 一個具有泛化性的小樣本語義分割(GFS-Seg)
一個具有泛化性的小樣本語義分割(GFS-Seg)

1 前言
之前已經有過關于小樣本語義分割的論文解讀,關于如何用 Transformer 思想的分類器進行小樣本分割。本篇是發表在 CVPR 2022 上的 Generalized Few-shot Semantic Segmentation(后文簡稱 GFS-Seg),既一種泛化的小樣本語義分割模型。在看論文的具體內容之前,我們先了解一些前置知識。
深度學習是 Data hunger 的方法, 需要大量的數據,標注或者未標注。少樣本學習研究就是如何從少量樣本中去學習。拿分類問題來說,每個類只有一張或者幾張樣本。少樣本學習可以分為 Zero-shot Learning(即要識別訓練集中沒有出現過的類別樣本)和 One-Shot Learning/Few shot Learning(即在訓練集中,每一類都有一張或者幾張樣本)。以 Zero-shot Learning 來說,比如有一個中文 “放棄”,要你從 I, your、 she、them 和 abnegation 五個單詞中選擇出來對應的英文單詞,盡管你不知道“放棄”的英文是什么,但是你會將“放棄”跟每個單詞對比,而且在你之前的學習中,你已經知道了 I、 your、she 和 them 的中文意思,都不是“放棄”,所以你會選擇 abnegation。還需要明確幾個概念:
Support set:支撐集,每次訓練的樣本集合。
Query set:查詢集,用于與訓練樣本比對的樣本,一般來說 Query set 就是一個樣本。
在 Support set 中,如果有 n 個種類,每個種類有 k 個樣本,那么這個訓練過程叫 n-way k-shot。如每個類別是有 5 個 examples 可供訓練,因為訓練中還要分 Support set 和 Query set,5-shots 場景至少需要 5+1 個樣例,至少一個 Query example 去和 Support set 的樣例做距離(分類)判斷。
2 概述
訓練語義分割模型需要大量精細注釋的數據,這使得它很難快速適應不滿足這一條件的新類,FS-Seg 在處理這個問題時有很多限制條件。在這篇文章中引入了一個新的方法,稱為 GFS-Seg,能同時分割具有極少樣本的新類別和具有足夠樣本的基礎類別的能力。建立了一個 GFS-Seg baseline,在不對原模型進行結構性改變的情況下能取得不錯的性能。此外,由于上下文信息對語義分割至關重要,文中提出了上下文感知原型學習架構(CAPL),利用 Support Set 樣本共同的先驗知識,根據每個 Query Set 圖像的內容動態地豐富分類器的上下文信息,顯著提高性能。
3 GFS-Seg 和 FS-Seg 的 Pipeline 區別
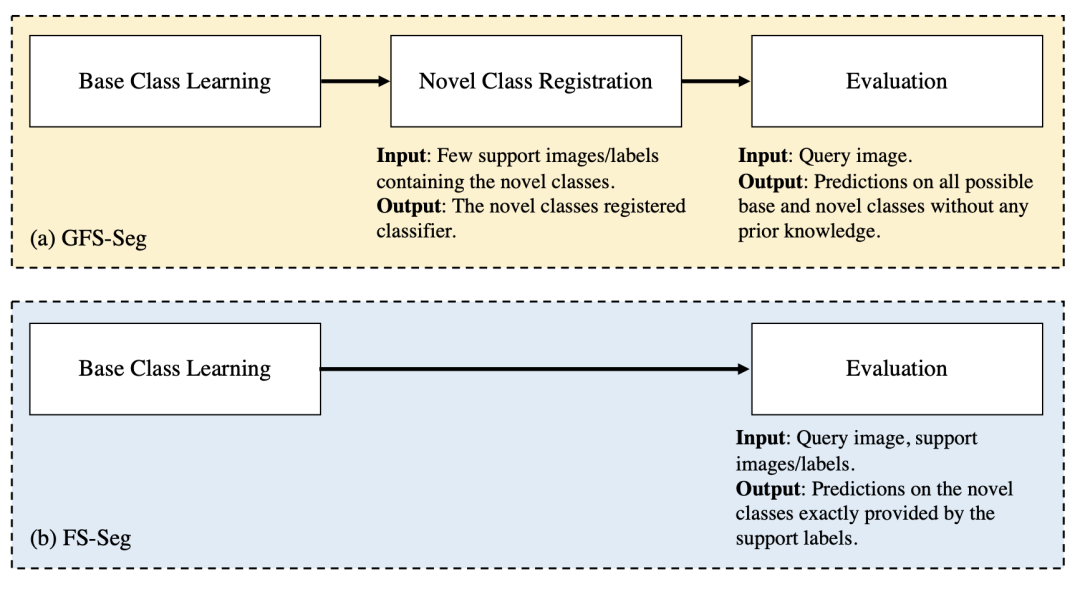
如下圖所示,GFS-Seg 有三個階段。分別是:基類的學習階段;新類的注冊階段,其中包含新類的少數 Support set 樣本;對基類和新類的評估階段。也就是說,GFS-Seg 與 FS-Seg 的區別在于,在評估階段,GFS-Seg 不需要轉發測試(Query set)樣本中包含相同目標類的 Support set 樣本來進行預測,因為 GFS-Seg 在基類學習階段和新類注冊階段應該已經分別獲得了基類和新類的信息。GFS-Seg 在事先不知道查詢圖像中包含哪些類別的情況下,同時對新類進行預測時,可以在不犧牲基類準確性的情況下仍表現良好。
4 Towards GFS-Seg
在經典的 Few-Shot Segmentation 任務中,有兩個關鍵標準:(1) 模型在訓練期間沒有看到測試類的樣本。(2) 模型要求其 Support set 樣本包含 Query set 中存在的目標類,以做出相應的預測。
通過下圖,我們來看下 GFS-Seg 與經典人物有哪些不同。下圖中用相同的 Query 圖像說明了 FS-Seg 和 GFS-Seg 的一個 2-way K-shot 任務,其中牛和摩托車是新的類,人和車是基類。先來看下 (a),Prototype Network 通過 Embedding Generation 函數,將牛和摩托車的少量訓練樣本映射為 2 個向量,在檢測分類時候,將待分割圖像的特征也通過 Embedding Generation 映射為向量,最后計算待檢測向量與 2 個向量的特征差異(假設是距離),認定距離最小的為預測類別。(a) 只限于預測 Support set 中包含的類的二進制分割掩碼。右邊的人和上面的車在預測中缺失,因為支持集沒有提供這些類的信息,即使模型已經在這些基類上訓練了足夠的 epoch。此外,如果 (a) 的支持集提供了查詢圖像中沒有的多余的新類(如飛機),這些類別可能會影響模型性能,因為 FS-Seg 有一個前提條件,即 Query 圖像必須是 Support set 樣本提供的類。
FS-Seg 模型只學習并預測給定的新類的前景掩碼,所以在我們提出的 GFS-Seg 的通用化設置中,性能會大大降低,因為所有可能的基類和新類都需要預測。不同的是,(b) 也就是 GFS-Seg,在沒有 Query 圖像中包含的類的先驗知識的情況下,同時識別基類和新類,額外的 Support set(如 (b) 左上角的飛機)應該不會對模型產生很大影響。在評估過程中,GFS-Seg 不需要事先了解 Query 圖像中存在哪些目標類別,而是通過注冊新的類別,對所有測試圖像一次性形成一個新的分類器((b) 中的藍色區域代表新的類別注冊階段)。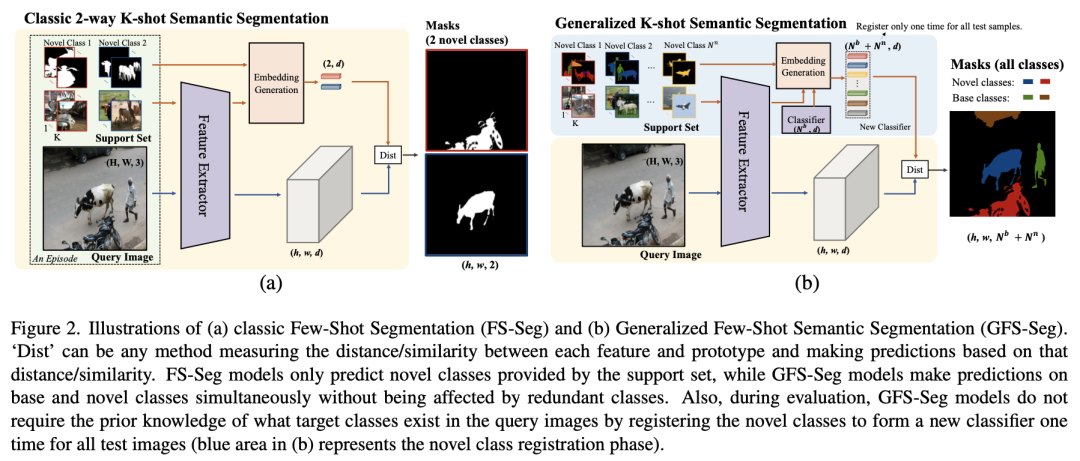
此外,還有更多關于 GFS-Seg 的 baseline 細節,這里就不詳細展開了,讀者們可以一遍看代碼一邊看論文中的解釋,不難理解。
5 上下文感知原型學習(CAPL)
原型學習(PL)適用于小樣本分類和 FS-Seg,但它對 GFS-Seg 的效果較差。在 FS-Seg 的設置中,查詢樣本的標簽只來自于新的類別。因此,新類和基類之間沒有必要的聯系,可以利用它來進一步改進。然而,在 GFS-Seg 中,對每個測試圖像中包含的類別沒有這樣的限制,需要對所有可能的基類和新穎類進行預測。
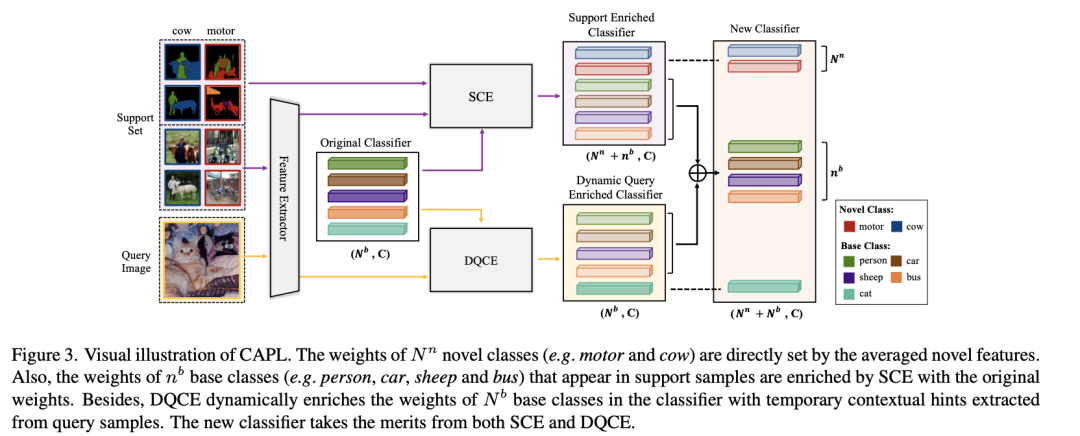
如上圖所示,我們不關注 SCE 和 DQCE 的計算過程。SCE 只發生在新的類注冊階段,它利用支持 Support set 樣本來提供先驗知識。然而,在評估階段,新分類器由所有 Query 圖像共享,因此引入的先驗可能會偏向于有限的 Support set 樣本的內容,導致對不同 Query 圖像的泛化能力較差。為了緩解這個問題,進一步提出了動態查詢上下文豐富計算(DQCE),它通過動態合并從單個查詢樣本中挖掘的基本語義信息,使新分類器適應不同的上下文。繼續看上圖,N‘n 個新類別(例如摩托車和奶牛)的權重直接由特征平均得出。此外,Support set 中出現的 N’b 個基類(例如人、汽車、羊和公共汽車)的權重由 SCE 用原始權重計算得出。此外,DQCE 通過從 Query set 樣本中提取的臨時上下文特征,動態豐富了分類器中 N'b 個基類的權重。綜上,新的分類器結合了 SCE 和 DQCE 的優點。
GFS-Seg 使用 CAPL 的方式完成訓練,具體性能表現在下面的實驗部分列出。
6 實驗
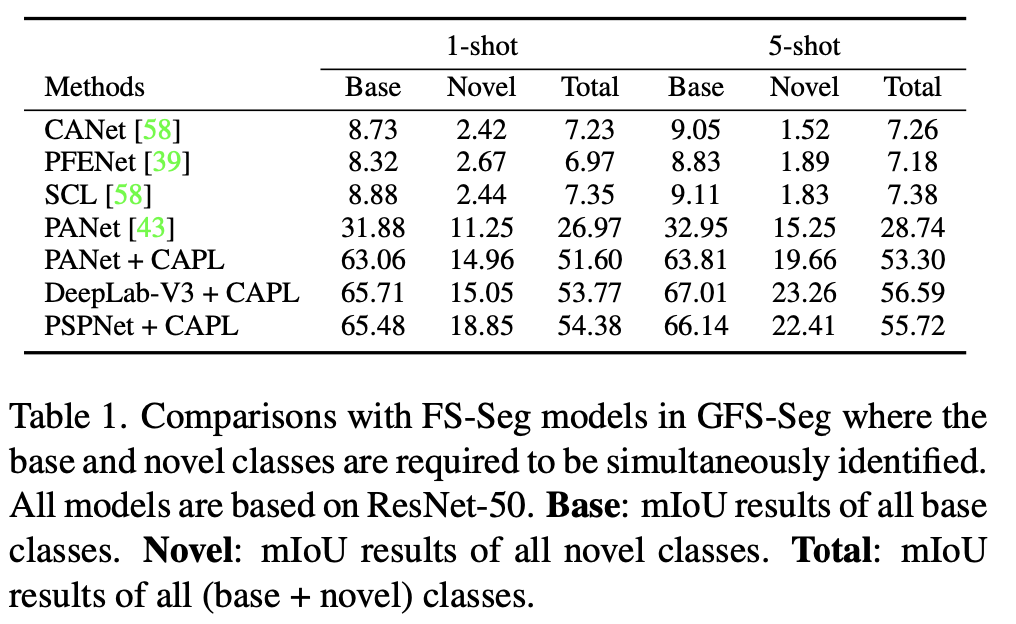
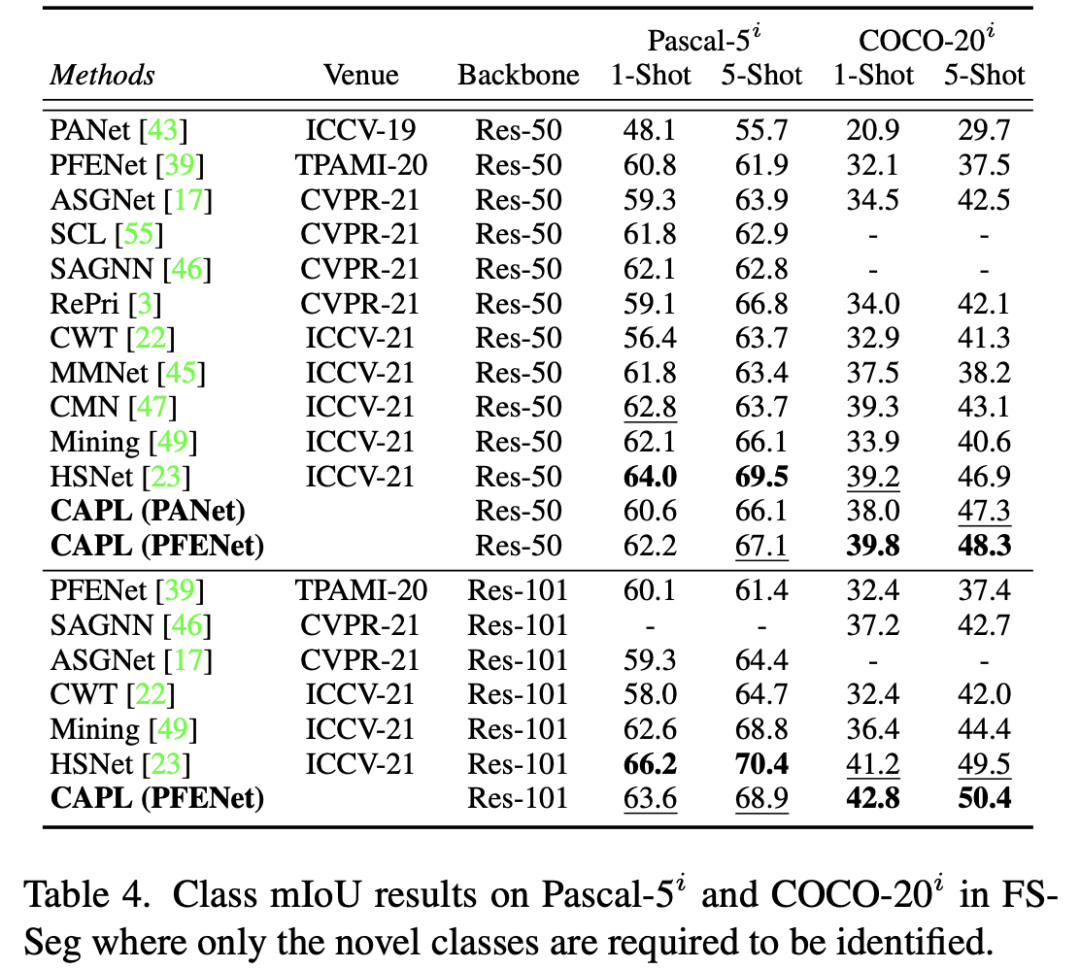
如下表所示,CANet、SCL、PFENet 和 PANet 與用 CAPL 實現的模型相比表現不佳。值得注意的是,下表中的 mIoU 的結果是在 GFS-Seg 配置下的,因此它們低于這些 FS-Seg 模型的論文中給出的結果,這種差異是由不同的全局設置造成的。在 GFS-Seg 中,模型需要在給定的測試圖像中識別所有的類,包括基類和新類,而在 FS-Seg 中,模型只需要找到屬于一個特殊的新類的像素,不會去分割基類,Support set 的樣本提供了目標類是什么的先驗知識。因此,在 GFS-Seg 中,存在基類干擾的情況下,識別新類要難得多,所以數值很低。
FS-Seg 是 GFS-Seg 的一個極端情況。所以為了在 FS-Seg 的中驗證提出的 CAPL,在下表中,我們將 CAPL 合并到 PANet 和 PFENet。可以看出, CAPL 對 baseline 實現了顯著的改進。數據集是 Pascal-5i 和 COCO-20i ,只需要識別新類。
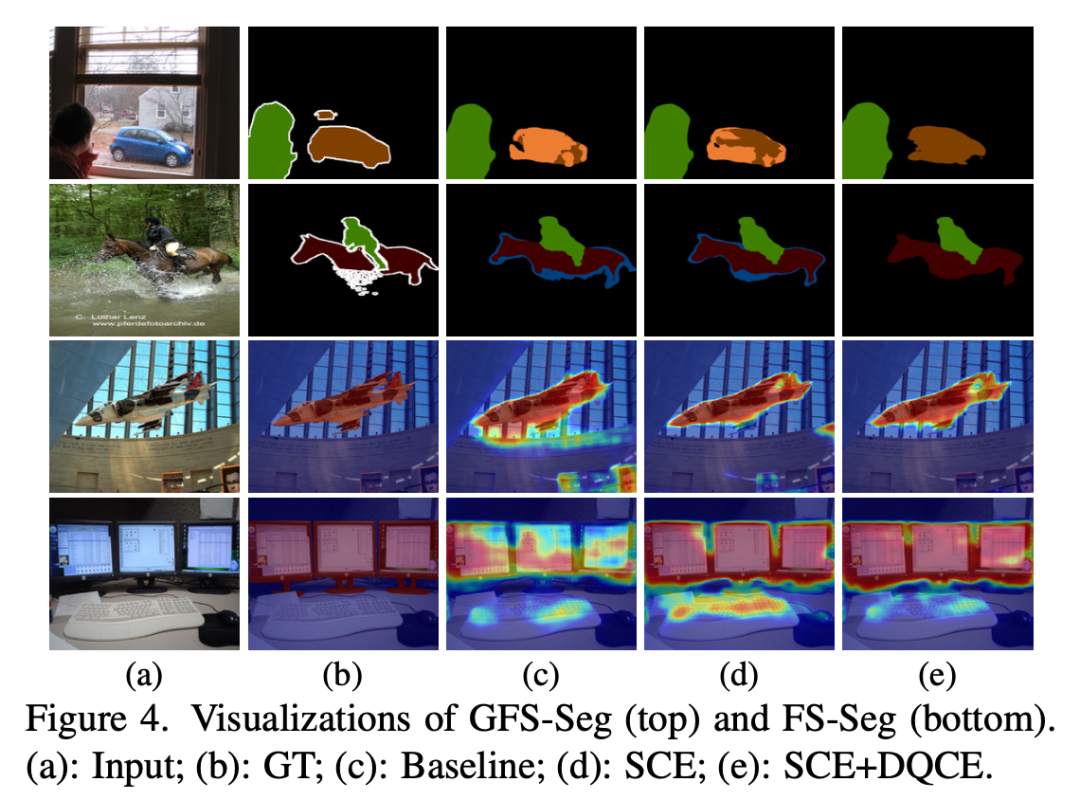
下圖對分割結果進行了可視化,其中 SCE 和 DQCE 的組合進一步完善了 baseline 的預測,還有一些消融實驗的效果這里不一一列出了。
7 結論
這篇閱讀筆記僅為個人理解,文章提出了一個具有泛化性的小樣本語義分割(GFS-Seg),并提出了一個新的解決方案:上下文感知原型學習(CAPL)。與經典的 FS-Seg 不同,GFS-Seg 旨在識別 FS-Seg 模型所不能識別的基礎類和新類。提出的 CAPL 通過動態地豐富上下文信息的適應性特征,實現了性能的顯著提高。CAPL 對基礎模型沒有結構上的限制,因此它可以很容易地應用于普通的語義分離框架,并且它可以很好地推廣到 FS-Seg。
審核編輯:劉清
原文標題:CVPR 2022:Generalized Few-shot Semantic Segmentation 解讀
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
EL非監督分割白皮書丨5張OK圖、1分鐘建模、半小時落地的異常檢測工具!

【正點原子STM32MP257開發板試用】基于 DeepLab 模型的圖像分割
如何修改yolov8分割程序中的kmodel?
RK3576 yolov11-seg訓練部署教程
SparseViT:以非語義為中心、參數高效的稀疏化視覺Transformer

ADS8556和ADS8568采集一個樣本點最快支持多少nS?
手冊上新 |迅為RK3568開發板NPU例程測試
語義分割25種損失函數綜述和展望






 工商網監
工商網監
評論