 一文解析交互式相機標定的高效位姿選擇方法
一文解析交互式相機標定的高效位姿選擇方法
摘要
平面圖案標定姿勢的選擇很少被考慮——但標定精度很大程度上取決于它。本文提出了一種姿態選擇方法,可以找到一個緊湊和魯棒的標定姿態集,并適合于交互式標定。奇異的姿態會導致解決方案不可靠,而減少姿態的不確定度對標定有利的。為此,我們使用不確定性傳播原理。
我們的方法利用了一個自識別的標定圖案來實時跟蹤相機的姿態。這允許迭代地引導用戶到目標姿態,直到達到所需的質量水平。因此,只需要一組稀疏的關鍵幀來進行標定。
該方法在單獨的訓練集和測試集以及合成數據上進行了評估。我們的方法比可比較的解決方案性能更好,同時需要更少的30%的標定幀。
01 引言
 |
| 圖1 使用9個選定的姿勢和用戶指導覆蓋,投影到到右下角的相機。 |
在三維計算機視覺的背景下,相機標定是確定相機內部的幾何和光學特征(內參)以及相機在世界坐標系中的位置和方向(外參)的過程。許多三維計算機視覺算法的性能直接取決于該標定的質量。此外,標定是一個重復任務,每次設置必須更改時執行。即使是同款相機,這些參數也可能會由于制造的不準確性而變化。相機標定的流行方法是基于獲取一個已知尺寸的平面圖案的多幅圖像。然而,存在退化姿態配置會導致不可靠的解。
因此,標定的任務不能由沒有經驗的用戶來完成——即使是在該領域工作的研究人員也經常難以量化什么是良好的標定圖像。 有一些研究對CCD成像平面與圖案之間的夾角對估計誤差的影響進行了研究:
Triggs將角擴散與焦距誤差聯系起來。他發現超過5°后誤差會擴散。
Sturm和Maybank進一步區分了估計主點和焦距。更重要的是,他們討論了在使用一個平面和兩個平面進行標定時可能存在的奇點,并將它們與單個針孔參數聯系起來;例如,如果圖案在每一幀中平行于圖像平面,則不能確定焦距。
這些發現在中得到了重復。然而,姿態對失真參數估計或一般相機相對標定板的姿態影響迄今尚未被考慮。
另一個方面是標定數據的質量和數量。
Sun和庫珀斯托克評估了攝像機模型對噪聲的靈敏度、訓練數據量和在模型復雜性方面的標定精度。然而,他們只測量了各自訓練集上的殘差,這受過擬合的影響。
為了克服這個問題,理查森等人引入了最大期望重投影誤差(最大ERE)度量,而不是與測試誤差相關,從而允許一個有意義的收斂測試。此外,他們會自動計算一個“最佳的下一個姿勢”,并將其作為圖案的疊加投影作為用戶指導。通過在大約60個候選姿態的固定集合中進行窮舉搜索來選擇姿態。對于每個姿態,執行一個包括該姿態的假設標定,并選擇最大ERE最小的姿態。然而,候選姿態在視場中均勻分布,沒有明確考慮角擴散和退化情況。
在輔助用戶標定任務的一般情況下,尚未特別考慮相機標定的準確性。 我們提出在解析生成最優模式姿態的同時,明確地避免退化的姿態配置。為此,我們將姿態與單個參數的約束聯系起來,這樣所產生的姿態序列就可以約束所有的校準參數,并確保準確的校準。與的窮舉搜索相比,這將計算時間從秒減少到毫秒。
利用估計解的協方差來評估校準參數的不確定度。然后對姿態序列進行調整,以便為最不確定的參數捕獲更多的約束。參數的協方差與檢驗誤差相關,因此也可以作為一個收斂準則。
基于以上幾點,我們的主要貢獻是:
兩種不同的姿態選擇策略
一種有效的姿態選擇方案
本文的結構如下:
第2節:介紹了所使用的相機模型和不確定度估計方法,并討論了一個合適的標定圖案的選擇。
第3節:描述了我們的新的姿態選擇方法
第4節:描述了完整的標定流程。
第5節:
對該方法在真實數據和合成數據進行了評估,并與OpenCV和AprilCal[10]的標定方法進行了比較[3]。
分析了結果標定的緊致性,并進行了一個非正式的用戶調查,以顯示該方法的可用性。
最后,我們以第6節總結了我們的結果,并討論了其局限性和未來的工作。
02 準備工作

2.1 估計和誤差分析

其中:

2.2 標定圖案
我們的方法適用于任何平面標定目標,例如常見的棋盤和圓網格圖案。然而,對于交互式用戶指導,快速的板檢測是至關重要的。因此,我們使用在OpenCV中實現的自識別ChArUco[5]圖案。與經典棋盤相比,這節省了檢測到的矩形對規范拓撲的耗時順序。然而,我們也可以在這里使用任何最近開發的自我識別目標[1,2,4]。 圖案大小被設置為個方塊,從而在每個捕獲幀的棋盤關節上進行多達40次測量。這允許成功地完成初始化,即使沒有檢測到所有的標記,如第4.3節中所討論的那樣。
03 姿勢選擇
我們的方法的核心思想是明確地指定使用Zhang[16]的方法進行標定的單個關鍵幀。 在本節中,首先討論了內參和標定板姿態的關系,我們將參數向量分為針孔和失真參數。對于每個參數組,我們然后給出我們的規則集,以生成一個最優姿態,同時顯式地避免退化配置。
3.1 分離針孔和畸變參數
看公式1,我們可以看到,和都應用于后投影,描述了二維到二維的映射。因此,我們可以考慮僅從一個均勻采樣圖像的板姿態來估計。然而,由于內參和外參同時由[16]估計,不確定性增加。
引用: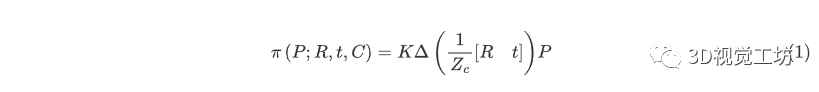

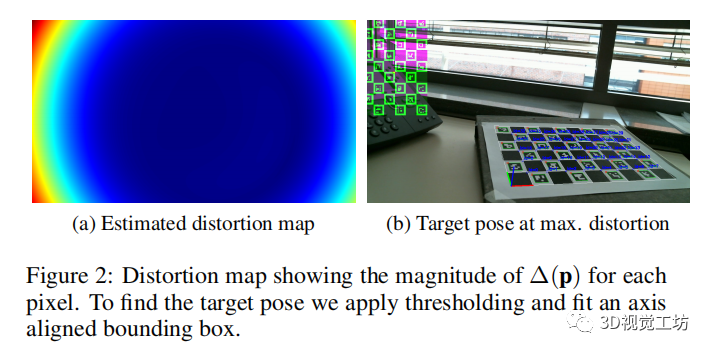 |
|
圖2 失真圖,顯示了每個像素的?(p)的大小。 為了找到目標姿態,我們應用閾值化和擬合一個軸對齊的邊界框。 |

3.2 避免針孔相機的奇異性

3.3 姿勢生成
|
|
|
圖3 示例性姿態選擇狀態。頂部:色散指數。 左:經過一個(洋紅色)和兩個(黃色)細分步驟后的固有標定候選位置。 右:已經訪問過的區域的扭曲地圖。 |


3.4 初始化

04 標定過程
在下面,我們將介紹參數細化和用戶指導部分以及任何使用的啟發式方法。這就完成了用于真實數據實驗的標定流程。
4.1 參數優化

4.2 用戶指導
為了指導用戶,目標相機姿態投影使用當前估計的內在參數。然后,這個投影被顯示為一個覆蓋在直播視頻流的頂部(參見圖1和補充材料中的視頻)。 驗證用戶是否足夠接近目標姿態我們使用Jaccard指數J(A,B)(交集聯合)計算的投影模式的目標姿態T和面積的投影從當前姿態估計e我們假設用戶已經達到所需的姿態如果J(T,E)>0.8。 比較投影重疊而不是直接使用估計的姿態是更穩健的,因為姿態估計通常是不可靠的——特別是在初始化期間。
4.3 啟發法
在整個過程中,我們強制執行通用啟發式約束[6,7.2],即約束的數量應該超過未知數的5倍。所使用的校準方法[16]不僅估計了固有參數C,而且還估計了模型平面和圖像平面的相對姿態,即參數R、三維旋轉和t、三維平移。當使用M校準圖像時,我們有d=9+6M未知數,每個點對應提供了兩個約束。對于初始化(M=2),我們有21個未知數,這意味著總共需要52.5個點對應或每幀需要27個對應。對于任何后續的幀,只需要15個點。 為了防止由于運動模糊和滾動快門偽影而導致的不準確的測量,圖案應該是靜止的。為了確保這一點,我們要求在連續的幀中重新檢測到所有的點,并且這些點的平均運動要小于1.5px(根據經驗確定)。
05 評估
在合成數據和真實數據上對該方法進行了評價。合成實驗旨在驗證第3節中提出的參數分割和姿態生成規則,并使用真實數據與其他方法進行比較。此外,通過對測試集進行直接優化,估計了結果與真實數據的緊致性。
5.1 合成數據
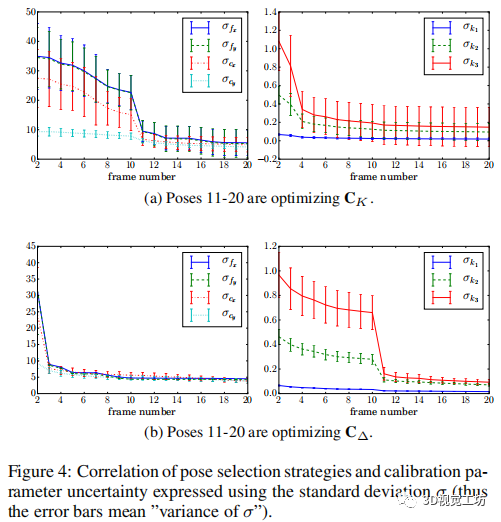 |
| 圖4 姿態選擇策略和校準參數不確定性的相關性(因此誤差條意味著“σ的方差”)。 |

5.2 真實數據
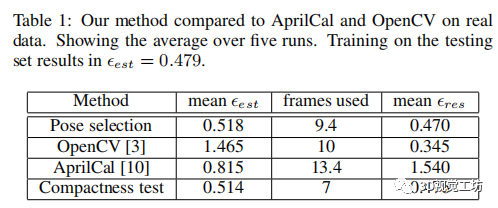 |
| 表1:我們的方法與AprilCal和OpenCV的真實數據進行了比較。顯示五次以上的平均值。對測試集的訓練結果在中。 |

5.3 標定緊致度的分析

5.4 用戶調查

06 結論和未來的工作
我們提出了一種校準方法來生成一組緊湊的校準框架,適合于交互式用戶指導。避免了奇異的姿態配置,從而捕獲約9個關鍵幀就足以進行精確的校準。這比可比的解決方案少了30%。所提供的用戶指導允許沒有經驗的用戶在2分鐘內完成校準。校準精度可以根據收斂閾值與所需的校準時間進行加權。攝像機參數的不確定性在整個過程中都被監測,以確保可以反復達到給定的置信水平。 我們的評估表明,所需的幀的數量仍然可以減少,以進一步加快這個過程。我們只使用一個廣泛而簡單的失真模型,在未來的工作中需要考慮薄棱鏡[15]、徑向[8]和傾斜傳感器。最終,我們可以加入對未使用的參數的檢測。這將允許從最復雜的失真模型開始,它可以在校準過程中逐漸減少。 此外,該方法需要適應特殊情況,如顯微鏡,其中視野深度限制可能的校準角度或在大距離的校準,因此縮放標定板是不需要的。
審核編輯:劉清
-
計算機
+關注
關注
19文章
7636瀏覽量
90270 -
人工智能
+關注
關注
1804文章
48788瀏覽量
246938 -
視覺算法
+關注
關注
0文章
32瀏覽量
5754
原文標題:交互式相機標定的高效位姿選擇方法集
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
非標定制超聲波清洗設備的核心技術解析與應用

ADC靜態參數全解析:從偏移誤差到未調整總誤差,一文掌握核心計算!
東軟聯合推出新一代全語言交互式人社服務機器人“南小寧”
中國移動攜手華為打造全國首個5G新通話交互式客服
肇觀電子首發自標定3D深度相機
請問做反射式血氧飽和度測量時如何進行標定呢?
用于任意排列多相機的通用視覺里程計系統
Google DeepMind發布Genie 2:打造交互式3D虛擬世界
交互式ups和在線UPS不同點,超過限值

ZCAN PRO解析的DBC Singal 起始位與XNET解析的起始位不同;解析的信號不符合大端邏輯
交互式低延遲音頻解碼器








 工商網監
工商網監
評論