") PC處理器的chiplet結構設計未來會向怎樣的方向發(fā)展
PC處理器的chiplet結構設計未來會向怎樣的方向發(fā)展

似乎PC處理器這兩年競爭的焦點,除了性能、能效這些常規(guī)指數(shù),還包括期貨水平......Intel和AMD現(xiàn)在都熱衷于輪番預告未來產品多么彪悍。尤其是Intel,12代酷睿剛發(fā)幾天,13代酷睿和14代酷睿的消息就不絕于耳了。
最近的Technology Tour 2022上,Intel又分享了有關13代酷睿(Raptor Lake)CPU最高頻率可上達6GHz,以及超頻記錄達8GHz的消息——這應該是明擺著針對即將上市AMD Ryzen 7000的5.7GHz吧。這也算是市場“信息戰(zhàn)”了。
不過畢竟過不了多久13代酷睿就要發(fā)布了,真正“展望”作品應該是14代酷睿(Meteor Lake)。今年年中的Intel Vision大會上,Intel就展示了14代酷睿處理器的真容:讓人們知道了其chiplet方案怎么做的,以及Intel 4工藝的正式提槍上馬。
這些未來產品的消息放出,更多的應該還是為了穩(wěn)住市場和投資者,尤其是Intel著眼于戰(zhàn)未來技術的現(xiàn)狀。上個月的Hot Chips 34上,Intel詳述了Meteor Lake的部分細節(jié)信息:尤其是這代芯片采用的chiplet方案。借著14代酷睿的chiplet方案,我們也有機會了解應用于PC處理器的chiplet結構設計未來會向怎樣的方向發(fā)展。
AMD、蘋果已經(jīng)在用chiplet
PC領域chiplet方案的近代應用并不新鮮,為普羅大眾所知的是蘋果M1 Ultra——用在了Mac Studio上。這顆芯片差不多是把兩顆M1 Max加在一起,屬于比較典型的基于chiplet的芯片。所謂的chiplet結構,也就是把幾顆die封裝到一起構成一顆芯片的方案。這種芯片的每一片die,就是一個chiplet。Chiplet的本質也就是一種多die解決方案。
Chiplet出現(xiàn)的原因莫過于(1)單die越來越大,大到光刻機即將無法處理(超過reticle limit限制);(2)尺寸縮減的多die有利于提升產品良率,縮減成本;(3)應用端的算力需求仍在不斷增加,chiplet式的設計也有利于堆算力,在產品組合上也更為靈活。
AMD則是在PC市場上更早應用chiplet方案的先鋒,比如在Ryzen 3000系列CPU上,每4個CPU核心組成一個CCX,兩個CCX構成一個CCD——也就是一片die/chiplet。多個CCD,外加I/O die,就構成了完整的芯片。這算是近些年PC處理器核心數(shù)飆升的某一個原因,畢竟藉由增加CCD來增加處理器核心比以前容易多了。這年頭,16核處理器已經(jīng)不罕見了。
其實基于前文chiplet技術很不嚴謹?shù)亩x,當年的Intel奔騰D膠水雙核處理器(2005年)似乎也可以被叫做chiplet。嚴謹一點,如果我們說chiplet要求先進封裝(或至少不是PCB級別的電路連接),那么近代Intel在自家處理器上采用chiplet方案的處理器應該是Kaby Lake-G,8代酷睿產品中的某一個偏門系列,將AMD的iGPU(核顯)與Intel的CPU藉由2.5D先進封裝工藝,放到同一顆芯片上。
Meteor Lake的chiplet
不過像Kaby Lake-G這樣的產品,怎么說都只是試驗和先進封裝工藝的練手。Intel始終也沒有像AMD那樣,通過chiplet來堆CPU核心。似乎從直覺來看,隨著當代PC處理器核心數(shù)增多、I/O能力增強、核顯性能內卷,眼見著die size越來越大,還不得不給更多的算力,再不用chiplet是真的不行了。
此前14代酷睿的die shot公布時,我們也都知道了這代產品終于要開始用chiplet方案了。但很顯然,Meteor Lake基于chiplet的芯片架構與AMD仍然大相徑庭。
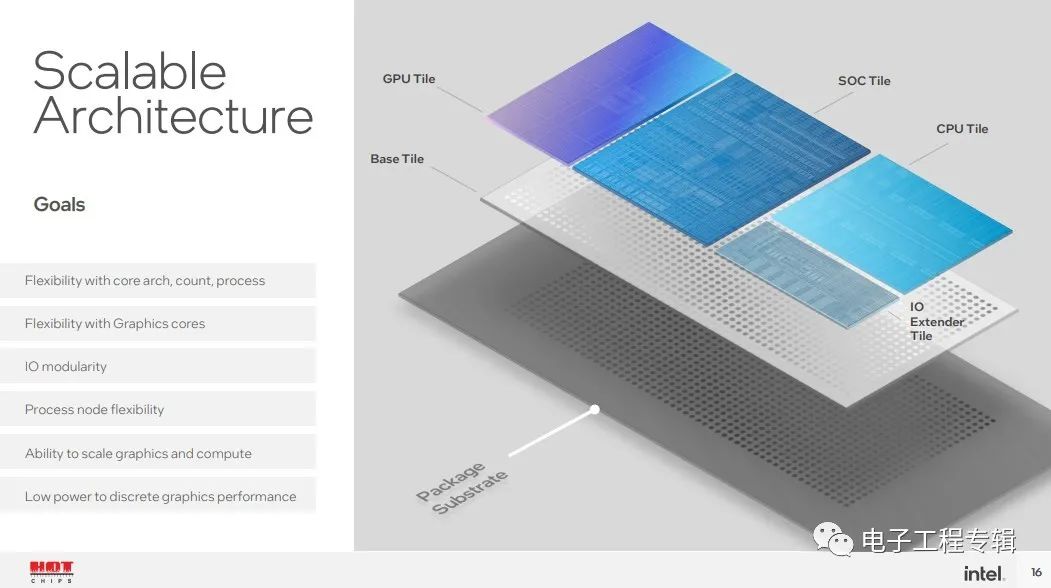
Meteor Lake總共4片die,Intel稱其為tile,分別是CPU Tile、SoC Tile、Graphics Tile和IOE Tile(IO extender)。
CPU Tile里面主要就是CPU核心與cache,而Graphics Tile自然就是核顯部分了,SoC Tile包含此前SA(System Agent)的絕大部分功能,IOE Tile則連接到SoC Tile。所有的tile都放到一片base die上。這種chiplet式的方案自然就極大提升了處理器產品面向不同市場的靈活性。
比如說要是很看重PCIe連接數(shù)量,那么SoC Tile可以做擴展;面向筆記本設備時,SoC Tile還可以加上圖像處理單元之類的部分;而CPU Tile則能夠根據(jù)場景需要來設計不同的核心數(shù)組合;GPU die則面向不同的圖形算力需求。
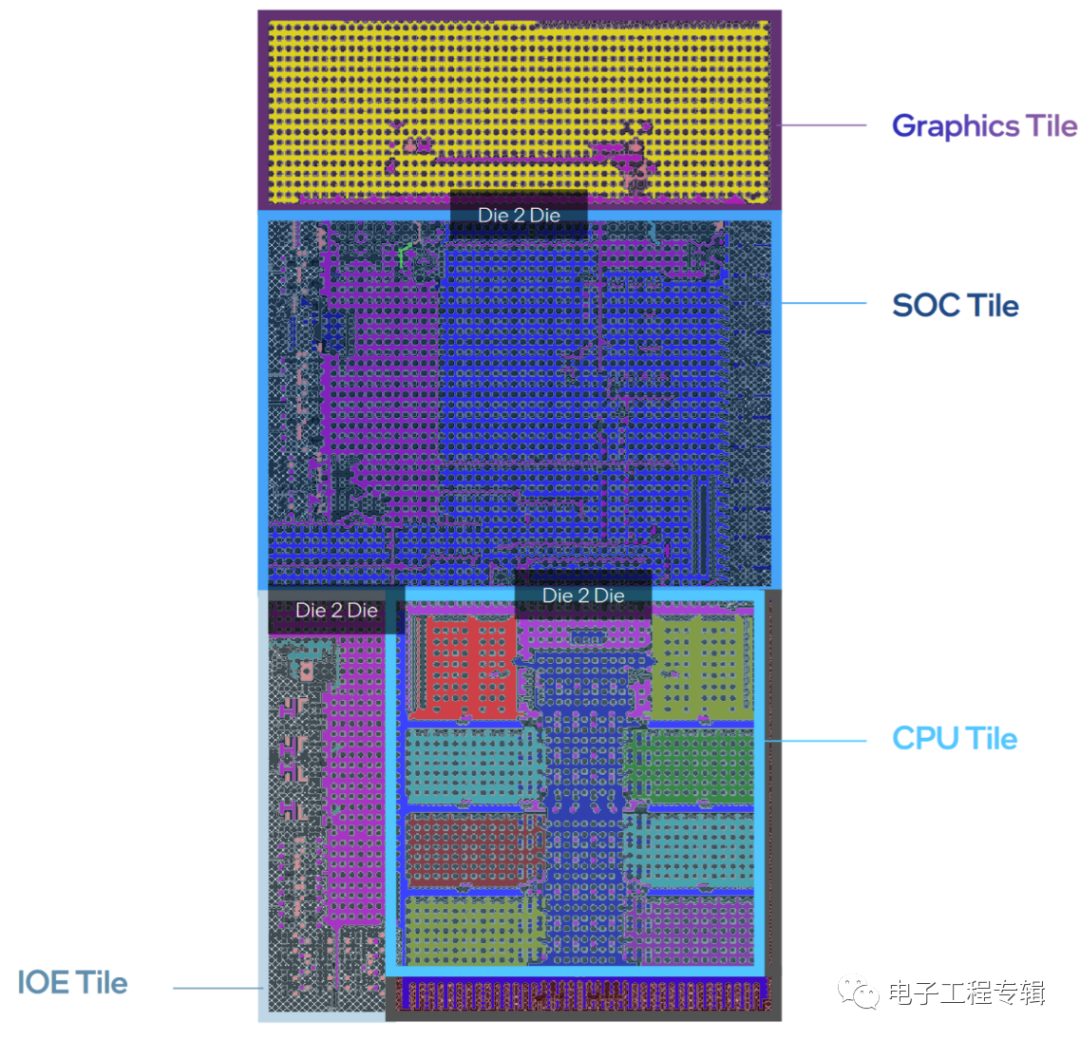
很容易發(fā)現(xiàn),Meteor Lake的chiplet“切分”方式,和AMD Ryzen的chiplet相當不一樣。可能很多人會認為,AMD的CCD + I/O die的設計更靈活,但AMD在移動平臺上受制于功耗仍然采用單die方案;而且從die間通信和封裝的角度來看,AMD所用的chiplet方案并不能算先進封裝——而是直接從PCB基板走線——這種方案成本更低,但對通信效率和功耗而言都不是什么好事。
前不久我們詳細探討過先進封裝技術,及主流的一些方案。Intel雖未詳談Meteor Lake封裝,但大致也不離文章里談到的主流技術。基于2.5D/3D封裝,則Meteor Lake的封裝成本自然就會高于AMD現(xiàn)階段的方案,更靠近蘋果M1 Ultra(雖然還是不同的)。從擴展靈活性的角度來看,如果CPU要增加更多核心,那么CPU Tile需要更大的die size,則base die的這種硅中介或硅橋也要跟著變大。
不過2.5D/3D先進封裝能夠獲得更高的IO密度、功耗也會更低。這對小尺寸封裝,以及電池驅動的功耗敏感型設備來說會很有價值。
Die間互聯(lián)與通信
AMD此前提到Zen架構的die-to-die Infinity Fabric鏈接功耗水平為2 pJ/bit(皮焦/比特);Zen 2的Infinity Fabric這一數(shù)值降低了大約27%。Chips and Cheese在近期的技術文章中提到,有理由認為AMD的die間傳輸功耗應該和Intel Haswell(4代酷睿)的OPIO(一般是片上處理器die和PCH die的連接)類似。

上面這張來自Intel的PPT也基本能闡明這一點。Intel將Meteor Lake的die-to-die link稱作FDI(Foveros Die Interconnect)。而FDI的die間通信功耗水平為0.2-0.3 pJ/bit。這張圖中的延遲數(shù)據(jù)比較模糊,只說是小于10ns。AMD那種相對簡單粗暴的連接方式,此前公布的延遲數(shù)據(jù)也是差不多的水平。
AMD說Zen 2架構的這種die間連接延遲為13個FCLK(Infinity Fabric)時鐘周期,即不到9ns;如果推升DDR內存頻率和FLCK的頻率,則Ryzen 3000系列處理器的13個FCLK周期可低至7.22ns。所以Intel這邊的延遲數(shù)據(jù)就顯得并不算多好。
另外表中的帶寬數(shù)據(jù)也不算明朗,2 GT/s(每秒20億次傳輸)沒有指明每次傳輸?shù)膶挾取hips and Cheese評論說,有可能帶寬也就是OPIO或IFOP(Infinity Fabric On Package)的水平。
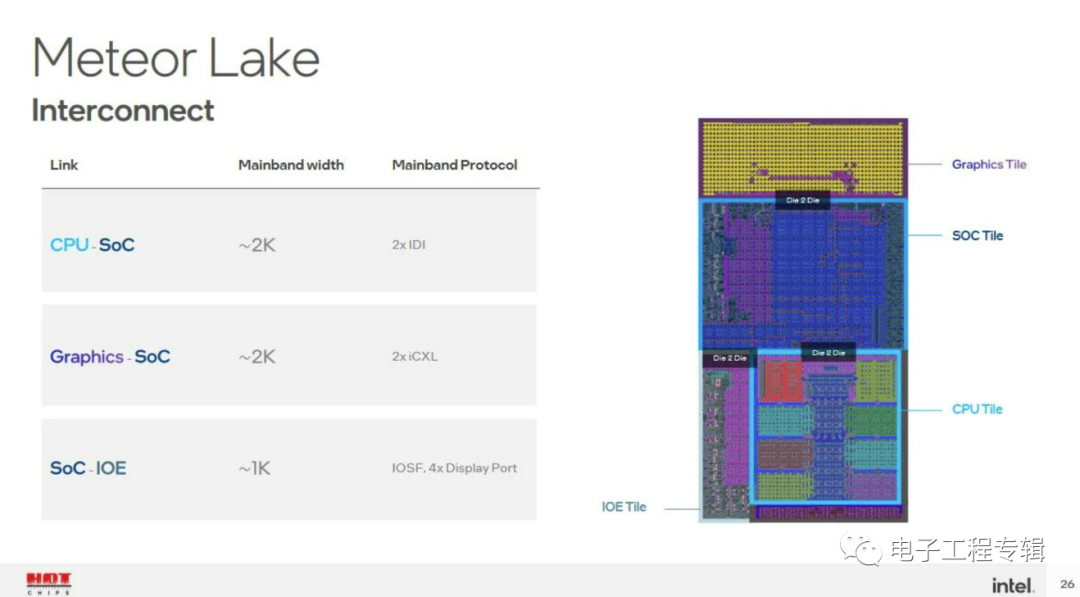
通信協(xié)議方面,Intel表示CPU與SoC Tile采用IDI(In-Die Interface)協(xié)議,Graphics Tile到SoC Tile則采用iCXL協(xié)議(對于現(xiàn)在很火的CXL的一個內部實施方案,和IDI應該有諸多相似之處),SoC與IOE Tile連接是通過IOSF(Integrated On-chip System Fabric)和DisplayPort——可見IOE Tile上估計是有PCIe控制器和DisplayPort PHY的。
這里的IDI,最早出現(xiàn)于Intel Nehalem架構(2008年,初代酷睿i5/i7),用于把CPU核心連接到uncore的Global Queue和L3;后續(xù)IDI就成為Intel處理器ring bus總線的主要協(xié)議了,當然后續(xù)有不斷更新。總的來說,IDI是一種處理mesh和ring總線通信的內部協(xié)議。
值得一提的是,此前Intel處理器的核顯也采用IDI協(xié)議與L3 cache連接。去年我們撰寫的《蘋果M1統(tǒng)一內存架構真的很厲害嗎?稀松平常的UMA(下)》一文曾經(jīng)提到過,酷睿處理器從Sandy Bridge(6代酷睿)開始就把核顯掛在環(huán)形總線上,LLC(也就是L3 cache)也與核顯共享(如下圖)。換句話說,核顯和CPU一樣都能用L3資源。
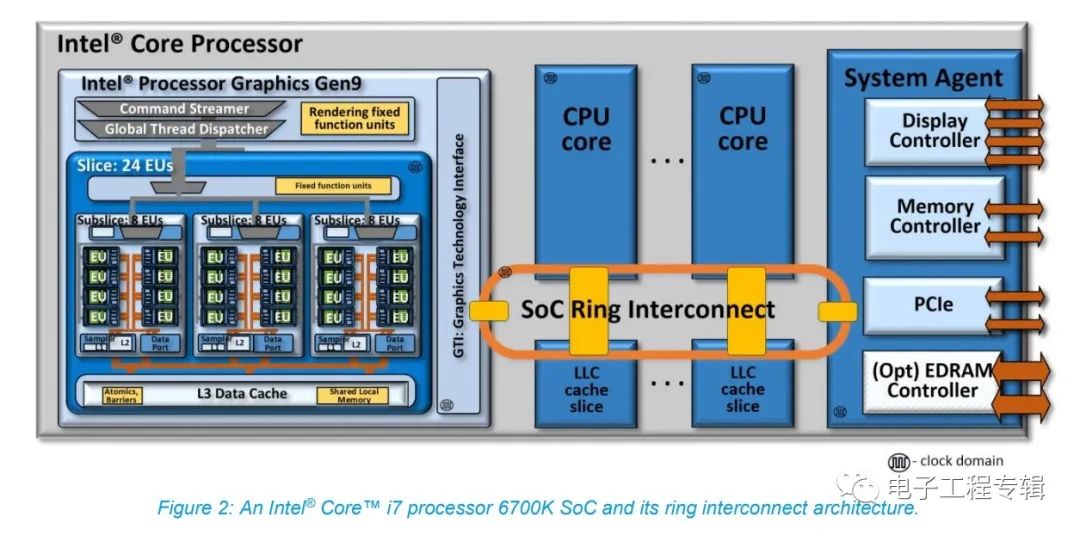
不過從Meteor Lake的die shot來看,Graphics Tile和CPU Tile離得比較遠,所以過去的這種設計應當也就不復存在了,也就是說核顯可能就不再共享L3 cache了。這么做對核顯效率會有影響嗎?Chips and Cheese評論說或許也未必,因為一方面總線上的stop變少,這利于降低延遲、提升數(shù)據(jù)傳輸?shù)哪苄?另外這可能也有機會讓ring頻率變高,達成CPU核心更高的L3性能;還有就是核顯和CPU隔開,便于將整個CPU Tile設定在低功耗狀態(tài),降低功耗。
Chips and Cheese對此還特別提到了一點,就是一般核顯的LLC命中率極低。比如Arm架構普遍會用到的SLC(System Level Cache)也為GPU服務,8MB SLC就只有28%的命中率。AMD的GPU Infinity Cache命中率也很低。Intel這邊的情況也沒好到哪里去。所以有沒有必要再共享L3,原本就很值得懷疑。
與此同時,Intel處理器現(xiàn)在的Xe核顯配備了更大的專用cache,相比AMD這邊的Vega和RDNA 2核顯都更大。若這種設計持續(xù),則Meteor Lake的核顯應該就有足夠的cache資源,不需要多依賴L3。那么當前的這種設計也就比較好理解了。

來源:Lecomptoir via Chips and Cheese
雖然單純從物理層面的die shot來觀察,我們普遍都覺得Meteor Lake即便用了chiplet的方案,耦合度依然比較高,但Chips and Cheese認為其靈活度相比AMD的方案更高,更為分散化(disaggregation)。而且FDI連接在達成與AMD IFOP相似性能的同時,功耗更低。
所以這種連接并不用于性能敏感路徑。SoC到IOE Tile鏈接處理DisplayPort和PCIe數(shù)據(jù);核顯內存訪問則主要由核顯的專用cache進行——核顯到SoC鏈接用于處理GPU的cache未命中請求;CPU的L3主要獲取內存訪問,即藉由CPU到SoC Tile。
Chips and Cheese認為SoC很可能在CPU Tile上有掛一個ring stop,跨die鏈接只留意發(fā)往SoC的IDI packets,而“熱”數(shù)據(jù)則僅在CPU Tile內部ring stop上傳遞。從die shot來看,在CPU Tile的效率核(E-core)ring stop和這片die的邊緣之間有這么一個部分,猜測“這個位于CPU Tile的部分會有不少發(fā)往SoC Tile請求的隊列和仲裁邏輯。”
明年電腦全面走向chiplet
Intel在Hot Chips上再次明確了14代酷睿Meteor Lake明年發(fā)布——上個月有傳言說臺積電N3工藝遭遇不確定性,可能對Meteor Lake的發(fā)布產生影響,不過最近的消息說Meteor Lake的Graphics Tile實際上用的是臺積電N5工藝。另外除了CPU Tile基于Intel 4工藝外,傳言IOE Tile和SoC Tile都基于臺積電N6工藝(還有個base die是基于Intel的22FFL工藝)。
無論面向臺式機還是筆記本的Meteor Lake處理器,預計都會采用這種chiplet方案。畢竟像Intel這種方案的特色就是面向不同場景的彈性化選擇。未來AMD也有概率會采用類似的方案,因為此前AMD就提到以后15-45W TDP的處理器也將應用chiplet結構,這對其現(xiàn)有IFOP而言在功耗上是個挑戰(zhàn)。
這算是個新的技術戰(zhàn)場,我們也很期待看到在PC處理器具備相當?shù)男阅芘c功耗彈性擴展空間以后,又會賦予PC設備怎樣的體驗提升。
審核編輯:劉清
-
SoC芯片
+關注
關注
1文章
644瀏覽量
35816 -
PC處理器
+關注
關注
0文章
12瀏覽量
2055 -
chiplet
+關注
關注
6文章
459瀏覽量
12994 -
RDNA
+關注
關注
0文章
22瀏覽量
2088
原文標題:電腦用上chiplet處理器以后,會有哪些變化?
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
印刷線路板元件布局及結構設計






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論