 預先訓練的語言模型能像人類一樣聰明地解釋明喻嗎?
預先訓練的語言模型能像人類一樣聰明地解釋明喻嗎?
前言
明喻是人們日常生活中一類常見的表述形式,解釋明喻可以幫助機器更好地理解自然語言。因此,明喻解釋(SimileInterpretation)是自然語言處理領域中一個重要的研究問題。如今,大規模預訓練語言模型(Pre-trainedLanguage Models , PLMs)在各類自然語言處理任務上得到突出的表現效果。那預訓練語言模型是否能像人一樣解釋明喻呢?
本文介紹了復旦大學知識工場實驗室的最新工作《Can Pre-trained Language Models Interpret Similes as Smart as Human?》,該工作已經被ACL 2022錄用。此工作創新性地提出了明喻屬性探測任務(Simile Property Probing),也即讓預訓練語言模型推斷明喻中的共同屬性。此工作從通用語料文本、人工構造題目兩個數據源構建明喻屬性探測數據集,規模為1,633個題目,涵蓋七個主要類別。基于構建的數據集,實驗證明預訓練語言模型具有一定推斷明喻屬性的能力,但是仍然不及人類的表現。為了進一步增強預訓練語言模型的明喻解釋能力,此工作借鑒知識表示方法設計優化目標,將明喻知識注入模型。實驗證明,該優化目標在探測任務帶來8.58%的提升、在情感分析下游任務上帶來1.37%的提升。

paper: https://arxiv.org/abs/2203.08452
Datasets and Code:https://github.com/Abbey4799/PLMs-Interpret-Simile
研究背景
通過捕捉概念之間的共同屬性,明喻將看似無關的兩個概念聯系起來,形成一段生動的表述。例如圖1中雖然“老婦人”與“蝸牛”看似毫無關系,前者是人類,后者是動物。但是,由于二者的共同屬性——“行走速度較慢”,明喻便在二者之間建立了聯系,拓展了語言的表達能力,豐富了讀者的想象力。
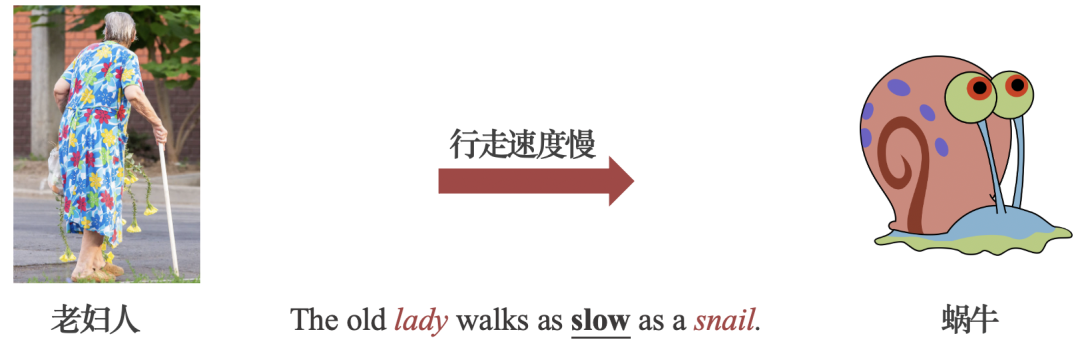
圖1:明喻通過共同屬性將兩個概念聯系起來的示例。
明喻主要分為兩類:封閉式明喻(ClosedSimile),以及開放式明喻(OpenSimile)。如圖2所示,二者區別在于是否顯式地指明本體、喻體的共同屬性,例如上例中的“速度慢”。
若屬性顯式出現(例如,The old lady walks as slow as a snail.),則是封閉式明喻;
若沒有顯式指出屬性(例如,The old lady walks like a snail.),則是開放式明喻。
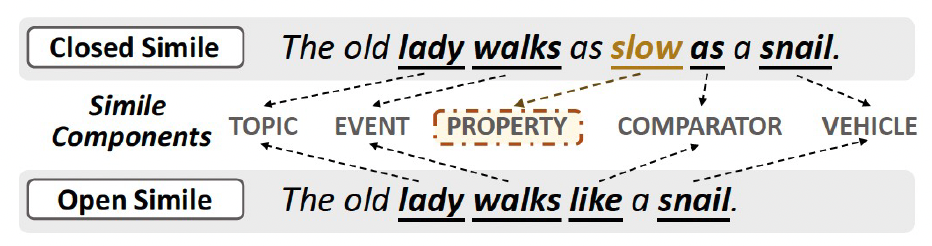
圖2:兩類明喻的示例。二者區別在于是否顯式地指明共同屬性。
明喻解釋是自然語言處理領域中的一個重要研究問題,可以幫助許多下游任務,例如:理解更復雜的修辭手法、情感分析任務等。以明喻“這個律師像一條鯊魚”為例,此句雖然用詞中性,但當機器推斷出“律師”和“鯊魚”共同具有的“氣勢洶洶”這一屬性后,便可判斷這一句所表達的是消極情緒。
近年來,大規模預訓練語言模型,例如BERT、RoBERTa,成為解決自然語言處理任務的新趨勢。許多研究證明,大規模預訓練語言模型在預訓練過程中存儲了一定知識在模型豐富的參數、精巧的結構中。然而,預訓練語言模型解釋明喻的能力卻并未被關注。
因此,我們創新性地提出了明喻屬性探測任務(SimileProperty Probing)。通過讓預訓練語言模型推斷明喻中的共同屬性,從而研究了預訓練語言模型解釋明喻的能力。
明喻屬性探測任務
01
問題建模
為了研究預訓練語言模型解釋明喻的能力,我們遮蓋(Mask)了封閉式明喻(ClosedSimile)中的屬性,讓語言模型根據上下文信息推斷屬性。由于本體和喻體可能同時擁有多個屬性,因此,我們將任務設計為選擇題(只有一個正確答案)而非填空題。
給定一個單詞序列S={w1w2,,...,wi-1,[MASK],wi+1,...,wn},將本體和喻體共有屬性wi遮蓋為[MASK]符號。PLMs需要從四個選項中選擇正確屬性,剩余三個選項為錯誤干擾選項。
02
數據集構建
針對明喻屬性探測任務,我們構建了評估數據集。我們首先從兩個數據來源搜集封閉式明喻,并基于明喻組件設計干擾選項候選集合,接著我們利用余弦相似度篩選最具有挑戰性的干擾選項得到最終選項,最后我們通過人工標注確保數據集的質量。整體數據集構建流程展示如圖3。
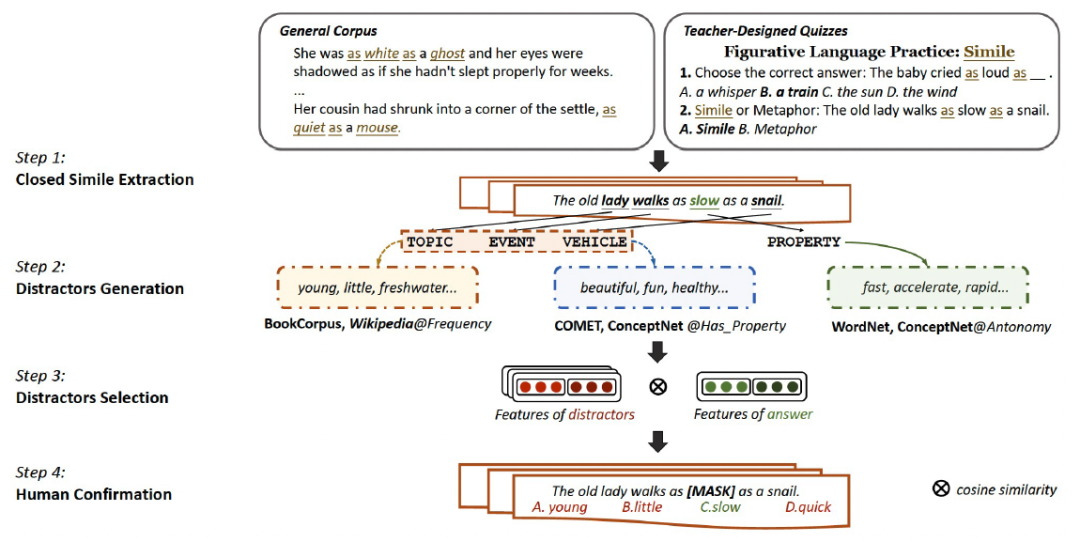
圖3:構建明喻屬性探測數據集流程圖。
數據來源
我們選擇兩個數據來源以構建數據集:通用語料文本、人工構造題目。由于開放式明喻的屬性沒有被顯式指出,若要用以構建明喻屬性探測數據集,需要人工根據上下文標注正確屬性。為了減少標注的成本,在構建數據集的過程中,我們選擇顯式指出屬性的封閉式明喻作為數據來源。
通用語料文本。首先選取兩個通用語料庫:BNC以及iWeb,隨后利用模版as ADJ as (a, an, the) NOUN匹配句子。
人工構造題目。老師為檢驗學生是否掌握明喻知識所制定的題目是合適的數據來源。因此,我們將在線測驗的趣味學習平臺Quizizz作為數據來源。選取一系列標題與明喻相關的測驗,并基于測驗中的問題和答案解析出封閉式明喻。
為了保證數據集的質量,三個標注者對句子是否為明喻進行判斷,并標注每個句子的明喻組件。數據集中所有屬性均為單符號的(single-token),原句中的多符號(multi-token)屬性均被替換為它們在知識庫WordNet和ConceptNet中的單符號同義詞。
干擾選項構建
為了保證題目的質量,我們以兩個原則設計了剩余的三個干擾選項:錯誤(true-negative)、具有挑戰性(challenging)。也即,高質量的干擾選項應該違背上下文的邏輯(true-negative ),同時與正確答案語義相關(challenging)。
生成干擾選項。為了實現“具有挑戰性(challenging)”的要求,我們基于明喻中四個語義相關的組件(本體topic、喻體vehicle、謂詞event、屬性property)設計干擾選項候選集合。
給定原有屬性,我們首先從知識庫WordNet和ConceptNet中獲取反義詞;
對于剩下的三個組件,我們首先利用ConceptNet的HasProperty和COMET分別獲得每個組件相關屬性。接著,通過統計頻次,獲得每個組件在Wikipedia和BookCorpus中共現次數最多的副詞/形容詞,選取共現頻次排名前十的修飾詞(并且頻次大于1)作為候選選項。
通過以上策略,得到干擾選項候選集。
篩選干擾選項。我們利用句子的相似度,進一步從干擾選項候選集中獲得最具有挑戰性的干擾選項。整體流程如圖4。給定原句以及將正確屬性替換為的干擾選項的新句子,我們利用RoBERTaLARGE提取兩類特征,從而衡量二者的相似度。
一個是上下文特征(Context Embedding),由[CLS]的嵌入向量表示;
一個是單詞特征(Word Embedding),由正確選項或干擾選項的嵌入向量表示。
最后,拼接兩個特征,利用余弦相似度(consinesimilarity)衡量正確答案和干擾選項之間在給定上下文中的關聯性。最終,選取關聯性最高的三個干擾選項與正確答案組成最終選項。
人工確認選項。為了確保干擾選項為“錯誤(true-negative)”的,由三個標注者對干擾選項進行清洗。
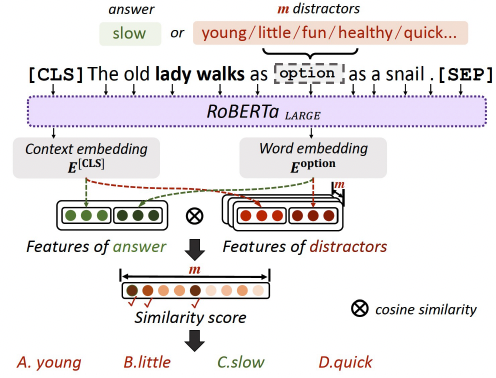
圖4:篩選最具有挑戰性的干擾選項的示意圖。
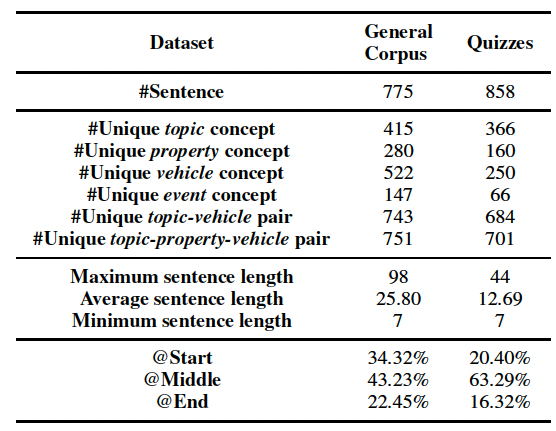
數據集統計指標
最終,我們從通用語料文本、人工構造題目兩個數據源構建明喻屬性探測數據集,規模為1,633個題目,涵蓋七個類別。題目示例如表1。
表1:明喻屬性探測數據集中各類題目的示例和占比。其中,“__”標示的選項是正確答案。每句中的斜體詞分別代表本體、遮蓋后的屬性和喻體。

數據集統計指標如表2。整體而言,Quizzes數據集中的明喻更常見,GeneralCorpus數據集中的明喻上下文更豐富。
表2:明喻屬性探測數據集統計指標。
03
有監督微調
除了評估預訓練語言模型在零樣本場景下直接表現的預測明喻屬性能力,我們利用遮蓋屬性后的Masked Language Modeling (MLM)訓練目標微調模型,探索微調是否能提升模型理解明喻的能力。我們利用來自StandardizedProject Gutenberg Corpus(SPGC)語料庫4510條(Noun... as ADJ as ... NOUN)的句子作為微調數據。
主要實驗結果
我們對比了模型在零樣本、微調后的結果,并與前人工作、人類表現進行對比。實驗結果如表3。
表3:各模型在明喻屬性探測任務中的準確率。
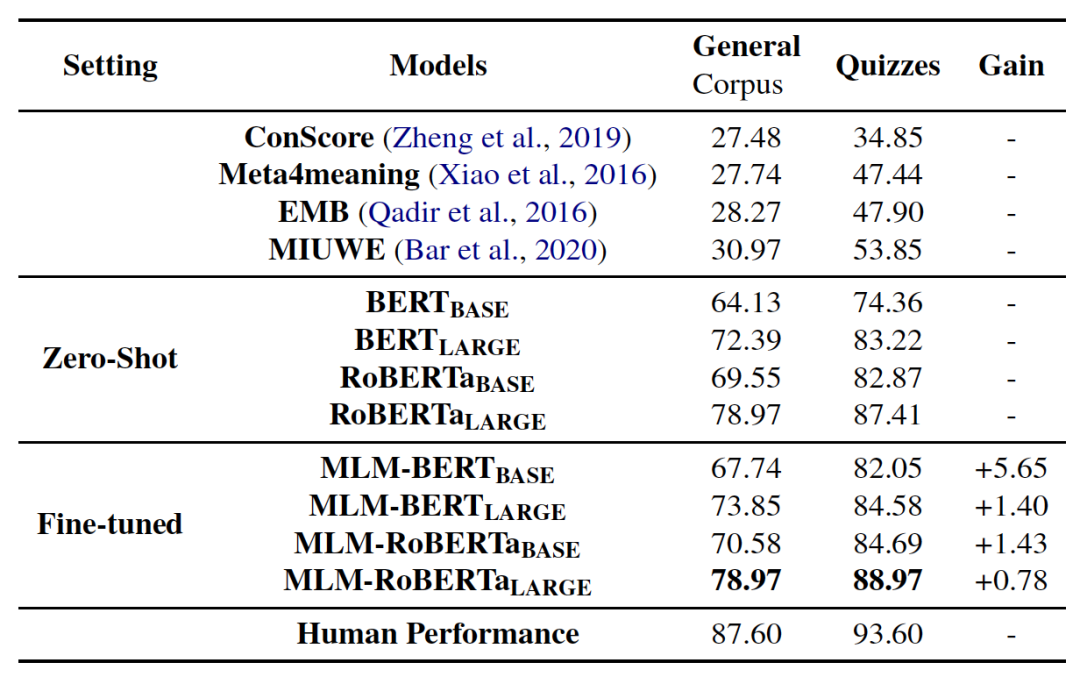
我們觀察到:
模型在預訓練階段存儲的知識可以幫助推斷明喻屬性;
利用MLM目標微調可以進一步提升模型預測明喻屬性的能力;
微調后的模型仍然不及人類的表現。
總體而言,模型在Quizzes數據集上的表現好于在GeneralCorpus數據集上的表現效果,更豐富的上下文會增加推斷明喻屬性的難度。同時,RoBERTa的表現持續好于BERT,證明更大規模的預訓練語料可以讓模型建模更多的明喻文本。
我們還對明喻各個組件對解釋明喻的貢獻程度進行探究,從而進一步揭示模型解釋明喻的機制。我們分別將明喻組件(本體、喻體、比較詞)替換為[UNK]符號,將謂詞替換為be動詞從而在抹除語義的同時不影響語法。我們同時隨機替換任一符號為[UNK]作為對照。實驗結果如表4。
表4:未經微調的預訓練語言模型在分別遮蓋各組件的情況下預測明喻屬性的結果。
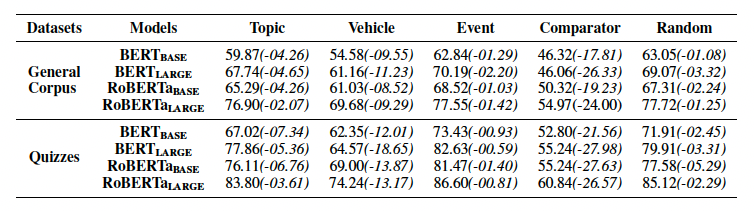
我們觀察到:
喻體、本體和比較詞較上下文能提供更關鍵的信息;
喻體能提供最豐富的語義信息,本體次之。
因此,我們認為有效利用喻體和本體的信息可以進一步提高模型的表現效果。
增強PLMs中的明喻知識
01
設計目標函數進行知識增強
根據實驗分析,我們已知本體和喻體是推測明喻屬性最重要的兩個組件。因此,由知識表示相關方法(Knowledge Embedding, KE)啟發,我們認為屬性(property)可以看作本體(topic)和喻體(vehicle)的關系。受事實三元組的啟發,我們將明喻看作三元組(本體topic,屬性property,喻體vehicle)。如圖5所示,在表示空間中,將屬性看作從本體到喻體的平移向量。用知識表示方法的打分函數對屬性予以評估和約束。
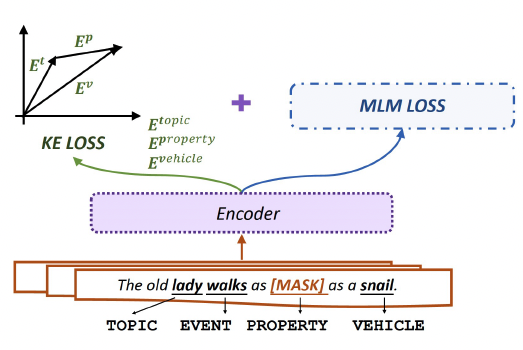
圖5:我們設計的目標函數示意圖
受經典的知識表示方法TransE啟發,我們利用均方誤差(MeanSquare Error, MSE)損失函數作為我們的知識表示損失函數(KE Loss)。
LKE= MSE(Et+ Ep, Ev)
其中,Et,Ep, Ev為本體、屬性、喻體由語言模型編碼的表示向量。我們也嘗試了改進后的知識表示方法(例如TransH,TransD),我們將結果展示在附錄中。
最終,我們的損失函數由MLMLoss和KE Loss共同組成:
LOurs =αLKE + LMLM
其中,α是平衡兩個目標函數的超參數。
02
實驗結果
我們分別基于MLM目標函數以及我們設計的目標函數進行微調,對比模型在明喻屬性探測任務上的表現效果。實驗結果如表5。
表5:利用MLM以及我們設計的目標函數在明喻屬性探測任務上的準確率。
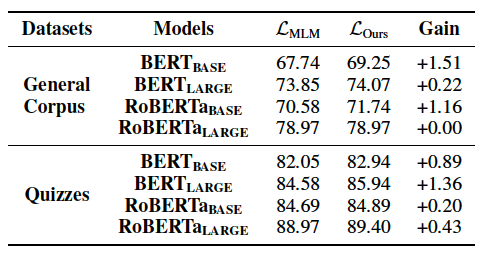
我們觀察到我們設計的目標函數可以提高模型推測共同屬性的能力,在明喻屬性探測任務上驗證了我們設計的目標函數的有效性。
研究表明,明喻往往帶有情感極性。為了進一步揭示改進后目標函數的應用潛力,我們在情感分析下游任務上進行實驗。我們選取Amazon評論情感分析數據集進行二分類任務,訓練過程中僅更新MLP層的參數,預訓練語言模型的參數保持不變。預訓練語言模型的參數來自于明喻屬性探測任務中的三個場景:零樣本(Original)、基于MLM目標函數微調后(LMLM)、基于知識增強后的模板函數微調后(LOurs)。實驗結果如表6。
表6:三個場景下的預訓練語言模型在情感分析下游任務上的準確率。
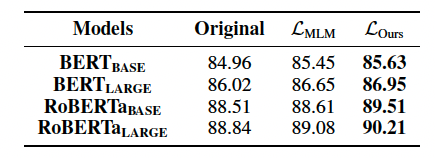
我們觀察到,增強預訓練語言模型推斷明喻屬性的能力可以提升模型分析文本情感極性的能力。同時在下游任務上也驗證了我們設計的目標函數的有效性。并且,我們在論文中也通過實驗分析了目標函數帶來表現提升的原因。
總結
我們是第一篇通過設計明喻屬性探測任務研究預訓練語言模型解釋明喻能力的文章。基于兩個數據來源構建了兩個明喻屬性探測數據集,并進行了一系列實驗。我們證明了預訓練語言模型在預訓練階段已經掌握一定推斷明喻屬性的能力,同時該能力可以進一步在精調階段提升,但是仍然與人的表現有所差距。特別地,我們提出的目標函數將明喻知識注入模型,進一步縮短了這一差距。我們的目標函數在明喻屬性探測任務以及情感分析下游任務上都表現出有效性。在未來,我們將考慮探索如何讓機器解釋更復雜的修辭手法,例如隱喻和類比。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3499瀏覽量
50072 -
語言模型
+關注
關注
0文章
560瀏覽量
10695 -
數據集
+關注
關注
4文章
1223瀏覽量
25301
原文標題:ACL'22丨預訓練語言模型能否像人一樣解釋明喻
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
CoT 數據集如何讓大模型學會一步一步思考?

基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型

Stm32CubeIDE能像Keil一樣指定不同文件下的代碼編譯到不同的FLASH地址嗎?
小白學大模型:訓練大語言模型的深度指南








 工商網監
工商網監
評論