任務,會導致劇烈的資源爭搶,并且每個離線Pod的性能都會下降。 因此,調度器在調度時,需要動態感知離線實時算力。驅逐器也應當在線嚴重干擾離線時,驅逐離線Pod,保證節點的算力穩定。
Kuberbnetes精細化調度
在原生Kubernetes不能很好地解決資源競爭與資源感知問題時,亟需對資源進行更加精細化的調度。
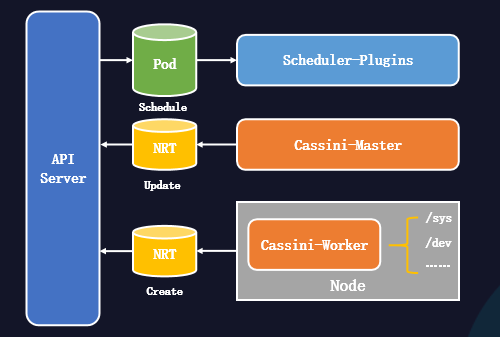
如上圖,是精細化調度系統的結構。
Cassini-Worker能從節點采集資源拓撲信息并創建NRT對象。
Cassini-Master能從外部系統采集節點擴展信息(可選)。
Scheduler-Plugins能擴展調度器,為Pod進行資源拓撲分配。
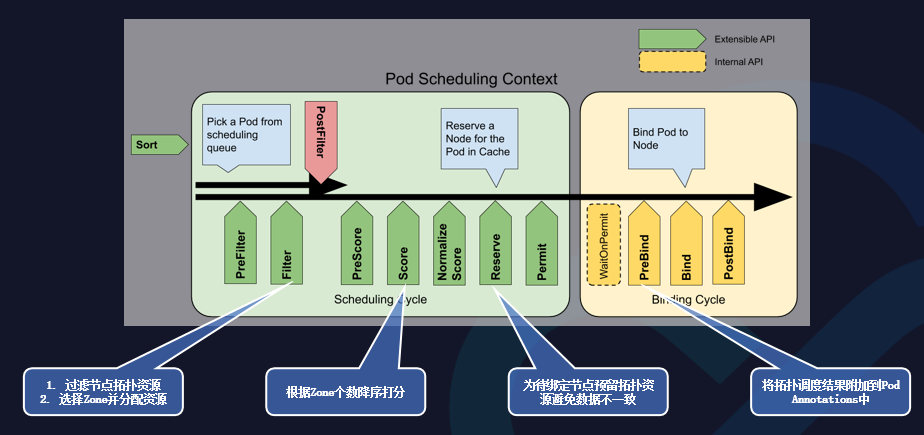
擴展調度器是通過Scheduler-Plugins來實現的,可以在幾個插入點做一些插件,保證實現標庫資源頭部感知調度的功能。
在Fitter的插件內,可以過濾節點拓撲資源和選擇Zone并分配資源。
在Score的插件內,可以根據Zone個數降序打分。
在Reserver的插件內,可以為待綁定節點預留拓撲資源避免數據不一致。
在PreBind的插件內,可以將拓撲調度結果附加到Pod Annotations中。
在調度算法上,可以從性能和負載均衡兩個方面做出考慮,以便更好地選擇節點和拓撲。
在性能方面,優先選擇Pod能綁定在單NUMA node內的節點。如果找不到該節點,可以優先選擇在同一個NUMA Socket內的NUMA node
在負載均衡方面,優先選擇空閑資源更多的NUMA node。
容器CPUSet管理
Kubernetes的精細化調度做出一些拓撲感知,而實際落到節點上,為了更好地實現資源分配,我們設計了一個資源分配系統。
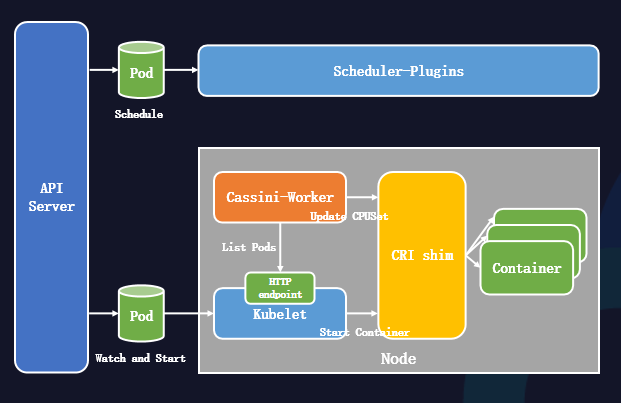
首先,節點Kubelet會監聽到Pod并準備啟動Pod。
隨后,節點Kubelet調用容器運行時接口啟動容器。
與此同時,節點Cassini-Worker通過List Kubelet的10250端口獲得節點上的所有Pod,再從Pod Annotations中獲取調度器的拓撲調度結果。
節點Cassini-Worker調用容器運行時接口來更改容器的綁核結果。
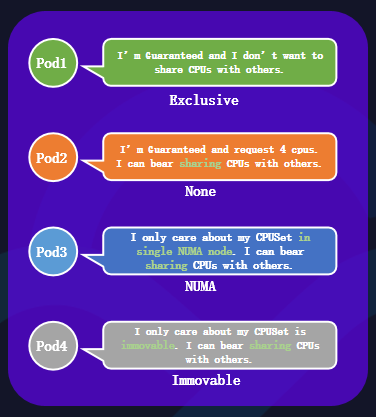
關于容器多級資源QoS分配策略,在CPUSet的策略上,可以劃分為四種:
Exclusive:它可以獨占CPU內核心,其他Pod不可使用,一般是高利用率的容器會采取該策略;
None:不做CPU綁核的策略,可以使用節點的Default CPU共享池;
NUMA:讓CPUSet固定到NUMA node上的共享池內;
Immovable:將CPU內核心固定,讓其他Pod也可共享。
在CPU內核心選擇策略上:
首先,按照調度結果獲取NUMA node上需分配的核心數;
隨后,從共享池中選擇可分配的CPU內核心;
同時,還希望一個Pod盡量不使用在同一個物理核上的邏輯核。
在離線混部場景下的實踐
由于離線混部場景中,離線會受到在線的影響,算力是波動的。因此,在離線混部場景下,還會做一些差異化重調度:
當在線負載上升時,離線的算力會被壓制。因此,離線的Pod需要及時驅逐,以便剛好滿足節點離線算力的要求;
通過改造Descheduler組件,建立通用的可配置的平臺通用驅逐框架,支持Metrics驅逐,以及支持動態調整/配置驅逐策略;
建立算力平臺通用Metrics;
支持業務自定義Metrics驅逐。
在不同混部場景下,容器CPUSet策略也是不同的。
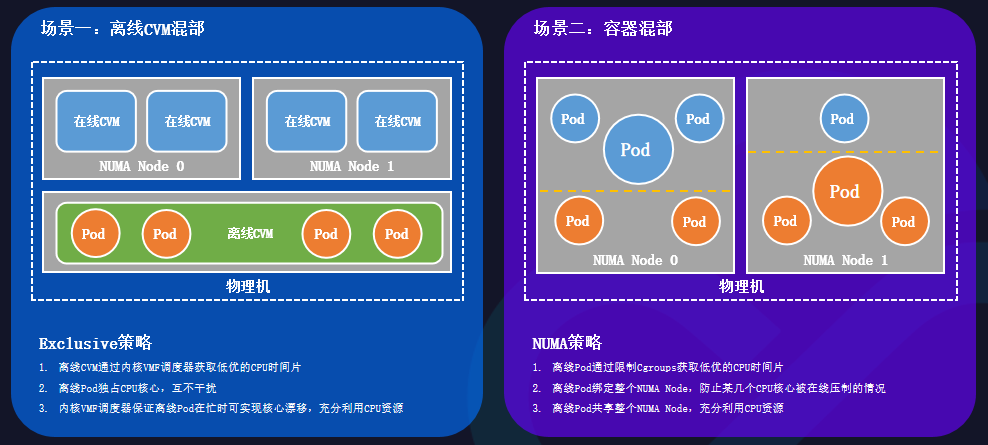
離線CVM混部的場景中,一臺物理機的各個NUMA node上都生產了許多在線的CVM,當在線利用率很低時,需要更好地利用資源。
此時需要采取Exclusive策略:
離線CVM通過內核VMF調度器獲取低優的CPU時間片;
離線Pod通過獨占CPU內核心的方式,保證互不干擾;
內核VMF調度器保證離線Pod在忙時,可實現核心漂移,充分利用CPU資源。
在容器混部的場景中,在線Pod和離線Pod同時部署在同一臺物理機上。
此時需要采取NUMA策略:
離線Pod通過限制Cgroups,獲取低優的CPU時間片;
離線Pod綁定整個NUMA node,防止某幾個CPU內核心被壓制;
離線Pod共享整個NUMA node,充分利用CPU資源。
總結
本文圍繞Kubernetes的資源拓撲感知調度的主題展開。從CPU體系結構和吵鬧的鄰居問題切人,隨后闡述了原生Kubernetes的不足和混部場景下的算力感知的局限,最后從采集節點拓撲資源、擴展Kubernetes調度器、多級資源QoS分配策略幾個方面給出了相應的解決方案。在策略的優化后,資源得到更合理地利用。
未來,Kubernetes精細化調度將會覆蓋更多的場景,例如碎片GPU、網絡拓撲架構、電力調度。
審核編輯:劉清
-
cpu
+關注
關注
68文章
11048瀏覽量
216111 -
操作系統
+關注
關注
37文章
7103瀏覽量
125032 -
調度算法
+關注
關注
1文章
68瀏覽量
12088
原文標題:騰訊方睿:詳解Kubernetes資源拓撲感知調度
文章出處:【微信號:coder_life,微信公眾號:程序人生】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【啟揚方案】基于RK3588的救護車智能調度系統應用解決方案

詳解Kubernetes中的Pod調度親和性
安全生產調度管理系統的核心功能模塊
Kubernetes Helm入門指南
梯度科技助力客戶破解算力調度難題
Kubernetes負載均衡器MetalLB介紹
Kubernetes中部署MySQL集群
Kubernetes包管理工具Helm的安裝和使用

構建綜合指揮調度系統的重要性
Kubernetes:構建高效的容器化應用平臺
使用 Flexus 云服務器 X 實例部署 Kubernetes 圖形化管理平臺
Kubernetes的CNI網絡插件之flannel
使用Velero備份Kubernetes集群
如何使用Kubeadm命令在PetaExpress Ubuntu系統上安裝Kubernetes集群





 工商網監
工商網監
評論