 什么是嵌套實體識別
什么是嵌套實體識別
嵌套命名實體識別是命名實體識別中的一個頗具挑戰的子問題。我們在《實體識別LEAR論文閱讀筆記》與《實體識別BERT-MRC論文閱讀筆記》中已經介紹過針對這個問題的兩種方法。今天讓我們通過本文來看看在嵌套實體識別上哪一個方法更勝一籌。
1. 嵌套實體識別
1.1 什么是嵌套實體識別
嵌套實體識別是命名實體識別中一個子問題。那么什么才是嵌套實體呢?我們看下面這個例子:
“北京天安門”是地點實體;
“北京天安門”中“北京”也是地點實體;兩者存在嵌套關系。
1.2 嵌套實體識別方法
CRF等傳統序列標注方法無法應用于嵌套實體識別。現階段,業界比較流行的是構建實體矩陣,即用一個矩陣 來代表語料中的所有實體及其類型。
其中任一元素 表示類為 ,起點為 ,結尾為 的實體。比如在下圖所示實體矩陣中,就有兩個Location類的實體:北京、北京天安門。
通過這樣的標注方式我們可以對任何嵌套實體進行標注,從而解決訓練和解碼的問題。
在本文中,我們將對比目前接觸到的部分實體矩陣的構建方法在 CMeEE 數據集(醫學NER,有一定比例的嵌套實體)上的表現。
2. 實體矩陣構建框架
2.1 變量與符號約定
為了方便后續對比說明,這里我們先定義幾個統一的變量與符號。
首先,上文中 表示類為 ,起點為 ,結尾為 的實體。
在本實驗中,我們均使用 bert-base-chinese 作為 編碼器。假設 表示最后一層隱藏層中第 個 token 的 embedding,那么 和 分別表示經過編碼器之后實體 start 和 end token 的embedding。
我們有公式 ,其中 就表示我們所需要對比的實體矩陣構建頭(姑且這么稱呼)。
2.2 相關配置
在對比實驗中,除了不同實體矩陣構建頭對應的batch_size,learning_rate不同,所使用的編碼器、損失函數、評估方式以及訓練輪次均保持一致。
2.3 對比方法
本文選取了四種實體矩陣構建方法進行比較,分別是:
GlobalPointer;
TPLinker(Muti-head selection);
Tencent Muti-head;
Deep Biaffine(雙仿射)。
3. 代碼實現
3.1 GlobalPointer
GlobalPointer 出自蘇劍林的博客GlobalPointer:用統一的方式處理嵌套和非嵌套NER[1]。
Global Pointer 的核心計算公式為:
其中 ,。
GlobalPointer 的核心思想類似 attention的打分機制,將多個實體類型的識別視為 Muti-head機制,將每一個head視為一種實體類型識別任務,最后利用attention的score(QK)作為最后的打分。
為考慮Start和end之間距離的關鍵信息,作者在此基礎上引入了旋轉式位置編碼(RoPE),在其文中顯示引入位置信息能給結果帶來極大提升,符合預期先驗。
classGlobalPointer(Module): """全局指針模塊 將序列的每個(start,end)作為整體來進行判斷 """ def__init__(self,heads,head_size,hidden_size,RoPE=True): super(GlobalPointer,self).__init__() self.heads=heads self.head_size=head_size self.RoPE=RoPE self.dense=nn.Linear(hidden_size,self.head_size*self.heads*2) defforward(self,inputs,mask=None): inputs=self.dense(inputs) inputs=torch.split(inputs,self.head_size*2,dim=-1) inputs=torch.stack(inputs,dim=-2) qw,kw=inputs[...,:self.head_size],inputs[...,self.head_size:] #RoPE編碼 ifself.RoPE: pos=SinusoidalPositionEmbedding(self.head_size,'zero')(inputs) cos_pos=pos[...,None,1::2].repeat(1,1,1,2) sin_pos=pos[...,None,::2].repeat(1,1,1,2) qw2=torch.stack([-qw[...,1::2],qw[...,::2]],4) qw2=torch.reshape(qw2,qw.shape) qw=qw*cos_pos+qw2*sin_pos kw2=torch.stack([-kw[...,1::2],kw[...,::2]],4) kw2=torch.reshape(kw2,kw.shape) kw=kw*cos_pos+kw2*sin_pos #計算內積 logits=torch.einsum('bmhd,bnhd->bhmn',qw,kw) #排除padding,排除下三角 logits=add_mask_tril(logits,mask) returnlogits/self.head_size**0.5
3.2 TPLinker
TPLinker 來自論文《TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking》[2]。
TPLinker 原本是為解決實體關系抽取設計的方法,原型為《Joint entity recognition and relation extraction as a multi-head selection problem》[3]論文中的 Muti-head selection機制。此處選取其中用于識別實體部分的機制,作為對比方法。
TPLinker中相應的計算公式如下:
,
其中
與GlobalPointer不同的是,GlobalPointer 是乘性的,而 Muti-head是加性的。這兩種機制,誰的效果更好,我們無法僅通過理論進行分析,因此需要做相應的對比實驗,從結果進行倒推。但是在實際實現的過程中,筆者發現加性比乘性占用更多的內存,但是與GlobalPointer中不同的是,加性仍然能實現快速并行,需要在計算設計上加入一些技巧。
classMutiHeadSelection(Module): def__init__(self,hidden_size,c_size,abPosition=False,rePosition=False,maxlen=None,max_relative=None): super(MutiHeadSelection,self).__init__() self.hidden_size=hidden_size self.c_size=c_size self.abPosition=abPosition self.rePosition=rePosition self.Wh=nn.Linear(hidden_size*2,self.hidden_size) self.Wo=nn.Linear(self.hidden_size,self.c_size) ifself.rePosition: self.relative_positions_encoding=relative_position_encoding(max_length=maxlen, depth=2*hidden_size,max_relative_position=max_relative) defforward(self,inputs,mask=None): input_length=inputs.shape[1] batch_size=inputs.shape[0] ifself.abPosition: #由于為加性拼接,我們無法使用RoPE,因此這里直接使用絕對位置編碼 inputs=SinusoidalPositionEmbedding(self.hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1],dim=-1) #與TPLinker原論文中不同的是,通過重復+拼接的方法構建的矩陣能滿足并行計算的要求。 ifself.rePosition: #如果使用相對位置編碼,我們則直接在矩陣上實現相加 relations_keys=self.relative_positions_encoding[:input_length,:input_length,:].to(inputs.device) concat_x+=relations_keys hij=torch.tanh(self.Wh(concat_x)) logits=self.Wo(hij) logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
3.3 Tencent Muti-head
《EMPIRICAL ANALYSIS OF UNLABELED ENTITY PROBLEM IN NAMED ENTITY RECOGNITION》[4] 提出了一種基于片段標注解決實體數據標注缺失的訓練方法,并在部分數據集上達到了SOTA。關注其實體矩陣構建模塊,相當于Muti-head的升級版,因此我把它叫做Tencent Muti-head。
Tencent Muti-head的計算公式如下:
其中
與TPLinker相比,Tencent Muti-head在加性的基礎上加入了更多信息交互元素,比如 (作差與點乘),但同時也提高了內存的占用量。
classTxMutihead(Module): def__init__(self,hidden_size,c_size,abPosition=False,rePosition=False,maxlen=None,max_relative=None): super(TxMutihead,self).__init__() self.hidden_size=hidden_size self.c_size=c_size self.abPosition=abPosition self.rePosition=rePosition self.Wh=nn.Linear(hidden_size*4,self.hidden_size) self.Wo=nn.Linear(self.hidden_size,self.c_size) ifself.rePosition: self.relative_positions_encoding=relative_position_encoding(max_length=maxlen, depth=4*hidden_size,max_relative_position=max_relative) defforward(self,inputs,mask=None): input_length=inputs.shape[1] batch_size=inputs.shape[0] ifself.abPosition: #由于為加性拼接,我們無法使用RoPE,因此這里直接使用絕對位置編碼 inputs=SinusoidalPositionEmbedding(self.hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1,x2-x1,x2.mul(x1)],dim=-1) ifself.rePosition: relations_keys=self.relative_positions_encoding[:input_length,:input_length,:].to(inputs.device) concat_x+=relations_keys hij=torch.tanh(self.Wh(concat_x)) logits=self.Wo(hij) logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
3.4 Deep Biaffine
此處使用的雙仿射結構出自《Named Entity Recognition as Dependency Parsing》[5]。原文用于識別實體依存關系,因此也可以直接用于實體命名識別。
Deep Biaffine的計算公式如下:
簡單來說雙仿射分別 為頭 為尾的實體類別后驗概率建模 + 對 或 為尾的實體類別的后驗概率分別建模 + 對實體類別 的先驗概率建模。
不難看出Deep Biaffine是加性與乘性的結合。在筆者復現的關系抽取任務中,雙仿射確實帶來的一定提升,但這種建模思路在實體識別中是否有效還有待驗證。
classBiaffine(Module): def__init__(self,in_size,out_size,Position=False): super(Biaffine,self).__init__() self.out_size=out_size self.weight1=Parameter(torch.Tensor(in_size,out_size,in_size)) self.weight2=Parameter(torch.Tensor(2*in_size+1,out_size)) self.Position=Position self.reset_parameters() defreset_parameters(self): torch.nn.init.kaiming_uniform_(self.weight1,a=math.sqrt(5)) torch.nn.init.kaiming_uniform_(self.weight2,a=math.sqrt(5)) defforward(self,inputs,mask=None): input_length=inputs.shape[1] hidden_size=inputs.shape[-1] ifself.Position: #引入絕對位置編碼,在矩陣乘法時可以轉化為相對位置信息 inputs=SinusoidalPositionEmbedding(hidden_size,'add')(inputs) x1=torch.unsqueeze(inputs,1) x2=torch.unsqueeze(inputs,2) x1=x1.repeat(1,input_length,1,1) x2=x2.repeat(1,1,input_length,1) concat_x=torch.cat([x2,x1],dim=-1) concat_x=torch.cat([concat_x,torch.ones_like(concat_x[...,:1])],dim=-1) #bxi,oij,byj->boxy logits_1=torch.einsum('bxi,ioj,byj->bxyo',inputs,self.weight1,inputs) logits_2=torch.einsum('bijy,yo->bijo',concat_x,self.weight2) logits=logits_1+logits_2 logits=logits.permute(0,3,1,2) logits=add_mask_tril(logits,mask) returnlogits
4. 實驗結果
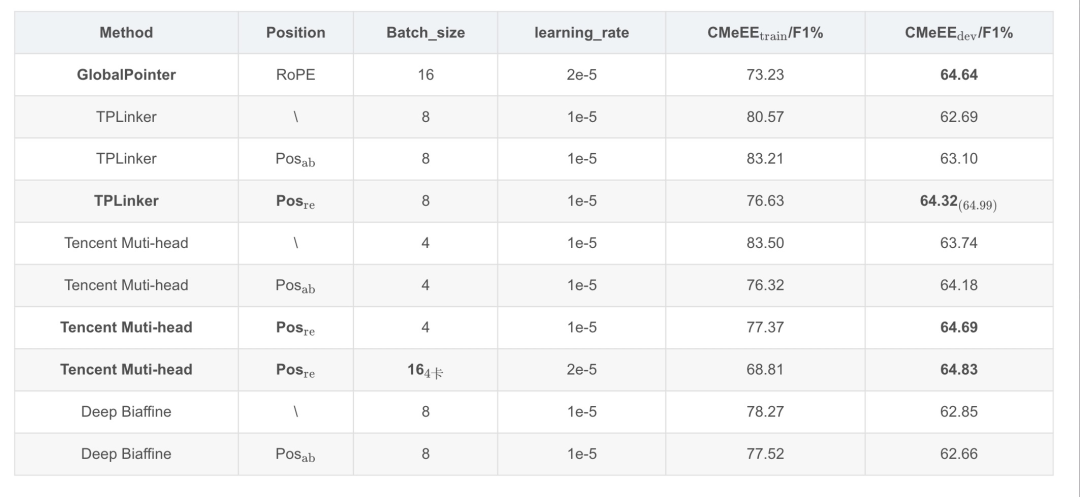
實驗所用的GPU為: P40 24G (x1)。為了把各方法的內存占用情況考慮在內,本次對比實驗全都在一張P40 24G的GPU上進行,并把Batch_size開到最大:
僅GlobalPointer可達到16;
Tencent Muti-head batch_size只能達到4。
Tencent Muti-head因為需要構建超大矩陣,所以占用內存較大,batch_size最大只能到4。從中,我們可以看出GlobalPointer的性能優勢。
需要注意的是,我們這里只比較了各方法在訓練過程中在驗證集上的最好表現:
總結
GlobalPointer作為乘性方法,在空間內存占用上明顯優于其他方法,并且訓練速度較快,能達到一個具有競爭力的效果。
TPLinker 和 Tencent Muti-head作為加性方法,在優化過程中均表現出 相對位置編碼 > 絕對位置編碼 > 不加入位置編碼 的特征。這意味著在通過構建實體矩陣進行實體命名識別時位置信息具有絕對重要的優勢,且直接引入相對位置信息較優。
在絕對位置編碼和不加入位置編碼的測試中Tencent Muti-head的效果明顯優于TPLinker而兩者均差于GlobalPointer,但在引入相對位置信息后Tencent Muti-head略微超越了GlobalPointer,而TPLinker提點顯著,作為Tencent Muti-head的原型在最高得分上甚至可能有更好的表現。
Biaffine雙仿射表現不佳,意味著這種建模思路不適合用于實體命名識別。
在計算資源有限的情況下GlobalPointer是最優的baseline選擇,如果擁有足夠的計算資源且對訓練、推理時間的要求較為寬松,嘗試使用TPLinker/Tencent Muti-head + 相對位置編碼或許能取得更好的效果。
-
編碼器
+關注
關注
45文章
3775瀏覽量
137190 -
內存
+關注
關注
8文章
3109瀏覽量
75000 -
解碼
+關注
關注
0文章
185瀏覽量
27764
原文標題:總結
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
HanLP分詞命名實體提取詳解
基于結構化感知機的詞性標注與命名實體識別框架
HanLP-命名實體識別總結
基于深度信念網絡的實體識別算法

一種中文電子病歷醫療實體關系識別方法

命名實體識別的遷移學習相關研究分析

基于字語言模型的中文命名實體識別系統






 工商網監
工商網監
評論