 聯合索引的最左匹配原則
聯合索引的最左匹配原則
大家在背 MySQL 八股文的時候,是不是經常看到這句話。
聯合索引的最左匹配原則會一直向右匹配直到遇到范圍查詢(>、<、between、like) 就會停止匹配。
我隨手在網上搜了下, 基本全部都是這個結論,似乎這個結論大家都耳濡目染了,應該大多數人都覺得這個結論是正確的吧。
我在昨晚折騰了幾個實驗,發現這個結論并不全對!去掉 「between 和 like 」這個結論就沒問題了。
經過實驗的證明,我得出的結論是這樣的:
聯合索引的最左匹配原則,在遇到范圍查詢(如 >、<)的時候,就會停止匹配,也就是范圍查詢的字段可以用到聯合索引,但是在范圍查詢字段后面的字段無法用到聯合索引。但是,對于 >=、<=、BETWEEN、like 前綴匹配這四種范圍查詢,并不會停止匹配。
接下來,我會用幾個實驗例子來說明這個結論。

B+Tree 索引
首先,先來認識下 B+Tree 索引。
MySQL 的 InnoDB 存儲引擎會為每一張數據庫表創建一個「聚簇索引」來保存表的數據,聚簇索引默認使用的是 B+Tree 索引。
為了讓大家理解 B+Tree 索引的存儲和查詢的過程,接下來我通過一個簡單例子,說明一下 B+Tree 索引在存儲數據中的具體實現。
假設有一張商品表,表里有這些數據:
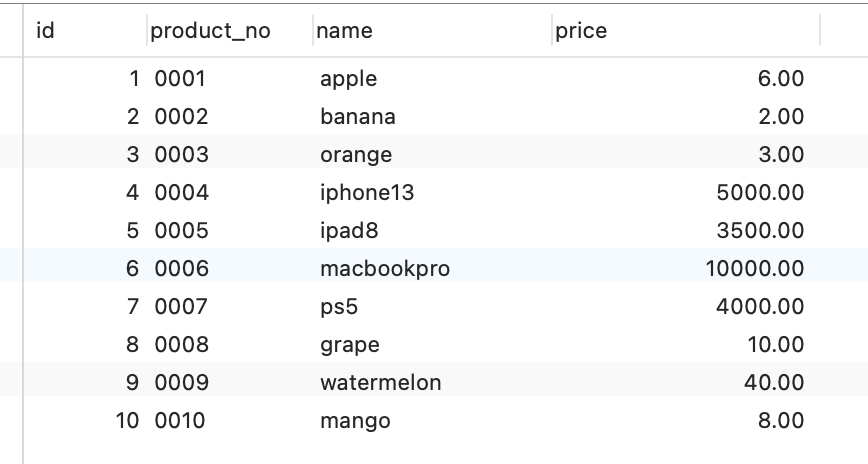
這些數據,存儲在 B+Tree 索引時是長什么樣子的?
B+Tree 是一種多叉樹,葉子節點才存放數據,非葉子節點只存放索引,而且每個節點里的數據是按主鍵值(id)順序存放的,每一層父節點的索引值都會出現在下層子節點的索引值中,因此在葉子節點中,包括了所有的索引值信息,并且每一個葉子節點都指向下一個葉子節點,形成一個鏈表,便于范圍查詢。
聚簇索引的 B+Tree 如圖所示:
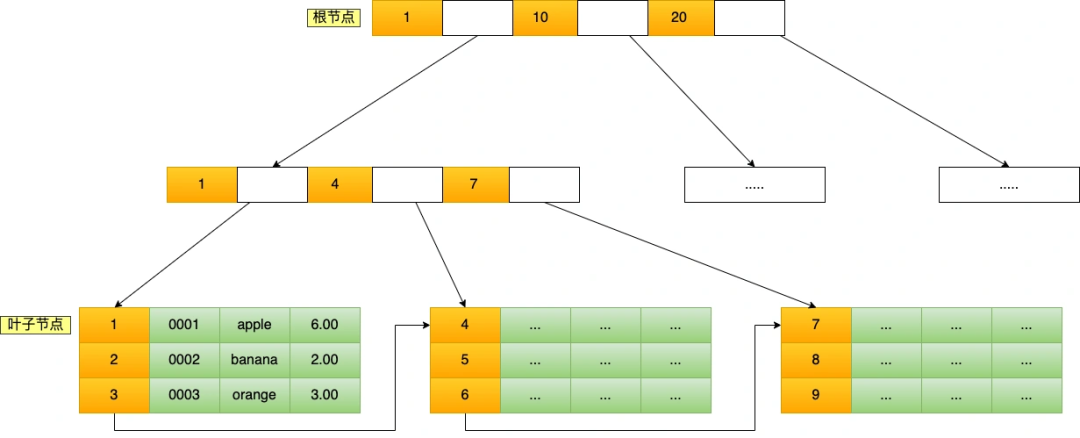
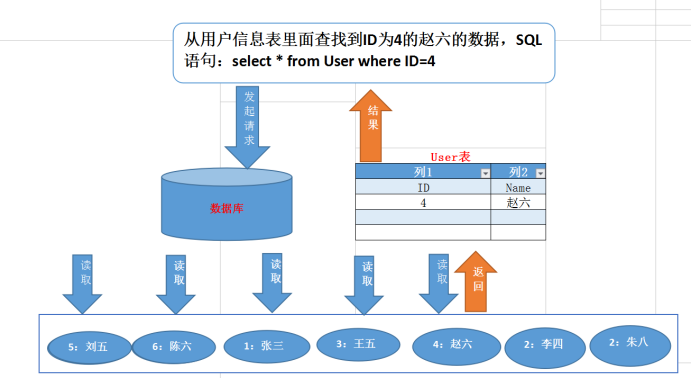
假設,執行了 select * from t_product where id = 5 查詢語句,該查詢語句的條件是找到 id(主鍵)為 5 的這條記錄。因為 B+Tree 是一個有序的數據結構,所以可以通過二分查找算法快速定位到這條記錄,這也就是我們常說的索引查詢,具體過程如下:
從根節點開始,將 5 與根節點的索引數據 (1,10,20) 比較,5 在 1 和 10 之間,根據二分查找算法,找到第二層的索引數據 (1,4,7);
在第二層的索引數據 (1,4,7)中進行查找,因為 5 在 4 和 7 之間,根據二分查找算法,找到第三層的索引數據(4,5,6);
在葉子節點的索引數據(4,5,6)中進行查找,然后我們找到了索引值為 5 的這條記錄。
聚簇索引只能用于主鍵字段的快速查詢,如果想實現「非主鍵字段」的快速查詢,我們就要針對「非主鍵字段」創建索引,這種索引稱作為「二級索引」。二級索引同樣基于 B+Tree 實現的,不過二級索引的葉子節點存放的是主鍵值,不是實際數據。
我這里將前面的商品表中的 product_no (商品編碼)字段設置為二級索引,那么二級索引的 B+Tree 如下圖,其中非葉子的索引值是 product_no(圖中橙色部分),葉子節點存儲的數據是主鍵值(圖中綠色部分)。
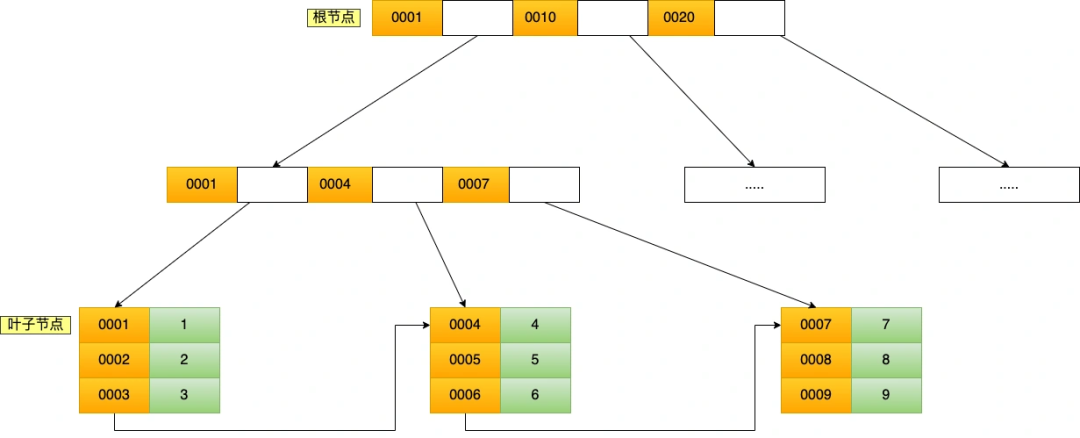 如果我用 product_no 二級索引查詢商品,如下查詢語句:
如果我用 product_no 二級索引查詢商品,如下查詢語句:
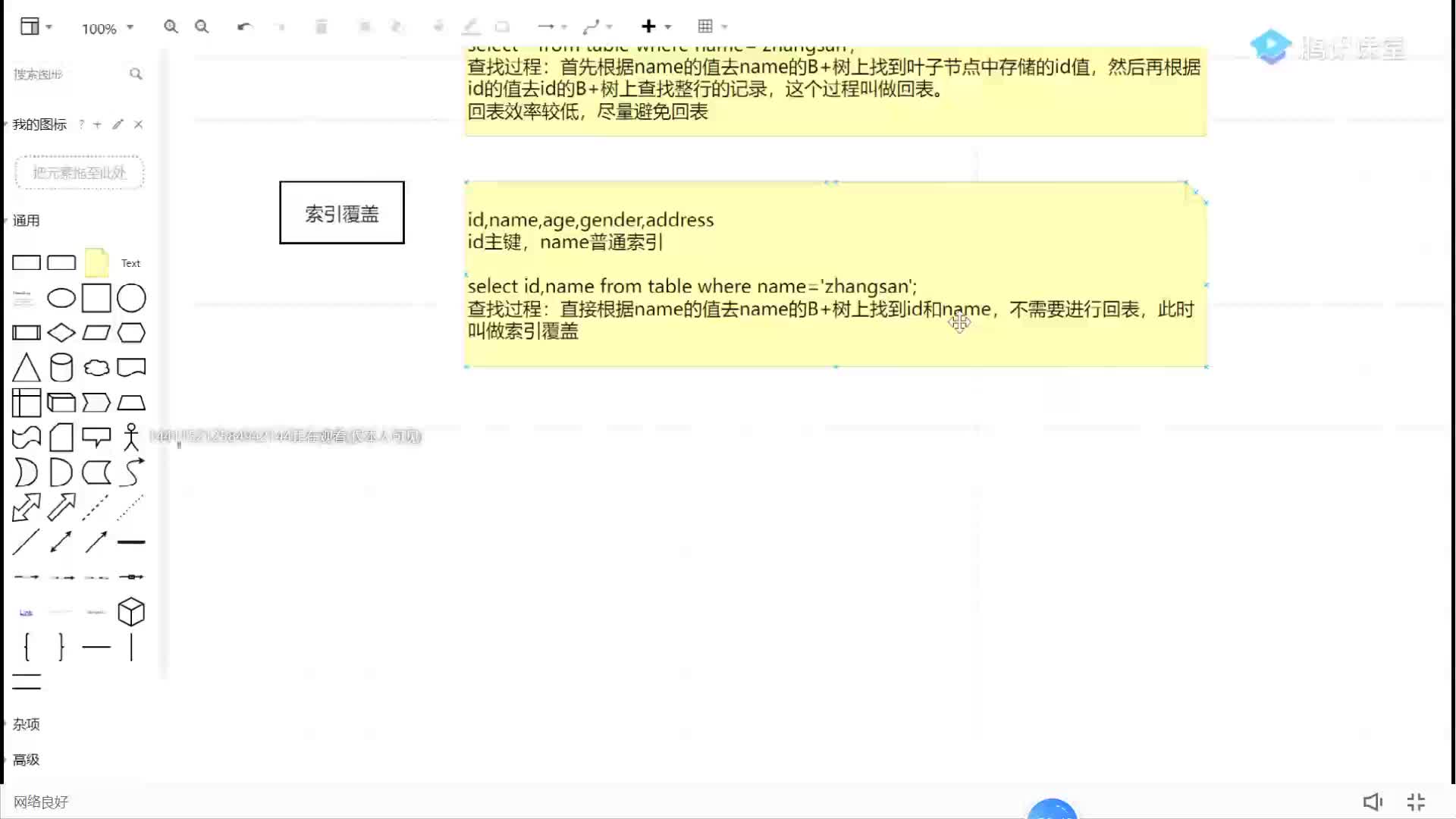
select*fromproductwhereproduct_no='0002';
會先在二級索引的 B+Tree 中快速查找到 product_no 為 0002 的二級索引記錄,然后獲取主鍵值,然后利用主鍵值在主鍵索引的 B+Tree 中快速查詢到對應的葉子節點,然后獲取完整的記錄。這個過程叫「回表」,也就是說要查兩個 B+Tree 才能查到數據。如下圖:
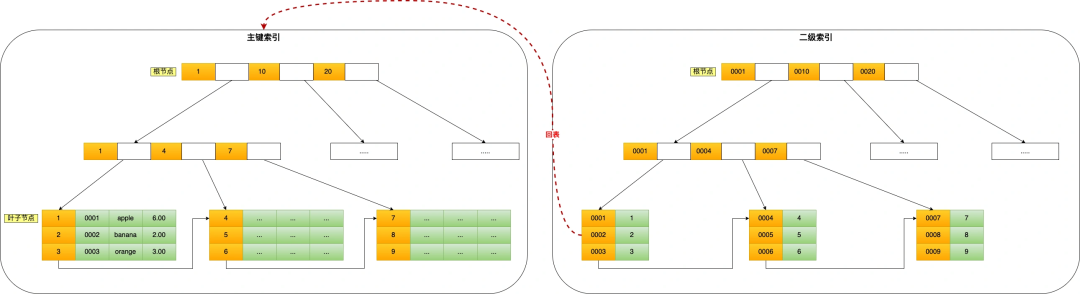
不過,當查詢的數據是能在二級索引的 B+Tree 的葉子節點里查詢到,這時就不用再查主鍵索引查,比如下面這條查詢語句:
selectidfromproductwhereproduct_no='0002';
這種在二級索引的 B+Tree 就能查詢到結果的過程就叫作「覆蓋索引」,也就是只需要查一個 B+Tree 就能找到數據。
什么是聯合索引?
前文我將 product_no 字段設置為了索引,這種二級索引只有一個字段。如果將多個字段組合成一個索引,那么這種二級索引就被稱為聯合索引。
比如,將商品表中的 product_no 和 name 字段組合成聯合索引`(product_no, name)``,創建聯合索引的方式如下:
CREATEINDEXindex_product_no_nameONproduct(product_no,name);
聯合索引 ``(product_no, name)` 的 B+Tree 示意圖如下:
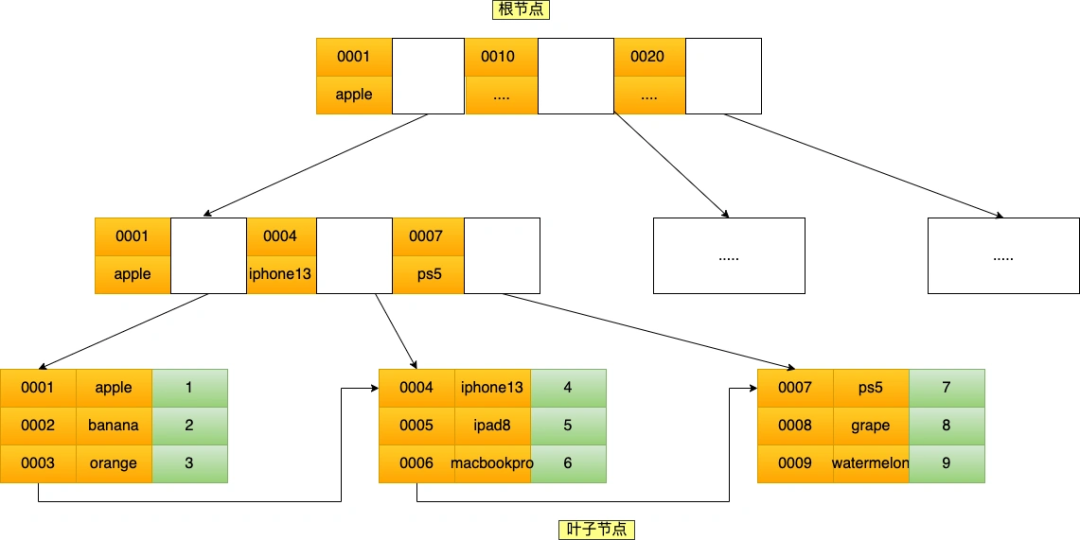
可以看到,聯合索引的非葉子節點用兩個字段的值作為 B+Tree 的索引值。
聯合索引的 B+Tree 是先按 product_no 進行排序,然后再 product_no 相同的情況再按 name 字段排序。記住這句話,很重要!
最左匹配原則
使用聯合索引時,存在最左匹配原則,也就是按照最左優先的方式進行索引的匹配。
在使用聯合索引進行查詢的時候,如果不遵循「最左匹配原則」,聯合索引會失效,這樣就無法利用到索引快速查詢的特性了。
比如,如果創建了一個 (a, b, c) 聯合索引,如果查詢條件是以下這幾種,就可以利用聯合索引:
where a=1;
where a=1 and b=2 and c=3;
where a=1 and b=2;
需要注意的是,因為有查詢優化器,所以 a 字段在 where 子句的順序并不重要。但是,如果查詢條件是以下這幾種,因為不符合最左匹配原則,所以就無法匹配上聯合索引,聯合索引就會失效:
where b=2;
where c=3;
where b=2 and c=3;
上面這些查詢條件之所以會失效,是因為(a, b, c) 聯合索引,是先按 a 排序,在 a 相同的情況再按 b 排序,在 b 相同的情況再按 c 排序。所以,b 和 c 是全局無序,局部相對有序的,這樣在沒有遵循最左匹配原則的情況下,是無法利用到索引的。
我這里舉聯合索引(a,b)的例子,該聯合索引的 B+ Tree 如下:
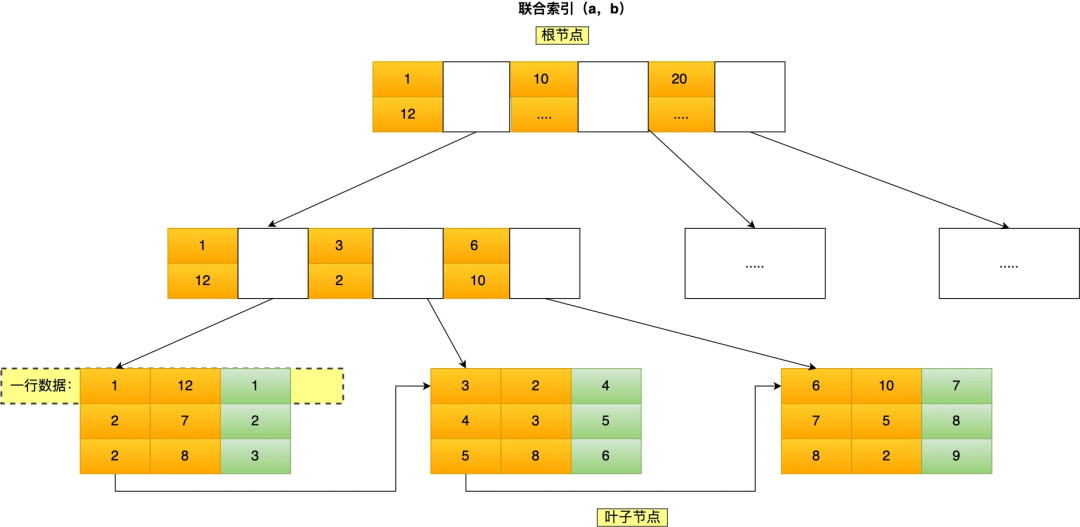
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是無序的(12,7,8,2,3,8,10,5,2)。因此,直接執行 where b = 2 這種查詢條件沒有辦法利用聯合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情況才,b 才是有序的,比如 a 等于 2 的時候,b 的值為(7,8),這時就是有序的,這個有序狀態是局部的,因此,執行 where a = 2 and b = 7 這種查詢條件時, a 和 b 字段能用到聯合索引的,也就是聯合索引生效了。
聯合索引范圍查詢
聯合索引有一些特殊情況,并不是查詢過程使用了聯合索引查詢,就代表聯合索引中的所有字段都用到了聯合索引進行索引查詢,也就是可能存在部分字段用到聯合索引的 B+Tree,部分字段沒有用到聯合索引的 B+Tree 的情況。
這種特殊情況就發生在范圍查詢。也就是文章開頭的那句話:聯合索引的最左匹配原則會一直向右匹配直到遇到「范圍查詢」就會停止匹配。也就是范圍查詢的字段可以用到聯合索引,但是范圍查詢字段的后面的字段無法用到聯合索引。
范圍查詢有很多種,那到底是哪些范圍查詢會導致聯合索引的最左匹配原則會停止匹配呢?
接下來,舉例幾個范圍查詢的例子,下面的實驗案例是基于 MySQL 8.0做的。
例子一
Q1: select * from t_table where a > 1 and b = 2,聯合索引(a, b)哪一個字段用到了聯合索引的 B+Tree?
由于聯合索引(二級索引)是先按照 a 字段的值排序的,所以符合 a > 1 條件的二級索引記錄肯定是相鄰的,于是在進行索引掃描的時候,可以定位到符合 a > 1 條件的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄不符合 a > 1 條件位置。所以 a 字段可以在聯合索引的 B+Tree 中進行索引查詢。
但是在符合 a > 1 條件的二級索引記錄的范圍里,b 字段的值是無序的。
比如,下圖的聯合索引的 B+ Tree 里:
下面這三條記錄的 a 字段的值都符合 a > 1 查詢條件,而 b 字段的值是無序的:
a 字段值為 5 的記錄,該記錄的 b 字段值為 8;
a 字段值為 6 的記錄,該記錄的 b 字段值為 10;
a 字段值為 7 的記錄,該記錄的 b 字段值為 5;
因此,我們不能根據查詢條件 b = 2 來進一步減少需要掃描的記錄數量(b 字段無法利用聯合索引進行索引查詢的意思)。
所以在執行 Q1 這條查詢語句的時候,對應的掃描區間是 (2, + ∞),形成該掃描區間的邊界條件是 a > 1,與 b = 2 無關。
因此,Q1 這條查詢語句只有 a 字段用到了聯合索引進行索引查詢,而 b 字段并沒有使用到聯合索引。
我們也可以在執行計劃中的 key_len 知道這一點,在使用聯合索引進行查詢的時候,通過 key_len 我們可以知道優化器具體使用了多少個字段的查詢條件來形成掃描區間的邊界條件。
舉例個例子 ,a 和 b 都是 int 類型且不為 NULL 的字段,那么 Q1 這條查詢語句執行計劃如下:

可以看到 key_len 為 4 字節(如果字段允許為 NULL,就在字段類型占用的字節數上加 1,也就是 5 字節),說明只有 a 字段用到了聯合索引進行索引查詢,而且可以看到,即使 b 字段沒用到聯合索引,key 為 idx_a_b,說明 Q1 查詢語句使用了 idx_a_b 聯合索引。
通過 Q1 查詢語句我們可以知道,a 字段使用了 > 進行范圍查詢,聯合索引的最左匹配原則在遇到 a 字段的范圍查詢( >)后就停止匹配了,因此 b 字段并沒有使用到聯合索引。
例子二
Q2: select * from t_table where a >= 1 and b = 2,聯合索引(a, b)哪一個字段用到了聯合索引的 B+Tree?
Q2 和 Q1 的查詢語句很像,唯一的區別就是 a 字段的查詢條件「大于等于」。
由于聯合索引(二級索引)是先按照 a 字段的值排序的,所以符合 >= 1 條件的二級索引記錄肯定是相鄰,于是在進行索引掃描的時候,可以定位到符合 >= 1 條件的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄不符合 a>= 1 條件位置。所以 a 字段可以在聯合索引的 B+Tree 中進行索引查詢。
雖然在符合 a>= 1 條件的二級索引記錄的范圍里,b 字段的值是「無序」的,但是對于符合 a = 1 的二級索引記錄的范圍里,b 字段的值是「有序」的(因為對于聯合索引,是先按照 a 字段的值排序,然后在 a 字段的值相同的情況下,再按照 b 字段的值進行排序)。
于是,在確定需要掃描的二級索引的范圍時,當二級索引記錄的 a 字段值為 1 時,可以通過 b = 2 條件減少需要掃描的二級索引記錄范圍(b 字段可以利用聯合索引進行索引查詢的意思)。也就是說,從符合 a = 1 and b = 2 條件的第一條記錄開始掃描,而不需要從第一個 a 字段值為 1 的記錄開始掃描。
所以,Q2 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。
我們也可以在執行計劃中的 key_len 知道這一點。執行計劃如下:

可以看到 key_len 為 8 字節,說明優化器使用了 2 個字段的查詢條件來形成掃描區間的邊界條件,也就是 a 和 b 字段都用到了聯合索引進行索引查詢。
通過 Q2 查詢語句我們可以知道,雖然 a 字段使用了 >= 進行范圍查詢,但是聯合索引的最左匹配原則并沒有在遇到 a 字段的范圍查詢( >=)后就停止匹配了,b 字段還是可以用到了聯合索引的。
例子三
Q3: SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2,聯合索引(a, b)哪一個字段用到了聯合索引的 B+Tree?
Q3 查詢條件中 a BETWEEN 2 AND 8 的意思是查詢 a 字段的值在 2 和 8 之間的記錄。
不同的數據庫對 BETWEEN ... AND 處理方式是有差異的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 邊界值,類似于 >= and =<。而有的數據庫則不包含 value1 和 value2 邊界值(類似于 > and <)。
這里我們只討論 MySQL。由于 MySQL 的 BETWEEN 包含 value1 和 value2 邊界值,所以類似于 Q2 查詢語句,因此 Q3 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。
我們也可以在執行計劃中的 key_len 知道這一點。執行計劃如下:

可以看到 key_len 為 8 字節,說明優化器使用了 2 個字段的查詢條件來形成掃描區間的邊界條件,也就是 a 和 b 字段都用到了聯合索引進行索引查詢。
通過 Q3 查詢語句我們可以知道,雖然 a 字段使用了 BETWEEN 進行范圍查詢,但是聯合索引的最左匹配原則并沒有在遇到 a 字段的范圍查詢( BETWEEN)后就停止匹配了,b 字段還是可以用到了聯合索引的。
例子四
Q4: SELECT * FROM t_user WHERE name like 'j%' and age = 22,聯合索引(name, age)哪一個字段用到了聯合索引的 B+Tree?
由于聯合索引(二級索引)是先按照 name 字段的值排序的,所以前綴為 ‘j’ 的 name 字段的二級索引記錄都是相鄰的, 于是在進行索引掃描的時候,可以定位到符合前綴為 ‘j’ 的 name 字段的第一條記錄,然后沿著記錄所在的鏈表向后掃描,直到某條記錄的 name 前綴不為 ‘j’ 為止。
所以 a 字段可以在聯合索引的 B+Tree 中進行索引查詢,形成的掃描區間是['j','k')。注意, j 是閉區間。如下圖:
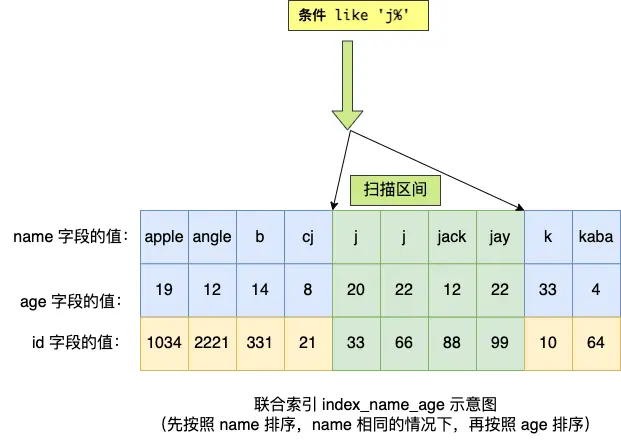
雖然在符合前綴為 ‘j’ 的 name 字段的二級索引記錄的范圍里,age 字段的值是「無序」的,但是對于符合 name = j 的二級索引記錄的范圍里,age字段的值是「有序」的(因為對于聯合索引,是先按照 name 字段的值排序,然后在 name 字段的值相同的情況下,再按照 age 字段的值進行排序)。
于是,在確定需要掃描的二級索引的范圍時,當二級索引記錄的 name 字段值為 ‘j’ 時,可以通過 age = 22 條件減少需要掃描的二級索引記錄范圍(age 字段可以利用聯合索引進行索引查詢的意思)。也就是說,從符合 name = 'j' and age = 22 條件的第一條記錄時開始掃描,而不需要從第一個 name 為 j 的記錄開始掃描 。如下圖的右邊:
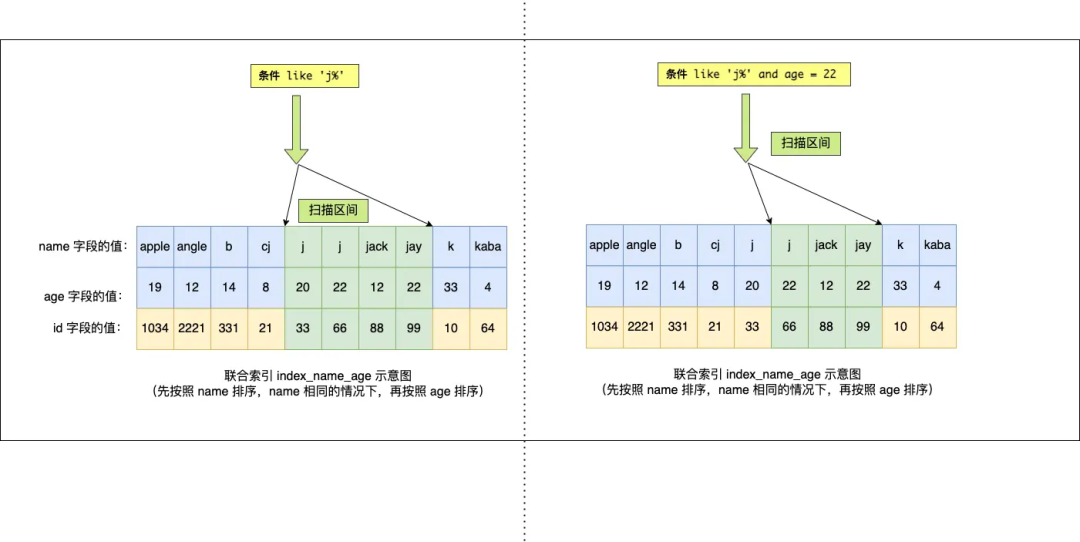
所以,Q4 這條查詢語句 a 和 b 字段都用到了聯合索引進行索引查詢。
我們也可以在執行計劃中的 key_len 知道這一點。本次例子中:
name 字段的類型是 varchar(30) 且不為 NULL,數據庫表使用了 utf8mb4 字符集,一個字符集為 utf8mb4 的字符是 4 個字節,因此 name 字段的實際數據最多占用的存儲空間長度是 120 字節(30 x 4),然后因為 name 是變長類型的字段,需要再加 2,也就是 name 的 key_len 為 122。
age 字段的類型是 int 且不為 NULL,key_len 為 4。
Q4 查詢語句的執行計劃如下:

可以看到 key_len 為 126 字節,name 的 key_len 為 122,age 的 key_len 為 4,說明優化器使用了 2 個字段的查詢條件來形成掃描區間的邊界條件,也就是 name 和 age 字段都用到了聯合索引進行索引查詢。
通過 Q4 查詢語句我們可以知道,雖然 name 字段使用了 like 前綴匹配進行范圍查詢,但是聯合索引的最左匹配原則并沒有在遇到 name 字段的范圍查詢( like 'j%')后就停止匹配了,age 字段還是可以用到了聯合索引的。
小結
網上傳來穿去這句話:「聯合索引的最左匹配原則會一直向右匹配直到遇到范圍查詢(>、<、between、like) 就會停止匹配」并不是對的。
經過實驗的證明,我得出的結論是這樣的:
聯合索引的最左匹配原則,在遇到范圍查詢(如 >、<)的時候,就會停止匹配,也就是范圍查詢的字段可以用到聯合索引,但是在范圍查詢字段后面的字段無法用到聯合索引。注意,對于 >=、<=、BETWEEN、like 前綴匹配的范圍查詢,并不會停止匹配。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3782瀏覽量
137388 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9800
原文標題:全網都在說一個錯誤的結論
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于網格索引的高速網絡數據流偏好查詢方法
基于增量序列的調色板索引匹配算法
Mysql優化選擇最佳索引規則
功放和喇叭如何匹配_功放與喇叭的匹配原則是什么
MySQL索引使用原則
MySQL索引的使用問題
一百道關于MySQL索引解答
sql優化常用的幾種方法
索引的底層實現詳解

低噪聲放大器輸入端和輸出端匹配原則是什么?阻抗匹配的目的是什么?
Mysql索引是什么東西?索引有哪些特性?索引是如何工作的?





 工商網監
工商網監
評論